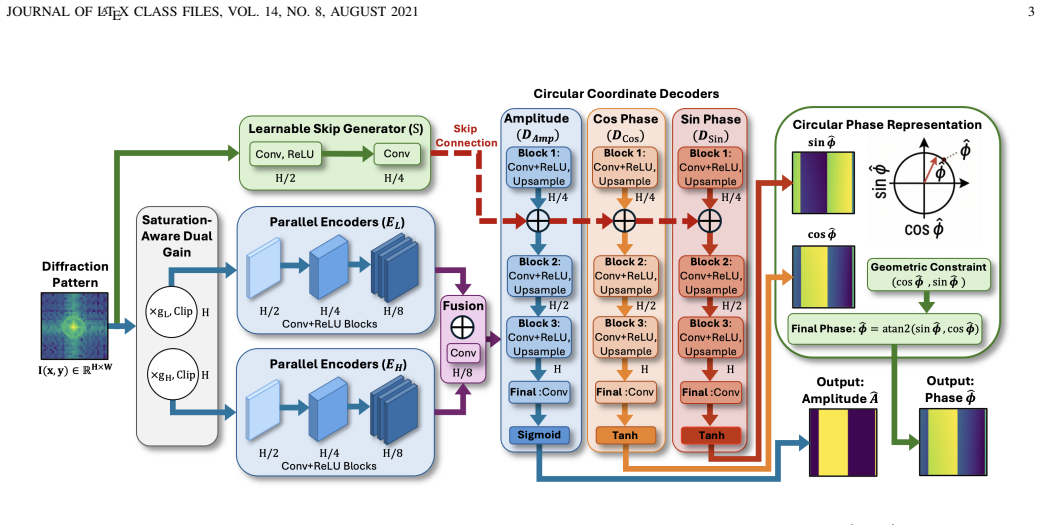
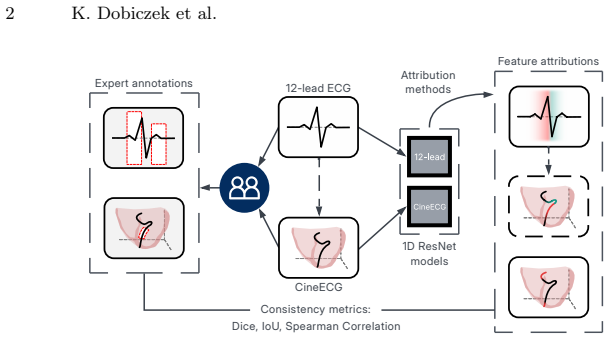
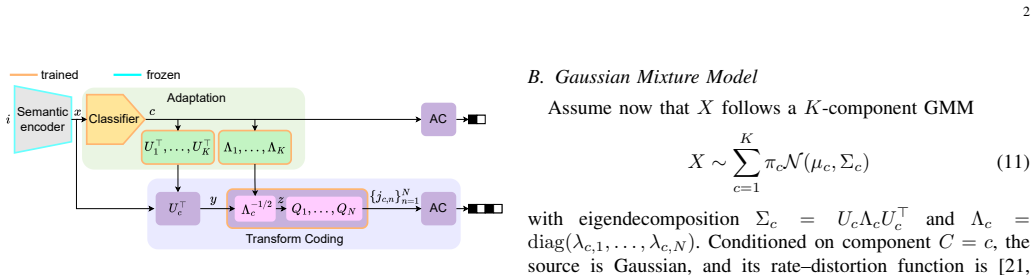
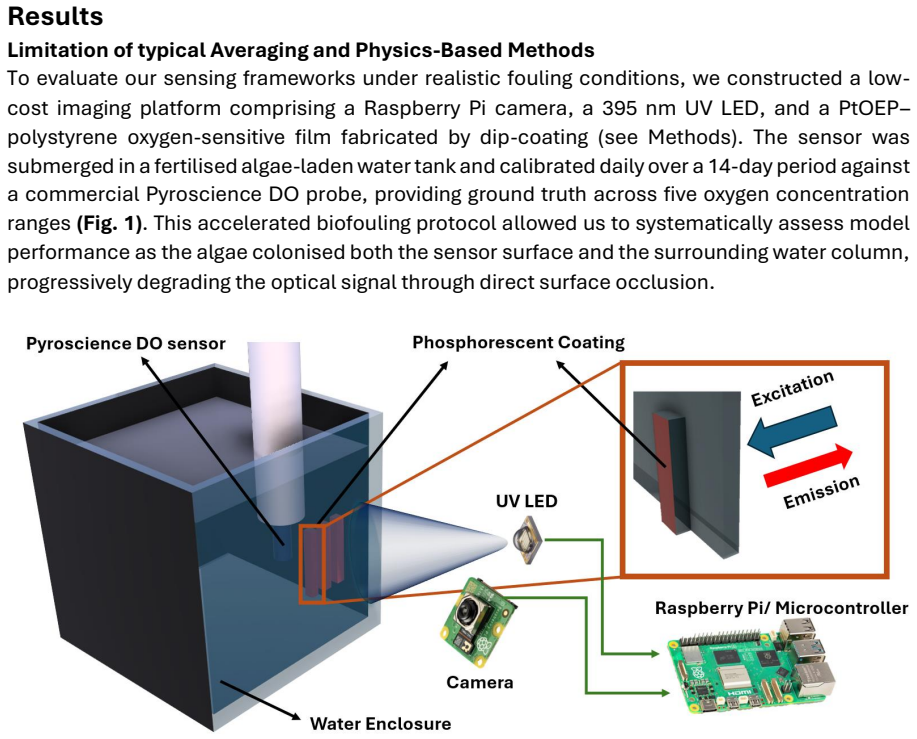
0
CycleGAN turns standard CT scans into usable low-dose training data
A Comparative Analysis of CT Degradation for LDCT Nodule Classification using Radiomics
Synthetic images raise nodule classifier AUC to 0.861 and sensitivity to 0.743 on real screening cases.
 full image
full image
abstract click to expand
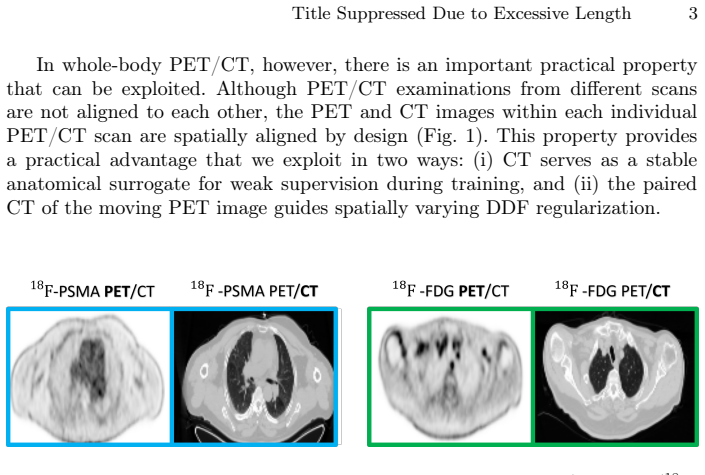
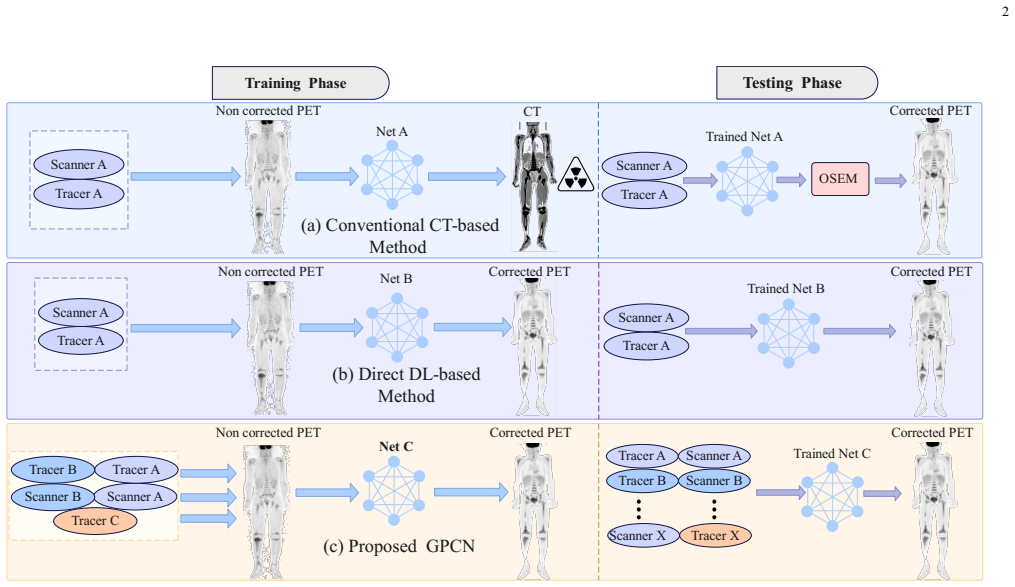
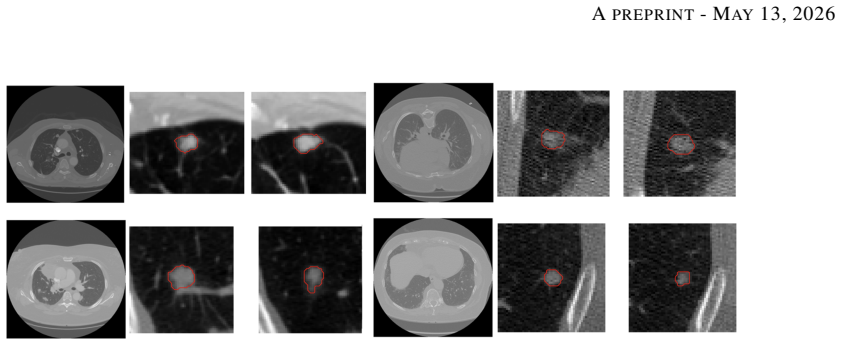
Low-dose computed tomography (LDCT) is the standard modality for lung cancer screening, known for its low radiation dose but high noise levels. While existing literature focuses on denoising LDCT images, comparative research on simulating LDCT characteristics to directly use these images for model development is lacking. This study shifts the focus from denoising images to degrading available standard-dose CT (SDCT) data, generating synthetic images for data augmentation to train classifiers for screening-detected nodules. We compare three degradation methods: (1) a sinogram domain statistical noise insertion; (2) replicate a validated physics-based simulation using Pix2Pix; and (3) unpaired CycleGAN. The generated images were utilized to simulate LDCT screening scenario replacing 695 SDCT cases from the LIDC-IDRI dataset, from which radiomic features were extracted to train machine learning models for lung nodule classification. Regarding image quality, CycleGAN achieved the best Fr\'echet inception distance (0.1734) and kernel inception distance (0.0813; 0.1002) scores, indicating distributional alignment with the target low-dose domain. In the nodule classification task, results confirmed the necessity of domain adaptation since a baseline model trained on non-degraded SDCT data failed to generalize to the real LDCT set (AUC 0.789) with a low sensitivity (0.571). Degraded images generated using CycleGAN approach led to the most balanced performance on the classification task using Adam Booster classifier, achieving an AUC of 0.861, sensitivity of 0.743 and specificity of 0.858 in the independent test. Our findings confirm that generating synthetic LDCT data from standard-dose scans is a viable strategy for training robust nodule classifiers for screening detected nodules.