ClinicalMC: A Benchmark for Multi-Course Clinical Decision-Making with Large Language Models
Pith reviewed 2026-06-28 10:14 UTC · model grok-4.3
The pith
ClinicalMC supplies 7,079 multi-course clinical samples to test LLMs on decisions that unfold across admission, treatment, and discharge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
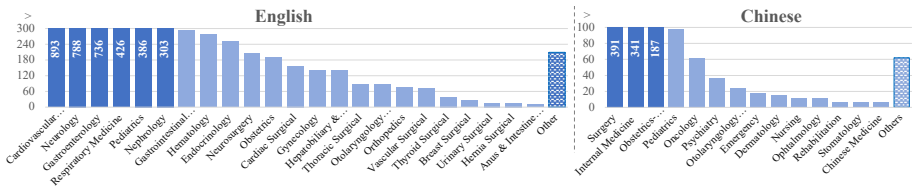
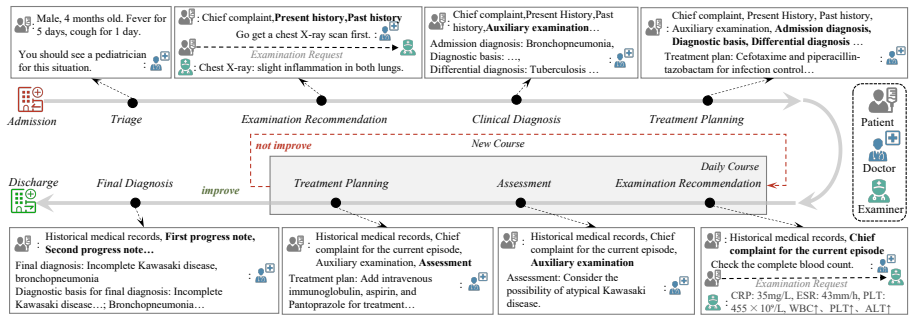
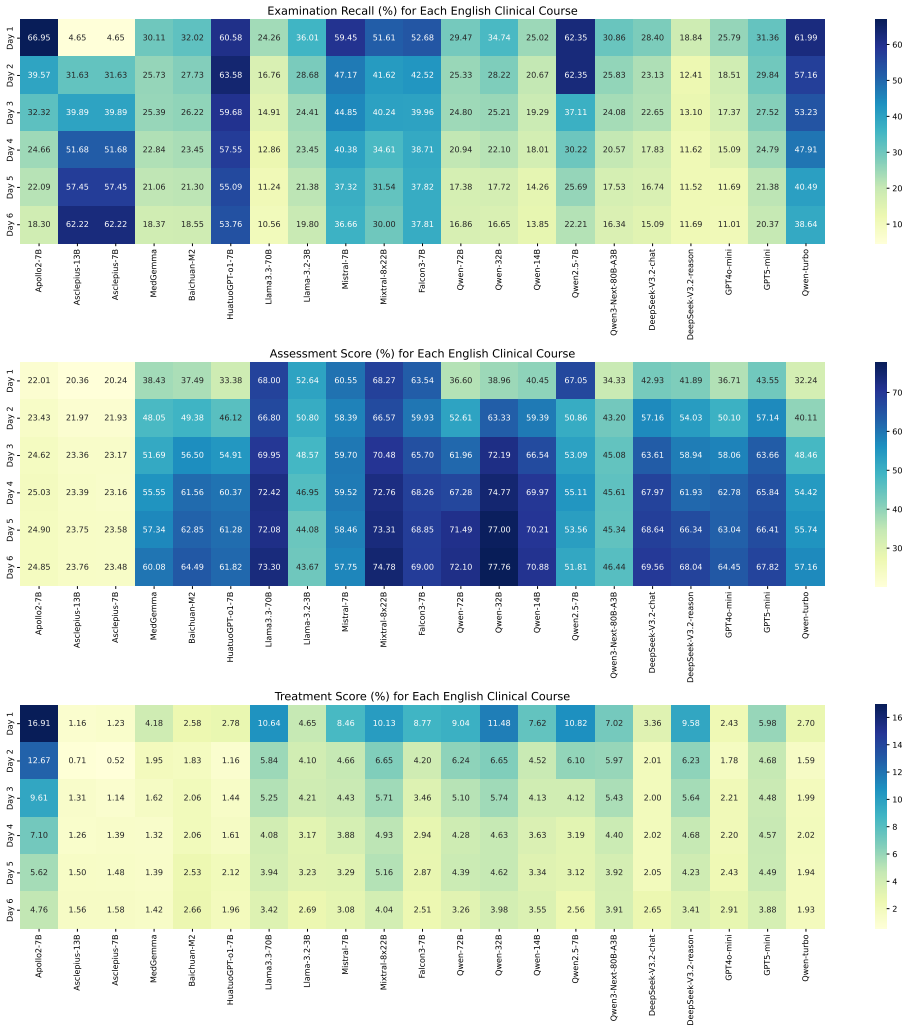
ClinicalMC is a benchmark of 1,275 Chinese and 5,804 English samples that cover four stages of multi-course clinical decision-making from triage through final diagnosis, with English cases averaging 5.11 courses and Chinese cases averaging 3.42 courses; performance is measured through a multi-agent framework of patient, examiner, and doctor agents under both single-turn static and multi-turn dynamic settings.
What carries the argument
The ClinicalMC benchmark together with its multi-agent evaluation framework (patient, examiner, and doctor agents) that generates and scores trajectories across repeated clinical courses.
If this is right
- LLM evaluation can shift from isolated single-encounter tests to repeated interaction across evolving patient states.
- Differences in model performance between static and dynamic settings become measurable for closed-source, open-source, and medical LLMs.
- Deployment decisions for LLMs in healthcare can be informed by results that track the full admission-to-discharge sequence rather than single decisions.
- The benchmark supplies concrete data on how many clinical courses typical patients undergo, enabling more realistic simulation lengths.
Where Pith is reading between the lines
- Training regimes that optimize for multi-turn consistency may become a practical next step for medical LLMs.
- The same multi-agent structure could be adapted to track performance on rare disease pathways or specific specialties once more samples are added.
- If the benchmark scores correlate with real clinical outcomes, regulators could require multi-course testing before approving AI tools for longitudinal care.
Load-bearing premise
The collected samples and the simulated patient-examiner-doctor interactions faithfully represent real multi-course clinical processes without introducing large artificial biases or oversimplifications.
What would settle it
A panel of practicing clinicians reviews a random subset of the benchmark trajectories and reports that a substantial fraction contain medically implausible condition progressions or agent behaviors that do not match observed hospital practice.
Figures












read the original abstract
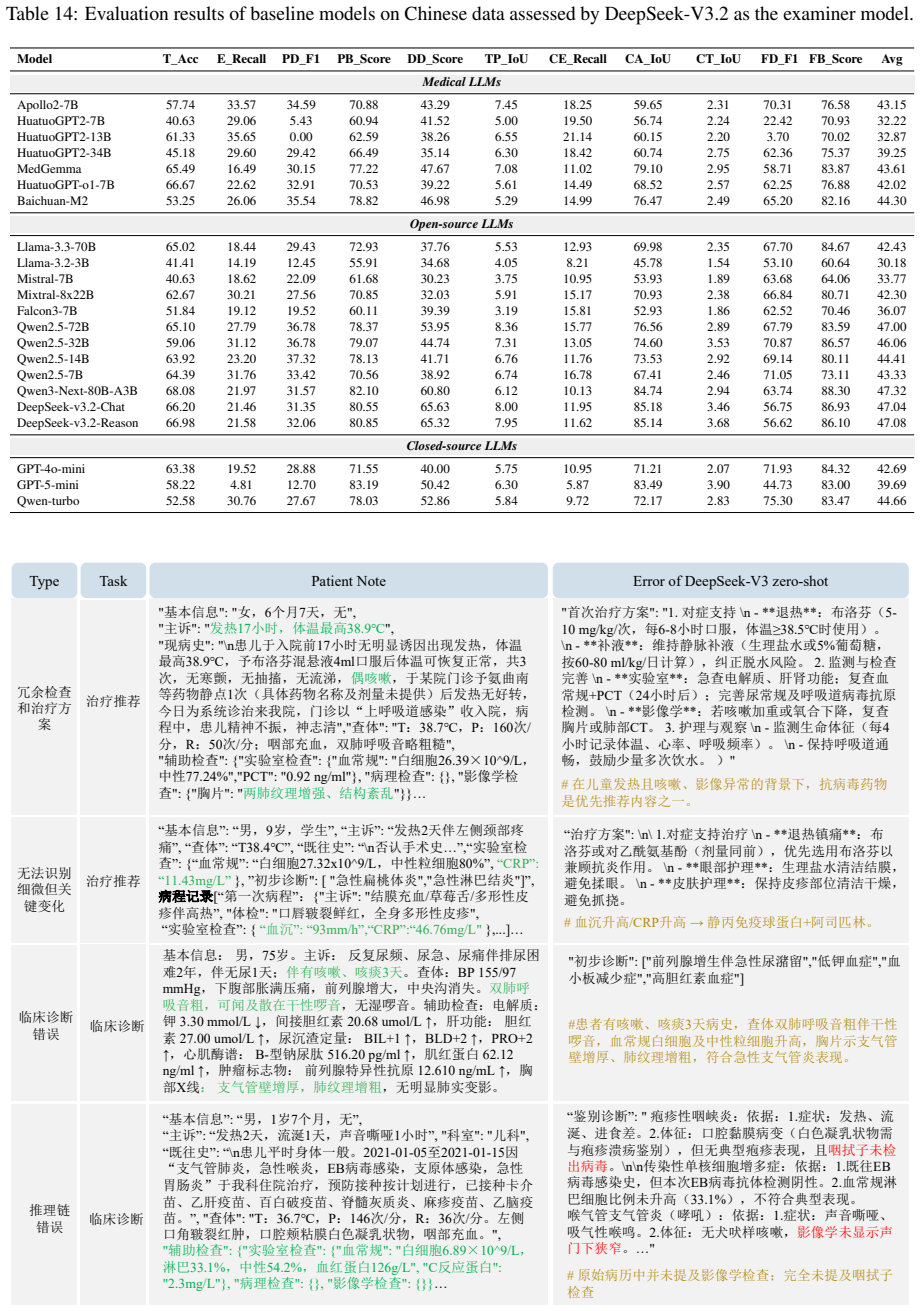
Large language models (LLMs) have been widely adopted in healthcare, yet they still encounter significant challenges in complex clinical decision-making scenarios. Existing benchmarks primarily assess LLM performance in single-course settings and lack systematic evaluation in multi-course scenarios, where a patient's condition evolves over time. To address this gap, we propose ClinicalMC, a benchmark for multi-course clinical decision-making. It includes 1,275 Chinese and 5,804 English samples across four stages from admission to discharge. These stages cover triage, first-course examination/diagnosis/treatment, subsequent multi-course examination/assessment/treatment, and final diagnosis. In ClinicalMC, patients in the English dataset undergo an average of 5.11 clinical courses, whereas those in the Chinese dataset undergo 3.42. To assess LLM performance, we construct a multi-agent evaluation framework that includes patient, examiner, and doctor agents. Based on the benchmark and framework, we design two experimental settings -- a single-turn static setting and a multi-turn dynamic setting -- and assess three categories of LLMs: 1) closed-source LLMs like GPT5-mini; 2) open-source LLMs like DeepSeek-V3.2; and 3) medical LLMs like HuatuoGPT-o1. Through extensive evaluation, we aim to better understand LLM performance in the medical domain and support its effective deployment in healthcare.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ClinicalMC, a benchmark for multi-course clinical decision-making with LLMs. It consists of 1,275 Chinese and 5,804 English samples spanning four stages from admission to discharge (triage; first-course examination/diagnosis/treatment; subsequent multi-course examination/assessment/treatment; final diagnosis), with patients undergoing an average of 3.42 and 5.11 courses respectively. A multi-agent framework (patient, examiner, doctor agents) is proposed to simulate trajectories, and LLMs are evaluated under single-turn static and multi-turn dynamic settings across closed-source, open-source, and medical model categories.
Significance. If the dataset construction and multi-agent simulation prove faithful to real clinical processes, this benchmark would address a clear gap in single-course evaluations and enable more realistic assessment of LLM performance in evolving patient scenarios. The dual-language coverage and explicit multi-turn dynamic setting are strengths that could support safer deployment of LLMs in healthcare. The work also provides a concrete framework for future multi-agent medical evaluations.
major comments (2)
- [Benchmark construction] Benchmark construction section: The manuscript states the sample counts and average course numbers but supplies no information on data sourcing (e.g., real EHR extraction vs. synthetic generation), curation criteria, expert validation, or inter-rater reliability. These details are load-bearing for the central claim that ClinicalMC constitutes a reliable benchmark for multi-course decision-making.
- [Multi-agent evaluation framework] Multi-agent evaluation framework section: The patient/examiner/doctor agent roles are introduced without describing interaction protocols, bias-mitigation steps, or any validation that the simulated trajectories avoid substantial artificial simplifications relative to actual clinical workflows. This directly affects the soundness of both the single-turn and multi-turn experimental settings.
minor comments (2)
- [Abstract] Abstract: The claim of 'extensive evaluation' is made without any quantitative results or performance metrics, which would strengthen the reader's ability to assess the benchmark's utility.
- [Benchmark description] Notation: The four stages are described in prose but would benefit from an explicit table or diagram listing stage definitions and transition rules for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify genuine gaps in the current manuscript regarding the transparency of benchmark construction and the multi-agent simulation protocol. We address each point below and will incorporate the requested details in a revised version.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: The manuscript states the sample counts and average course numbers but supplies no information on data sourcing (e.g., real EHR extraction vs. synthetic generation), curation criteria, expert validation, or inter-rater reliability. These details are load-bearing for the central claim that ClinicalMC constitutes a reliable benchmark for multi-course decision-making.
Authors: We agree that these methodological details are essential for establishing the benchmark's reliability and were insufficiently described. In the revised manuscript we will add a dedicated subsection under Benchmark Construction that specifies: (1) the exact data sources and whether samples were extracted from real EHRs or generated synthetically, (2) the curation criteria and filtering steps applied, (3) the expert validation protocol (including number of clinicians involved and their qualifications), and (4) inter-rater reliability statistics (e.g., Cohen's or Fleiss' kappa). revision: yes
-
Referee: [Multi-agent evaluation framework] Multi-agent evaluation framework section: The patient/examiner/doctor agent roles are introduced without describing interaction protocols, bias-mitigation steps, or any validation that the simulated trajectories avoid substantial artificial simplifications relative to actual clinical workflows. This directly affects the soundness of both the single-turn and multi-turn experimental settings.
Authors: We acknowledge that the current description of the multi-agent framework is high-level and lacks the requested operational details. In the revision we will expand the Multi-agent Evaluation Framework section to include: (1) the precise interaction protocols and turn-taking rules between the patient, examiner, and doctor agents, (2) any bias-mitigation techniques employed (e.g., prompt constraints or role-specific instructions), and (3) validation experiments or qualitative checks demonstrating that the generated trajectories remain faithful to real clinical workflows rather than introducing artificial simplifications. revision: yes
Circularity Check
No significant circularity in benchmark introduction
full rationale
The paper introduces an external benchmark (ClinicalMC) consisting of curated Chinese and English clinical samples across admission-to-discharge stages, together with a multi-agent simulation framework (patient/examiner/doctor agents) and two evaluation settings (single-turn static, multi-turn dynamic). No equations, fitted parameters, or predictive derivations appear; the work does not claim to derive any quantity from its own outputs or from self-citations that would reduce the central claim to a tautology. The contribution is the construction of new test data and an evaluation protocol, which stands as an independent artifact rather than a self-referential computation. This matches the default expectation that benchmark papers are typically non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The multi-agent framework with patient, examiner, and doctor agents provides a valid proxy for real clinical interactions.
- domain assumption The 1,275 Chinese and 5,804 English samples across four stages faithfully represent evolving multi-course patient conditions.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2202.13876 , year=
Pmc-patients: A large-scale dataset of patient summaries and relations for benchmarking retrieval-based clinical decision support systems , author=. arXiv preprint arXiv:2202.13876 , year=
-
[2]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on neural data-to-text generation , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2023 , publisher=
2023
-
[3]
2: Pushing the frontier of open large language models , author=
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
-
[4]
Expert Systems with Applications , pages=
CDAFlow: Enhancing LLM Clinical Decision-Making through Agentic Workflow , author=. Expert Systems with Applications , pages=. 2026 , publisher=
2026
-
[5]
Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes
Kweon, Sunjun and Kim, Junu and Kim, Jiyoun and Im, Sujeong and Cho, Eunbyeol and Bae, Seongsu and Oh, Jungwoo and Lee, Gyubok and Moon, Jong Hak and You, Seng Chan and Baek, Seungjin and Han, Chang Hoon and Jung, Yoon Bin and Jo, Yohan and Choi, Edward. Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes. Findings of the As...
-
[6]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[7]
Scientific data , volume=
MIMIC-III, a freely accessible critical care database , author=. Scientific data , volume=. 2016 , publisher=
2016
-
[8]
Journal of the American Medical Informatics Association , volume=
Evaluating the state-of-the-art in automatic de-identification , author=. Journal of the American Medical Informatics Association , volume=. 2007 , publisher=
2007
-
[9]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[10]
arXiv preprint arXiv:2503.04691 , year=
Quantifying the reasoning abilities of llms on real-world clinical cases , author=. arXiv preprint arXiv:2503.04691 , year=
-
[11]
arXiv preprint arXiv:2406.13890 , year=
ClinicalLab: Aligning Agents for Multi-Departmental Clinical Diagnostics in the Real World , author=. arXiv preprint arXiv:2406.13890 , year=
-
[12]
Nature medicine , volume=
Evaluation and mitigation of the limitations of large language models in clinical decision-making , author=. Nature medicine , volume=. 2024 , publisher=
2024
-
[13]
MedChain: Bridging the Gap Between
Jie Liu and Wenxuan Wang and Zizhan Ma and Guolin Huang and SU Yihang and Kao-Jung Chang and Haoliang Li and Linlin Shen and Michael Lyu and Wenting Chen , booktitle=. MedChain: Bridging the Gap Between. 2025 , url=
2025
-
[14]
AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator
Fan, Zhihao and Wei, Lai and Tang, Jialong and Chen, Wei and Siyuan, Wang and Wei, Zhongyu and Huang, Fei. AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[15]
Nature Medicine , pages=
An evaluation framework for clinical use of large language models in patient interaction tasks , author=. Nature Medicine , pages=. 2025 , publisher=
2025
-
[16]
arXiv preprint arXiv:2503.13205 , year=
Map: Evaluation and multi-agent enhancement of large language models for inpatient pathways , author=. arXiv preprint arXiv:2503.13205 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
MedJourney: Benchmark and Evaluation of Large Language Models over Patient Clinical Journey , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
GLM: General Language Model Pretraining with Autoregressive Blank Infilling , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
arXiv preprint arXiv:2311.16867 , year=
The falcon series of open language models , author=. arXiv preprint arXiv:2311.16867 , year=
-
[20]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[21]
Yi: Open foundation models by 01. ai , author=. arXiv preprint arXiv:2403.04652 , year=
-
[22]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[23]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[24]
arXiv preprint arXiv:2401.04088 , year=
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
-
[25]
Mistral 7B , author=. 2023 , archiveprefix =. 2310.06825 , primaryClass=
Pith/arXiv arXiv 2023
-
[26]
arXiv preprint arXiv:2311.09774 , year=
Huatuogpt-ii, one-stage training for medical adaption of llms , author=. arXiv preprint arXiv:2311.09774 , year=
-
[27]
arXiv preprint arXiv:2410.10626 , year=
Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts , author=. arXiv preprint arXiv:2410.10626 , year=
-
[28]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[29]
Conference on health, inference, and learning , pages=
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering , author=. Conference on health, inference, and learning , pages=. 2022 , organization=
2022
-
[30]
arXiv preprint arXiv:1909.06146 , year=
Pubmedqa: A dataset for biomedical research question answering , author=. arXiv preprint arXiv:1909.06146 , year=
Pith/arXiv arXiv 1909
-
[31]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[32]
arXiv preprint arXiv:2408.10039 , year=
MSDiagnosis: An EMR-based Dataset for Clinical Multi-Step Diagnosis , author=. arXiv preprint arXiv:2408.10039 , year=
-
[33]
arXiv preprint arXiv:2407.13301 , year=
CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis , author=. arXiv preprint arXiv:2407.13301 , year=
-
[34]
2024 , url=
Yubin Kim and Chanwoo Park and Hyewon Jeong and Yik Siu Chan and Xuhai Xu and Daniel McDuff and Hyeonhoon Lee and Marzyeh Ghassemi and Cynthia Breazeal and Hae Won Park , booktitle=. 2024 , url=
2024
-
[35]
M ed A gents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
Tang, Xiangru and Zou, Anni and Zhang, Zhuosheng and Li, Ziming and Zhao, Yilun and Zhang, Xingyao and Cohan, Arman and Gerstein, Mark. M ed A gents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. Findings of the Association for Computational Linguistics ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.33
-
[36]
arXiv preprint arXiv:2405.02957 , year=
Agent hospital: A simulacrum of hospital with evolvable medical agents , author=. arXiv preprint arXiv:2405.02957 , year=
-
[37]
MM ed A gent: Learning to Use Medical Tools with Multi-modal Agent
Li, Binxu and Yan, Tiankai and Pan, Yuanting and Luo, Jie and Ji, Ruiyang and Ding, Jiayuan and Xu, Zhe and Liu, Shilong and Dong, Haoyu and Lin, Zihao and Wang, Yixin. MM ed A gent: Learning to Use Medical Tools with Multi-modal Agent. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.510
-
[38]
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , year =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[39]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[40]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[41]
M ed E ureka: A Medical Domain Benchmark for Multi-Granularity and Multi-Data-Type Embedding-Based Retrieval
Fan, Yongqi and Wang, Nan and Xue, Kui and Liu, Jingping and Ruan, Tong. M ed E ureka: A Medical Domain Benchmark for Multi-Granularity and Multi-Data-Type Embedding-Based Retrieval. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
2025
-
[42]
NPJ digital medicine , volume=
An overview of clinical decision support systems: benefits, risks, and strategies for success , author=. NPJ digital medicine , volume=. 2020 , publisher=
2020
-
[43]
Advances in neural information processing systems , volume=
Learning imbalanced datasets with label-distribution-aware margin loss , author=. Advances in neural information processing systems , volume=
-
[44]
Journal of artificial intelligence research , volume=
SMOTE: synthetic minority over-sampling technique , author=. Journal of artificial intelligence research , volume=
-
[45]
Bowen Wang and Jiuyang Chang and Yiming Qian and Guoxin Chen and Junhao Chen and Zhouqiang Jiang and Jiahao Zhang and Yuta Nakashima and Hajime Nagahara , booktitle=. DiRe
-
[46]
Journal of the American Medical Informatics Association , volume =
Zhan, Zaifu and Zhou, Shuang and Li, Mingchen and Zhang, Rui , title =. Journal of the American Medical Informatics Association , volume =. 2025 , month =. doi:10.1093/jamia/ocaf002 , url =
-
[47]
Proceedings of COLING
Summarizing patients’ problems from hospital progress notes using pre-trained sequence-to-sequence models , author=. Proceedings of COLING. International Conference on Computational Linguistics , volume=
-
[48]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[49]
Scientific data , volume=
MIMIC-IV, a freely accessible electronic health record dataset , author=. Scientific data , volume=. 2023 , publisher=
2023
-
[50]
Canadian journal of statistics , volume=
Beyond kappa: A review of interrater agreement measures , author=. Canadian journal of statistics , volume=. 1999 , publisher=
1999
-
[51]
arXiv preprint arXiv:2507.05201 , year=
Medgemma technical report , author=. arXiv preprint arXiv:2507.05201 , year=
-
[52]
arXiv preprint arXiv:2509.02208 , year=
Baichuan-m2: Scaling medical capability with large verifier system , author=. arXiv preprint arXiv:2509.02208 , year=
-
[53]
Towards Medical Complex Reasoning with LLM s through Medical Verifiable Problems
Chen, Junying and Cai, Zhenyang and Ji, Ke and Wang, Xidong and Liu, Wanlong and Wang, Rongsheng and Wang, Benyou. Towards Medical Complex Reasoning with LLM s through Medical Verifiable Problems. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.751
-
[54]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[55]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.