Enginuity: A Dataset and Benchmark for Vision-Language Understanding of Engineering Diagrams
Pith reviewed 2026-06-28 10:57 UTC · model grok-4.3
The pith
Enginuity is the first open benchmark showing vision-language models identify parts in engineering diagrams but fail to describe them accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
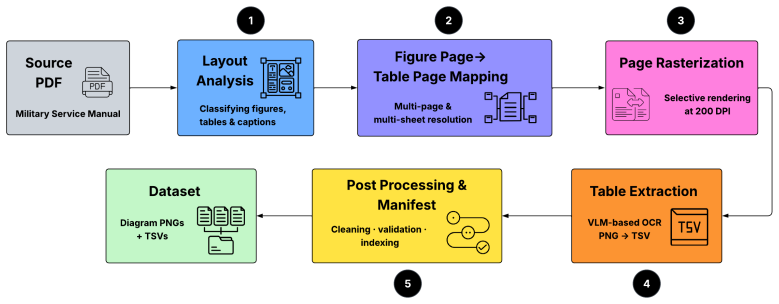
Enginuity supplies the first public dataset and benchmark for vision-language models on complex engineering diagrams, using a corpus of U.S. military manuals to define structured parts-table extraction and free-form visual question answering tasks; evaluations demonstrate that models achieve Recall@all of 0.61-0.87 on part identification yet only 0.03-0.18 Token F1 on description fidelity, with a separate factual-reasoning shortfall on the question-answering task.
What carries the argument
The Enginuity benchmark consisting of annotated engineering diagrams from military manuals, evaluated on parts-table extraction via recall and penalized token F1 plus free-form VQA with LLM-as-judge calibration.
If this is right
- Vision-language models require better mechanisms for linking visual callouts to structured tables in dense diagrams.
- Evaluation of technical descriptions should combine token metrics with semantic similarity measures.
- The released annotations and harness enable direct comparison of future models on the same engineering content.
Where Pith is reading between the lines
- Performance patterns observed here may appear in other diagram-heavy domains such as electrical schematics or process flow diagrams.
- Closing the description-fidelity gap could improve automated assistance for locating replacement parts in service manuals.
- The military-manual source may under-represent civilian or proprietary engineering styles that use different symbol conventions.
Load-bearing premise
The two tasks and the corpus of U.S. military manuals capture the main difficulties that vision-language models face when reading engineering diagrams in actual repair and design work.
What would settle it
A model that reaches token F1 above 0.4 on the parts-table task while preserving high recall, or that eliminates the factual-reasoning gap on the VQA task, would show the reported performance shortfalls are not inherent to current architectures.
Figures
read the original abstract
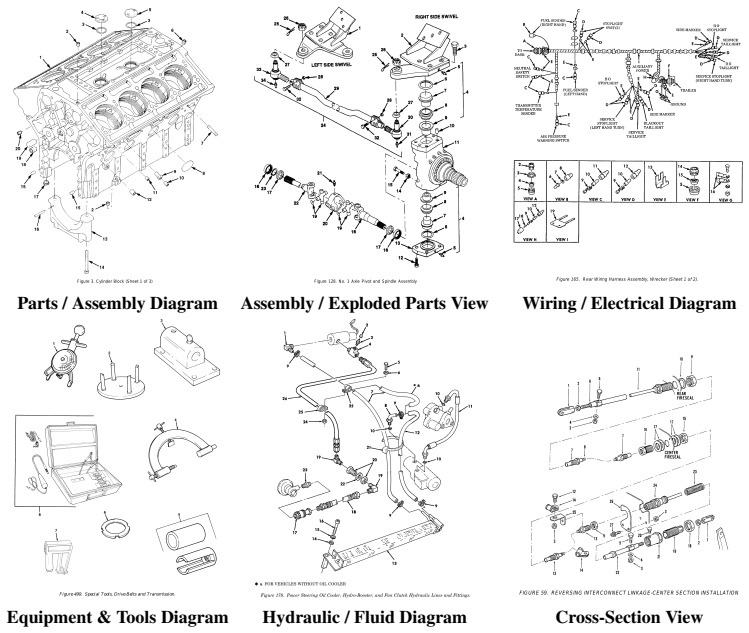
Engineering diagrams pose a distinct challenge for vision-language models: unlike natural images or general documents, they encode information through dense spatial layouts, domain-specific symbols, and cross-references between visual callouts and structured parts tables. Despite their centrality to service, repair, and design workflows, there is no public benchmark for measuring VLM capabilities in this domain; existing datasets primarily focus on flowcharts, scientific figures, or business documents. To address this gap, we introduce Enginuity, the first open dataset and benchmark for evaluating VLMs on complex engineering diagrams. We define two tasks over a corpus of U.S. military service and repair manuals: structured parts-table extraction (Task 1) and free-form visual diagram question answering (VQA)(Task 2) for benchmarking. We evaluate four frontier VLMs (GPT-5.2 Chat, Claude Opus 4.7, Gemma 4, Qwen3-VL-32B-Instruct) under zero-shot and chain-of-thought prompting. On Task 1, models reach Recall@all of 0.61-0.87 but Token F1pen of only 0.03-0.18, exposing a systematic gap between part identification and description fidelity. Task 2 reveals a consistent factual-reasoning gap across all models. A supporting analysis shows that token-overlap metrics under-report model capability on technical descriptions by 2-6x relative to semantic similarity, motivating LLM-as-judge calibration for domain-specific evaluation. We release the dataset, annotations, evaluation harness, and per-sample model outputs to support a reproducible study of VLM capability on engineering content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Enginuity as the first open dataset and benchmark for vision-language models on complex engineering diagrams, drawn from a corpus of U.S. military service and repair manuals. It defines two tasks—structured parts-table extraction (Task 1) and free-form visual diagram question answering (Task 2)—evaluates four frontier VLMs (GPT-5.2 Chat, Claude Opus 4.7, Gemma 4, Qwen3-VL-32B-Instruct) under zero-shot and chain-of-thought prompting, reports quantitative gaps (e.g., Recall@all 0.61-0.87 versus Token F1pen 0.03-0.18 on Task 1; factual-reasoning shortfalls on Task 2), notes that token-overlap metrics under-report capability by 2-6x relative to semantic similarity, and releases the dataset, annotations, evaluation harness, and per-sample outputs.
Significance. If the dataset construction details and corpus representativeness hold, the work supplies a reproducible benchmark that exposes systematic VLM weaknesses in handling dense spatial layouts, domain-specific symbols, and cross-references in technical diagrams. The explicit release of data, annotations, and evaluation code is a clear strength that enables follow-on research and metric calibration studies in this domain.
major comments (3)
- [Dataset description] Dataset description (abstract and § on corpus/tasks): no total number of diagrams, pages, or annotation process (e.g., how parts tables were extracted/verified or VQA questions generated) is provided. This information is load-bearing for assessing whether the reported performance gaps are robust, as the soundness note indicates the abstract alone leaves dataset scale and reliability unverifiable.
- [Introduction and task definition] Introduction and task definition: the choice of U.S. military manuals is presented without any justification, comparison to other engineering diagram types (commercial CAD, P&ID schematics, design-phase drawings), or ablation showing that the observed challenges (dense layouts, symbols, cross-references) are representative. This directly affects the central claim that Enginuity constitutes a benchmark for the domain's core difficulties in real service/repair/design workflows.
- [Evaluation results] Evaluation results: no statistical significance tests, confidence intervals, or variance estimates accompany the model performance numbers (Recall@all, Token F1pen, factual-reasoning gaps). Without these, it is impossible to determine whether the claimed systematic gaps are reliable or could be artifacts of small/unreported sample sizes.
minor comments (2)
- [Abstract] The metric 'Token F1pen' is referenced in the abstract but not defined or expanded in the provided text; a brief definition or pointer to its formulation would improve clarity.
- [Introduction] The claim of 'first open dataset' would benefit from an explicit comparison table against prior diagram/VQA datasets (flowcharts, scientific figures) to substantiate novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Dataset description] Dataset description (abstract and § on corpus/tasks): no total number of diagrams, pages, or annotation process (e.g., how parts tables were extracted/verified or VQA questions generated) is provided. This information is load-bearing for assessing whether the reported performance gaps are robust, as the soundness note indicates the abstract alone leaves dataset scale and reliability unverifiable.
Authors: We agree that the abstract and corpus section lack explicit totals and annotation details. The manuscript does not currently provide the total number of diagrams or pages, nor a full description of the extraction and verification process. We will revise to add these specifics, including dataset scale and annotation methodology, in both the abstract and a dedicated subsection. revision: yes
-
Referee: [Introduction and task definition] Introduction and task definition: the choice of U.S. military manuals is presented without any justification, comparison to other engineering diagram types (commercial CAD, P&ID schematics, design-phase drawings), or ablation showing that the observed challenges (dense layouts, symbols, cross-references) are representative. This directly affects the central claim that Enginuity constitutes a benchmark for the domain's core difficulties in real service/repair/design workflows.
Authors: The manuscript introduces the U.S. military manuals corpus without explicit justification or comparisons to other diagram types. We will add a paragraph in the introduction providing motivation based on the public availability and presence of the targeted challenges, along with a discussion of how these compare to commercial CAD or P&ID diagrams and the resulting scope limitations of the benchmark. revision: yes
-
Referee: [Evaluation results] Evaluation results: no statistical significance tests, confidence intervals, or variance estimates accompany the model performance numbers (Recall@all, Token F1pen, factual-reasoning gaps). Without these, it is impossible to determine whether the claimed systematic gaps are reliable or could be artifacts of small/unreported sample sizes.
Authors: The reported metrics are presented without accompanying statistical measures. We will revise the evaluation section to include bootstrap confidence intervals and per-metric variance estimates computed over the test samples to better substantiate the observed performance gaps. revision: yes
Circularity Check
No circularity: empirical dataset and benchmark release
full rationale
The paper introduces Enginuity as a new dataset and benchmark with two defined tasks (parts-table extraction and VQA) over U.S. military manuals, then reports zero-shot evaluations of existing VLMs. No equations, fitted parameters, predictions, or derivations appear in the provided text. No self-citations are invoked as load-bearing premises for any result. The work is self-contained as an empirical release whose claims rest on the released data and external model outputs rather than any reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
2025
-
[2]
2026 , eprint =
Enginuity: Building an Open Multi-Domain Dataset of Complex Engineering Diagrams , author =. 2026 , eprint =
2026
-
[3]
arXiv preprint arXiv:1910.09700 , year =
Quantifying the Carbon Emissions of Machine Learning , author =. arXiv preprint arXiv:1910.09700 , year =
Pith/arXiv arXiv 1910
-
[4]
Proceedings of the Ninth International Conference on Document Analysis and Recognition (
Smith, Ray , title =. Proceedings of the Ninth International Conference on Document Analysis and Recognition (. 2007 , pages =
2007
-
[5]
MMMU: A Massive Multi-Discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , year=
Yue, Xiang and Ni, Yuansheng and Zheng, Tianyu and Zhang, Kai and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , booktit...
-
[6]
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and Chen, Kai and Lin, Dahua , booktitle=
-
[7]
2021 , eprint=
DocVQA: A Dataset for VQA on Document Images , author=. 2021 , eprint=
2021
-
[8]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[9]
SeePhys: Does Seeing Help Thinking?
Kun Xiang and Heng Li and Terry Jingchen Zhang and Yinya Huang and Zirong Liu and Peixin Qu and Jixi He and Jiaqi Chen and Yu-Jie Yuan and Jianhua Han and Hang Xu and Hanhui Li and Mrinmaya Sachan and Xiaodan Liang , booktitle=. SeePhys: Does Seeing Help Thinking?. 2026 , url=
2026
-
[10]
A Diagram is Worth a Dozen Images
Kembhavi, Aniruddha and Salvato, Mike and Kolve, Eric and Seo, Minjoon and Hajishirzi, Hannaneh and Farhadi, Ali. A Diagram is Worth a Dozen Images. Computer Vision -- ECCV 2016. 2016
2016
-
[11]
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , url =
Lu, Pan and Mishra, Swaroop and Xia, Tanglin and Qiu, Liang and Chang, Kai-Wei and Zhu, Song-Chun and Tafjord, Oyvind and Clark, Peter and Kalyan, Ashwin , booktitle =. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , url =
-
[12]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[13]
Industry
Yifan Li and Yuhang Chen and Anh Dao and Lichi Li and Zhongyi Cai and Zhen Tan and Tianlong Chen and Yu Kong , booktitle=. Industry. 2026 , url=
2026
-
[14]
and Constantini, Dan and Douhard, Willy and Li, Qiwei and Poirier, Louis , booktitle=
Mani, Shouvik and Haddad, Michael A. and Constantini, Dan and Douhard, Willy and Li, Qiwei and Poirier, Louis , booktitle=. Automatic Digitization of Engineering Diagrams using Deep Learning and Graph Search , year=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
An Automated Engineering Assistant: Learning Parsers for Technical Drawings , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i17.17783 , abstractNote=
-
[16]
Minesh Mathew and Viraj Bagal and Rub. InfographicVQA , journal =. 2021 , url =. 2104.12756 , timestamp =
arXiv 2021
-
[17]
Document Understanding Dataset and Evaluation (
Landeghem, Jordy Van and Powalski, Rafał and Tito, Rubèn and Jurkiewicz, Dawid and Blaschko, Matthew and Borchmann, Łukasz and Coustaty, Mickaël and Moens, Sien and Pietruszka, Michał and Ackaert, Bertrand and Stanisławek, Tomasz and Józiak, Paweł and Valveny, Ernest , booktitle=. Document Understanding Dataset and Evaluation (. 2023 , volume=
2023
-
[18]
Proceedings of the 30th ACM International Conference on Multimedia , pages =
Huang, Yupan and Lv, Tengchao and Cui, Lei and Lu, Yutong and Wei, Furu , title =. Proceedings of the 30th ACM International Conference on Multimedia , pages =. 2022 , isbn =. doi:10.1145/3503161.3548112 , abstract =
-
[19]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[20]
F low VQA : Mapping Multimodal Logic in Visual Question Answering with Flowcharts
Singh, Shubhankar and Chaurasia, Purvi and Varun, Yerram and Pandya, Pranshu and Gupta, Vatsal and Gupta, Vivek and Roth, Dan. F low VQA : Mapping Multimodal Logic in Visual Question Answering with Flowcharts. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.78
-
[21]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[22]
Artificial Intelligence Review , volume =
Jamieson, Laura and Moreno-Garcia, Carlos Francisco and Elyan, Eyad , title =. Artificial Intelligence Review , volume =. 2024 , publisher =. doi:10.1007/s10462-024-10779-2 , url =
-
[23]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[24]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[25]
2026 , howpublished =
2026
-
[26]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[27]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.