Coherence Maximization Improves Pluralistic Alignment
Pith reviewed 2026-06-28 10:19 UTC · model grok-4.3
The pith
Coherence maximization matches gold labels in pluralistic alignment
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
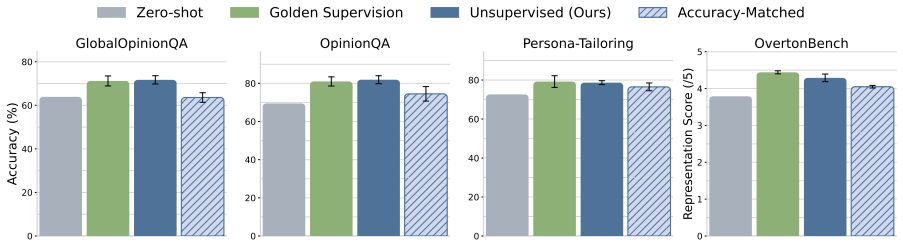
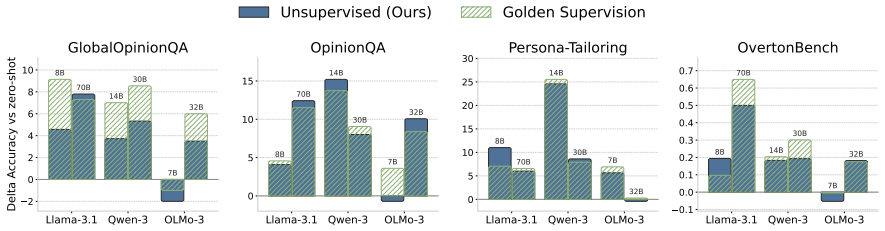
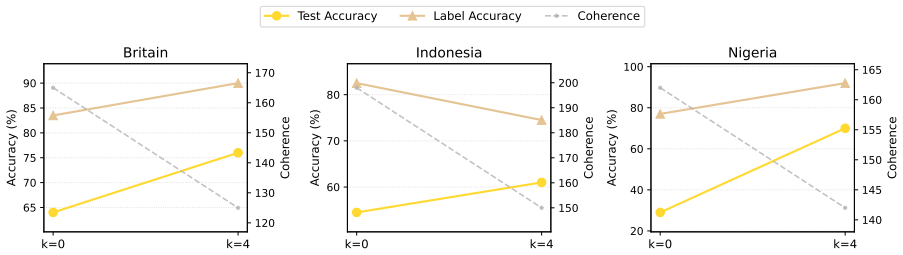
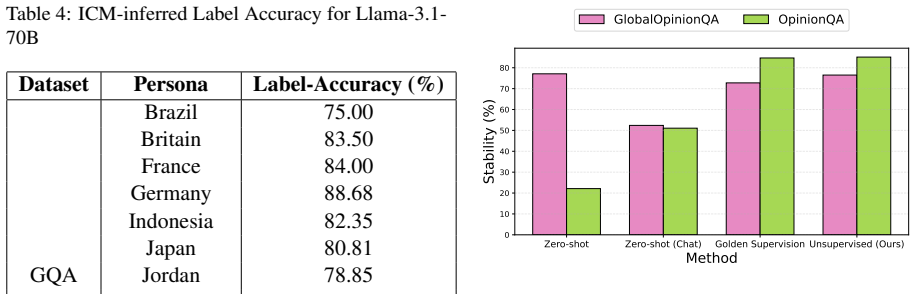
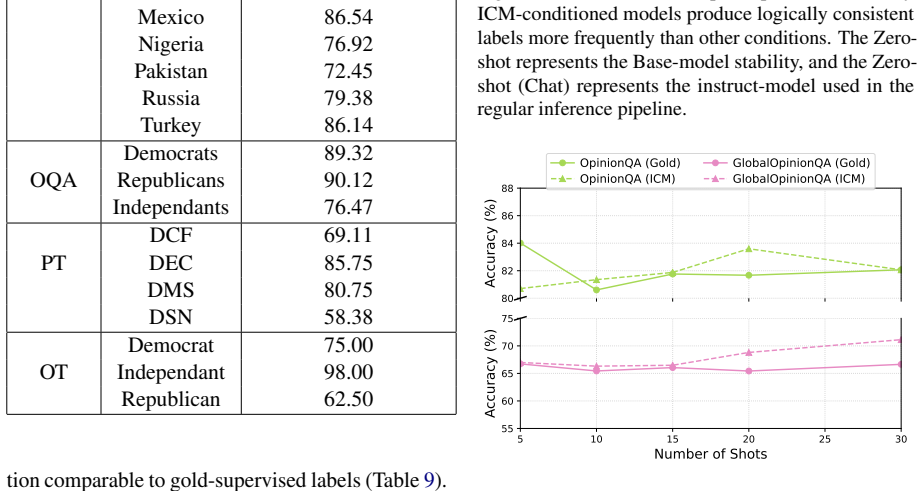
Internal Coherence Maximization infers labels for in-context examples by maximizing their mutual predictability, producing persona-specific examples that steer a model toward a target group's values without human supervision. Across four benchmarks, these examples match the performance of gold labels. Coherence matters beyond individual label accuracy, as more coherent examples generalize substantially better when accuracy is held constant. For underrepresented personas, targeted human feedback on uncertain questions improves generalization over the same number of arbitrary labels.
What carries the argument
Internal Coherence Maximization (ICM), a method that infers labels by maximizing their mutual predictability to create coherent examples for persona alignment.
If this is right
- ICM examples match gold label performance across classification, preference, and generation tasks.
- More coherent examples generalize better than less coherent ones even at equal accuracy.
- Targeted feedback on low-certainty questions benefits alignment for underrepresented personas.
- Coherence is a key design principle for scalable value specification using pretrained models.
Where Pith is reading between the lines
- Alignment pipelines could incorporate coherence checks to improve example quality from any source.
- The findings suggest pretrained models hold extractable knowledge about a wide range of human values.
- This method may apply to specifying values in other domains where multiple perspectives are needed.
Load-bearing premise
Pretrained language models already encode diverse human perspectives that can be extracted via coherence maximization without additional supervision.
What would settle it
An experiment that controls for label accuracy and finds no difference in generalization between high- and low-coherence example sets on the alignment benchmarks.
Figures


read the original abstract
Aligning AI systems with diverse human values requires value specifications grounded in concrete examples, but generating such examples without extensive human supervision remains an open challenge. We investigate what makes these examples effective, using Internal Coherence Maximization (ICM) -- which infers labels by maximizing their mutual predictability -- to generate persona-specific examples that steer a model toward a target group's values, without human supervision. Across four benchmarks spanning classification, preference, and open-ended generation, ICM-inferred in-context examples match the performance of gold labels. Crucially, coherence matters beyond individual label accuracy: with accuracy held constant, more coherent examples generalize substantially better than incoherent ones. For personas underrepresented in pretraining data, targeted human feedback on the questions where the model is least certain about a persona's values yields better generalization than the same number of labels on arbitrary questions. These results identify coherence as a key design principle for scalable value specification, leveraging the diverse human perspectives already encoded in pretrained language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Internal Coherence Maximization (ICM), a method that infers persona-specific labels by maximizing mutual predictability among examples, and evaluates it on four benchmarks covering classification, preference, and open-ended generation tasks. It reports that ICM-generated in-context examples achieve performance matching gold labels, while demonstrating that coherence provides generalization benefits beyond label accuracy when accuracy is held constant via controlled matching. Additional results show that targeted human feedback on low-certainty questions improves outcomes for personas underrepresented in pretraining data.
Significance. If the controlled comparisons hold, the work establishes coherence as a load-bearing design principle for scalable pluralistic alignment, showing that pretrained models can yield effective value specifications without extensive supervision. The accuracy-matched protocol, ablations, and cross-benchmark consistency are explicit strengths that support the central empirical claim without circularity.
minor comments (3)
- §3 (Benchmarks): the accuracy-matching protocol is described as explicit, but the exact procedure for constructing incoherent subsets while preserving per-example accuracy should be stated with pseudocode or a numbered step list to allow direct replication.
- Table 2 (or equivalent results table): report the number of runs, standard deviations, and any statistical tests for the coherence-vs-incoherence generalization gap to quantify the 'substantially better' claim.
- §4.3 (Targeted feedback): clarify how 'least certain' questions are selected (e.g., entropy threshold or ranking) and whether this selection is performed before or after ICM inference.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity; empirical claims rest on external benchmarks and explicit controls
full rationale
The paper's central result—that ICM-generated examples match gold-label performance and that coherence improves generalization when accuracy is held constant—is established through controlled experiments on four external benchmarks (classification, preference, open-ended generation). ICM is defined as maximizing mutual predictability for label inference without reference to the target generalization metric, and the accuracy-matching protocol is described as an explicit post-hoc selection step rather than a definitional identity. No load-bearing self-citation, self-definitional loop, or fitted-input-renamed-as-prediction is present in the provided text; the derivation chain remains self-contained against the reported ablations and external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained language models encode diverse human perspectives that coherence maximization can surface without supervision.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2212.08073 , year=
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[2]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Collective constitutional ai: Aligning a language model with public input , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[3]
Position: Towards Bidirectional Human-AI Alignment , author=
-
[4]
arXiv preprint arXiv:2408.10392 , year=
Value alignment from unstructured text , author=. arXiv preprint arXiv:2408.10392 , year=
-
[5]
Methods in analytical political theory , pages=
Reflective equilibrium , author=. Methods in analytical political theory , pages=. 2017 , publisher=
2017
-
[6]
Truong and Andreas Haupt and Sanmi Koyejo , title =
Sang T. Truong and Andreas Haupt and Sanmi Koyejo , title =. 2025 , publisher =
2025
-
[7]
arXiv preprint arXiv:2404.10271 , year=
Social choice should guide ai alignment in dealing with diverse human feedback , author=. arXiv preprint arXiv:2404.10271 , year=
-
[8]
arXiv preprint arXiv:2402.05070 , year=
A roadmap to pluralistic alignment , author=. arXiv preprint arXiv:2402.05070 , year=
-
[9]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
Randomness, not representation: The unreliability of evaluating cultural alignment in llms , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
2025
-
[10]
arXiv preprint arXiv:2510.26202 , year=
What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data , author=. arXiv preprint arXiv:2510.26202 , year=
-
[11]
arXiv preprint arXiv:2410.14632 , year=
Diverging Preferences: When do Annotators Disagree and do Models Know? , author=. arXiv preprint arXiv:2410.14632 , year=
-
[12]
International Conference on Machine Learning , pages=
Whose opinions do language models reflect? , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[13]
arXiv preprint arXiv:2506.10139 , year=
Unsupervised Elicitation of Language Models , author=. arXiv preprint arXiv:2506.10139 , year=
-
[14]
Nature machine intelligence , volume=
Principles alone cannot guarantee ethical AI , author=. Nature machine intelligence , volume=. 2019 , publisher=
2019
-
[15]
Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pages=
The role and limits of principles in AI ethics: Towards a focus on tensions , author=. Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pages=
2019
-
[16]
Minds and machines , volume=
Artificial intelligence, values, and alignment , author=. Minds and machines , volume=. 2020 , publisher=
2020
-
[17]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[18]
arXiv preprint arXiv:2503.18991 , year=
Inverse reinforcement learning with dynamic reward scaling for llm alignment , author=. arXiv preprint arXiv:2503.18991 , year=
-
[19]
arXiv preprint arXiv:2311.10934 , year=
Case repositories: Towards case-based reasoning for ai alignment , author=. arXiv preprint arXiv:2311.10934 , year=
-
[20]
arXiv preprint arXiv:2501.16448 , year=
What is Harm? Baby Don't Hurt Me! On the Impossibility of Complete Harm Specification in AI Alignment , author=. arXiv preprint arXiv:2501.16448 , year=
-
[21]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Steerable pluralism: Pluralistic alignment via few-shot comparative regression , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[22]
arXiv preprint arXiv:2507.21509 , year=
Persona vectors: Monitoring and controlling character traits in language models , author=. arXiv preprint arXiv:2507.21509 , year=
-
[23]
arXiv preprint arXiv:2511.01689 , year=
Open character training: Shaping the persona of AI assistants through constitutional AI , author=. arXiv preprint arXiv:2511.01689 , year=
-
[24]
arXiv preprint arXiv:2511.02966 , year=
Inference-Time Personalized Alignment with a Few User Preference Queries , author=. arXiv preprint arXiv:2511.02966 , year=
-
[25]
arXiv preprint arXiv:2408.11779 , year=
Personality alignment of large language models , author=. arXiv preprint arXiv:2408.11779 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Self-supervised alignment with mutual information: Learning to follow principles without preference labels , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2509.25369 , year=
Generative value conflicts reveal LLM priorities , author=. arXiv preprint arXiv:2509.25369 , year=
-
[28]
arXiv preprint arXiv:2509.01418 , year=
On the Alignment of Large Language Models with Global Human Opinion , author=. arXiv preprint arXiv:2509.01418 , year=
-
[29]
Statutory Construction and Interpretation for Artificial Intelligence , journal =
He, Luxi and Nadeem, Nimra and Liao, Michel and Chen, Howard and Chen, Danqi and Cuéllar, Mariano-Florentino and Henderson, Peter , year =. Statutory Construction and Interpretation for Artificial Intelligence , journal =
-
[30]
arXiv preprint arXiv:2403.19154 , year=
Star-gate: Teaching language models to ask clarifying questions , author=. arXiv preprint arXiv:2403.19154 , year=
-
[31]
arXiv preprint arXiv:2506.10949 , year=
Monitoring Decomposition Attacks in LLMs with Lightweight Sequential Monitors , author=. arXiv preprint arXiv:2506.10949 , year=
-
[32]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Whose boat does it float? improving personalization in preference tuning via inferred user personas , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
arXiv preprint arXiv:2512.01351 , year=
Benchmarking Overton Pluralism in LLMs , author=. arXiv preprint arXiv:2512.01351 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.