Lingo_Research_Group at SemEval-2026 Task 9: Evaluating Prompt Variants for Polarization Detection
Pith reviewed 2026-06-28 10:02 UTC · model grok-4.3
The pith
Twelve prompt variants achieve 0.762 macro F1 for binary polarization detection across 22 languages but decline to 0.444 for manifestation identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
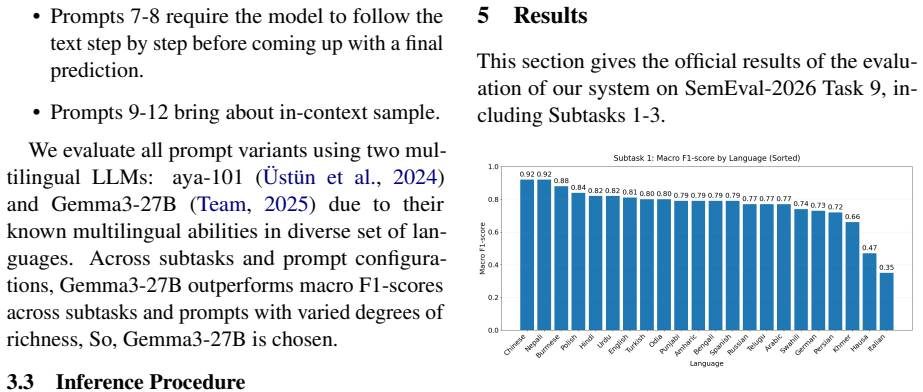
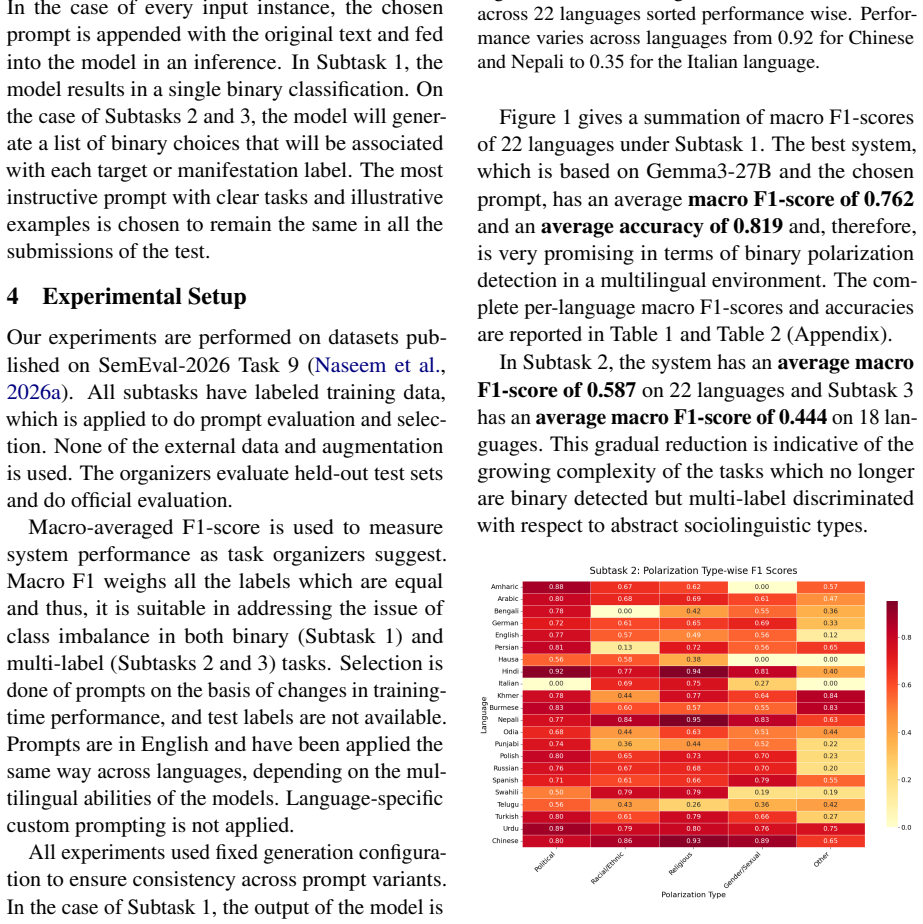
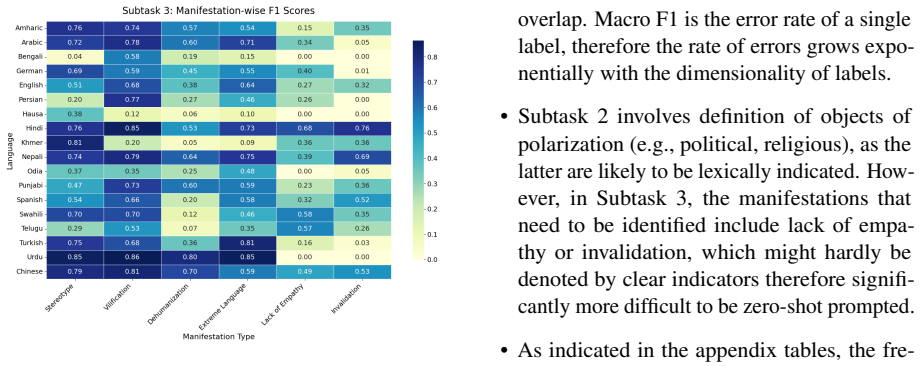
Using the Gemma3-27B model with the best-performing prompt variant, the system reaches average macro F1 scores of 0.762 on subtask 1, 0.587 on subtask 2, and 0.444 on subtask 3, with corresponding accuracies of 0.819, 0.678, and 0.498 on the official test set across 22 languages. Cross-task analysis reveals that prompt methods handle coarse-grained polarization detection effectively yet encounter increasing difficulties with fine-grained and multi-label classification.
What carries the argument
Twelve hand-designed prompts that differ in terminology clarity, definition detail, reasoning guidance, and inclusion of in-context examples.
If this is right
- Binary polarization detection benefits from careful prompt design and reaches usable performance levels.
- Classification accuracy and F1 scores decrease steadily as the subtask requires more detailed polarization type and manifestation labels.
- Prompt approaches remain viable for coarse detection even in a multilingual setting with 22 languages.
- Further refinements in prompt structure are needed to address challenges in fine-grained sociolinguistic tasks.
Where Pith is reading between the lines
- Other multilingual classification problems with similar granularity levels may exhibit comparable prompt sensitivity.
- Testing the same prompt set on additional models could reveal whether the performance pattern is model-dependent or general.
- The observed decline suggests that hybrid approaches combining prompts with other techniques might be required for multi-label cases.
Load-bearing premise
The twelve prompts adequately cover the range of effective instructions and that performance differences arise primarily from prompt properties rather than model quirks or test set features.
What would settle it
Running the same twelve prompts on a new test set or with a different model and observing no consistent drop in performance from subtask 1 to subtask 3 would contradict the claim.
Figures
read the original abstract
Our submission presented in this paper is for SemEval-2026 Task 9: Multilingual Text Classification Challenge - Polarization Detection and it covers all three subtasks: (1) binary polarization detection, (2) polarization type classification and (3) polarization manifestation identification. We adopt a systematic approach of research on short designed prompts by considering twelve designed prompts that are different in terminology clarity, detail of the definition, guidance of reasoning and in-context examples use. The experiments are conducted using aya-101 and Gemma3-27B, with the latter chosen for the submission at the end of the development through performance considerations. Our system has an average macro level F1-score of 0.762 on Subtask 1, 0.587 on Subtask 2 and 0.444 on Subtask 3 with the average accuracy of 0.819, 0.678 and 0.498, respectively, on the official test set averaged among 22 languages, respectively. With cross-task and cross-lingual analysis, we demonstrate that prompt-based approaches can be used effectively to detect coarse grained polarization but encounter more and more difficulties as far as fine-grained and multi-label sociolinguistic classification is concerned.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the Lingo_Research_Group submission to SemEval-2026 Task 9 on multilingual polarization detection across three subtasks: (1) binary polarization detection, (2) polarization type classification, and (3) polarization manifestation identification. The authors evaluate twelve hand-designed prompts that vary in terminology clarity, definition detail, reasoning guidance, and in-context example usage on the aya-101 and Gemma3-27B models, selecting Gemma3-27B for the final submission. They report average macro F1 scores of 0.762 / 0.587 / 0.444 and accuracies of 0.819 / 0.678 / 0.498 on the official test set averaged over 22 languages, and conclude that prompt-based methods work for coarse-grained but not fine-grained polarization detection.
Significance. If the reported official test-set scores hold, the work supplies concrete empirical baselines for prompt-variant evaluation in a multilingual shared task. The systematic variation of twelve prompts and the cross-task/cross-lingual analysis provide modest evidence that prompt design affects coarse- versus fine-grained performance, adding a documented data point to the literature on instruction tuning for sociolinguistic classification.
minor comments (2)
- [Abstract] Abstract: the reported averages across 22 languages do not indicate whether languages are equally weighted or whether per-language variance is reported; adding this detail would strengthen the cross-lingual claim.
- The manuscript would benefit from an appendix containing the exact wording of all twelve prompts to support reproducibility of the prompt-design experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive summary of our submission to SemEval-2026 Task 9 and for the positive assessment of its significance as an empirical baseline for prompt-variant evaluation in multilingual polarization detection. The recommendation of minor revision is noted. However, the report lists no specific major comments under the MAJOR COMMENTS section, so we have no individual points to address.
Circularity Check
No significant circularity
full rationale
The paper is a standard shared-task system description reporting empirical macro F1 and accuracy scores obtained by applying twelve hand-designed prompts to two LLMs on the official blind test set. No equations, derivations, fitted parameters, or predictions are present. No self-citations are used to justify any load-bearing claim. The results stand as direct measurements against external benchmarks and do not reduce to quantities defined by the authors' own choices.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
POLAR: A Benchmark for Multilingual, Multicultural, and Multi-Event Online Polarization , author=. 2026 , eprint=
2026
-
[2]
Polarization Detection on Social Networks: dual contrastive objectives for Self-supervision , year=
Cui, Hang and Abdelzaher, Tarek , booktitle=. Polarization Detection on Social Networks: dual contrastive objectives for Self-supervision , year=. doi:10.1109/CIC62241.2024.00020 , url =
-
[3]
Advances in Neural Information Processing Systems , title =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Others , publisher =. Advances in Neural Information Processing Systems , title =
-
[4]
Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference
Schick, Timo and Sch. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.20
-
[5]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[6]
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 2024. doi:10.18653/v1/2024.acl-long.845
-
[7]
Gemma 3 , url=
Gemma Team , year=. Gemma 3 , url=
-
[8]
2026 , publisher =
Naseem, Usman and Geislinger, Robert and Ren, Juan and Kohail, Sarah and Garrido Veliz, Rudy and Sam Sahil, P and Zhang, Yiran and Stranisci, Marco Antonio and Abdulmumin, Idris and Alacam, Özge and Acarürk, Cengiz and Jabr, Aisha and Anwar, Saba and Ayele, Abinew Ali and Tutubalina, Elena and Htet, Aung Kyaw and Wang, Xintong and Thapa, Surendrabikram an...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.