Vision-language Models for Driver Monitoring Systems: A Driver Activity Description Dataset
Pith reviewed 2026-06-28 15:27 UTC · model grok-4.3
The pith
Fine-tuning vision-language models on detailed driver action descriptions raises their accuracy from 66 to 76 on an automated metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
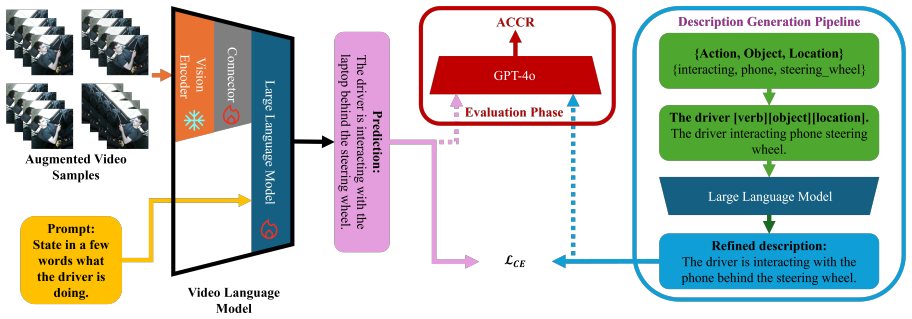
The paper converts the labeled Drive&Act videos into a parallel Drive&Act description dataset of fine-grained natural language captions, then fine-tunes VLMs on these captions. The fine-tuned model achieves an ACCR score of 76 on the new benchmark while the zero-shot baseline reaches only 66; the same model also generalizes to actions in the Driver Monitoring Dataset. The authors conclude that domain-specific language supervision measurably strengthens VLMs for driver-activity understanding.
What carries the argument
The Drive&Act description dataset, a set of fine-grained natural-language annotations paired with the original Drive&Act video clips that supplies the training signal for VLM adaptation.
If this is right
- Fine-tuned VLMs generate more accurate fine-grained descriptions of driver activities than zero-shot models.
- The performance gain transfers to actions recorded in a different driver-monitoring dataset.
- Rich textual supervision on driver actions improves a VLM's ability to interpret behavior.
- Broader generalization will require still more diverse description datasets.
Where Pith is reading between the lines
- The same conversion of action labels into language descriptions could be applied to other video datasets in robotics or surveillance.
- Real-time driver-monitoring pipelines could incorporate the fine-tuned model once latency and on-device constraints are addressed.
- The gap between zero-shot and fine-tuned performance suggests that current general VLMs lack the vocabulary and visual grounding needed for safety-critical narrow domains.
Load-bearing premise
The LLM-based scoring method produces an accurate and unbiased measure of how well a generated description matches the ground-truth driver activity.
What would settle it
A side-by-side human rating study in which raters assign quality scores to the same model outputs and the human scores fail to correlate with the reported ACCR numbers.
Figures


read the original abstract
Understanding subtle driver actions is essential for building reliable driver monitoring systems. Existing visionlanguage models (VLMs) are trained on general datasets and struggle to recognize fine distinctions in driver behaviors. This paper addresses this limitation by creating a detailed natural language version of the Drive&Act dataset. We evaluate three VLMs on our new benchmark using LLM-based scoring methods. Their performance on the new benchmark shows that they cannot reliably generate accurate fine-grained driver activity descriptions. Based on the labeled Drive&Act dataset we create a new Drive&Act description dataset containing finegrained descriptions to train VLMs on driver activity understanding. Cross dataset evaluation on the Driver Monitoring Dataset (DMD) shows that the VLM fine-tuned on our new Drive&Act description dataset generalizes well to actions in the DMD dataset. The VLM fine-tuned on our Drive&Act description dataset achieves an ACCR score of 76 outperforming the zero-shot VLM baseline with an ACCR score of 66. These findings demonstrate that adapting VLMs with richly described driver actions can significantly improve their ability to interpret driver behavior while also highlighting the need for more diverse datasets to support broader generalization in future applications. Our Drive&Act description dataset and code will be publicly available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper creates a fine-grained natural language description dataset derived from Drive&Act to improve VLM understanding of driver activities. It reports that VLMs perform poorly on this benchmark when evaluated with LLM-based scoring methods, but that fine-tuning a VLM on the new dataset yields improved generalization on the independent DMD dataset (ACCR 76 vs. 66 for zero-shot baseline). The dataset and code are to be released publicly.
Significance. If the performance claims hold under validated evaluation, the work supplies a useful domain-specific resource for adapting VLMs to safety-critical driver monitoring tasks and demonstrates the value of cross-dataset testing on DMD. The planned public release of the dataset and code is a clear strength that would enable follow-on research.
major comments (2)
- [Abstract] Abstract: the central claim that fine-tuning raises ACCR from 66 to 76 rests exclusively on LLM-based scoring methods, yet the manuscript supplies no information on the scoring prompt, rubric, temperature, few-shot examples, or any human-rater correlation study. Without such validation the 10-point gap cannot be distinguished from a possible artifact of the automated metric.
- [Abstract] Abstract / dataset construction: the new Drive&Act description dataset is presented as the basis for fine-tuning, but the text provides no details on the annotation protocol, number of annotators, or inter-annotator agreement. This information is required to assess whether the training signal is reliable enough to support the reported generalization improvement.
minor comments (1)
- [Abstract] Abstract: the three evaluated VLMs are not named, and the zero-shot baseline is described only by its ACCR score; explicit model names and additional baselines would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details on evaluation and annotation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that fine-tuning raises ACCR from 66 to 76 rests exclusively on LLM-based scoring methods, yet the manuscript supplies no information on the scoring prompt, rubric, temperature, few-shot examples, or any human-rater correlation study. Without such validation the 10-point gap cannot be distinguished from a possible artifact of the automated metric.
Authors: We agree that the current manuscript does not provide sufficient transparency on the LLM-based scoring procedure. In the revised version we will add the full scoring prompt, rubric, temperature, and few-shot examples. We will also include a human-rater correlation study (conducted on a held-out subset) that reports agreement between the automated scores and multiple human annotators, thereby validating that the observed 10-point improvement is not an artifact of the metric. revision: yes
-
Referee: [Abstract] Abstract / dataset construction: the new Drive&Act description dataset is presented as the basis for fine-tuning, but the text provides no details on the annotation protocol, number of annotators, or inter-annotator agreement. This information is required to assess whether the training signal is reliable enough to support the reported generalization improvement.
Authors: We concur that annotation details are necessary to evaluate dataset quality. The revised manuscript will describe the annotation protocol (including guidelines given to annotators), the number of annotators, their background, and inter-annotator agreement statistics (e.g., pairwise agreement or Fleiss' kappa). These additions will allow readers to assess the reliability of the training signal. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external DMD evaluation
full rationale
The paper's central claim is an empirical performance improvement (fine-tuned VLM ACCR 76 vs zero-shot 66) measured via cross-dataset evaluation on the independent DMD benchmark. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The LLM-based ACCR scoring is a methodological choice whose accuracy is a separate validity question, not a circular reduction of the reported result to its own inputs by construction. The derivation chain is self-contained against the external DMD benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can be fine-tuned on domain-specific video-text pairs to improve performance on related driver-activity description tasks.
Reference graph
Works this paper leans on
-
[1]
Eu road safety policy framework 2021–2030: Next steps towards vision zero,
European Commission, “Eu road safety policy framework 2021–2030: Next steps towards vision zero,” Tech. Rep., 2020. 1
2021
-
[2]
Euro ncap vision 2030: a safer future for mobility,
Euro NCAP, “Euro ncap vision 2030: a safer future for mobility,” Euro NCAP, Tech. Rep., Nov. 2022, accessed from official Euro NCAP resources. [Online]. Available: https://cdn.euroncap.com/ media/74468/euro-ncap-roadmap-vision-2030.pdf 1
2030
-
[3]
Activities that correlate with motion sickness in driving cars – an international online survey,
F. Diederichs, A. Herrmanns, D. Lerch, Z. Zhong, D. Piechnik, L.- A. Mathis, B. Xian, N. Vaupel, A. Vijayakumar, C. Cabaroglu, and J. Rausch, “Activities that correlate with motion sickness in driving cars – an international online survey,” inHCI in Mobility, Transport, and Automotive Systems, 2024. 1
2024
-
[4]
Detection of distraction-related actions on dmd: An image and a video-based approach comparison,
P. N. Ca ˜nas, J. D. Ortega, M. Nieto, and O. Otaegui, “Detection of distraction-related actions on dmd: An image and a video-based approach comparison,” inVISIGRAPP, 2021. 1
2021
-
[5]
Vision-language models can identify distracted driver behavior from naturalistic videos,
M. Z. Hasan, J. Chen, J. Wang, M. S. Rahman, A. Joshi, S. Velipasalar, C. Hegde, A. Sharma, and S. Sarkar, “Vision-language models can identify distracted driver behavior from naturalistic videos,”IEEE Transactions on Intelligent Transportation Systems, 2024. 1
2024
-
[6]
Driver activity recognition for intelligent vehicles: A deep learning approach,
Y . Xing, C. Lv, H. Wang, D. Cao, E. Velenis, and F.-Y . Wang, “Driver activity recognition for intelligent vehicles: A deep learning approach,” IEEE Transactions on Vehicular Technology, 2019. 1
2019
-
[7]
Drive and act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles,
M. Martin, A. Roitberg, M. Haurilet, M. Horne, S. Reiß, M. V oit, and R. Stiefelhagen, “Drive and act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles,” inProceedings of the IEEE/CVF ICCV, Oct 2019. 1, 2, 3, 5, 6, 7
2019
-
[8]
Exploration of VLMs for driver monitoring systems applications,
P. N. Ca ˜nas, M. Nieto, O. Otaegui, and I. Rodr ´ıguez, “Exploration of VLMs for driver monitoring systems applications,”arXiv preprint arXiv:2503.12281, 2025. 2, 3
arXiv 2025
-
[9]
Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis,
J. D. Ortega, N. Kose, P. Ca ˜nas, M.-A. Chao, A. Unnervik, M. Nieto, O. Otaegui, and L. Salgado, “Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis,” inComputer Vision – ECCV 2020 Workshops, 2020, pp. 387–405. 2, 5, 6
2020
-
[10]
Show and tell: A neural image caption generator,
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” inIEEE CVPR, 2015. 2
2015
-
[11]
Show, attend and tell: neural image caption generation with visual attention,
K. Xu, J. L. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. S. Zemel, and Y . Bengio, “Show, attend and tell: neural image caption generation with visual attention,” ser. ICML’15, 2015. 2
2015
-
[12]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763. 2
2021
-
[13]
Videoclip: Con- trastive pre-training for zero-shot video-text understanding,
H. Xu, G. Ghosh, P. Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “Videoclip: Con- trastive pre-training for zero-shot video-text understanding,”CoRR, vol. abs/2109.14084, 2021. 2
arXiv 2021
-
[14]
Internvid: A large-scale video-text dataset for multimodal understanding and generation,
Y . Wang, Y . He, Y . Li, K. Li, J. Yu, X. Ma, X. Li, G. Chen, X. Chen, Y . Wang, P. Luo, Z. Liu, Y . Wang, L. Wang, and Y . Qiao, “Internvid: A large-scale video-text dataset for multimodal understanding and generation,” inICLR, 2024. 2, 5
2024
-
[15]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” 2023. 2, 5
2023
-
[16]
Video-llava: Learning united visual representation by alignment before projection,
B. Lin, B. Zhu, Y . Ye, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” arXiv preprint arXiv:2311.10122, 2023. 2, 5, 6
Pith/arXiv arXiv 2023
-
[17]
Internvideo2.5: Empowering video mllms with long and rich context modeling,
Y . Wang, X. Li, Z. Yan, Y . He, J. Yu, X. Zeng, C. Wang, C. Ma, H. Huang, J. Gao, M. Dou, K. Chen, W. Wang, Y . Qiao, Y . Wang, and L. Wang, “Internvideo2.5: Empowering video mllms with long and rich context modeling,”ArXiv, 2025. 2, 5, 6
2025
-
[18]
Percep- tionlm: Open-access data and models for detailed visual understand- ing,
J. H. Cho, A. Madotto, E. Mavroudi, T. Afouras, T. Nagarajan, M. Maaz, Y . Song, T. Ma, S. Hu, S. Jain, M. Martin, H. Wang, H. Rasheed, P. Sun, P.-Y . Huang, D. Bolya, N. Ravi, S. Jain, T. Stark, S. Moon, B. Damavandi, V . Lee, A. Westbury, S. Khan, P. Kr¨ahenb¨uhl, P. Doll´ar, L. Torresani, K. Grauman, and C. Feichtenhofer, “Percep- tionlm: Open-access d...
2025
-
[19]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” in IEEE/CVF CVPR, 2023. 2
2023
-
[20]
Languagebind: Extending video-language pretraining to n-modality by language- based semantic alignment,
B. Zhu, B. Lin, M. Ning, Y . Yan, J. Cui, H. Wang, Y . Pang, W. Jiang, J. Zhang, Z. Li, W. Zhang, Z. Li, W. Liu, and L. Yuan, “Languagebind: Extending video-language pretraining to n-modality by language- based semantic alignment,” inICLR, 2024. 2, 5
2024
-
[21]
Learning robust aligned representations across mul- tiple visual modalities in human action recognition,
D. Lerch, B. Rothenburger, Z. Zhong, M. Martin, F. Diederichs, and R. Stiefelhagen, “Learning robust aligned representations across mul- tiple visual modalities in human action recognition,” inProceedings of the IEEE/CVF ICCV Workshops, 2025. 2
2025
-
[22]
State farm distracted driver detection,
A. Montoya, D. Holman, T. Smith, and W. Kan, “State farm distracted driver detection,” 2016. 2
2016
-
[23]
Real-time dis- tracted driver posture classification,
Y . Abouelnaga, H. M. Eraqi, and M. N. Moustafa, “Real-time dis- tracted driver posture classification,” inNeurIPS, Montr ´eal, Canada,
-
[24]
A novel public dataset for multimodal multiview and multispectral driver distraction analysis: 3MDAD,
I. Jegham, A. Ben Khalifa, I. Alouani, and M. A. Mahjoub, “A novel public dataset for multimodal multiview and multispectral driver distraction analysis: 3MDAD,”Signal Processing: Image Communica- tion, vol. 88, p. 115960, Oct. 2020. 2, 5
2020
-
[25]
Self-supervised driver distraction detection for imbalanced datasets,
S. Bhardwaj, D. J. Lerch, M. Martin, F. Diederichs, and R. Stiefel- hagen, “Self-supervised driver distraction detection for imbalanced datasets,” inProceedings of the IEEE 28th ITSC, 2025. 3
2025
-
[26]
State farm distracted driver detection,
A. Montoya, D. Holman, T. Smith, and W. Kan, “State farm distracted driver detection,” 2016. [Online]. Available: https://www. kaggle.com/datasets/hungquangdang/statefarm 5
2016
-
[27]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 5
2023
-
[28]
Bertscore: Evaluating text generation with bert,
T. Zhang*, V . Kishore*, F. Wu*, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,” inInternational Conference on Learning Representations, 2020. 5, 6
2020
-
[29]
Clair: Evaluating image captions with large language models,
D. M. Chan, S. Petryk, J. E. Gonzalez, T. Darrell, and J. Canny, “Clair: Evaluating image captions with large language models,” in Proceedings of the EMNLP Conference, 2023. 5, 6
2023
-
[30]
G-veval: a versatile metric for evaluating image and video captions using gpt-4o,
T. C. Tong, S. He, Z. Shao, and D.-Y . Yeung, “G-veval: a versatile metric for evaluating image and video captions using gpt-4o,” in Proceedings of the 39th AAAI Conference on Artificial Intelligence,
-
[31]
Cognitive distraction: Something to think about – lessons learned from recent studies,
B. Hamilton and J. Grabowski, “Cognitive distraction: Something to think about – lessons learned from recent studies,” AAA Foundation for Traffic Safety, Washington, D.C., Tech. Rep., 2013. 8
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.