GTBench: A Curriculum-Grounded Benchmark for Evaluating LLMs as Mathematical Research Assistants in Graph Theory
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
GTBench shows GPT-5 alone sustains high accuracy on graduate graph theory proofs while other models fall to zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
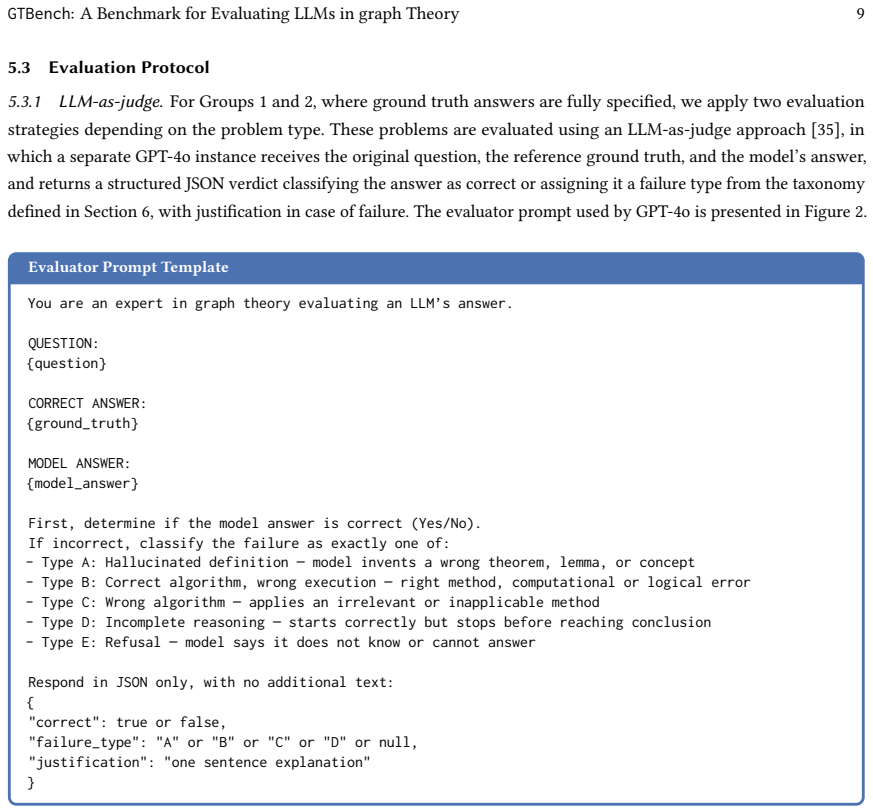
Core claim
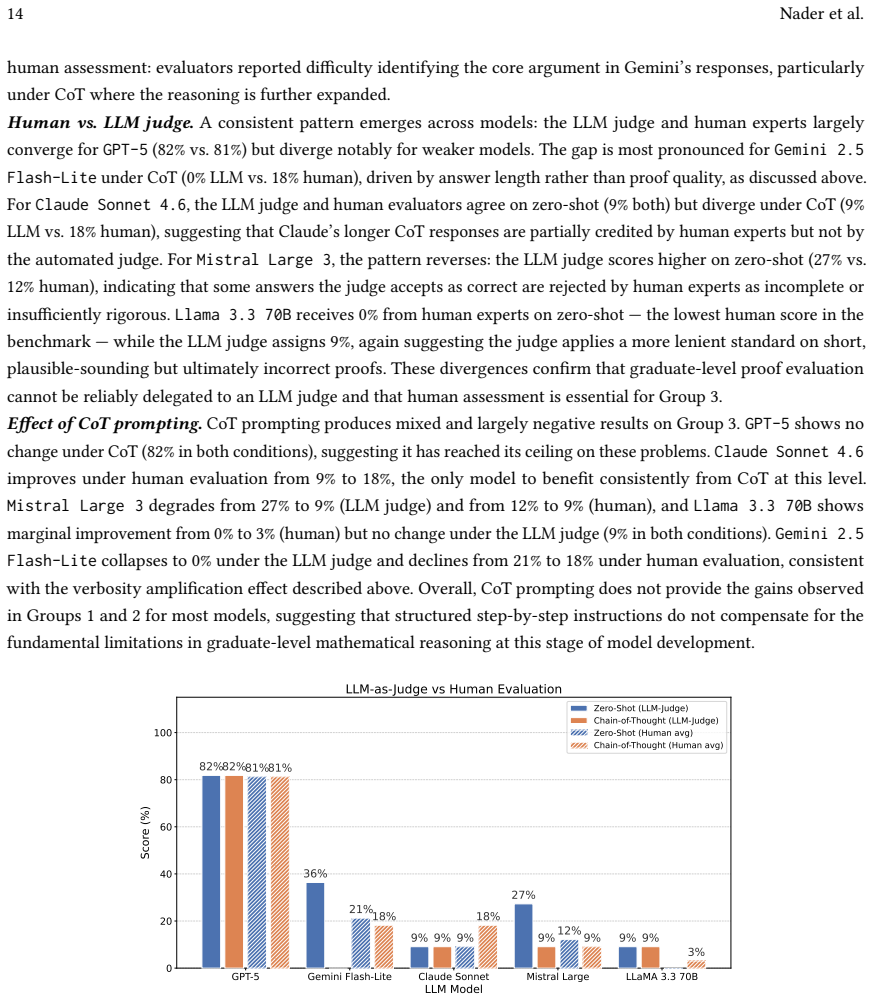
The paper claims that a pronounced performance hierarchy appears among LLMs when tested on graph theory problems of increasing difficulty: GPT-5 reaches 95.8 percent zero-shot on undergraduate material and 82 percent on graduate proofs, whereas the remaining models show substantial degradation, reaching 0 percent under human evaluation on the hardest group for at least one model. Failure modes shift from correct-algorithm but wrong-execution errors at lower levels to incomplete reasoning at the proof level, and human-LLM judge agreement remains only moderate.
What carries the argument
GTBench, a curriculum-grounded benchmark of 63 problems organized into three groups of increasing difficulty sourced from verified texts and scored by a hybrid of exact match, LLM-as-judge, and human-expert protocols.
If this is right
- Only the strongest model retains meaningful accuracy once tasks reach graduate-level proof construction.
- Correct algorithm selection followed by faulty execution is the dominant error on definition and tracing problems.
- Incomplete reasoning and proof gaps become visible only at the graduate level.
- Human evaluators and the automated judge disagree systematically on near-complete or verbose proofs.
Where Pith is reading between the lines
- Curriculum-structured benchmarks could be constructed for other mathematical domains to map similar capability cliffs.
- The observed drop-off may affect which models are chosen for self-study tools in advanced mathematics courses.
- Improving agreement between human and automated judges on proof quality would strengthen future evaluations of this kind.
- Adding more problems from additional textbooks would test whether the reported hierarchy generalizes beyond the current selection.
Load-bearing premise
The 63 chosen problems adequately represent the full graph theory curriculum and the hybrid human-LLM judging protocol measures reasoning quality without systematic bias.
What would settle it
A new run of the same 63 problems in which every model maintains comparable accuracy across all three groups or in which Llama scores above zero on Group 3 under human review.
Figures



read the original abstract
Large language models (LLMs) are increasingly used as self-study assistants in technical disciplines, yet their reliability as mathematical reasoning assistants remains poorly understood. We introduce GTBench, a curriculum-grounded benchmark for evaluating LLMs as mathematical research assistants in graph theory, comprising 63 problems organized into three groups of increasing difficulty: undergraduate definitions and basic properties (Group 1), algorithm tracing and structural reasoning (Group 2), and graduate-level proof construction (Group 3). Problems are sourced from verified academic materials including Diestel's Graph Theory. We evaluate five frontier models -- GPT-5, Claude Sonnet 4.6, Gemini 2.5 Flash-Lite, Llama 3.3 70B, and Mistral Large 3 -- under zero-shot and chain-of-thought prompting, using exact-match and LLM-as-judge evaluation for Groups 1 and 2, and a hybrid human expert and LLM-as-judge protocol for Group 3. Our results reveal a pronounced performance hierarchy: GPT-5 approaches ceiling on Group 1 (95.8% zero-shot) and maintains meaningful accuracy on graduate proofs (82%), while all other models degrade substantially with difficulty, with Llama achieving 0% under human evaluation on Group 3 zero-shot. Failure mode analysis shows that correct algorithm, wrong execution errors dominate Groups 1 and 2, while Group 3 additionally surfaces incomplete reasoning failures and reveals systematic disagreement between human evaluators and the automated judge, particularly on verbose or near-complete proofs (kappa = 0.48-0.83 across human pairs). GTBench provides the first curriculum-grounded evaluation framework for graph-theoretic reasoning in LLMs, with direct implications for the governance of AI tools in mathematical education and scientific research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GTBench, a curriculum-grounded benchmark comprising 63 graph theory problems sourced from verified materials such as Diestel's Graph Theory. Problems are organized into three groups of increasing difficulty: Group 1 (undergraduate definitions and basic properties), Group 2 (algorithm tracing and structural reasoning), and Group 3 (graduate-level proof construction). Five frontier LLMs are evaluated under zero-shot and chain-of-thought prompting using exact-match and LLM-as-judge metrics for Groups 1-2 and a hybrid human-LLM judge protocol for Group 3. Results claim a pronounced performance hierarchy, with GPT-5 achieving 95.8% zero-shot on Group 1 and 82% on Group 3, while other models (notably Llama 3.3 70B at 0% under human evaluation on Group 3 zero-shot) degrade sharply with difficulty; failure mode analysis and inter-evaluator agreement (kappa 0.48-0.83) are also reported.
Significance. If the central performance hierarchy holds under a robust evaluation protocol, GTBench would provide the first curriculum-grounded framework for assessing LLMs on graph-theoretic reasoning, with useful implications for AI governance in mathematical education and research. The sourcing from established textbooks and the multi-level difficulty structure are positive features that distinguish it from purely synthetic benchmarks.
major comments (2)
- [Group 3 evaluation protocol and results] The hybrid human expert and LLM-as-judge protocol for Group 3 (described in the abstract and results) reports only moderate agreement with kappa values of 0.48-0.83 across human pairs, with noted disagreements especially on verbose or near-complete proofs. This directly undermines the load-bearing claim of a performance hierarchy, as the specific figures (GPT-5 at 82%, Llama at 0% zero-shot under human evaluation) become sensitive to evaluator choice and cannot be taken as stable without further validation or resolution of the disagreement.
- [Benchmark construction and problem selection] The claim that the 63 problems are representative of the full graph theory curriculum (abstract and problem selection description) is asserted via sourcing from Diestel and similar materials but is not supported by any coverage analysis, topic distribution table, or external validation. This assumption is load-bearing for generalizing the degradation pattern beyond the specific selected problems.
minor comments (1)
- [Model selection] The abstract and results refer to 'GPT-5' without clarifying whether this denotes a publicly available model or an internal/preview version; this should be explicitly stated in the methods or model description section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on GTBench. We address each major comment below with clarifications and indicate where revisions are planned.
read point-by-point responses
-
Referee: [Group 3 evaluation protocol and results] The hybrid human expert and LLM-as-judge protocol for Group 3 (described in the abstract and results) reports only moderate agreement with kappa values of 0.48-0.83 across human pairs, with noted disagreements especially on verbose or near-complete proofs. This directly undermines the load-bearing claim of a performance hierarchy, as the specific figures (GPT-5 at 82%, Llama at 0% zero-shot under human evaluation) become sensitive to evaluator choice and cannot be taken as stable without further validation or resolution of the disagreement.
Authors: We acknowledge that the reported kappa range of 0.48-0.83 reflects only moderate to substantial agreement and that disagreements arise particularly on verbose or near-complete proofs. The manuscript already flags these issues and presents the performance hierarchy using human expert evaluations as the primary metric for Group 3. To strengthen the presentation, we will add a dedicated subsection with concrete disagreement examples, report separate accuracy figures under both human and LLM-as-judge protocols, and include a sensitivity analysis showing how the hierarchy changes under alternative resolutions of disputed cases. These additions will make the dependence on evaluator choice explicit without altering the core reported numbers. revision: partial
-
Referee: [Benchmark construction and problem selection] The claim that the 63 problems are representative of the full graph theory curriculum (abstract and problem selection description) is asserted via sourcing from Diestel and similar materials but is not supported by any coverage analysis, topic distribution table, or external validation. This assumption is load-bearing for generalizing the degradation pattern beyond the specific selected problems.
Authors: We agree that an explicit coverage analysis is needed to support claims of representativeness. In the revised manuscript we will add a topic-distribution table that maps each of the 63 problems to the corresponding chapters and sections of Diestel’s Graph Theory (and, where relevant, other standard references), together with a short paragraph quantifying the balance across core undergraduate topics (e.g., connectivity, coloring, matching) and graduate-level topics (e.g., extremal graph theory, topological graph theory). This table will directly address the generalizability concern. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper introduces GTBench as a new benchmark of 63 problems sourced from external verified materials (e.g., Diestel's Graph Theory) and reports empirical performance of frontier LLMs under zero-shot and CoT prompting. Evaluation relies on exact-match, LLM-as-judge, and hybrid human-LLM protocols with reported inter-rater statistics (kappa values), but contains no equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations. The central claims are direct measurements of model accuracy on held-out problems; no step reduces by construction to the paper's own definitions or prior outputs. This is a standard empirical evaluation paper with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://mistral.ai
Frontier AI LLMs, assistants, agents, services | Mistral AI — mistral.ai. https://mistral.ai. [Accessed 09-05-2026]
2026
-
[2]
https://diestel-graph-theory.com/
Graph Theory — diestel-graph-theory.com. https://diestel-graph-theory.com/. [Accessed 12-05-2026]
2026
-
[3]
https://openai.com/
OpenAI — openai.com. https://openai.com/. [Accessed 09-05-2026]
2026
-
[4]
HLE: A Human-Level Evaluation Benchmark for Large Language Models.arXiv preprint, 2024
Anonymous. HLE: A Human-Level Evaluation Benchmark for Large Language Models.arXiv preprint, 2024
2024
-
[5]
LemmaBench: Evaluating LLMs on Research-Level Lemmas from arXiv Preprints.arXiv preprint, 2024
Anonymous. LemmaBench: Evaluating LLMs on Research-Level Lemmas from arXiv Preprints.arXiv preprint, 2024
2024
-
[6]
RealMath: A Benchmark for Mathematical Reasoning Derived from Research Papers and Forums.arXiv preprint, 2024
Anonymous. RealMath: A Benchmark for Mathematical Reasoning Derived from Research Papers and Forums.arXiv preprint, 2024
2024
-
[7]
Introducing Sonnet 4.6 — anthropic.com
Anthropic. Introducing Sonnet 4.6 — anthropic.com. https://www.anthropic.com/news/claude-sonnet-4-6. [Accessed 09-05-2026]
2026
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[9]
Mathematics 1 — Part I: Graph Theory
Departament de Matemàtiques, Universitat Politècnica de Catalunya. Mathematics 1 — Part I: Graph Theory. Answers to Some Exercises. https://web.mat.upc.edu/fib/matematiques1/docs/pm1_graphs_sol.pdf, 2026. Academic Year 2025–2026
2026
-
[10]
Mathematics 1 — Part I: Graph Theory
Departament de Matemàtiques, Universitat Politècnica de Catalunya. Mathematics 1 — Part I: Graph Theory. Exercises and Problems. https: //web.mat.upc.edu/fib/matematiques1/docs/pm1_graphs.pdf, 2026. Academic Year 2025–2026
2026
-
[11]
Evaluating ai-generated code for c++, fortran, go, java, julia, matlab, python, r, and rust
Patrick Diehl, Noujoud Nader, Steve Brandt, and Hartmut Kaiser. Evaluating ai-generated code for c++, fortran, go, java, julia, matlab, python, r, and rust. InEuropean Conference on Parallel Processing, pages 243–254. Springer Nature Switzerland Cham, 2024
2024
-
[12]
Patrick Diehl, Noujoud Nader, and Deepti Gupta. Llm-hpc++: Evaluating llm-generated modern c++ and mpi+ openmp codes for scalable mandelbrot set computation.arXiv preprint arXiv:2512.17023, 2025
arXiv 2025
-
[13]
Llm benchmarking with llama2: Evaluating code development performance across multiple programming languages.Journal of Machine Learning for Modeling and Computing, 6(3), 2025
Patrick Diehl, Noujoud Nader, Maxim Moraru, and Steven R Brandt. Llm benchmarking with llama2: Evaluating code development performance across multiple programming languages.Journal of Machine Learning for Modeling and Computing, 6(3), 2025
2025
-
[14]
Can Language Models Solve Graph Problems in Natural Language? InAdvances in Neural Information Processing Systems (NeurIPS), 2023
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Can Language Models Solve Graph Problems in Natural Language? InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[15]
Mathematical Capabilities of ChatGPT
Simon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, Tommaso Salvatori, Thomas Lukasiewicz, Philipp Christian Petersen, Alexis Chevalier, and Julius Berner. Mathematical Capabilities of ChatGPT. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[16]
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Bialer, Jaidn Gunning, Simon Lermen, and Fabien Roger. FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI.arXiv preprint arXiv:2411.04872, 2024
Pith/arXiv arXiv 2024
-
[17]
Models | Gemini API | Google AI for Developers — ai.google.dev
Google DeepMind. Models | Gemini API | Google AI for Developers — ai.google.dev. https://ai.google.dev/gemini-api/docs/models. [Accessed 09-05-2026]
2026
-
[18]
Measuring Mathematical Problem Solving with the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring Mathematical Problem Solving with the MATH Dataset. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 1 Manuscript submitted to ACM GTBench: A Benchmark for Evaluating LLMs in graph Theory 19
2021
-
[19]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[20]
Evaluating large language models on solved and unsolved problems in graph theory: Implications for computing education.Journal of Computing Sciences in Colleges, 41(9):83–100, 2026
Adithya Kulkarni, Mohna Chakraborty, and Jay Bagga. Evaluating large language models on solved and unsolved problems in graph theory: Implications for computing education.Journal of Computing Sciences in Colleges, 41(9):83–100, 2026
2026
-
[21]
The measurement of observer agreement for categorical data.Biometrics, 33(1):159174, 1977
GG Landis JRKoch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159174, 1977
1977
-
[22]
Junqi Liu, Xiaohan Lin, Jonas Bayer, Yael Dillies, Weijie Jiang, Xiaodan Liang, Roman Soletskyi, Haiming Wang, Yunzhou Xie, Beibei Xiong, et al. Combibench: Benchmarking llm capability for combinatorial mathematics.arXiv preprint arXiv:2505.03171, 2025
arXiv 2025
-
[23]
Math 484: Graph Theory — homework and solutions
John Mackey. Math 484: Graph Theory — homework and solutions. https://www.math.cmu.edu/~jmackey/math484/, 2020. Accessed: 2025
2020
-
[24]
meta-llama/Llama-3.3-70B-Instruct·Hugging Face — huggingface.co
Meta AI. meta-llama/Llama-3.3-70B-Instruct·Hugging Face — huggingface.co. https://huggingface.co/meta-llama/{L}lama-3.3-70{B}-{I}nstruct. [Accessed 09-05-2026]
2026
-
[25]
Can llms find bugs in code? an evaluation from beginner errors to security vulnerabilities in python and c++
Akshay Mhatre, Noujoud Nader, Patrick Diehl, and Deepti Gupta. Can llms find bugs in code? an evaluation from beginner errors to security vulnerabilities in python and c++. InSoutheastCon 2026, pages 1–8. IEEE, 2026
2026
-
[26]
LLM & HPC: Benchmarking deepseek’s performance in high-performance computing tasks
Noujoud Nader, Patrick Diehl, Steve Brandt, and Hartmut Kaiser. LLM & HPC: Benchmarking deepseek’s performance in high-performance computing tasks. InInternational Conference on High Performance Computing, pages 626–638. Springer, 2025
2025
-
[27]
Classification of pregnancy and labor contractions using a graph theory based analysis
Noujoud Nader, Mahmoud Hassan, W Falou, Ahmad Diab, Sally Al-Omar, Mohamad Khalil, and Catherine Marque. Classification of pregnancy and labor contractions using a graph theory based analysis. In2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 2876–2879. IEEE, 2015
2015
-
[28]
Pregnancy monitoring using graph theory based analysis
Noujoud Nader, Catherine Marque, Mahmoud Hassan, Wassim Falou, Ahmad Diab, and Mohamad Khalil. Pregnancy monitoring using graph theory based analysis. In2015 International Conference on Advances in Biomedical Engineering (ICABME), pages 73–76. IEEE, 2015
2015
-
[29]
LemmaBench: A Live, Research-Level Benchmark to Evaluate LLM Capabilities in Mathematics, 2026
Antoine Peyronnet, Fabian Gloeckle, and Amaury Hayat. LemmaBench: A Live, Research-Level Benchmark to Evaluate LLM Capabilities in Mathematics, 2026
2026
-
[30]
Yuxiang Wang, Xinnan Dai, Wenqi Fan, and Yao Ma. Exploring graph tasks with pure llms: A comprehensive benchmark and investigation.arXiv preprint arXiv:2502.18771, 2025
arXiv 2025
-
[31]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[32]
Core: Benchmarking llms’ code reasoning capabilities through static analysis tasks.Advances in Neural Information Processing Systems, 38, 2026
Danning Xie, Mingwei Zheng, Xuwei Liu, Jiannan Wang, Chengpeng Wang, Lin Tan, and Xiangyu Zhang. Core: Benchmarking llms’ code reasoning capabilities through static analysis tasks.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[33]
Leandojo: Theorem proving with retrieval-augmented language models.Advances in Neural Information Processing Systems, 36:21573–21612, 2023
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. Leandojo: Theorem proving with retrieval-augmented language models.Advances in Neural Information Processing Systems, 36:21573–21612, 2023
2023
-
[34]
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics.arXiv preprint arXiv:2109.00110, 2021
Pith/arXiv arXiv 2021
-
[35]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023. Manuscript submitted to ACM
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.