Learning When Not to Act: Mitigating Tool Abuse in Agentic Reinforcement Learning
Pith reviewed 2026-06-28 14:57 UTC · model grok-4.3
The pith
EAPO lets agents learn selective tool use by penalizing redundant calls mainly on easier queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
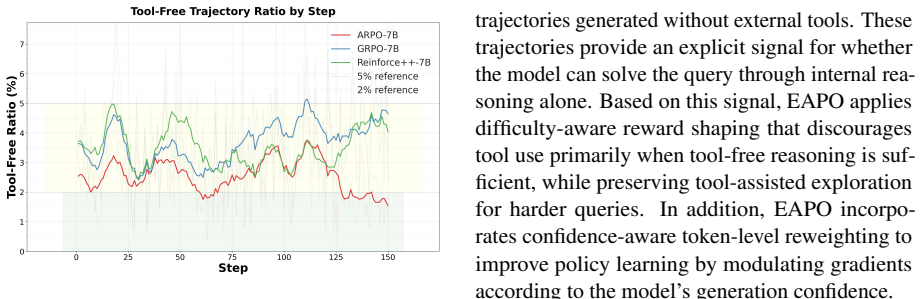
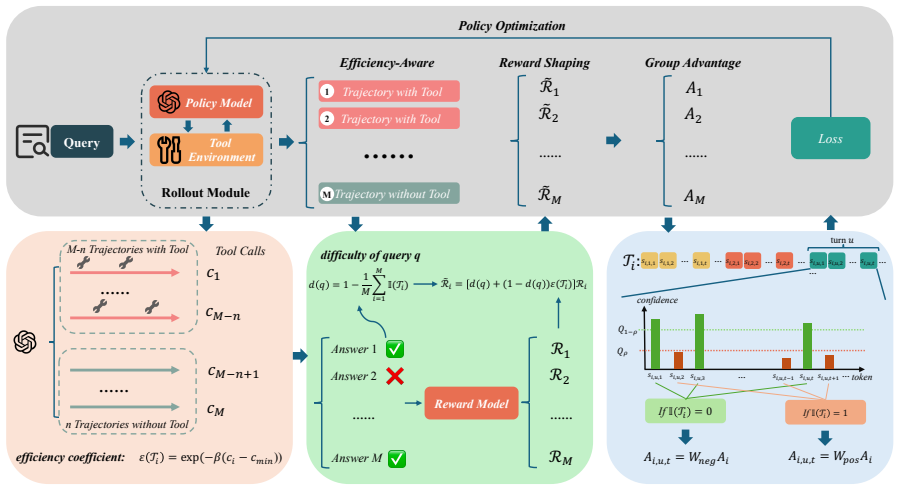
EAPO introduces tool-free trajectories into each rollout group, applies difficulty-aware reward shaping to penalize redundant tool calls mainly on easier queries, and uses confidence-aware token reweighting to improve policy learning. Across nine mathematical and knowledge-intensive reasoning benchmarks, EAPO improves average performance by 10.45%, 7.27%, and 9.69% on Qwen2.5-3B, Qwen2.5-7B, and Llama3.1-8B while reducing average tool calls by 18.33%, 18.33%, and 24.59% respectively compared with GRPO.
What carries the argument
Difficulty-aware reward shaping on tool-free trajectories within rollout groups, which selectively discourages unnecessary tool calls.
If this is right
- Agents reach higher accuracy on reasoning tasks while making fewer tool calls overall.
- The gains hold across model sizes from 3B to 8B parameters.
- Tool use stays available for queries that genuinely need it due to the difficulty-aware design.
- Policy updates improve because low-confidence tokens receive adjusted weights.
Where Pith is reading between the lines
- The same selective-shaping idea could extend to code or planning agents where tool overuse also occurs.
- Replacing static difficulty labels with online estimation would make the method more general.
- Uniform tool penalties appear less efficient than query-specific shaping for the accuracy-efficiency trade-off.
Load-bearing premise
Penalizing tool use mainly on easier queries will not suppress beneficial tool-assisted exploration on harder queries where tools remain necessary.
What would settle it
If EAPO agents show lower accuracy than GRPO on hard queries because they use tools less often, that observation would falsify the claim that the shaping preserves necessary tool use.
Figures


read the original abstract
Agentic reinforcement learning can induce tool abuse, where models overuse external tools even for queries solvable by internal reasoning. Existing approaches mitigate this issue with uniform tool-use penalties or hard limits, which reduce tool frequency but may also suppress useful tool-assisted exploration. We propose EAPO, an Efficient Agentic Policy Optimization framework that learns selective tool use. EAPO introduces tool-free trajectories into each rollout group, applies difficulty-aware reward shaping to penalize redundant tool calls mainly on easier queries, and uses confidence-aware token reweighting to improve policy learning. Across nine mathematical and knowledge-intensive reasoning benchmarks, EAPO consistently improves the accuracy efficiency trade-off on Qwen2.5-3B, Qwen2.5-7B, and Llama3.1-8B. Compared with GRPO, EAPO improves average performance by 10.45%, 7.27%, and 9.69%, while reducing average tool calls by 18.33%, 18.33%, and 24.59%, respectively. These results show that agents can learn when not to use tools without compromising tool-integrated reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EAPO, an Efficient Agentic Policy Optimization method for agentic RL that mitigates tool abuse via tool-free trajectories in rollouts, difficulty-aware reward shaping to penalize redundant tool calls primarily on easier queries, and confidence-aware token reweighting. It claims consistent improvements to the accuracy-efficiency trade-off over GRPO across nine mathematical and knowledge-intensive benchmarks on Qwen2.5-3B, Qwen2.5-7B, and Llama3.1-8B, with average accuracy gains of 10.45%, 7.27%, and 9.69% alongside tool-call reductions of 18.33%, 18.33%, and 24.59%.
Significance. If the empirical claims are substantiated with variance, statistical tests, and targeted ablations, the selective penalty mechanism could meaningfully advance efficient tool use in agentic systems by showing that difficulty-aware shaping can reduce overuse without harming hard-query performance. The multi-model, multi-benchmark scope is a positive aspect of the evaluation design.
major comments (2)
- [Abstract] Abstract: the central performance claims report average gains without variance, statistical tests, ablation results, or experimental protocol details (e.g., rollout counts, difficulty estimator definition, or seed reporting), leaving the quantitative improvements only weakly supported.
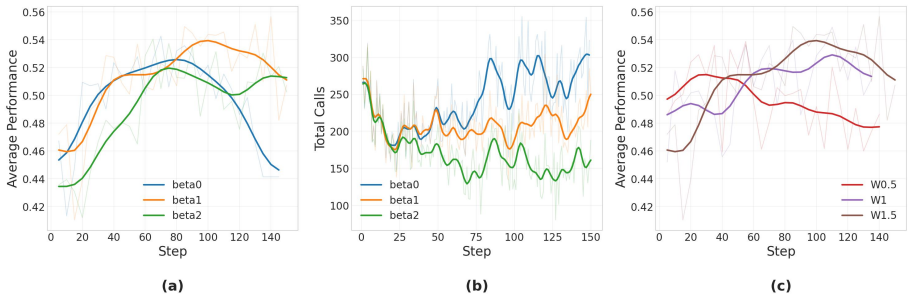
- [Method (difficulty-aware reward shaping)] Method section on difficulty-aware reward shaping: the load-bearing assumption that the (unspecified) difficulty metric cleanly separates redundant tool use on easy queries from necessary tool use on hard queries is not validated; aggregate benchmark results do not address potential misclassification on the harder tail, which could suppress beneficial exploration as highlighted by the stress-test concern.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly defined or referenced the difficulty estimator and confidence reweighting mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we address each major comment point-by-point, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims report average gains without variance, statistical tests, ablation results, or experimental protocol details (e.g., rollout counts, difficulty estimator definition, or seed reporting), leaving the quantitative improvements only weakly supported.
Authors: We agree that the abstract's quantitative claims would be better supported by variance, statistical details, and protocol information. In the revision we will add standard deviations across seeds to the reported averages, explicitly state the number of rollouts and seeds used, define the difficulty estimator in the method section (with a brief reference in the abstract if space allows), and include a short note on the experimental protocol. These additions will be placed in the main text or appendix as appropriate while keeping the abstract concise. revision: yes
-
Referee: [Method (difficulty-aware reward shaping)] Method section on difficulty-aware reward shaping: the load-bearing assumption that the (unspecified) difficulty metric cleanly separates redundant tool use on easy queries from necessary tool use on hard queries is not validated; aggregate benchmark results do not address potential misclassification on the harder tail, which could suppress beneficial exploration as highlighted by the stress-test concern.
Authors: The difficulty metric is introduced in the method section but we acknowledge it is not fully specified or validated against the harder tail in the current draft. We will revise the method section to provide an explicit definition and add a targeted analysis (new figure or table) that breaks down tool-call frequency and accuracy on the most difficult queries to demonstrate that performance on hard cases is preserved. This directly addresses the risk of misclassification suppressing exploration. revision: partial
Circularity Check
No circularity: empirical gains on held-out benchmarks are independent of internal definitions
full rationale
The paper proposes EAPO as a policy optimization method with difficulty-aware reward shaping and reports direct accuracy and tool-call reductions versus GRPO on nine external benchmarks. No equations are presented that define a 'prediction' as a fitted parameter or that reduce the reported deltas to quantities constructed from the method's own inputs. The central claims rest on held-out evaluation rather than self-referential derivation or self-citation chains. This is the expected non-finding for an empirical RL methods paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- difficulty threshold for reward shaping
axioms (1)
- domain assumption Standard assumptions of policy gradient methods hold for the agentic tool-use MDP.
Forward citations
Cited by 1 Pith paper
-
Einstein World Models
Einstein World Models integrate visual rollouts from a callable world-module into LLM reasoning traces to support complex thought beyond language.
Reference graph
Works this paper leans on
-
[1]
Agentic Reinforced Policy Optimization
Guanting Dong and Hangyu Mao and Kai Ma and Licheng Bao and Yifei Chen and Zhongyuan Wang and Zhongxia Chen and Jiazhen Du and Huiyang Wang and Fuzheng Zhang and Guorui Zhou and Yutao Zhu and Ji. Agentic Reinforced Policy Optimization , journal =. 2025 , url =. doi:10.48550/ARXIV.2507.19849 , eprinttype =. 2507.19849 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19849 2025
-
[2]
Guanting Dong and Licheng Bao and Zhongyuan Wang and Kangzhi Zhao and Xiaoxi Li and Jiajie Jin and Jinghan Yang and Hangyu Mao and Fuzheng Zhang and Kun Gai and Guorui Zhou and Yutao Zhu and Ji. Agentic Entropy-Balanced Policy Optimization , journal =. 2025 , url =. doi:10.48550/ARXIV.2510.14545 , eprinttype =. 2510.14545 , timestamp =
-
[3]
arXiv preprint arXiv:2509.02479 , year=
SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning , author=. arXiv preprint arXiv:2509.02479 , year=
-
[4]
2025 , eprint=
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
First Return, Entropy-Eliciting Explore , author=. 2025 , eprint=
2025
-
[6]
2023 , eprint=
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author=. 2023 , eprint=
2023
-
[7]
2025 , eprint=
Acting Less is Reasoning More! Teaching Model to Act Efficiently , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
ToRL: Scaling Tool-Integrated RL , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Know When to Explore: Difficulty-Aware Certainty as a Guide for LLM Reinforcement Learning , author=. 2025 , eprint=
2025
-
[12]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[13]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[14]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[15]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=
-
[16]
2020 , eprint=
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps , author=. 2020 , eprint=
2020
-
[17]
2022 , publisher=
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal=. 2022 , publisher=
2022
-
[18]
Measuring and Narrowing the Compositionality Gap in Language Models
Press, Ofir and Zhang, Muru and Min, Sewon and Schmidt, Ludwig and Smith, Noah and Lewis, Mike. Measuring and Narrowing the Compositionality Gap in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.378
-
[19]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[20]
arXiv preprint arXiv:2501.03262 , year=
Reinforce++: A simple and efficient approach for aligning large language models , author=. arXiv preprint arXiv:2501.03262 , year=
-
[21]
Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning , journal =
Guanting Dong and Yifei Chen and Xiaoxi Li and Jiajie Jin and Hongjin Qian and Yutao Zhu and Hangyu Mao and Guorui Zhou and Zhicheng Dou and Ji. Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2505.16410 , eprinttype =. 2505.16410 , timestamp =
-
[22]
The Landscape of Agentic Reinforcement Learning for
Guibin Zhang and Hejia Geng and Xiaohang Yu and Zhenfei Yin and Zaibin Zhang and Zelin Tan and Heng Zhou and Zhong-Zhi Li and Xiangyuan Xue and Yijiang Li and Yifan Zhou and Yang Chen and Chen Zhang and Yutao Fan and Zihu Wang and Songtao Huang and Francisco Piedrahita Velez and Yue Liao and Hongru WANG and Mengyue Yang and Heng Ji and Jun Wang and Shuich...
2026
-
[23]
2024 , eprint=
Retrieval-Augmented Generation for Large Language Models: A Survey , author=. 2024 , eprint=
2024
-
[24]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[25]
arXiv preprint arXiv:2210.03629 , year =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. arXiv preprint arXiv:2210.03629 , year =
-
[26]
Bowen Jin and Hansi Zeng and Zhenrui Yue and Jinsung Yoon and Sercan O. Ar. Search-R1: Training. arXiv preprint arXiv:2503.09516 , year =. 2503.09516 , archivePrefix=
-
[27]
arXiv preprint arXiv:2504.09696 , year =
GRPO-LEAD: A Difficulty-Aware Reinforcement Learning Approach for Concise Mathematical Reasoning in Language Models , author =. arXiv preprint arXiv:2504.09696 , year =. 2504.09696 , archivePrefix=
-
[28]
arXiv preprint arXiv:2505.18086 , year =
Stable Reinforcement Learning for Efficient Reasoning , author =. arXiv preprint arXiv:2505.18086 , year =. 2505.18086 , archivePrefix=
-
[29]
2024 , eprint=
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. 2024 , eprint=
2024
-
[30]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.550
-
[31]
arXiv preprint arXiv:2507.21836 , year=
Autotir: Autonomous tools integrated reasoning via reinforcement learning , author=. arXiv preprint arXiv:2507.21836 , year=
-
[32]
SMART : Self-Aware Agent for Tool Overuse Mitigation
Qian, Cheng and Acikgoz, Emre Can and Wang, Hongru and Chen, Xiusi and Sil, Avirup and Hakkani-T. SMART : Self-Aware Agent for Tool Overuse Mitigation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.239
-
[33]
2026 , eprint=
Beyond Accuracy: Unveiling Inefficiency Patterns in Tool-Integrated Reasoning , author=. 2026 , eprint=
2026
-
[34]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.