Cost-Aware Diffusion Draft Trees for Speculative Decoding
Pith reviewed 2026-06-28 14:46 UTC · model grok-4.3
The pith
CaDDTree jointly optimizes draft tree structure and node budget to maximize token throughput in speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CaDDTree directly optimizes the throughput objective by selecting both the tree and the budget each round. By decomposing the objective into a one-dimensional search over budget and proving unimodality under convex verification cost, it enables an efficient greedy stopping rule that requires no pre-computed budget schedule.
What carries the argument
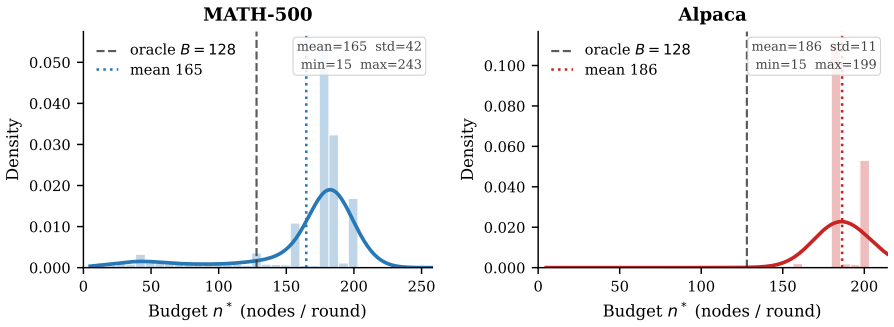
The throughput objective (expected tokens per unit time) that incorporates explicit draft and verification latencies and is shown to be unimodal when verification cost is convex.
If this is right
- Budget is chosen adaptively each round from current marginals and measured cost, eliminating offline search.
- The unimodal property guarantees an efficient greedy search finds the throughput-maximizing budget.
- Throughput is optimized rather than acceptance length, directly improving practical generation speed.
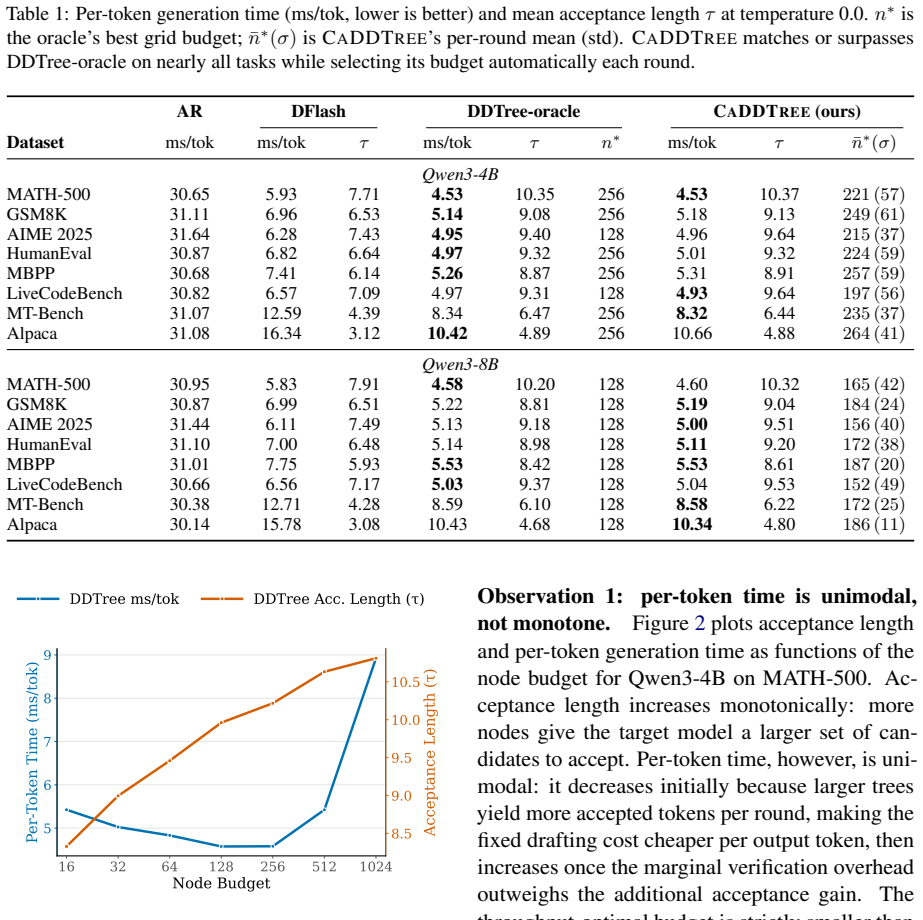
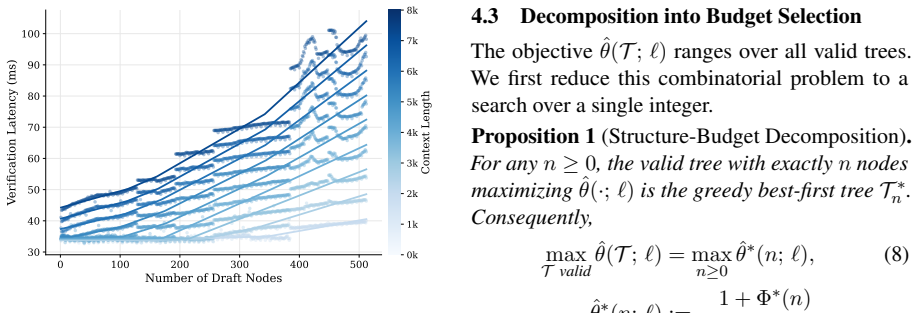
- Performance matches or exceeds DDTree with oracle budget selection across eight benchmarks on Qwen3-4B and Qwen3-8B.
Where Pith is reading between the lines
- The same per-round decomposition could be tested on drafters that are not block-diffusion if they also produce per-position probabilities.
- Hardware whose verification cost curves deviate from convexity would require checking whether a different search procedure is needed.
- The adaptive-budget idea suggests re-examining other fixed-resource choices in inference pipelines where cost grows with resource use.
- pith_inferences
Load-bearing premise
The verification cost function is convex in the number of nodes.
What would settle it
Run the greedy stopping rule on hardware where measured verification cost is observed to be non-convex and check whether the selected budget still maximizes measured throughput.
Figures
read the original abstract
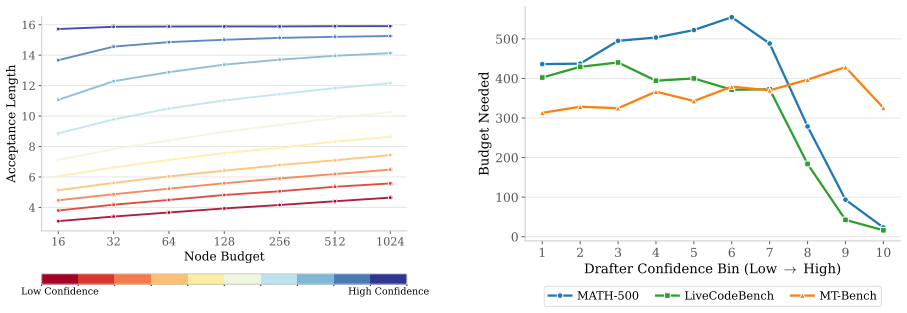
Speculative decoding accelerates inference by having a lightweight drafter propose tokens verified in parallel by the target language model. Block diffusion drafters such as DFlash generate an entire draft block in one pass, yielding per-position marginals; DDTree uses these to build a candidate tree that maximizes expected acceptance length under a fixed node budget. We observe, however, that acceptance length is non-decreasing in budget: it always favors larger trees regardless of verification cost, offering no principled basis for budget selection. We introduce \textbf{CaDDTree} (Cost-aware Diffusion Draft Tree), a method that directly optimizes token throughput (expected tokens generated per unit time) by jointly selecting the tree structure and node budget. We model draft and verification latencies explicitly, show that the throughput objective decomposes into a per-round one-dimensional search over the budget, and prove that under a convex verification cost the throughput function is \emph{unimodal}, enabling an efficient greedy stopping rule. CaDDTree requires no offline budget search, adapting the budget each round from the current per-position distributions and verification cost. Experiments on Qwen3-4B and Qwen3-8B across eight benchmarks spanning reasoning, coding, and instruction-following tasks show that \caDDTree{} matches or surpasses DDTree with oracle budget selection on nearly all tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CaDDTree for speculative decoding with block diffusion drafters. It claims that acceptance length alone provides no basis for budget selection, so the method directly optimizes expected token throughput by jointly choosing tree structure and node budget. Latencies are modeled explicitly; the throughput objective is shown to decompose into a per-round 1D search over budget; under the assumption of convex verification cost the objective is proved unimodal, admitting an efficient greedy stopping rule with no offline search. Experiments on Qwen3-4B and Qwen3-8B across eight benchmarks report that CaDDTree matches or exceeds DDTree equipped with oracle budget selection on nearly all tasks.
Significance. If the decomposition and unimodality result hold, the work supplies a principled, online adaptive procedure for budget selection in tree-based speculative decoding that removes the need for per-model offline tuning. The explicit latency modeling and the reported experimental parity with an oracle baseline on multiple task categories would constitute a concrete practical advance for inference efficiency in large language models.
major comments (1)
- [Abstract] Abstract and the central algorithmic claim: the proof that the throughput objective is unimodal (and therefore admits an efficient greedy stopping rule) is conditioned on convexity of the verification cost function. No empirical validation or plot is supplied showing that verification latency versus node budget is convex for the Qwen3-4B or Qwen3-8B models used in the experiments. If convexity fails on these models, the unimodality guarantee does not apply, the greedy rule may terminate at a suboptimal budget, and the claim that CaDDTree matches oracle performance would rest solely on the empirical results rather than on the stated optimization procedure.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for empirical support of the convexity assumption underlying our unimodality proof. We address the concern directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and the central algorithmic claim: the proof that the throughput objective is unimodal (and therefore admits an efficient greedy stopping rule) is conditioned on convexity of the verification cost function. No empirical validation or plot is supplied showing that verification latency versus node budget is convex for the Qwen3-4B or Qwen3-8B models used in the experiments. If convexity fails on these models, the unimodality guarantee does not apply, the greedy rule may terminate at a suboptimal budget, and the claim that CaDDTree matches oracle performance would rest solely on the empirical results rather than on the stated optimization procedure.
Authors: We agree that the manuscript lacks an explicit empirical check of convexity for the verification latency function on the evaluated Qwen3 models. The theoretical result is stated under the convexity assumption, and the experiments report end-to-end throughput parity with the oracle independently of that proof. In the revision we will add a plot of measured verification latency versus node budget for both Qwen3-4B and Qwen3-8B (under the same hardware and batch settings used in the main experiments) together with a brief discussion of the observed shape. If the plotted function is convex, this directly supports applicability of the unimodality guarantee; if not, we will note the limitation and emphasize that the reported performance gains rest on the empirical results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives the throughput objective directly from explicit models of draft and verification latencies, decomposes the optimization into a per-round 1D search over budget, and proves unimodality under the convexity assumption on verification cost. This is a forward mathematical derivation from stated modeling assumptions rather than any reduction of the claimed result to its inputs by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text; the convexity is an explicit enabling assumption, not a derived or fitted quantity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption verification cost is convex
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
International Conference on Learning Representations , volume=
Block diffusion: Interpolating between autoregressive and diffusion language models , author=. International Conference on Learning Representations , volume=
-
[4]
DFlash: Block Diffusion for Flash Speculative Decoding
DFlash: Block Diffusion for Flash Speculative Decoding , author=. arXiv preprint arXiv:2602.06036 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Accelerating Speculative Decoding with Block Diffusion Draft Trees
Accelerating Speculative Decoding with Block Diffusion Draft Trees , author=. arXiv preprint arXiv:2604.12989 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Eagle: Speculative sampling requires rethinking feature uncertainty , author=. arXiv preprint arXiv:2401.15077 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Eagle-2: Faster inference of language models with dynamic draft trees , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[8]
Advances in Neural Information Processing Systems , volume=
Eagle-3: Scaling up inference acceleration of large language models via training-time test , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Transactions of the Association for Computational Linguistics , volume=
Opt-tree: Speculative decoding with adaptive draft tree structure , author=. Transactions of the Association for Computational Linguistics , volume=. 2025 , publisher=
2025
-
[10]
Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 , pages=
Specinfer: Accelerating large language model serving with tree-based speculative inference and verification , author=. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 , pages=
-
[11]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple llm inference acceleration framework with multiple decoding heads , author=. arXiv preprint arXiv:2401.10774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2504.18583 , year=
Pard: Accelerating llm inference with low-cost parallel draft model adaptation , author=. arXiv preprint arXiv:2504.18583 , year=
-
[13]
arXiv preprint arXiv:2601.19278 , year=
DART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference , author=. arXiv preprint arXiv:2601.19278 , year=
-
[14]
arXiv preprint arXiv:2601.07353 , year=
TALON: Confidence-Aware Speculative Decoding with Adaptive Token Trees , author=. arXiv preprint arXiv:2601.07353 , year=
-
[15]
arXiv preprint arXiv:2603.01639 , year=
Learning to Draft: Adaptive Speculative Decoding with Reinforcement Learning , author=. arXiv preprint arXiv:2603.01639 , year=
-
[16]
arXiv preprint arXiv:2604.02047 , year=
Goose: Anisotropic Speculation Trees for Training-Free Speculative Decoding , author=. arXiv preprint arXiv:2604.02047 , year=
-
[17]
arXiv preprint arXiv:2308.04623 , year=
Accelerating llm inference with staged speculative decoding , author=. arXiv preprint arXiv:2308.04623 , year=
-
[18]
arXiv preprint arXiv:2402.14160 , year=
Recursive speculative decoding: Accelerating llm inference via sampling without replacement , author=. arXiv preprint arXiv:2402.14160 , year=
-
[19]
World Wide Web , volume=
Dyspec: Faster speculative decoding with dynamic token tree structure , author=. World Wide Web , volume=. 2025 , publisher=
2025
-
[20]
International Conference on Learning Representations , volume=
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. International Conference on Learning Representations , volume=
-
[21]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[23]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[27]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[28]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[29]
Stanford Center for Research on Foundation Models
Alpaca: A strong, replicable instruction-following model , author=. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html , volume=
2023
-
[30]
Mathematical Programming Computation , pages=
Clarabel: An interior-point solver for conic programs with quadratic objectives , author=. Mathematical Programming Computation , pages=. 2026 , publisher=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.