Extreme Low-Bit Inference in Reasoning Models: Failure Modes and Targeted Recovery
Pith reviewed 2026-06-28 14:24 UTC · model grok-4.3
The pith
2-bit quantized reasoning models produce repetitive loops and unfinished traces that erase speed gains and tank accuracy, but lightweight detection plus selective high-precision steps can recover both.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
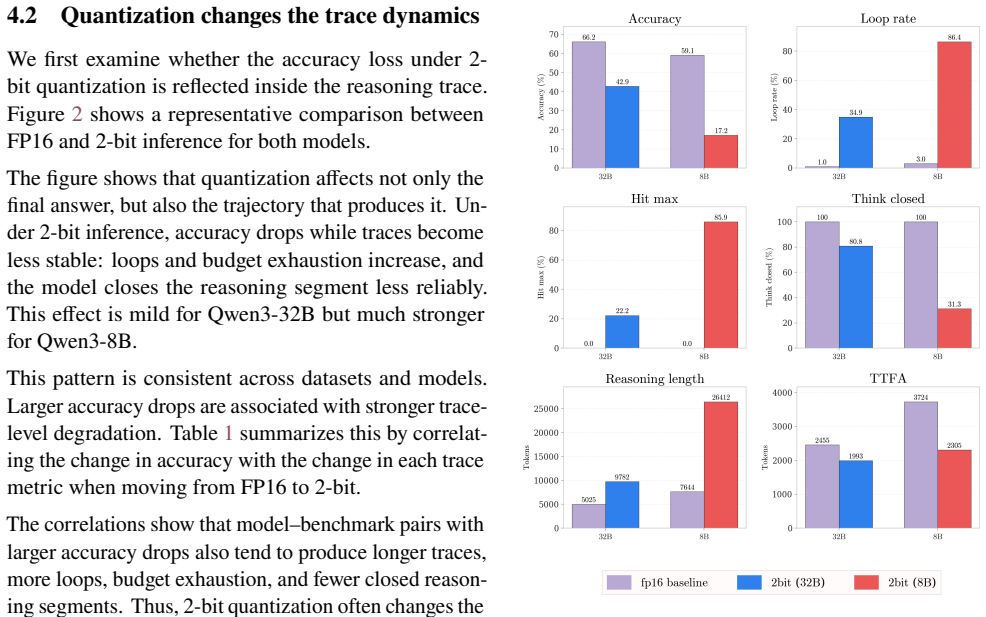
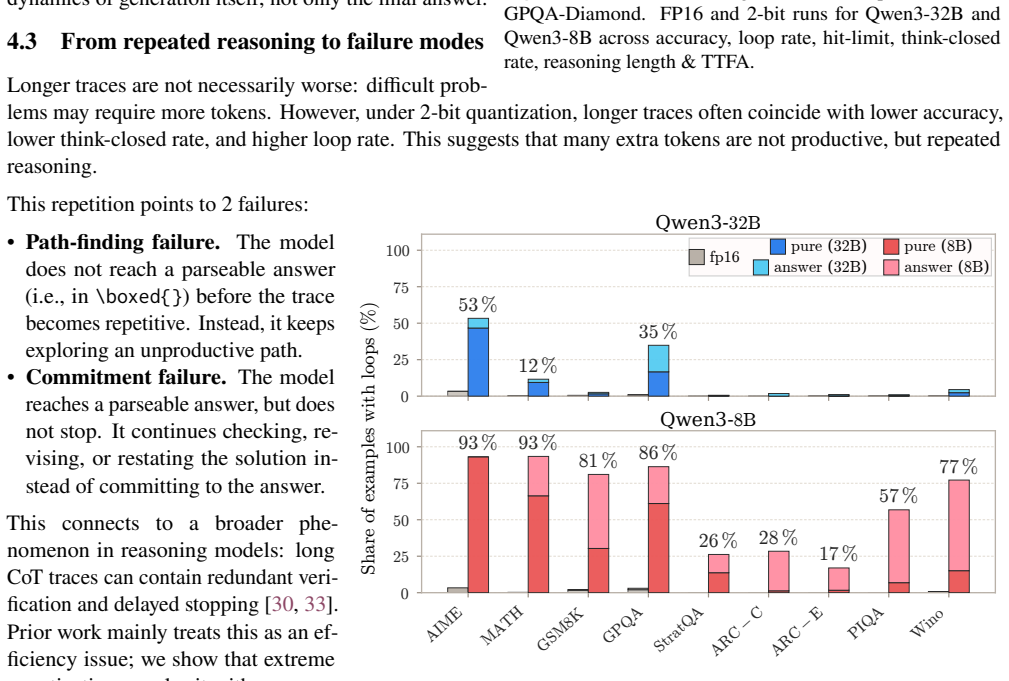
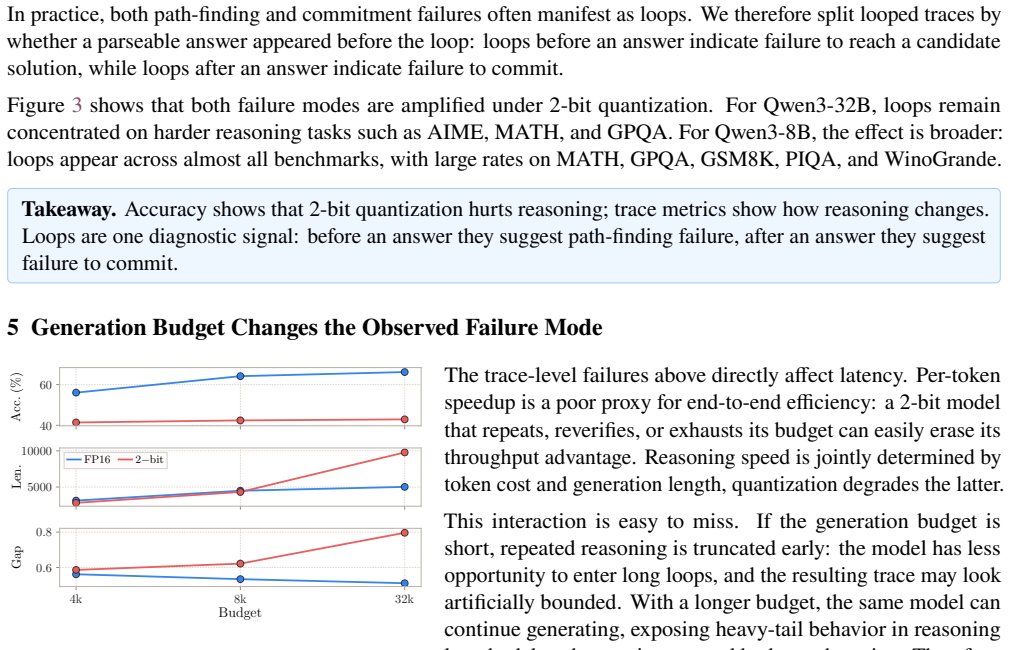
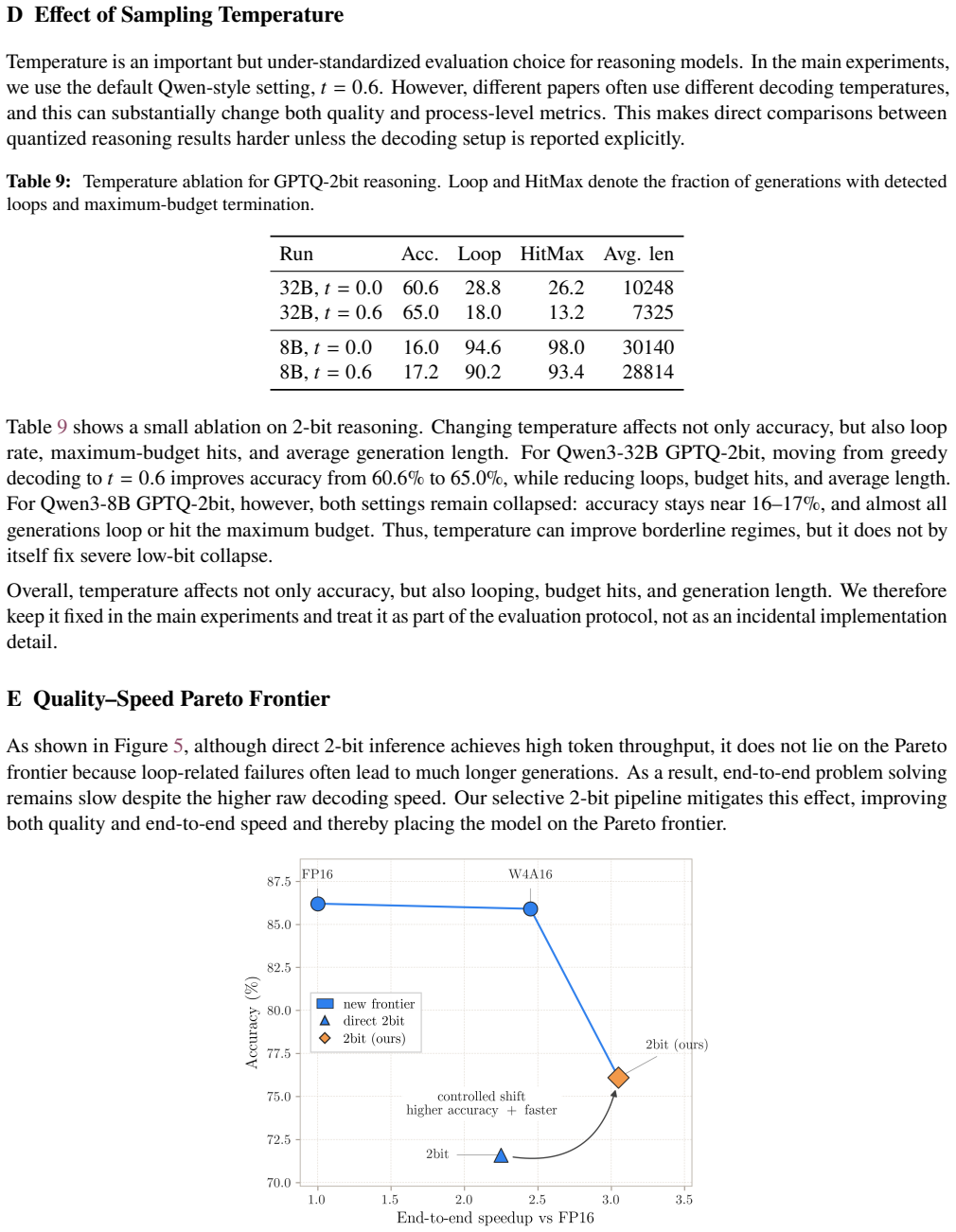
Accuracy degradation under 2-bit inference is not mainly a token-level error problem but a process-level one: the models emit much longer traces containing repetitive loops, budget exhaustion, delayed commitment, and unclosed reasoning segments. Treating these as controllable generation pathologies, the authors introduce FP16 planning (a short high-precision outline) and loop rescue (lightweight detection that forces an earlier answer or FP16 fallback). On MATH-500 these interventions raise Qwen3-8B accuracy from 17.2% to 74.2% and Qwen3-32B from 65.0% to 87.2% while preserving real end-to-end speed.
What carries the argument
Lightweight loop detection paired with selective FP16 planning outlines and rescue fallbacks that intervene only when repetition or exhaustion is flagged.
If this is right
- 2-bit decoding becomes usable for reasoning workloads once the generation pathologies are treated as detectable events.
- Accuracy recovery on MATH-500 scales from 8B to 32B models with the same two controls.
- End-to-end latency stays close to pure 2-bit levels because interventions are short and infrequent.
- The same failure categories appear across mathematical and commonsense tasks, suggesting the pattern is general for long-trace reasoning.
Where Pith is reading between the lines
- Similar lightweight detection rules could be tested on other low-bit levels or model families to see whether the same pathologies appear.
- The approach implies that future quantization work may benefit from monitoring trace-level statistics rather than only final-answer accuracy.
- If the detection rules generalize, they could reduce the need for full-precision fallback on resource-constrained hardware.
Load-bearing premise
The repetitive loops and related failures can be caught reliably by simple rules and the selective FP16 patches fix accuracy without erasing the overall latency reduction or creating new instabilities.
What would settle it
Apply the loop-rescue method to a fresh reasoning benchmark and measure whether accuracy stays near the degraded 2-bit baseline or total generated tokens rise instead of fall.
Figures

read the original abstract
Large Reasoning Models (LRMs) rely on long reasoning traces, making inference expensive. While low-bit quantization reduces per-token decoding cost, we show that aggressive 2-bit inference can fail to deliver end-to-end speedup because instability in the generation process inflates total token count. Instead of merely lowering answer accuracy, 2-bit quantization often produces much longer traces with repetitive loops, budget exhaustion, delayed commitment, and unclosed reasoning segments. We analyze full reasoning traces of Qwen3 reasoning models across mathematical and commonsense benchmarks and show that accuracy degradation is tightly linked to these process-level failures. To address them, we introduce two lightweight controls: FP16 planning, which gives the 2-bit model a short high-precision outline, and loop rescue, which detects repetitive traces and either commits to an earlier answer or falls back to FP16. On MATH-500, loop rescue improves Qwen3-8B accuracy from 17.2% to 74.2%, while planning plus loop rescue improves Qwen3-32B from 65.0% to 87.2%. Overall, our results show that extreme low-bit reasoning becomes practical when its failures are treated as controllable generation pathologies: with lightweight detection and selective FP16 support, 2-bit inference can recover accuracy while preserving real end-to-end speed. Our code is available at: https://github.com/brain-lab-research/quantized-reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 2-bit quantization of large reasoning models produces process-level failures (repetitive loops, budget exhaustion, delayed commitment, unclosed segments) that inflate token counts and degrade accuracy on math and commonsense benchmarks. It introduces lightweight FP16 planning (short high-precision outline) and loop rescue (detect repetitive traces and commit or fallback to FP16), reporting large accuracy gains such as Qwen3-8B on MATH-500 rising from 17.2% to 74.2% with loop rescue and Qwen3-32B from 65.0% to 87.2% with both controls. The central assertion is that these targeted interventions recover accuracy while preserving the end-to-end speed advantage of 2-bit decoding; code is released.
Significance. If the speed-preservation claim is substantiated, the work provides a practical route to extreme quantization for reasoning models by reframing failures as detectable generation pathologies rather than irreducible accuracy loss. The empirical trace analysis and open code are strengths that would aid reproducibility and extension.
major comments (3)
- [Abstract] Abstract: the claim that the controls allow 2-bit inference to 'recover accuracy while preserving real end-to-end speed' is unsupported because no token counts, wall-clock times, or speedup ratios are reported for any rescued configuration relative to naive 2-bit or FP16 baselines. This is load-bearing for the practical contribution.
- [Evaluation / Results] Evaluation sections (implied by reported accuracy deltas): the asserted tight linkage between the enumerated process failures and accuracy degradation is presented via before/after numbers but lacks correlation statistics, per-failure ablation tables, or error bars across runs, leaving the causal claim only moderately supported.
- [Methods] Methods (lightweight detection rules): the loop-rescue trigger conditions are described as lightweight but no sensitivity analysis or false-positive rates across model sizes or benchmarks are supplied, which directly affects the weakest assumption that selective FP16 interventions can be applied without new instabilities or excessive overhead.
minor comments (2)
- [Abstract] The abstract lists MATH-500 prominently but does not enumerate the full set of commonsense benchmarks used for the trace analysis.
- Notation for the two controls (FP16 planning, loop rescue) could be introduced with a short table of trigger conditions for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional empirical detail would strengthen the manuscript, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the controls allow 2-bit inference to 'recover accuracy while preserving real end-to-end speed' is unsupported because no token counts, wall-clock times, or speedup ratios are reported for any rescued configuration relative to naive 2-bit or FP16 baselines. This is load-bearing for the practical contribution.
Authors: We agree that the speed-preservation claim is central and requires explicit quantitative backing. The manuscript currently reports accuracy recovery but does not include the requested token counts, wall-clock times, or speedup ratios for the planning and loop-rescue configurations. In revision we will add these measurements for all relevant setups to substantiate the end-to-end speed advantage. revision: yes
-
Referee: [Evaluation / Results] Evaluation sections (implied by reported accuracy deltas): the asserted tight linkage between the enumerated process failures and accuracy degradation is presented via before/after numbers but lacks correlation statistics, per-failure ablation tables, or error bars across runs, leaving the causal claim only moderately supported.
Authors: The trace analysis in the paper links specific failure modes to accuracy drops through direct observation, yet we acknowledge the value of formal statistics. We will add per-failure ablation tables, Pearson correlation coefficients between failure incidence and accuracy, and error bars computed over multiple runs to provide stronger quantitative support for the causal relationship. revision: yes
-
Referee: [Methods] Methods (lightweight detection rules): the loop-rescue trigger conditions are described as lightweight but no sensitivity analysis or false-positive rates across model sizes or benchmarks are supplied, which directly affects the weakest assumption that selective FP16 interventions can be applied without new instabilities or excessive overhead.
Authors: The detection rules are kept deliberately simple to minimize overhead, but we recognize that sensitivity and reliability metrics are needed. We will include a sensitivity analysis of the trigger thresholds together with false-positive rates measured across model sizes and benchmarks, demonstrating that the rules remain stable and low-overhead. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivational steps
full rationale
The paper conducts an empirical study of 2-bit quantized reasoning models on MATH-500 and commonsense benchmarks. It identifies process-level failures via trace inspection, proposes lightweight interventions (FP16 planning and loop rescue), and reports accuracy deltas from direct experiments. No equations, fitted parameters, predictions, or self-citations form a derivation chain; all claims rest on external benchmark measurements rather than internal reductions or ansatzes. The work is self-contained against standard evaluation protocols.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 american invitational mathematics examination problems, 2026
AIME. 2026 american invitational mathematics examination problems, 2026. URLhttps://artofproblem solving.com/wiki/index.php?title=2026_AIME_I_Problems. Accessed 2026-05-26
2026
-
[2]
AbouElhamayed, Yueying Li, and Mohamed S
Yash Akhauri, Anthony Fei, Chi-Chih Chang, Ahmed F. AbouElhamayed, Yueying Li, and Mohamed S. Abdelfattah. SplitReason: Learning to offload reasoning, 2025. URLhttps://arxiv.org/abs/2504.16379
arXiv 2025
-
[3]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, 2020. URLhttps://arxiv.org/abs/1911.11641
Pith/arXiv arXiv 2020
-
[4]
Think you have solved question answering? try ARC, the AI2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge, 2018. URL https://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[5]
URLhttps://arxiv.org/abs/2110.14168
KarlCobbe,VineetKosaraju,MohammadBavarian,MarkChen,HeewooJun,LukaszKaiser,MatthiasPlappert, JerryTworek,JacobHilton,ReiichiroNakano,ChristopherHesse,andJohnSchulman.Trainingverifierstosolve math word problems.arXiv preprint arXiv:2110.14168, 2021. URLhttps://arxiv.org/abs/2110.14168
Pith/arXiv arXiv 2021
-
[6]
GSQ: Highly-accurate low-precision scalar quantization for LLMs via gumbel-softmax sampling, 2026
Alireza Dadgarnia, Soroush Tabesh, Mahdi Nikdan, Michael Helcig, Eldar Kurtic, and Dan Alistarh. GSQ: Highly-accurate low-precision scalar quantization for LLMs via gumbel-softmax sampling, 2026. URL https://arxiv.org/abs/2604.18556
Pith/arXiv arXiv 2026
-
[7]
Thecasefor4-bitprecision: k-bitinferencescalinglaws
TimDettmersandLukeZettlemoyer. Thecasefor4-bitprecision: k-bitinferencescalinglaws. InInternational Conference on Machine Learning, pages 7750–7774. PMLR, 2023. URLhttp://proceedings.mlr.press/ v202/dettmers23a/dettmers23a.pdf
2023
-
[8]
GPTQ: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tcbBPnfwxS. 9
2023
-
[9]
Tandem: Riding together with large and small language models for efficient reasoning, 2026
Zichuan Fu, Xian Wu, Guojing Li, Yejing Wang, Yijun Chen, Zihao Zhao, Yixuan Luo, Hanyu Yan, Yefeng Zheng, and Xiangyu Zhao. Tandem: Riding together with large and small language models for efficient reasoning, 2026. URLhttps://arxiv.org/abs/2604.23623
Pith/arXiv arXiv 2026
-
[10]
ML-SpecQD:Multi-level speculative decoding with quantized drafts, 2025
EvangelosGeorganas,DhirajKalamkar,AlexanderKozlov,andAlexanderHeinecke. ML-SpecQD:Multi-level speculative decoding with quantized drafts, 2025. URLhttps://arxiv.org/abs/2503.13565
arXiv 2025
-
[11]
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies.Transactions of the Association for Computational Linguistics, 2021. URLhttps://arxiv.org/abs/2101.02235
arXiv 2021
-
[12]
A survey of quantization methods for efficient neural network inference
Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. A survey of quantization methods for efficient neural network inference. InLow-power computer vision, pages 291–326. Chapman and Hall/CRC, 2022. URLhttps://amirgholami.org/assets/papers/2021_A_Survey_of_Q uantization_Methods_for_Efficient_Neural_Network_Inference.pdf
2022
-
[13]
Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Yang Yong, Shiqiao Gu, Haotong Qin, Jinyang Guo, Dahua Lin, Michele Magno, and Xianglong Liu. A survey of low-bit large language models: Basics, systems, and algorithms.Neural Networks, 192:107856, 2025. URL https://doi.org/10.1016/j.neunet.2025.107856
-
[14]
Gabriel Grand, Joshua B. Tenenbaum, Vikash K. Mansinghka, Alexander K. Lew, and Jacob Andreas. Self-steering language models, 2025. URLhttps://arxiv.org/abs/2504.07081
arXiv 2025
-
[16]
URLhttps://arxiv.org/abs/2103.03874
-
[17]
Guang Huang and Zeyi Wen. Quasar: Quantized self-speculative acceleration for rapid inference via memory-efficient verification, 2026. URLhttps://arxiv.org/abs/2603.01399
arXiv 2026
-
[18]
Quantized qwen3 collection, 2025
kaitchup. Quantized qwen3 collection, 2025. URLhttps://huggingface.co/collections/kaitchup/qu antized-qwen3
2025
-
[19]
Efficient LLM collaboration via planning, 2025
Byeongchan Lee, Jonghoon Lee, Dongyoung Kim, Jaehyung Kim, Kyungjoon Park, Dongjun Lee, and Jinwoo Shin. Efficient LLM collaboration via planning, 2025. URLhttps://arxiv.org/abs/2506.11578
Pith/arXiv arXiv 2025
-
[20]
Jinhao Li, Jiaming Xu, Shiyao Li, Shan Huang, Jun Liu, Yaoxiu Lian, and Guohao Dai. Fast and efficient 2-bit LLM inference on GPU: 2/4/16-bit in a weight matrix with asynchronous dequantization, 2024. URL https://arxiv.org/abs/2311.16442
arXiv 2024
-
[21]
Zhen Li, Yupeng Su, Songmiao Wang, Runming Yang, Congkai Xie, Aofan Liu, Ming Li, Jiannong Cao, Yuan Xie, Ngai Wong, and Hongxia Yang. Quantization meets reasoning: Exploring and mitigating degradation of low-bit LLMs in mathematical reasoning, 2025. URLhttps://arxiv.org/abs/2505.11574
arXiv 2025
-
[22]
Reward-guided speculative decoding for efficient LLM reasoning
Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong. Reward-guided speculative decoding for efficient LLM reasoning. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 37555–37572. PMLR, 2025. URLhttps://proceedings.ml...
2025
-
[23]
AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration. InProceedings of Machine Learning and Systems, volume 6, pages 87–100,
-
[24]
URL https://proceedings.mlsys.org/paper_files/paper/2024/hash/42a452cbafa9dd64e9 ba4aa95cc1ef21-Abstract-Conference.html. 10
2024
-
[25]
Quantization hurts reasoning? an empirical study on quantized reasoning models, 2025
Ruikang Liu, Yuxuan Sun, Manyi Zhang, Haoli Bai, Xianzhi Yu, Tiezheng Yu, Chun Yuan, and Lu Hou. Quantization hurts reasoning? an empirical study on quantized reasoning models, 2025. URLhttps: //arxiv.org/abs/2504.04823
arXiv 2025
-
[26]
Alliot Nagle, Jakhongir Saydaliev, Dhia Garbaya, Michael Gastpar, Ashok Vardhan Makkuva, and Hyeji Kim. TERMINATOR: Learning optimal exit points for early stopping in chain-of-thought reasoning.arXiv preprint arXiv:2603.12529, 2026. URLhttps://arxiv.org/abs/2603.12529
Pith/arXiv arXiv 2026
-
[27]
SpecReason: Fast and accurate inference-time compute via speculative reasoning, 2025
Rui Pan, Yinwei Dai, Zhihao Zhang, Gabriele Oliaro, Zhihao Jia, and Ravi Netravali. SpecReason: Fast and accurate inference-time compute via speculative reasoning, 2025. URLhttps://arxiv.org/abs/2504.078 91
2025
-
[28]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[29]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.org/abs/2311.12022
Pith/arXiv arXiv 2023
-
[30]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. InProceedings of the AAAI Conference on Artificial Intelligence, 2020. URLhttps://arxiv.org/abs/1907.10641
Pith/arXiv arXiv 2020
-
[31]
SpecCoT: Accelerating chain-of- thoughtreasoningthroughspeculativeexploration
Junhan Shi, Yijia Zhu, Zhenning Shi, Dan Zhao, Qing Li, and Yong Jiang. SpecCoT: Accelerating chain-of- thoughtreasoningthroughspeculativeexploration. InFindingsoftheAssociationforComputationalLinguistics: EMNLP 2025, pages 24405–24415, Suzhou, China, 2025. Association for Computational Linguistics. doi: 10 .18653/v1/2025.findings-emnlp.1326. URLhttps://a...
2025
-
[32]
Stop overthinking: A survey on efficient reasoning for large language models, 2025
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, et al. Stop overthinking: A survey on efficient reasoning for large language models, 2025. URLhttps://arxiv.org/abs/2503.16419
Pith/arXiv arXiv 2025
-
[33]
Efficient reasoning for LLMs through speculative chain-of-thought, 2025
Jikai Wang, Juntao Li, Lijun Wu, and Min Zhang. Efficient reasoning for LLMs through speculative chain-of-thought, 2025. URLhttps://arxiv.org/abs/2504.19095
arXiv 2025
-
[34]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 38087– 38099. PMLR, 2023. URLhttps://proceedings.mlr.pre...
2023
-
[35]
DEER: Dynamic early exit in reasoning models, 2025
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Zheng Lin, Li Cao, and Weiping Wang. DEER: Dynamic early exit in reasoning models, 2025. URLhttps://arxiv.org/abs/2504.15895
arXiv 2025
-
[36]
Wang Yang, Xiang Yue, Vipin Chaudhary, and Xiaotian Han. Speculative thinking: Enhancing small-model reasoning with large model guidance at inference time, 2025. URLhttps://arxiv.org/abs/2504.12329
Pith/arXiv arXiv 2025
-
[37]
Harp: Hadamard-preconditioned adaptive rotation processor for extreme llm quantization
Artur Zagitov, Gleb Molodtsov, and Aleksandr Beznosikov. Harp: Hadamard-preconditioned adaptive rotation processor for extreme llm quantization. 2026. URLhttps://arxiv.org/abs/2605.29843
Pith/arXiv arXiv 2026
-
[38]
ABQ-LLM: Arbitrary-bit quantized inference acceleration for large language models, 2025
Chao Zeng, Songwei Liu, Yusheng Xie, Hong Liu, Xiaojian Wang, Miao Wei, Shu Yang, Fangmin Chen, and Xing Mei. ABQ-LLM: Arbitrary-bit quantized inference acceleration for large language models, 2025. URL https://arxiv.org/abs/2408.08554
arXiv 2025
-
[39]
Whenreasoning meetscompression: UnderstandingtheeffectsofLLMscompressiononlargereasoningmodels.InInternational Conference on Learning Representations, 2026
NanZhang,EugeneKwek,YusenZhang,Ngoc-HieuNguyen,PrasenjitMitra,andRuiZhang. Whenreasoning meetscompression: UnderstandingtheeffectsofLLMscompressiononlargereasoningmodels.InInternational Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=2za3iNkwXn. 11
2026
-
[40]
QuantLRM: Quantization of large reasoning models via fine-tuning signals, 2026
NanZhang,EugeneKwek,YusenZhang,MuyuPan,SuhangWang,PrasenjitMitra,andRuiZhang. QuantLRM: Quantization of large reasoning models via fine-tuning signals, 2026. URLhttps://arxiv.org/abs/2602 .02581
2026
-
[41]
QSpec: Speculative decoding with complementaryquantizationschemes
Juntao Zhao, Wenhao Lu, Sheng Wang, Lingpeng Kong, and Chuan Wu. QSpec: Speculative decoding with complementaryquantizationschemes. InProceedingsofthe2025ConferenceonEmpiricalMethodsinNatural Language Processing, pages 4779–4795, Suzhou, China, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.emnlp-main.240. URLhttps://aclanthology.o...
-
[42]
Yushu Zhao, Yubin Qin, Yang Wang, Xiaolong Yang, Huiming Han, Shaojun Wei, Yang Hu, and Shouyi Yin. From quarter to all: Accelerating speculative LLM decoding via floating-point exponent remapping and parameter sharing, 2025. URLhttps://arxiv.org/abs/2510.18525. 12 Appendix Supplementary Materials forExtreme Low-Bit Inference in Reasoning Models: Failure ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.