Automated Report-Derived Oncology VQA Benchmark for Evaluating Vision-Language Models on 3D Medical Imaging
Pith reviewed 2026-06-28 15:03 UTC · model grok-4.3
The pith
An automated pipeline generates multiple-choice VQA datasets directly from private radiology reports and 3D oncology images without per-question human annotation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an automated pipeline can derive clinically grounded, multiple-choice VQA datasets directly from paired private radiology reports and 3D oncology imaging, yielding an instance-contamination-controlled benchmark without per-question human annotation, and that blind ablation on the resulting data reveals visual reliance to be highly dataset-specific.
What carries the argument
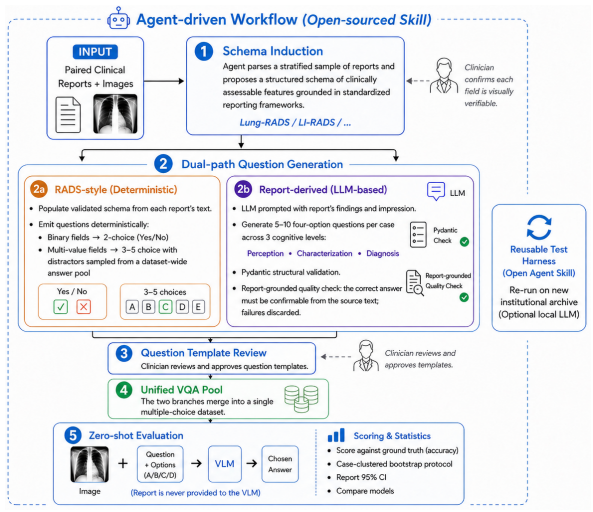
The automated agent-driven pipeline that deterministically extracts RADS-style questions from clinician schemas and uses an LLM to generate report-derived questions verified against the source radiology report.
If this is right
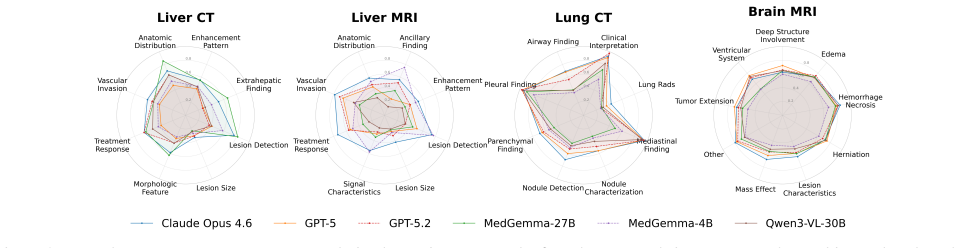
- Zero-shot evaluation across six VLMs shows no dominant model and substantial remaining headroom on all question types and cohorts.
- Blind ablation demonstrates that visual reliance is highly dataset-specific, with liver report-derived questions requiring the image while Lung CT questions are solvable without it.
- The leading closed model exceeds its sighted accuracy on Lung CT when blinded, showing that private clinical data alone does not guarantee a contamination-controlled read of visual capability.
- The pipeline is released as an open agent skill for redeployment on other in-house datasets.
Where Pith is reading between the lines
- Benchmarks for medical VLMs may need routine blind ablations to confirm that questions actually require the image.
- The approach could be extended to other imaging modalities or non-oncology domains where paired reports exist.
- Textual leakage from pretraining may persist even on private data, suggesting the need for stronger verification steps in future pipelines.
Load-bearing premise
That LLM-generated questions verified against the source report, combined with the private nature of the data, produce questions that genuinely test visual capability rather than permitting text-only solutions.
What would settle it
A result in which every evaluated VLM achieves identical accuracy on every dataset when the image is withheld as when the image is provided would falsify the claim that the benchmark isolates visual reliance.
Figures
read the original abstract
Evaluating vision-language models (VLMs) on medical images requires benchmarks that are clinically grounded, scalable, and controlled for evaluation confounds. Existing public benchmarks are limited in scale, manually annotated, or potentially leaked into VLM pretraining corpora. We present an automated agent-driven pipeline that generates multiple-choice VQA datasets directly from paired private radiology reports and 3D oncology imaging, producing two complementary question types: RADS-style questions deterministically derived from clinician-defined reporting schemas, and radiology report-derived questions generated by an LLM from radiologist findings and verified against the source report. Applied to four in-house cancer cohorts, the pipeline yields an instance-contamination-controlled benchmark without per-question human annotation. Zero-shot evaluation of six VLMs reveals no dominant model and substantial headroom across all cells. A blind ablation reveals that visual reliance is highly dataset-specific: liver Report-derived questions genuinely require the image, while Lung CT is essentially solvable without it - the leading closed model exceeds its sighted accuracy on Lung CT when blinded - indicating that even private clinical data does not guarantee a contamination-controlled read of visual capability. The pipeline is released as an open agent skill for in-house redeployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an automated agent-driven pipeline that generates multiple-choice VQA datasets directly from paired private radiology reports and 3D oncology imaging across four in-house cancer cohorts. It produces two question types (RADS-style deterministically derived from reporting schemas and LLM-generated report-derived questions verified against source reports), performs zero-shot evaluation of six VLMs, and reports blind ablations showing dataset-specific visual reliance (e.g., liver questions require the image while Lung CT does not), with the pipeline released as an open agent skill for redeployment.
Significance. If the pipeline details and verification steps can be substantiated, the work provides a scalable, annotation-free approach to creating clinically grounded benchmarks that control for instance contamination from pretraining data. The ablation results, which demonstrate that even private data does not guarantee visual grounding, represent a valuable cautionary finding for VLM evaluation in medical imaging. Explicit release of the pipeline as an open agent skill is a clear strength supporting reproducibility.
major comments (3)
- [Methods] Methods section (pipeline and verification description): the central claim that LLM-generated questions are 'verified against the source report' to produce a clinically grounded benchmark lacks any reported verification accuracy metrics, error analysis, or examples of the verification process; this is load-bearing because the skeptic correctly notes that text-only consistency does not ensure the questions require the 3D image.
- [Results] Results (blind ablation, Lung CT cohort): the finding that the leading closed model exceeds its sighted accuracy when blinded directly shows that report-derived questions for this cohort are solvable without the image, which undermines the abstract's framing of the output as a benchmark that 'genuinely test[s] visual capability' for all cohorts; this requires explicit quantification of how many questions fail the visual-dependence test.
- [Evaluation] Evaluation section: no statistical tests, confidence intervals, or error bars are reported for the VLM accuracy differences or ablation results, which is load-bearing for the claims of 'substantial headroom across all cells' and 'highly dataset-specific' visual reliance.
minor comments (1)
- [Abstract] Abstract: the term 'instance-contamination-controlled' should be defined more precisely to distinguish pretraining leakage from the separate issue of text-only solvability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point-by-point below, indicating planned revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Methods] Methods section (pipeline and verification description): the central claim that LLM-generated questions are 'verified against the source report' to produce a clinically grounded benchmark lacks any reported verification accuracy metrics, error analysis, or examples of the verification process; this is load-bearing because the skeptic correctly notes that text-only consistency does not ensure the questions require the 3D image.
Authors: We agree that the original Methods section provided insufficient detail on the verification step. In revision we will add a dedicated subsection with the exact verification prompt, three concrete examples of LLM-generated questions that were accepted or rejected after checking against the source report, and a description of the manual spot-check process used during pipeline development. We will also explicitly note the limitation that report-consistency verification addresses textual grounding but does not substitute for the blind-ablation evidence of visual dependence. revision: yes
-
Referee: [Results] Results (blind ablation, Lung CT cohort): the finding that the leading closed model exceeds its sighted accuracy when blinded directly shows that report-derived questions for this cohort are solvable without the image, which undermines the abstract's framing of the output as a benchmark that 'genuinely test[s] visual capability' for all cohorts; this requires explicit quantification of how many questions fail the visual-dependence test.
Authors: The Lung CT blind-ablation result is already presented as evidence that visual grounding is not automatic even with private data. We will revise the abstract to state that visual capability is tested in a dataset-specific manner. We will also add a new table (or expanded paragraph) that reports, for each cohort and question type, the fraction of questions for which blind accuracy is within 5 percentage points of sighted accuracy, thereby quantifying how many items fail the visual-dependence criterion. revision: yes
-
Referee: [Evaluation] Evaluation section: no statistical tests, confidence intervals, or error bars are reported for the VLM accuracy differences or ablation results, which is load-bearing for the claims of 'substantial headroom across all cells' and 'highly dataset-specific' visual reliance.
Authors: We accept that uncertainty quantification is needed to support the stated claims. In the revised manuscript we will add bootstrap 95% confidence intervals to all accuracy figures and ablation deltas, and we will include paired statistical comparisons (with p-values) between sighted and blind conditions for the key dataset-specific findings. revision: yes
Circularity Check
No circularity: methods paper with no derivations or fitted predictions
full rationale
This is a methods paper describing an automated pipeline for generating VQA datasets from paired reports and 3D images, with deterministic RADS-style questions and LLM-generated questions verified against source reports. No equations, parameter fittings, predictions, or derivation chains are present in the abstract or described approach. Claims rest on the explicit construction of the pipeline and empirical zero-shot/ablation results rather than any self-referential reduction. Self-citations are not invoked for uniqueness theorems or ansatzes, and the work is self-contained against external benchmarks without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Rajabalifardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley
Mohammad Asadi, Jack W. O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Rajabalifardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. MIRAGE: The illusion of visual understanding. arXiv preprint arXiv:2603.21687, 2026. 1
arXiv 2026
-
[2]
Villanueva-Meyer, Jeffrey D
Evan Calabrese, Javier E. Villanueva-Meyer, Jeffrey D. Rudie, Andreas M. Rauschecker, Ujjwal Baid, Spyridon Bakas, Soon- mee Cha, John T. Mongan, and Christopher P. Hess. The univer- sity of california san francisco preoperative diffuse glioma MRI (UCSF-PDGM) dataset.Radiology: Artificial Intelligence, 4 (6):e220058, 2022. 2
2022
-
[3]
Fowler, Aya Kamaya, Ania Z
Victoria Chernyak, Kathryn J. Fowler, Aya Kamaya, Ania Z. Kielar, Khaled M. Elsayes, Mustafa R. Bashir, Yuko Kono, Richard K. Do, Donald G. Mitchell, Amit G. Singal, An Tang, and Claude B. Sirlin. Liver imaging reporting and data system (LI-RADS) version 2018: Imaging of hepatocellular carcinoma in at-risk patients.Radiology, 289(3):816–830, 2018. 2
2018
-
[4]
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Peng- tao Xie. PathVQA: 30000+ questions for medical visual ques- tion answering.arXiv preprint arXiv:2003.10286, 2020. 1
Pith/arXiv arXiv 2003
-
[5]
OmniMedVQA: A new large-scale comprehensive evaluation benchmark for medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. OmniMedVQA: A new large-scale comprehensive evaluation benchmark for medical LVLM. In CVPR, 2024. 1
2024
-
[6]
Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman
Jason J. Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific Data, 5:180251, 2018. 1
2018
-
[7]
LLaV A-Med: Training a large language-and- vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Hao- tian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. LLaV A-Med: Training a large language-and- vision assistant for biomedicine in one day. InNeurIPS, 2023. 1
2023
-
[8]
SLAKE: A semantically-labeled knowledge- enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. SLAKE: A semantically-labeled knowledge- enhanced dataset for medical visual question answering. In IEEE International Symposium on Biomedical Imaging (ISBI), pages 1650–1654, 2021. 1
2021
-
[9]
Pinsky, David S
Paul F. Pinsky, David S. Gierada, William Black, Reginald Munden, Hrudaya Nath, Denise Aberle, and Ella Kazerooni. Performance of Lung-RADS in the national lung screening trial: A retrospective assessment.Annals of Internal Medicine, 162(7):485–491, 2015. 2
2015
-
[10]
Steiner, Can Kirmizibayrak, Rory Pilgrim, Daniel Golden, and Lin Yang
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C´ıan Hughes, Charles Lau, Justin Chen, Fereshteh Mahvar, Liron Yatziv, Tiffany Chen, Bram Sterling, Ste- fanie Anna Baby, Susanna Maria Baby, Jeremy Lai, Samuel Schmidgall, Lu Yang, Kejia Chen, Per Bjornsson, Shashir Reddy, Ryan...
Pith/arXiv arXiv 2025
-
[11]
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, Basil Mustafa, Aakanksha Chowdhery, Yun Liu, Simon Kornblith, David J. Fleet, Philip Mansfield, Sushant Prakash, Renee Wong, Sunny Virmani, Christopher Semturs, Sara Sara Mahdavi, Bradley Green, Ewa Dominowska, Bla...
arXiv 2024
-
[12]
Wen, David R
Patrick Y . Wen, David R. Macdonald, David A. Reardon, Timo- thy F. Cloughesy, A. Gregory Sorensen, Evanthia Galanis, John DeGroot, Wolfgang Wick, Mark R. Gilbert, Andrew B. Lass- man, Christina Tsien, Tom Mikkelsen, Eric T. Wong, Marc C. Chamberlain, Roger Stupp, Kathleen R. Lamborn, Michael A. V ogelbaum, Martin J. van den Bent, and Susan M. Chang. Upda...
1963
-
[13]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. PMC-VQA: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415, 2023. 1 5
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.