Retrieve What's Missing: Coverage-Maximizing Retrieval for Consistent Long Video Generation
Pith reviewed 2026-06-28 15:09 UTC · model grok-4.3
The pith
COVRAG retrieves past frames by maximizing residual target-view coverage from depth priors to sustain geometric consistency in long autoregressive video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COVRAG constructs a target-view coverage map from depth estimates produced by pretrained 3D priors; this map serves as lightweight 3D memory evidence that encodes pixel-wise visibility of past observations. Memory frames are then chosen by maximizing residual coverage gain, i.e., the additional target-view area explained by each new frame beyond what the current context and already-selected memories already cover. Sliding-window depth caching maintains efficiency across long sequences, avoiding the maintenance cost of full 3D reconstructions.
What carries the argument
The target-view coverage map (depth-derived pixel-wise visibility mask) together with residual coverage gain maximization for iterative memory-frame selection.
If this is right
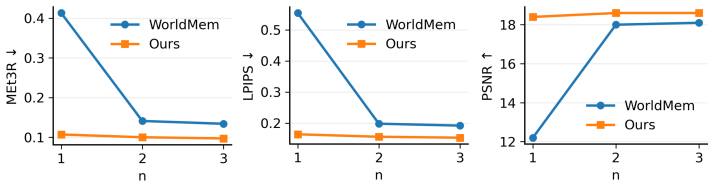
- Long-horizon geometric consistency improves on RealEstate10K and DL3DV10K relative to pose-based and reconstruction-based baselines.
- Latency stays low because sliding-window depth caching avoids repeated full-scene reconstruction.
- Memory selection becomes finer-grained than field-of-view overlap without incurring the storage cost of explicit 3D meshes.
- The same retrieval logic scales to longer rollouts while the coverage map remains lightweight.
Where Pith is reading between the lines
- The coverage-maximization principle could transfer to other autoregressive domains such as 3D scene synthesis or audio where the goal is to retrieve context that fills currently unobserved structure.
- If the coverage map proves reliable, downstream video pipelines might reduce reliance on explicit camera calibration or pose estimation.
- Combining the coverage selector with learned retrieval scores rather than purely geometric gain could further improve results on diverse scene types.
Load-bearing premise
Pretrained 3D priors suffice to construct an accurate target-view coverage map that reasons about pixel-wise visibility without explicit 3D reconstruction or camera poses.
What would settle it
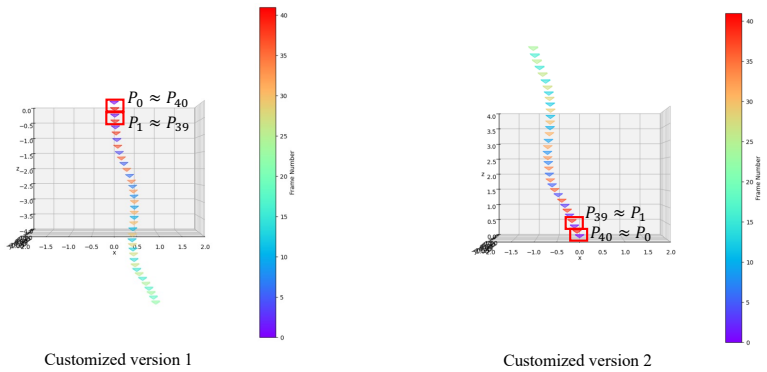
A controlled experiment on RealEstate10K or DL3DV10K in which replacing the coverage-map selector with a simple pose-overlap baseline yields equal or higher geometric-consistency scores and equal or lower latency.
Figures

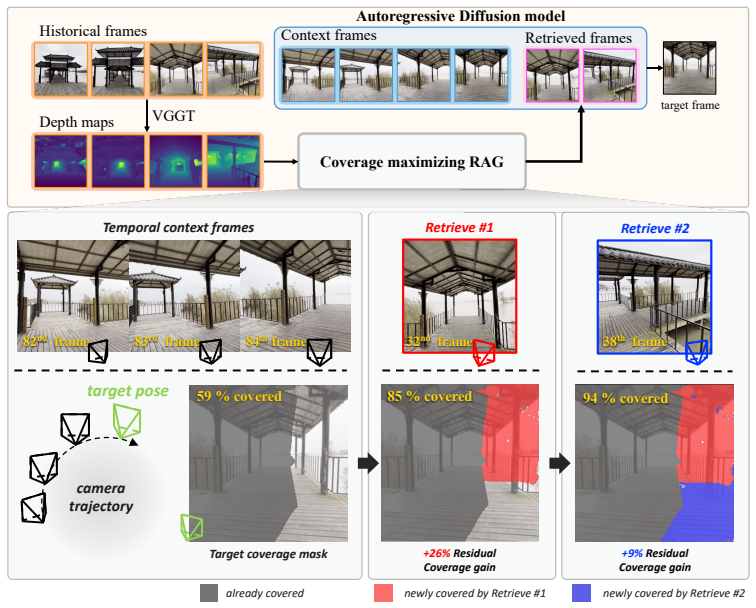

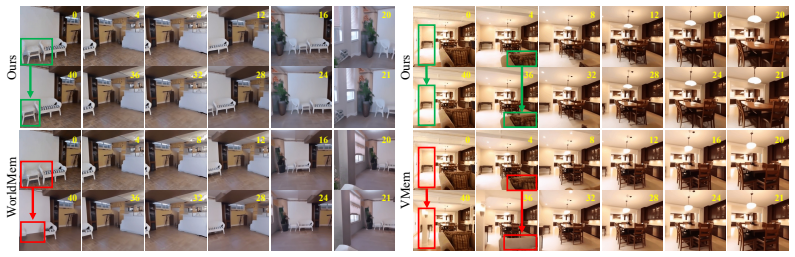

read the original abstract
Maintaining long-term geometric consistency remains challenging for long-horizon autoregressive video generation. Memory-augmented generative models address this by retrieving historical frames, but their effectiveness depends on two key design choices: what 3D-geometric evidence should represent past observations, and how memory frames should be selected from this evidence. Existing methods often rely on camera poses or field-of-view overlap, which are lightweight but too coarse to reason about pixel-wise visibility, or use explicit 3D reconstruction, which provides fine-grained evidence but is costly to maintain over long rollouts. We propose Coverage-Maximizing Retrieval-Augmented Generation (COVRAG), a depth-based memory retrieval framework that uses pretrained 3D priors to construct a target-view coverage map as lightweight 3D memory evidence. For frame selection, COVRAG maximizes residual coverage gain, iteratively retrieving frames that explain target-view regions not covered by the current context or previously selected memories. To improve scalability in long-video generation, we introduce sliding-window depth caching for efficient geometry estimation. Experiments on RealEstate10K and DL3DV10K show that COVRAG improves long-horizon geometric consistency while maintaining low latency compared to baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Coverage-Maximizing Retrieval-Augmented Generation (COVRAG), a depth-based memory retrieval method for autoregressive long video generation. It constructs a target-view coverage map from pretrained 3D priors (monocular depth) as lightweight geometric evidence and selects memory frames by iteratively maximizing residual coverage gain. A sliding-window depth caching scheme is introduced for efficiency. The abstract claims that this yields improved long-horizon geometric consistency on RealEstate10K and DL3DV10K while keeping latency low relative to pose-based or explicit-reconstruction baselines.
Significance. If the coverage map delivers reliable pixel-wise visibility estimates, COVRAG would supply a practical middle ground between coarse pose/FoV heuristics and expensive 3D reconstruction, directly addressing a core bottleneck in memory-augmented video models. The sliding-window caching is a concrete engineering contribution that could transfer to other long-horizon generation pipelines.
major comments (2)
- [Method] Method section (coverage-map construction): the central claim that pretrained monocular depth priors suffice to produce an accurate target-view coverage map for pixel-wise visibility reasoning (without camera poses or explicit reconstruction) is load-bearing for the consistency improvement. No direct validation metric (visibility IoU, boundary error, or occlusion accuracy against ground truth) is supplied to show the map is sufficiently reliable for the residual-coverage-gain objective to outperform coarser alternatives.
- [Experiments] Experiments (RealEstate10K / DL3DV10K results): the abstract asserts quantitative improvements in long-horizon geometric consistency, yet supplies no numerical values, baseline comparisons, error bars, or ablation tables. Without these data the magnitude and attribution of gains to the coverage-maximization step cannot be assessed.
minor comments (1)
- [Abstract] Abstract: the sentence reporting experimental results omits all metrics, making the strength of the empirical claim difficult to gauge at first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [Method] Method section (coverage-map construction): the central claim that pretrained monocular depth priors suffice to produce an accurate target-view coverage map for pixel-wise visibility reasoning (without camera poses or explicit reconstruction) is load-bearing for the consistency improvement. No direct validation metric (visibility IoU, boundary error, or occlusion accuracy against ground truth) is supplied to show the map is sufficiently reliable for the residual-coverage-gain objective to outperform coarser alternatives.
Authors: We agree that an explicit validation of the coverage map would strengthen the central claim. The current manuscript evaluates the map only indirectly via downstream geometric consistency. In the revision we will add a new subsection reporting visibility IoU, boundary error, and occlusion accuracy against ground-truth visibility derived from the datasets' known poses, thereby directly quantifying the reliability of the monocular-depth coverage map. revision: yes
-
Referee: [Experiments] Experiments (RealEstate10K / DL3DV10K results): the abstract asserts quantitative improvements in long-horizon geometric consistency, yet supplies no numerical values, baseline comparisons, error bars, or ablation tables. Without these data the magnitude and attribution of gains to the coverage-maximization step cannot be assessed.
Authors: The experiments section contains the requested quantitative results, including tables with consistency metrics, comparisons against pose-based and reconstruction baselines, error bars from multiple runs, and ablations isolating the coverage-maximization component. To address the abstract's lack of specificity, we will revise the abstract to include key numerical improvements and explicit references to the experimental tables. revision: partial
Circularity Check
No circularity: method uses external pretrained priors and reports empirical gains on held-out data
full rationale
The paper proposes COVRAG as a retrieval framework that constructs a coverage map from off-the-shelf monocular depth estimators and selects frames by maximizing residual coverage gain. No equations are presented that define the coverage map or selection objective in terms of the final consistency metric; the priors are imported from external pretrained models rather than fitted or derived within the paper. Experiments compare against baselines on RealEstate10K and DL3DV10K without any self-referential fitting of the claimed improvement. No self-citation chains or uniqueness theorems are invoked to justify core components. The derivation therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained 3D priors yield reliable per-pixel depth sufficient for visibility reasoning.
Reference graph
Works this paper leans on
-
[1]
Vid- man: Exploiting implicit dynamics from video diffusion model for effective robot manipulation
Youpeng Wen, Junfan Lin, Yi Zhu, Jianhua Han, Hang Xu, Shen Zhao, and Xiaodan Liang. Vid- man: Exploiting implicit dynamics from video diffusion model for effective robot manipulation. InNeural Information Processing Systems, NeurIPS, 2024
2024
-
[2]
Diffusion models for robotic manipulation: A survey.Frontiers in Robotics and AI, 2025
Rosa Wolf, Yitian Shi, Sheng Liu, and Rania Rayyes. Diffusion models for robotic manipulation: A survey.Frontiers in Robotics and AI, 2025
2025
-
[3]
Unisim: A unified simulator for time-coarsened dynamics of biomolecules
Ziyang Yu, Wenbing Huang, and Yang Liu. Unisim: A unified simulator for time-coarsened dynamics of biomolecules. InInternational Conference on Machine Learning, ICML, 2025
2025
-
[4]
Irasim: A fine-grained world model for robot manipulation
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. Irasim: A fine-grained world model for robot manipulation. InComputer Vision and Pattern Recognition, CVPR, 2025
2025
-
[5]
Wonderjourney: Going from anywhere to everywhere
Hong-Xing Yu, Haoyi Duan, Junhwa Hur, Kyle Sargent, Michael Rubinstein, William T Freeman, Forrester Cole, Deqing Sun, Noah Snavely, Jiajun Wu, et al. Wonderjourney: Going from anywhere to everywhere. InComputer Vision and Pattern Recognition, CVPR, 2024
2024
-
[6]
Cameractrl: Enabling camera control for video diffusion models
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for video diffusion models. InInternational Conference on Learning Representations, ICLR, 2025
2025
-
[7]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InInternational Conference on Computer Vision, ICCV, 2025
2025
-
[8]
CAT3D: Create anything in 3d with multi-view diffusion models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. CAT3D: Create anything in 3d with multi-view diffusion models. InNeural Information Processing Systems, NeurIPS, 2024
2024
-
[9]
Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[10]
Wonder- world: Interactive 3d scene generation from a single image
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T Freeman, and Jiajun Wu. Wonder- world: Interactive 3d scene generation from a single image. InComputer Vision and Pattern Recognition, CVPR. IEEE Computer Society, 2025
2025
-
[11]
The matrix: Infinite-horizon world generation with real-time moving control
Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control. InNeural Information Processing Systems, NeurIPS, 2025
2025
-
[12]
Gamefactory: Cre- ating new games with generative interactive videos
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Cre- ating new games with generative interactive videos. InInternational Conference on Computer Vision, ICCV, 2025
2025
-
[13]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. InInternational Conference on Learning Representations, ICLR, 2025
2025
-
[14]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InInternational Conference on Machine Learning, ICML, 2024
2024
-
[15]
WorldMem: Long-term consistent world simulation with memory
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. WorldMem: Long-term consistent world simulation with memory. InNeural Information Processing Systems, NeurIPS, 2025
2025
-
[16]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, 2025. 10
2025
-
[17]
VMem: Consistent interactive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. VMem: Consistent interactive video scene generation with surfel-indexed view memory. InInternational Conference on Computer Vision, ICCV, 2025
2025
-
[18]
Learning world models for interactive video generation
Taiye Chen, Xun Hu, Zihan Ding, and Chi Jin. Learning world models for interactive video generation. InNeural Information Processing Systems, NeurIPS, 2025
2025
-
[19]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tade- vosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InComputer Vision and Pattern Recognition, CVPR, 2025
2025
-
[20]
Xinhang Gao, Junlin Guan, Shuhan Luo, Wenzhuo Li, Guanghuan Tan, and Jiacheng Wang. Memcam: Memory-augmented camera control for consistent video generation.arXiv preprint arXiv:2603.26193, 2026
arXiv 2026
-
[21]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InComputer Vision and Pattern Recognition, CVPR, 2025
2025
-
[22]
History-guided video diffusion
Kiwhan Song, Boyuan Chen, Max Simchowitz, Yilun Du, Russ Tedrake, and Vincent Sitzmann. History-guided video diffusion. InInternational Conference on Machine Learning, ICML, 2025
2025
-
[23]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018
Pith/arXiv arXiv 2018
-
[24]
DL3DV-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. DL3DV-10k: A large-scale scene dataset for deep learning-based 3d vision. InComputer Vision and Pattern Recognition, CVPR, 2024
2024
-
[25]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeural Information Processing Systems, NeurIPS, 2020
2020
-
[26]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, ICLR, 2021
2021
-
[27]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[28]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, ICLR, 2025
2025
-
[29]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[30]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InNeural Information Processing Systems, NeurIPS, 2024
2024
-
[31]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Computer Vision and Pattern Recognition, CVPR, 2025
2025
-
[32]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InNeural Information Processing Systems, NeurIPS, 2025. 11
2025
-
[33]
Diffusion adversarial post-training for one-step video generation
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation. InInternational Conference on Machine Learning, ICML, 2025
2025
-
[34]
Mixture of contexts for long video generation
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, Maneesh Agrawala, Lu Jiang, and Gordon Wetzstein. Mixture of contexts for long video generation. InInternational Conference on Learning Representations, ICLR, 2026
2026
-
[35]
Reconx: Reconstruct any scene from sparse views with video diffusion model
Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, and Yueqi Duan. Reconx: Reconstruct any scene from sparse views with video diffusion model. arXiv preprint arXiv:2408.16767, 2024
arXiv 2024
-
[36]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. InInternational Conference on 3D Vision, 3DV, 2025
2025
-
[37]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InComputer Vision and Pattern Recognition, CVPR, 2025
2025
-
[38]
World-consistent video diffusion with explicit 3d modeling
Qihang Zhang, Shuangfei Zhai, Miguel Angel Bautista Martin, Kevin Miao, Alexander Toshev, Joshua Susskind, and Jiatao Gu. World-consistent video diffusion with explicit 3d modeling. In Computer Vision and Pattern Recognition, CVPR, 2025
2025
-
[39]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, ICLR, 2023
2023
-
[40]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InComputer Vision and Pattern Recognition, CVPR, 2018
2018
-
[41]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 2004
2004
-
[42]
MEt3R: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. MEt3R: Measuring multi-view consistency in generated images. InComputer Vision and Pattern Recognition, CVPR, 2024
2024
-
[43]
DUSt3R: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3d vision made easy. InComputer Vision and Pattern Recognition, CVPR, 2024
2024
-
[44]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InInternational Conference on Computer Vision, ICCV, 2021
2021
-
[45]
Towards accurate generative models of video: A new metric & challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
Pith/arXiv arXiv 2018
-
[46]
GANs trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. InNeural Information Processing Systems, NeurIPS, 2017
2017
-
[47]
Efros, and Angjoo Kanazawa
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InComputer Vision and Pattern Recogni- tion, CVPR, 2025
2025
-
[48]
Jensen (Jinghao) Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models.arXiv preprint arXiv:2503.14489, 2025. 12 A Experimental Details A.1 Baseline Setup We provide additional details on the baseline configurat...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.