The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Pith reviewed 2026-06-28 10:41 UTC · model grok-4.3
The pith
A global shadow price derived from shifted-surge utility functions optimally allocates limited LLM inference tokens across queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
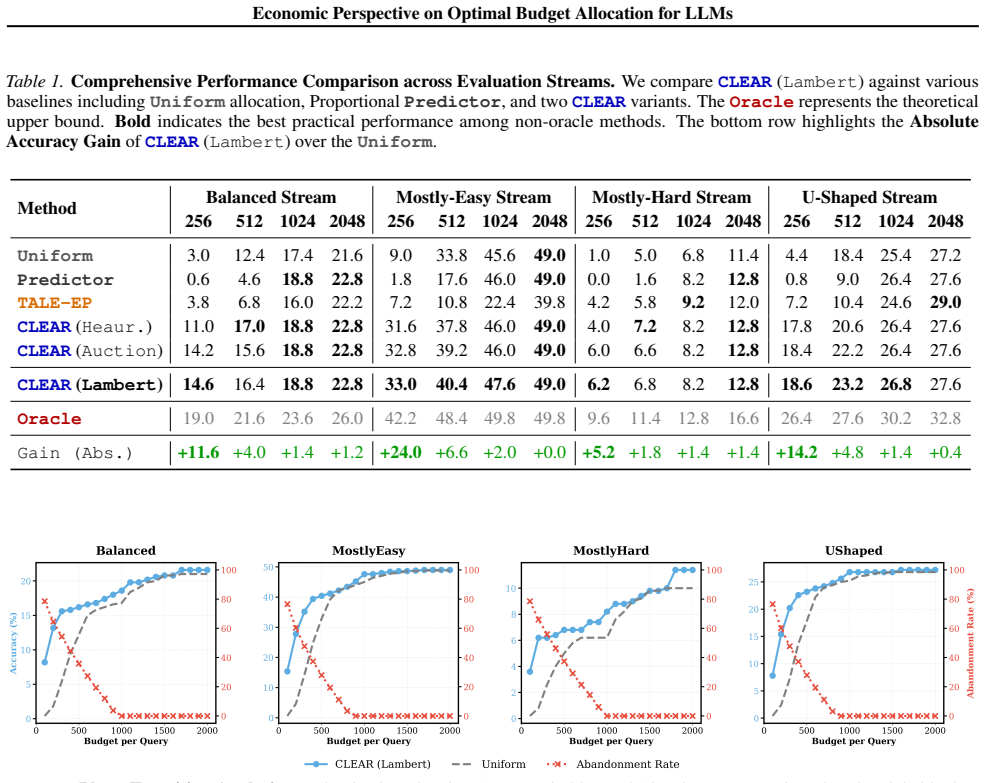
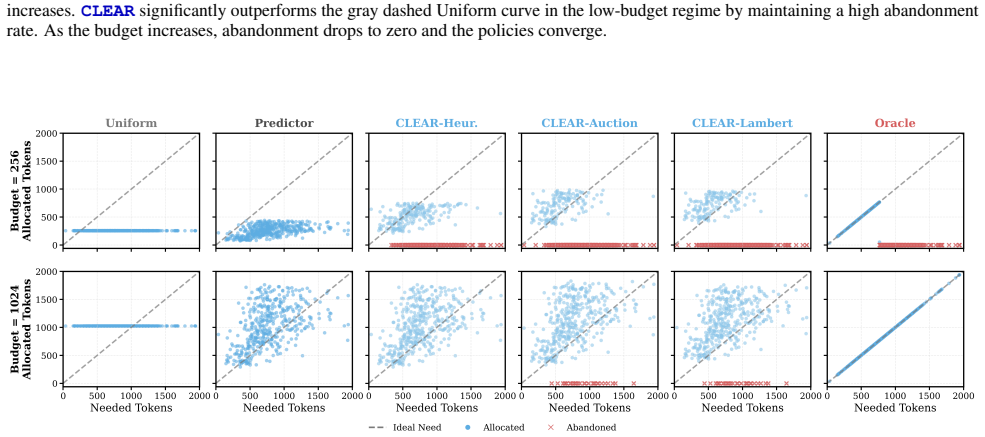
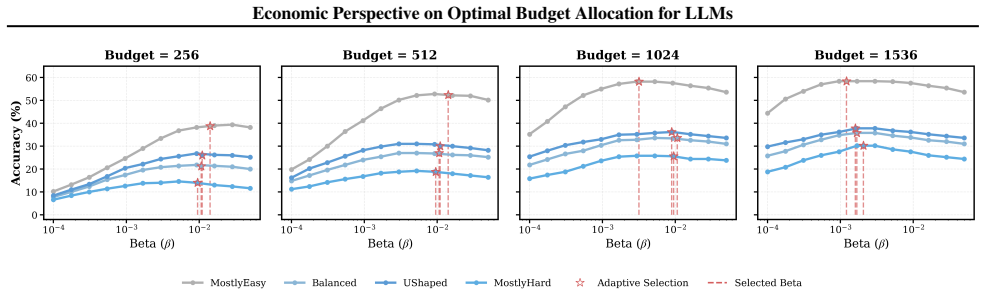
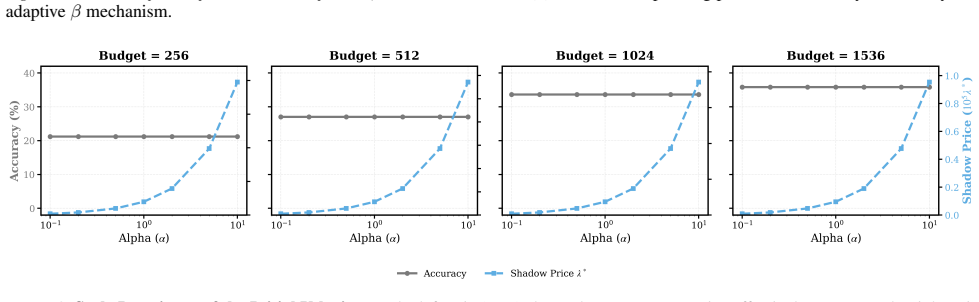
Inference budget allocation is solved by computing a global shadow price that equilibrates marginal utilities under a shifted-surge per-query utility model; the resulting CLEAR policy performs rational abandonment of insolvent queries and reallocates resources to solvable queries near emergence thresholds, producing better total-token versus mean-accuracy trade-offs than uniform allocation.
What carries the argument
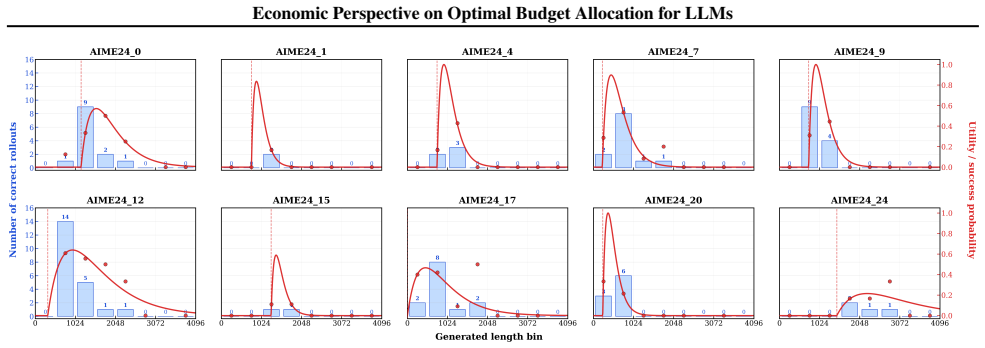
Shifted-surge function modeling per-query reasoning utility, used to derive the global shadow price that equilibrates marginal utilities across queries under scarcity.
If this is right
- CLEAR improves the Pareto frontier between total token cost and mean accuracy on multiple reasoning tasks.
- In resource-scarce regimes the method achieves up to 3x higher global accuracy than uniform allocation.
- Queries unlikely to succeed within budget are rationally abandoned rather than partially funded.
- Resources concentrate on queries near their performance emergence thresholds.
Where Pith is reading between the lines
- The same shadow-price logic could apply to allocating compute across model sizes or serving clusters when query streams vary.
- Accurate prediction of each query's emergence threshold becomes a critical upstream component for any production deployment.
- Periodic recomputation of the shadow price from recent traffic would be required to maintain equilibrium in online settings.
- The framework suggests a natural link to mechanism design if users could report or pay for their own query utilities.
Load-bearing premise
Per-query reasoning utility is accurately captured by a shifted-surge function whose parameters allow derivation of a global shadow price that correctly equilibrates marginal utilities across queries.
What would settle it
An experiment that applies the derived shadow price to a new set of queries and checks whether marginal accuracy gains per token converge to the same value; lack of convergence or failure to recover the reported accuracy improvements would falsify the central claim.
Figures



read the original abstract
Inference-time scaling has emerged as a critical avenue for enhancing Large Language Models' performance, yet real-world deployment is constrained by strict computational budgets. In this work, we formulate inference budget allocation as a global constrained optimization problem governed by economic principles. By modeling per-query reasoning utility with a shifted-surge function, we derive an optimal allocation policy based on a global shadow price that equilibrates marginal utility under resource scarcity. Based on this theory, we propose Constrained Latent-utility Equilibrium Allocation for Reasoning (CLEAR). It performs rational abandonment and reallocates resources from insolvent queries to solvable queries near their emergence thresholds. Extensive experiments on several reasoning tasks with different traffic streams demonstrate that CLEAR significantly improves the Pareto frontier of total token cost versus mean accuracy. In resource-scarce regimes, CLEAR achieves up to a 3x improvement in global accuracy compared to uniform allocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
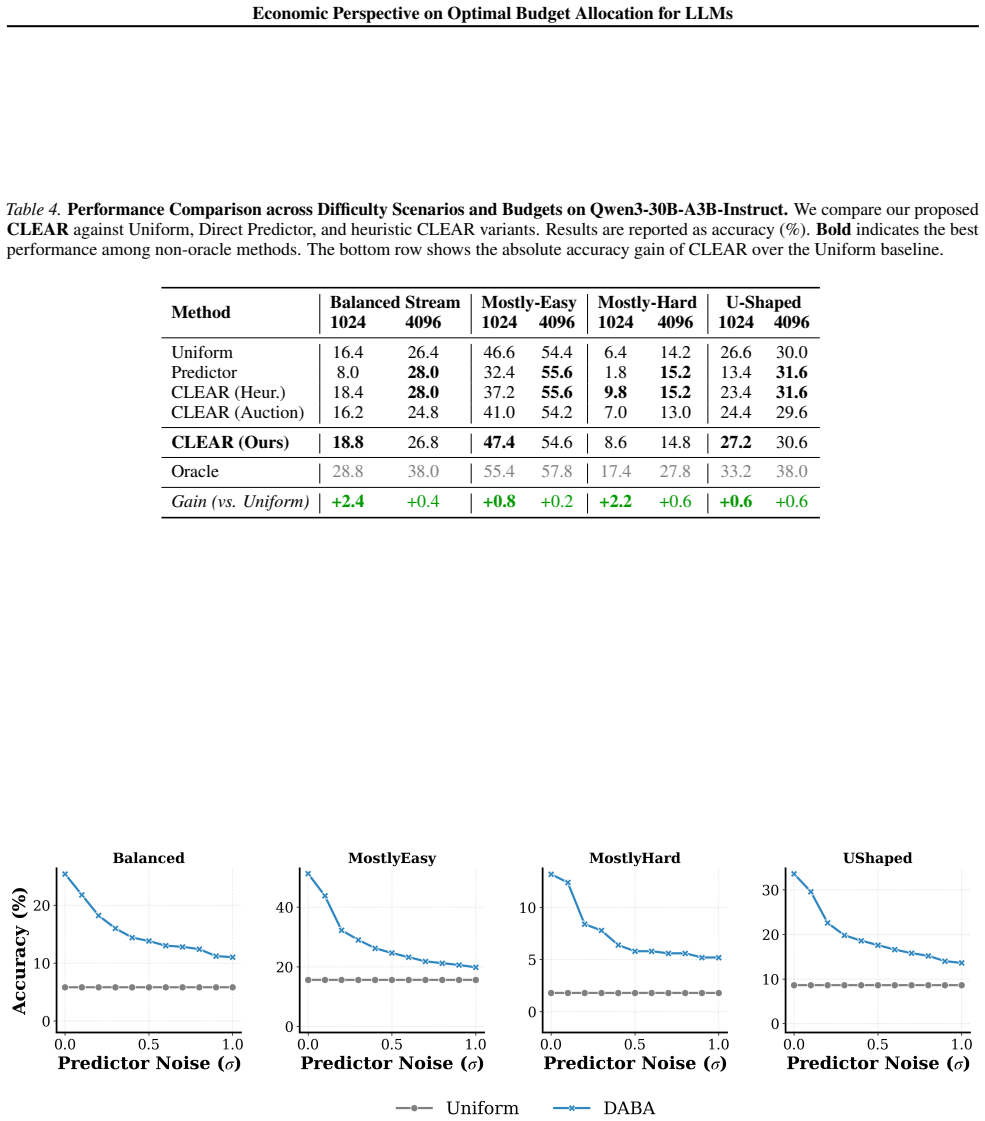
Summary. The paper claims that modeling per-query reasoning utility with a shifted-surge function allows derivation of a global shadow price for optimal inference budget allocation under resource constraints. It introduces the CLEAR algorithm, which performs rational abandonment of insolvent queries and reallocates budget to solvable ones near emergence thresholds. Experiments on multiple reasoning tasks with varying traffic streams show that CLEAR improves the Pareto frontier of total token cost versus mean accuracy and achieves up to 3x improvement in global accuracy compared to uniform allocation in resource-scarce regimes.
Significance. If the modeling assumptions hold, this provides a principled economic framework for inference-time compute allocation in LLMs, potentially enabling more efficient use of limited budgets. The reported quantitative gains (Pareto improvement and 3x accuracy) would be a notable practical contribution if the shifted-surge model is shown to match empirical accuracy-token curves.
major comments (1)
- [Utility modeling section] The shifted-surge utility model is load-bearing for the derivation of the global shadow price and the claimed optimality of CLEAR (see abstract and the section introducing the utility function). The manuscript provides no empirical validation, fitting procedure, or comparison of this functional form against observed accuracy-versus-token curves on the evaluated reasoning tasks. Without such evidence, it is unclear whether the derived shadow price correctly equilibrates marginal utilities, undermining support for the reported accuracy gains.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of empirical grounding for the shifted-surge utility model. We address the major comment below and commit to revisions that strengthen this aspect of the manuscript.
read point-by-point responses
-
Referee: [Utility modeling section] The shifted-surge utility model is load-bearing for the derivation of the global shadow price and the claimed optimality of CLEAR (see abstract and the section introducing the utility function). The manuscript provides no empirical validation, fitting procedure, or comparison of this functional form against observed accuracy-versus-token curves on the evaluated reasoning tasks. Without such evidence, it is unclear whether the derived shadow price correctly equilibrates marginal utilities, undermining support for the reported accuracy gains.
Authors: We agree that the manuscript currently lacks an explicit empirical validation or fitting procedure for the shifted-surge form against the accuracy-token curves from the evaluated tasks. The functional form was chosen because its combination of a fixed shift (modeling initial reasoning overhead) and a surge component (capturing emergence thresholds) admits a closed-form global shadow price that equilibrates marginal utilities under a budget constraint; this enables the rational abandonment and reallocation logic in CLEAR. The reported gains are obtained by applying this policy to real tasks and traffic streams, and they are consistent with the model's qualitative predictions. Nevertheless, to directly address the concern, the revision will add (i) a fitting procedure applied to per-query accuracy-versus-token data from the reasoning benchmarks, (ii) quantitative goodness-of-fit comparisons against alternative specifications (e.g., logistic, power-law), and (iii) a sensitivity analysis showing how deviations from the fitted parameters affect the resulting shadow price and allocation performance. revision: yes
Circularity Check
No significant circularity; derivation is deductive from explicit modeling choice with independent empirical validation
full rationale
The paper states it models per-query reasoning utility via a shifted-surge function as an explicit choice, then deductively derives the global shadow price and CLEAR allocation policy from economic optimization principles. Experiments on reasoning tasks then demonstrate Pareto improvements and accuracy gains. No quotes or equations show the utility form being fitted to evaluation data, results being forced by construction, or load-bearing self-citations. The chain (ansatz → derivation → policy → empirical test) remains self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- shifted-surge function parameters
axioms (1)
- domain assumption Reasoning utility for each query follows a shifted-surge functional form
Reference graph
Works this paper leans on
-
[1]
Teacher-based budget estimation:For each query si, the teacher predicts a raw token need˜τi
-
[2]
Renormalized proportional allocation:The raw esti- mates are converted into per-query caps under the same total budget: ˆttale i = ˜τi PN j=1 ˜τj ·B total.(21) In practice, we apply clipping and integerization: ttale i = clip ˆttale i , t min, t max ,(22) followed by a residual correction step to ensure exact budget conservation: NX i=1 ttale i =B total.(23)
-
[3]
keep the entire response within at most ttale i completion tokens
Budget-conditioned regeneration:For each query si, we construct a budget-aware prompt with a soft instruction (e.g., “keep the entire response within at most ttale i completion tokens”), and run decoding with a hard cap: yi ∼p θ(· |s i, t tale i ),max tokens=t tale i . (24) We use greedy decoding in our setup (temperature= 0,top p= 1). Final accuracy is c...
-
[4]
,ˆτN } and define η= ¯B/E[ ˆT]
Check budget scarcity:Let ˆT={ˆτ 1, . . . ,ˆτN } and define η= ¯B/E[ ˆT] . If η <0.8 , the cutoff rule is activated
-
[5]
Select easier queries:Queries with ˆτi >Median( ˆT) receive zero budget. The remaining queries share the total budget using: theur i = ( µsur +κ·(ˆτ i −µ sur)ifˆτ i ≤Median( ˆT) 0otherwise, (25) where µsur is the mean predicted threshold among se- lected queries, and κ is chosen so that the selected queries use exactlyB total tokens in total. 11 Economic ...
-
[6]
, pN)such thatˆτp1 ≤ · · · ≤ˆτpN
Sort by predicted length:Sort the query indices by increasing predicted threshold, yielding a permutation (p1, . . . , pN)such thatˆτp1 ≤ · · · ≤ˆτpN
-
[7]
Select survivors:Keep the largest prefix of this sorted list whose predicted thresholds fit within the total bud- get: m∗ = max m∈[1, N]| mX j=1 ˆτpj ≤B total .(26)
-
[8]
The selected queries then share the full budget using the same affine allocation rule as CLEAR (Heuristic), rescaled so that P i ti = Btotal
Allocate to survivors:Assign zero budget to all non- selected queries. The selected queries then share the full budget using the same affine allocation rule as CLEAR (Heuristic), rescaled so that P i ti = Btotal. A.2.6.OR A C L EPOLICY This policy is an upper-bound baseline that uses ground- truth solution lengths di, which are unavailable at test time. I...
-
[9]
, oN)such thatd o1 ≤ · · · ≤d oN
Sort by true length:Sort indices into a permutation (o1, . . . , oN)such thatd o1 ≤ · · · ≤d oN
-
[10]
Fill the budget greedily:Allocate exactly doj tokens to each query in sorted order until the next query would exceedB total: toracle oj = ( doj if Pj l=1 dol ≤B total 0otherwise. (27) B. Appendix: More Results To demonstrate the generalizability of our framework to larger-scale reasoning models, we present additional experi- mental results using Qwen3-30B...
-
[11]
Data Generation (Oracle) Backbone Models Qwen2.5-Math-7B, Qwen3-30B-A3B-Instruct Max New Tokens 16,384 (for 30B), 8,192 (for 7B) Decoding Strategy Greedy Decoding (Temperature = 0)
-
[12]
Threshold Predictor Architecture DeBERTa-v3-base (86M parameters) Training Sources GSM8K (Train), MATH (Train) Input Tokenization Left-Truncation (Retain last 512 tokens) Max Sequence Length 512 tokens Training Objective Mean Squared Error (MSE) on Log-Length Optimization AdamW (LR=2e-5, Weight Decay=0.01, Batch=32) Training Schedule 10 Epochs
-
[13]
CLEAR Allocation Mechanism Global Parametersα= 2.0 Optimization Method Bisection Search (40 iterations,ϵ= 1e−6)
-
[14]
Use Case Dataset Split Total Correct Pass@1 Avg
Evaluation Scenarios Sample SizeN= 5,00queries per simulation stream Evaluation Sources MATH-500, OlympiadBench, AIME (24/25), AMC- 23, Minerva Table 6.Detailed Statistics of Training and Evaluation Datasets for Qwen-2.5-math-7B-Instructunder greedy decoding and4Knew token constraints. Use Case Dataset Split Total Correct Pass@1 Avg. Len Threshold Tier Pr...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.