Combining Statistical Features and Deep Encodings for Rehearsal-Based Class-Incremental Time Series Classification
Pith reviewed 2026-06-28 08:16 UTC · model grok-4.3
The pith
A dual-stream pipeline of statistical features and frozen deep embeddings, paired with rehearsal, supports class-incremental multivariate time series classification with competitive accuracy and low forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a dual-stream feature extraction pipeline combining statistical features with deep temporal embeddings from a pre-trained frozen foundation model, when paired with rehearsal, produces competitive average accuracy and low forgetting rates on five benchmark datasets for class-incremental multivariate time series classification.
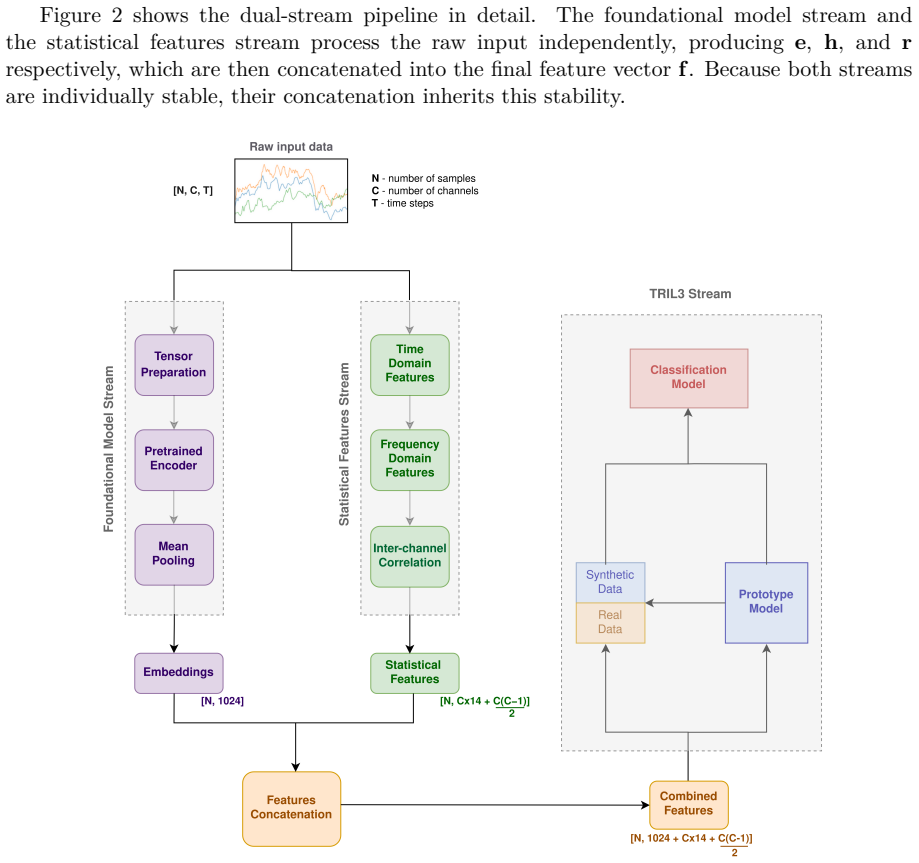
What carries the argument
The dual-stream feature extraction pipeline that merges hand-crafted statistical features with deep temporal embeddings from a frozen pre-trained foundation model, integrated into a rehearsal-based classifier.
If this is right
- New classes can be added without full retraining while preserving earlier classification performance on time series data.
- The approach handles the temporal structure of multivariate series through the combination of statistical summaries and learned embeddings.
- Low forgetting holds across multiple experimental configurations on standard benchmarks.
- Rehearsal remains effective when the feature representation is produced by the dual stream rather than raw inputs.
Where Pith is reading between the lines
- Swapping the foundation model for one trained on a different domain might extend the method to new sensor types without retraining the embedding layer.
- The method could be tested on streaming data where rehearsal buffers must be updated online rather than from fixed task splits.
- Accuracy gains might diminish if the statistical feature set is reduced to a minimal subset, revealing how much each stream contributes.
Load-bearing premise
The dual-stream combination of statistical features and frozen-foundation-model embeddings, when paired with rehearsal, will reliably produce low forgetting without dataset-specific tuning or hidden selection effects in the reported experiments.
What would settle it
An independent re-run on the same five benchmarks that reports substantially higher average forgetting rates for the dual-stream system than for standard rehearsal baselines or single-stream variants.
Figures


read the original abstract
Many systems used in real-world environments require adding new categories and incorporating new information without forgetting what was previously learnt by the classification model. This is known as class-incremental continual learning, and in the case of multivariate time-series, is further complicated by the temporal structure of the data. In this paper, we present a novel approach for performing class incremental continual learning for the classification of multivariate time series data based upon the construction of a dual-stream feature extraction pipeline (using both deep temporal embedding features generated via a pre-trained frozen foundation model and application of statistical features). Evaluated on five benchmark datasets, the proposed system achieves competitive average accuracy across all datasets while maintaining low forgetting rates across all experimental configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a dual-stream feature extraction pipeline for rehearsal-based class-incremental continual learning on multivariate time series. Statistical features are combined with deep temporal embeddings from a pre-trained frozen foundation model; the concatenated representation is used with a rehearsal buffer during incremental training. The central claim is that this yields competitive average accuracy and low forgetting rates across five benchmark datasets and all tested configurations.
Significance. If the empirical results prove robust, the work offers a practical, low-tuning approach to continual learning for time series by leveraging both domain-agnostic statistical descriptors and general-purpose foundation-model embeddings. The combination itself is incremental rather than foundational, but successful validation could inform deployment in settings where retraining is costly and temporal structure must be preserved.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: the reported competitive accuracy and low forgetting are presented without reference to specific baselines (e.g., standard rehearsal, other continual-learning methods for time series), without error bars or variance across runs, and without a clear statement of the incremental protocol (number of classes per task, buffer size selection, train/test splits). These omissions make the central performance claim unverifiable from the supplied text.
- [§3] §3 (Method): the dual-stream concatenation is described at a high level, but the manuscript does not specify how statistical features are scaled relative to the foundation-model embeddings or whether any feature selection occurs before rehearsal; without this, it is impossible to determine whether the low-forgetting result depends on dataset-specific preprocessing choices.
minor comments (2)
- [Abstract] Abstract: the five benchmark datasets are not named, nor is the foundation model identified; adding these details would improve reproducibility.
- [Introduction] Notation: the paper uses “frozen foundation model” without citing the specific architecture or pre-training corpus in the main text; a reference should be added at first mention.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details for improved clarity and verifiability.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: the reported competitive accuracy and low forgetting are presented without reference to specific baselines (e.g., standard rehearsal, other continual-learning methods for time series), without error bars or variance across runs, and without a clear statement of the incremental protocol (number of classes per task, buffer size selection, train/test splits). These omissions make the central performance claim unverifiable from the supplied text.
Authors: We agree that the Experimental Evaluation section requires additional information to substantiate the claims. In the revised manuscript we will add explicit comparisons to standard rehearsal and other continual-learning baselines for time series, report mean accuracy and forgetting with standard deviations across multiple runs (including error bars), and provide a precise description of the incremental protocol covering classes per task, buffer size selection, and train/test splits. revision: yes
-
Referee: [§3] §3 (Method): the dual-stream concatenation is described at a high level, but the manuscript does not specify how statistical features are scaled relative to the foundation-model embeddings or whether any feature selection occurs before rehearsal; without this, it is impossible to determine whether the low-forgetting result depends on dataset-specific preprocessing choices.
Authors: We accept that the current description in §3 lacks these implementation details. The revised version will specify the scaling/normalization applied to statistical features relative to the embeddings and state whether feature selection is performed before concatenation and rehearsal, thereby clarifying that results are not driven by unstated dataset-specific choices. revision: yes
Circularity Check
No significant circularity; empirical method with no derivation chain
full rationale
The paper proposes a dual-stream feature pipeline (statistical features + frozen foundation-model embeddings) combined with standard rehearsal for class-incremental time-series classification. No equations, first-principles derivations, or predictions derived from fitted parameters appear; performance is reported as experimental outcomes on five benchmarks. No self-definitional steps, fitted-input predictions, or load-bearing self-citations are present. The central claim rests on empirical evaluation rather than any closed mathematical reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2403.07815. Sio-Iong Ao and Haytham Fayek. Continual deep learning for time series modeling.Sensors, 23 (16):7167,
-
[2]
doi: 10.1007/s12539-024-00675-2. Marília Barandas, Duarte Folgado, Letícia Fernandes, Sara Santos, Mariana Abreu, Patrí- cia Bota, Hui Liu, Tanja Schultz, and Hugo Gamboa. Tsfel: Time series feature ex- traction library.SoftwareX, 11:100456,
-
[3]
ISSN 2352-7110. doi: https://doi.org/10. 1016/j.softx.2020.100456. URLhttps://www.sciencedirect.com/science/article/pii/ S2352711020300017. Maximilian Christ, Nils Braun, Julius Neuffer, and Andreas W. Kempa-Liehr. Time series fea- ture extraction on basis of scalable hypothesis tests (tsfresh – a python package).Neurocom- puting, 307:72–77,
arXiv 2020
-
[4]
doi: https://doi.org/10.1016/j.neucom.2018.03.067
ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2018.03.067. URLhttps://www.sciencedirect.com/science/article/pii/S0925231218304843. Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting,
-
[5]
URLhttps://arxiv.org/abs/2310.10688. Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gre- gory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE transactions on pattern analysis and machine intelligence, 44(7): 3366–3385,
-
[6]
Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885,
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885,
-
[7]
doi: 10.26555/ijain.v2i1.54. James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526,
-
[8]
URLhttps: //doi.org/10.1038/s41467-021-24483-0
doi: 10.1038/s41467-021-24483-0. URLhttps: //doi.org/10.1038/s41467-021-24483-0. Peter Kontschieder, Madalina Fiterau, Antonio Criminisi, and Samuel Rota Bulo. Deep neural decision forests,
-
[9]
Ashirbad Pradhan, Jiayuan He, and Ning Jiang
doi: 10.1109/PERCOM.2009.4912759. Ashirbad Pradhan, Jiayuan He, and Ning Jiang. Multi-day dataset of forearm and wrist elec- tromyogram for hand gesture recognition and biometrics.Scientific Data, 9:733, 11
-
[10]
doi: 10.1038/s41597-022-01836-y. Zhongzheng Qiao, Quang Pham, Zhen Cao, Hoang H Le, Ponnuthurai N Suganthan, Xudong Jiang, and Savitha Ramasamy. Class-incremental learning for time series: Benchmark and evaluation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5613–5624,
-
[11]
URLhttps://doi.org/10.1007/ s13218-020-00700-8
doi: 10.1007/s13218-020-00700-8. URLhttps://doi.org/10.1007/ s13218-020-00700-8. Siyi Wang, Jiaying Wang, Kunlun Xin, Hexiang Yan, Shuping Li, and Tao Tao. Enhanc- ing real-time urban drainage network modeling through crossformer algorithm and online continual learning.Water Research, 268:122614,
-
[12]
doi: https: //doi.org/10.1016/j.watres.2024.122614
ISSN 0043-1354. doi: https: //doi.org/10.1016/j.watres.2024.122614. URLhttps://www.sciencedirect.com/science/ article/pii/S0043135424015136. Gary Weiss. WISDM Smartphone and Smartwatch Activity and Biometrics Dataset . UCI Machine Learning Repository,
-
[13]
14 Yuanlong Wu, Mingxing Nie, Tao Zhu, Liming Chen, Huansheng Ning, and Yaping Wan
DOI: https://doi.org/10.24432/C5HK59. 14 Yuanlong Wu, Mingxing Nie, Tao Zhu, Liming Chen, Huansheng Ning, and Yaping Wan. Ptms- tscil pre-trained models based class-incremental learning,
-
[14]
Yanan Xiao, Minyu Liu, Zichen Zhang, Lu Jiang, Minghao Yin, and Jianan Wang
URLhttps://arxiv.org/ abs/2503.07153. Yanan Xiao, Minyu Liu, Zichen Zhang, Lu Jiang, Minghao Yin, and Jianan Wang. Streaming traffic flow prediction based on continuous reinforcement learning,
-
[15]
URLhttps:// arxiv.org/abs/2212.12767. Chin-Chia Michael Yeh, Uday Singh Saini, Junpeng Wang, Xin Dai, Xiran Fan, Jiarui Sun, Yujie Fan, and Yan Zheng. Tict: A synthetically pre-trained foundation model for time series classification,
-
[16]
URLhttps://arxiv.org/abs/2511.19694. 15 A Statistical Feature Definitions Letx= [x 1,x 2,...,xT ]denote a single channel of a time series sample of lengthT, and let X= [X 1,X 2,...,X⌊T/2⌋+1]denote its discrete Fourier transform (DFT) coefficients with corre- sponding frequenciesfk, computed at sampling frequencyfs. Table 4: Formal definitions of the stati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.