TrAction: Action Recognition with Sparse Trajectories
Pith reviewed 2026-06-28 10:31 UTC · model grok-4.3
The pith
Sparse point trajectories let action models focus on motion and boost accuracy when fused with appearance features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
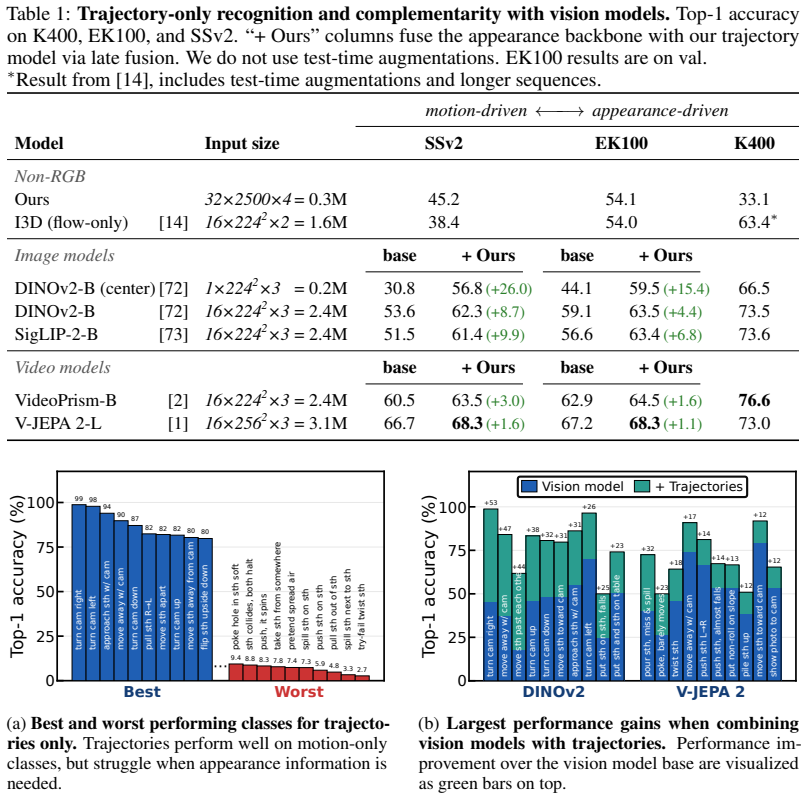
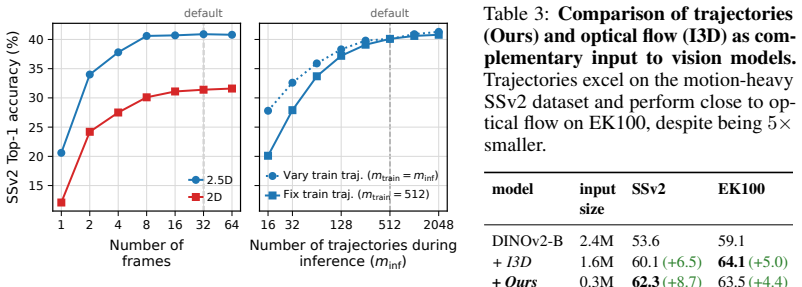
A simple transformer trained on sparse point trajectories with masked pretraining produces motion-focused features that reach competitive accuracy on standard action benchmarks and improve further when fused with appearance-based models, raising top-1 accuracy on Something-Something V2 by 8.7 points over DINOv2 alone and by 1.6 points over V-JEPA 2.
What carries the argument
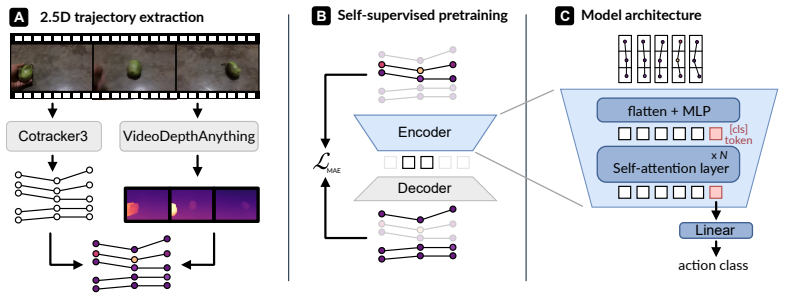
Sparse point trajectories processed by a 2.5D trajectory transformer with masked-trajectory pretraining.
If this is right
- Trajectory features improve time-reversal sensitivity beyond V-JEPA.
- Fusion with DINOv2 yields an 8.7-point gain on Something-Something V2.
- The method uses far less memory and compute than dense RGB volumes.
- Masked pretraining on trajectories measurably raises downstream recognition accuracy.
Where Pith is reading between the lines
- The approach may reduce reliance on large labeled video datasets if trajectory pretraining scales.
- Models built this way could be easier to audit for motion-based decisions rather than object shortcuts.
- The same trajectory stream might support real-time applications on resource-limited devices.
Load-bearing premise
Sparse trajectories supply enough distinctive motion information on their own and remain largely free of appearance shortcuts.
What would settle it
A controlled test in which trajectory-only accuracy collapses on action pairs that differ only by object identity or background while fusion with appearance models yields no gain.
Figures



read the original abstract
Modern action recognition models operate on memory- and compute-intensive dense RGB video volumes and frequently exploit appearance and background shortcuts, for example, predicting actions from objects or scenes instead of characteristic motion. We investigate an efficient alternative input modality that is largely free of such biases by construction: sparse point trajectories. To this end, we develop a simple transformer architecture for 2.5D trajectory-based recognition together with a masked-trajectory pretraining, which we show to substantially improve downstream action recognition accuracy. Despite using only a fraction of the dense RGB input, our method reaches 45% top-1 on Something-Something V2 and 54% on EPIC-Kitchens-100, and surpasses V-JEPA on time-reversal sensitivity. More importantly, we find trajectory features to be complementary to state-of-the-art appearance-based features. Fusing our pretrained model with DINOv2 and V-JEPA 2 improves top-1 accuracy on Something-Something V2 by 8.7 and 1.6 points, respectively. Code: https://github.com/ecker-lab/TrAction
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrAction, a transformer-based architecture operating on sparse 2.5D point trajectories for action recognition, paired with masked-trajectory pretraining. It reports 45% top-1 accuracy on Something-Something V2 and 54% on EPIC-Kitchens-100, claims superiority to V-JEPA on time-reversal sensitivity, and asserts that trajectory features are complementary to appearance-based models, with fusion yielding +8.7 points (DINOv2) and +1.6 points (V-JEPA 2) on SSv2. The core positioning is that trajectories are largely free of appearance/background shortcuts by construction and offer an efficient alternative to dense RGB inputs.
Significance. If the central claims hold, the work provides a computationally lighter motion-centric pathway for action recognition that could complement dense appearance models. The public code release at https://github.com/ecker-lab/TrAction is a clear strength for reproducibility. The reported fusion gains and time-reversal results, if robust, would support the value of trajectory representations in multimodal settings. Significance is limited by the absence of detailed experimental protocols in the provided abstract and the need to substantiate the bias-free assumption.
major comments (1)
- [Abstract] Abstract: The claim that sparse point trajectories are 'largely free of such biases by construction' is load-bearing for interpreting the fusion gains (+8.7 with DINOv2, +1.6 with V-JEPA 2) as evidence of orthogonal motion features rather than an ensemble effect. Standard RGB-based trajectory extraction (optical flow or learned trackers) can retain appearance cues via consistent pixel tracking; the manuscript must supply explicit controls (e.g., object-category prediction from trajectories alone or background-masked variants) to support the assumption.
minor comments (2)
- [Abstract] Abstract: Concrete accuracy numbers (45% SSv2, 54% EPIC-Kitchens) are stated without error bars, number of runs, or ablation details on the pretraining or fusion protocol.
- [Abstract] Abstract: The fusion mechanism (late fusion, feature concatenation, etc.) and the exact pretrained model variants are not specified, hindering assessment of the complementarity result.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our work. We address the single major comment below regarding the abstract's claim about biases in trajectory representations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that sparse point trajectories are 'largely free of such biases by construction' is load-bearing for interpreting the fusion gains (+8.7 with DINOv2, +1.6 with V-JEPA 2) as evidence of orthogonal motion features rather than an ensemble effect. Standard RGB-based trajectory extraction (optical flow or learned trackers) can retain appearance cues via consistent pixel tracking; the manuscript must supply explicit controls (e.g., object-category prediction from trajectories alone or background-masked variants) to support the assumption.
Authors: We agree that the phrasing 'largely free of such biases by construction' is imprecise and could overstate the separation from appearance cues, since standard trackers rely on RGB consistency for point correspondence. While the sparsity and 2.5D nature of the input inherently limit dense appearance and background information relative to full RGB volumes, residual cues may persist. The fusion gains are presented as evidence of complementarity rather than a strict proof of orthogonality. To substantiate the assumption as requested, we will add explicit controls in the revision, including object-category prediction accuracy from trajectory features alone and evaluations on background-masked variants. revision: yes
Circularity Check
No circularity in derivation chain; empirical claims rest on benchmarks
full rationale
The paper advances an empirical architecture and pretraining scheme for trajectory-based action recognition, with the central complementarity claim supported by reported fusion gains on standard benchmarks (SSv2, EPIC-Kitchens). No equations, parameter fits, or self-citations are presented that reduce any prediction or uniqueness result to the authors' own inputs by construction. The 'by construction' phrasing for bias freedom is a modeling assumption rather than a self-referential derivation step. This is the common honest case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muck- ley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, and others. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[2]
Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A
Long Zhao, Nitesh Bharadwaj Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J. Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A. Ross, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Ting Liu, and Boqing Gong. VideoPrism: A Foundational Visual Encoder for Video Understanding. InForty...
2024
-
[3]
Masked motion encoding for self-supervised video representation learning
Xinyu Sun, Peihao Chen, Liangwei Chen, Changhao Li, Thomas H Li, Mingkui Tan, and Chuang Gan. Masked motion encoding for self-supervised video representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2235–2245, 2023
2023
-
[4]
The panaf-fgbg dataset: Understanding the impact of backgrounds in wildlife behaviour recogni- tion
Otto Brookes, Maksim Kukushkin, Majid Mirmehdi, Colleen Stephens, Paula Dieguez, Thurston C Hicks, Sorrel Jones, Kevin Lee, Maureen S McCarthy, Amelia Meier, and others. The panaf-fgbg dataset: Understanding the impact of backgrounds in wildlife behaviour recogni- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p...
2025
-
[5]
Removing the background by adding the background: Towards background robust self-supervised video representation learning
Jinpeng Wang, Yuting Gao, Ke Li, Yiqi Lin, Andy J Ma, Hao Cheng, Pai Peng, Feiyue Huang, Rongrong Ji, and Xing Sun. Removing the background by adding the background: Towards background robust self-supervised video representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11804–11813, 2021
2021
-
[6]
Why can’t i dance in the mall? learning to mitigate scene bias in action recognition.Advances in Neural Information Processing Systems, 32, 2019
Jinwoo Choi, Chen Gao, Joseph CE Messou, and Jia-Bin Huang. Why can’t i dance in the mall? learning to mitigate scene bias in action recognition.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[7]
On the integration of optical flow and action recognition
Laura Sevilla-Lara, Yiyi Liao, Fatma Güney, Varun Jampani, Andreas Geiger, and Michael J Black. On the integration of optical flow and action recognition. InGerman conference on pattern recognition, pages 281–297. Springer, 2018
2018
-
[8]
Is appearance free action recognition possible? InEuropean Conference on Computer Vision, pages 156–173
Filip Ilic, Thomas Pock, and Richard P Wildes. Is appearance free action recognition possible? InEuropean Conference on Computer Vision, pages 156–173. Springer, 2022
2022
-
[9]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022, 2025
2025
-
[10]
Tapnext: Tracking any point (tap) as next token prediction
Artem Zholus, Carl Doersch, Yi Yang, Skanda Koppula, Viorica Patraucean, Xu Owen He, Ignacio Rocco, Mehdi SM Sajjadi, Sarath Chandar, and Ross Goroshin. Tapnext: Tracking any point (tap) as next token prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9693–9703, 2025. 10
2025
-
[11]
Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. In European Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[12]
Articulated Object Estimation in the Wild
Abdelrhman Werby, Martin Büchner, Adrian Röfer, Chenguang Huang, Wolfram Burgard, and Abhinav Valada. Articulated Object Estimation in the Wild. In Joseph Lim, Shuran Song, and Hae-Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 of Proceedings of Machine Learning Research, pages 3828–3849. PMLR, September 2025
2025
-
[13]
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong W ANG, Hongwei Yi, Xihui Liu, Hengshuang Zhao, Yu Liu, Yingya Zhang, and Yujiu Yang. Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[14]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
2017
-
[15]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, and others. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 584...
2017
-
[16]
Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100. International Journal of Computer Vision (IJCV), 130:33–55, 2022
2022
-
[17]
Large-scale video classification with convolutional neural networks
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014
2014
-
[18]
Long-term recurrent convolutional networks for visual recognition and description
Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2625–2634, 2015
2015
-
[19]
Courville
Nicolas Ballas, Li Yao, Chris Pal, and Aaron C. Courville. Delving Deeper into Convolutional Networks for Learning Video Representations. In Yoshua Bengio and Yann LeCun, editors, 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016
2016
-
[20]
Beyond short snippets: Deep networks for video classification
Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, and George Toderici. Beyond short snippets: Deep networks for video classification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4694–4702, 2015
2015
-
[21]
Learning spa- tiotemporal features with 3d convolutional networks
Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spa- tiotemporal features with 3d convolutional networks. InProceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015
2015
-
[22]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019
2019
-
[23]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 203–213, 2020
2020
-
[24]
Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021. 11
2021
-
[25]
Vivit: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021
2021
-
[26]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
2022
-
[27]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14549–14560, 2023
2023
-
[28]
Masked autoencoders as spatiotemporal learners.Advances in neural information processing systems, 35:35946–35958, 2022
Christoph Feichtenhofer, Yanghao Li, Kaiming He, and others. Masked autoencoders as spatiotemporal learners.Advances in neural information processing systems, 35:35946–35958, 2022
2022
-
[29]
Recurrent Video Masked Autoencoders.arXiv preprint arXiv:2512.13684, 2025
Daniel Zoran, Nikhil Parthasarathy, Yi Yang, Drew A Hudson, Joao Carreira, and Andrew Zisserman. Recurrent Video Masked Autoencoders.arXiv preprint arXiv:2512.13684, 2025
Pith/arXiv arXiv 2025
-
[30]
Revisiting Feature Prediction for Learning Visual Representations from Video.Transactions on Machine Learning Research, 2024
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. Revisiting Feature Prediction for Learning Visual Representations from Video.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[31]
Two-stream convolutional networks for action recognition in videos.Advances in neural information processing systems, 27, 2014
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos.Advances in neural information processing systems, 27, 2014
2014
-
[32]
Convolutional two-stream network fusion for video action recognition
Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Convolutional two-stream network fusion for video action recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1933–1941, 2016
1933
-
[33]
Memory-augmented dense predictive coding for video representation learning
Tengda Han, Weidi Xie, and Andrew Zisserman. Memory-augmented dense predictive coding for video representation learning. InEuropean conference on computer vision, pages 312–329. Springer, 2020
2020
-
[34]
Wang, Christopher Hoang, Yuwen Xiong, Yann LeCun, and Mengye Ren
Alex N. Wang, Christopher Hoang, Yuwen Xiong, Yann LeCun, and Mengye Ren. Poo- DLe: Pooled and dense self-supervised learning from naturalistic videos. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[35]
Spatial temporal graph convolutional networks for skeleton-based action recognition
Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[36]
Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation
Chao Li, Qiaoyong Zhong, Di Xie, and Shiliang Pu. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. InProceedings of the 27th International Joint Conference on Artificial Intelligence, IJCAI’18, pages 786–792. AAAI Press, 2018. ISBN 978-0-9992411-2-7
2018
-
[37]
Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Skeleton-Based Action Recognition With Directed Graph Neural Networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7904–7913, 2019. doi: 10.1109/CVPR.2019.00810
-
[38]
An end-to-end spatio- temporal attention model for human action recognition from skeleton data
Sijie Song, Cuiling Lan, Junliang Xing, Wenjun Zeng, and Jiaying Liu. An end-to-end spatio- temporal attention model for human action recognition from skeleton data. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
2017
-
[39]
Jun Liu, Gang Wang, Ping Hu, Ling-Yu Duan, and Alex C. Kot. Global Context-Aware Attention LSTM Networks for 3D Action Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
2017
-
[40]
Seeing without Pixels: Perception from Camera Trajectories.arXiv preprint arXiv:2511.21681, 2025
Zihui Xue, Kristen Grauman, Dima Damen, Andrew Zisserman, and Tengda Han. Seeing without Pixels: Perception from Camera Trajectories.arXiv preprint arXiv:2511.21681, 2025. 12
arXiv 2025
-
[41]
Renaud Vandeghen, Fida Mohammad Thoker, Marc Van Droogenbroeck, and Bernard Ghanem. TrackMAE: Video Representation Learning via Track Mask and Predict.arXiv preprint arXiv:2603.27268, 2026
arXiv 2026
-
[42]
Trajectory-aligned space-time tokens for few-shot action recognition
Pulkit Kumar, Namitha Padmanabhan, Luke Luo, Sai Saketh Rambhatla, and Abhinav Shri- vastava. Trajectory-aligned space-time tokens for few-shot action recognition. InEuropean Conference on Computer Vision, pages 474–493. Springer, 2024
2024
-
[43]
Trokens: Semantic-Aware Relational Trajectory Tokens for Few-Shot Action Recognition
Pulkit Kumar, Shuaiyi Huang, Matthew Walmer, Sai Saketh Rambhatla, and Abhinav Shrivas- tava. Trokens: Semantic-Aware Relational Trajectory Tokens for Few-Shot Action Recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13544– 13556, 2025
2025
-
[44]
Willem Davison, Xinyue Hao, and Laura Sevilla-Lara. It’s a Matter of Time: Three Lessons on Long-Term Motion for Perception.arXiv preprint arXiv:2602.14705, 2026
arXiv 2026
-
[45]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020
2020
-
[46]
W AFT: Warping-Alone Field Transforms for Optical Flow
Yihan Wang and Jia Deng. W AFT: Warping-Alone Field Transforms for Optical Flow. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[47]
Tap-vid: A benchmark for tracking any point in a video.Advances in Neural Information Processing Systems, 35:13610–13626, 2022
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Recasens, Lucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang. Tap-vid: A benchmark for tracking any point in a video.Advances in Neural Information Processing Systems, 35:13610–13626, 2022
2022
-
[48]
Particle video revisited: Tracking through occlusions using point trajectories
Adam W Harley, Zhaoyuan Fang, and Katerina Fragkiadaki. Particle video revisited: Tracking through occlusions using point trajectories. InEuropean Conference on Computer Vision, pages 59–75. Springer, 2022
2022
-
[49]
Tapir: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023
2023
-
[50]
Cotracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker: It is better to track together. InEuropean conference on computer vision, pages 18–35. Springer, 2024
2024
-
[51]
Dense optical tracking: Connecting the dots
Guillaume Le Moing, Jean Ponce, and Cordelia Schmid. Dense optical tracking: Connecting the dots. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19187–19197, 2024
2024
-
[52]
Local all-pair correspondence for point tracking
Seokju Cho, Jiahui Huang, Jisu Nam, Honggyu An, Seungryong Kim, and Joon-Young Lee. Local all-pair correspondence for point tracking. InEuropean conference on computer vision, pages 306–325. Springer, 2024
2024
-
[53]
TAPNext++: What’s Next for Tracking Any Point (TAP)?arXiv preprint arXiv:2604.10582, 2026
Sebastian Jung, Artem Zholus, Martin Sundermeyer, Carl Doersch, Ross Goroshin, David Joseph Tan, Sarath Chandar, Rudolph Triebel, and Federico Tombari. TAPNext++: What’s Next for Tracking Any Point (TAP)?arXiv preprint arXiv:2604.10582, 2026
Pith/arXiv arXiv 2026
-
[54]
Bootstap: Bootstrapped training for tracking-any-point
Carl Doersch, Pauline Luc, Yi Yang, Dilara Gokay, Skanda Koppula, Ankush Gupta, Joseph Heyward, Ignacio Rocco, Ross Goroshin, Joao Carreira, and others. Bootstap: Bootstrapped training for tracking-any-point. InProceedings of the Asian Conference on Computer Vision, pages 3257–3274, 2024
2024
-
[55]
Spatialtracker: Tracking any 2d pixels in 3d space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. Spatialtracker: Tracking any 2d pixels in 3d space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20406–20417, 2024
2024
-
[56]
Spatialtrackerv2: Advancing 3d point tracking with explicit camera motion
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: Advancing 3d point tracking with explicit camera motion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6726–6737, 2025. 13
2025
-
[57]
DELTA: DENSE EFFICIENT LONG-RANGE 3D TRACKING FOR ANY VIDEO
Tuan Duc Ngo, Peiye Zhuang, Evangelos Kalogerakis, Chuang Gan, Sergey Tulyakov, Hsin- Ying Lee, and Chaoyang Wang. DELTA: DENSE EFFICIENT LONG-RANGE 3D TRACKING FOR ANY VIDEO. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[58]
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, XinQiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, and Xin Jin. DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[59]
History-Aware Visuomotor Policy Learning via Point Tracking.arXiv preprint arXiv:2509.17141, 2025
Jingjing Chen, Hongjie Fang, Chenxi Wang, Shiquan Wang, and Cewu Lu. History-Aware Visuomotor Policy Learning via Point Tracking.arXiv preprint arXiv:2509.17141, 2025
arXiv 2025
-
[60]
Generative Video Motion Editing with 3D Point Tracks
Yao-Chih Lee, Zhoutong Zhang, Jiahui Huang, Jui-Hsien Wang, Joon-Young Lee, Jia-Bin Huang, Eli Shechtman, and Zhengqi Li. Generative Video Motion Editing with 3D Point Tracks. arXiv preprint arXiv:2512.02015, 2025
arXiv 2025
-
[61]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21686–21697, 2024
2024
-
[62]
Shape of motion: 4d reconstruction from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Weijia Zeng, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruction from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9660–9672, 2025
2025
-
[63]
TrackerSplat: Exploiting Point Tracking for Fast and Robust Dynamic 3D Gaussians Reconstruction
Daheng Yin, Isaac Ding, Yili Jin, Jianxin Shi, and Jiangchuan Liu. TrackerSplat: Exploiting Point Tracking for Fast and Robust Dynamic 3D Gaussians Reconstruction. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[64]
Segment anything meets point tracking
Frano Rajiˇc, Lei Ke, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, and Fisher Yu. Segment anything meets point tracking. InProceedings of the Winter Conference on Applications of Computer Vision, pages 9284–9293, 2025
2025
-
[65]
Nettrack: Tracking highly dynamic objects with a net
Guangze Zheng, Shijie Lin, Haobo Zuo, Changhong Fu, and Jia Pan. Nettrack: Tracking highly dynamic objects with a net. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19145–19155, 2024
2024
-
[66]
Forecasting Motion in the Wild, April 2026
Neerja Thakkar, Shiry Ginosar, Jacob Walker, Jitendra Malik, Joao Carreira, and Carl Doersch. Forecasting Motion in the Wild, April 2026. arXiv:2604.01015 [cs]
arXiv 2026
-
[67]
TRec: Learning Hand-Object Interactions through 2D Point Track Motion, January 2026
Dennis Holzmann and Sven Wachsmuth. TRec: Learning Hand-Object Interactions through 2D Point Track Motion, January 2026. arXiv:2601.03667 [cs]
arXiv 2026
-
[68]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025
2025
-
[69]
Andrea Tacchetti, Leyla Isik, and Tomaso Poggio. Invariant recognition drives neural represen- tations of action sequences.PLOS Computational Biology, 13(12):1–20, December 2017. doi: 10.1371/journal.pcbi.1005859
-
[70]
DisMo: Disentangled Motion Representations for Open-World Motion Transfer
Thomas Ressler-Antal, Frank Fundel, Malek Ben Alaya, Stefan Andreas Baumann, Felix Krause, Ming Gui, and Björn Ommer. DisMo: Disentangled Motion Representations for Open-World Motion Transfer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[71]
Chirality in Action: Time-Aware Video Repre- sentation Learning by Latent Straightening
Piyush Nitin Bagad and Andrew Zisserman. Chirality in Action: Time-Aware Video Repre- sentation Learning by Latent Straightening. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[72]
DINOv2: Learning Robust Visual Features without Supervision.Transactions on Machine Learning Research Journal, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, and others. DINOv2: Learning Robust Visual Features without Supervision.Transactions on Machine Learning Research Journal, 2024. 14
2024
-
[73]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, and others. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[74]
A deeper dive into what deep spatiotemporal networks encode: Quantifying static vs
Matthew Kowal, Mennatullah Siam, Md Amirul Islam, Neil DB Bruce, Richard P Wildes, and Konstantinos G Derpanis. A deeper dive into what deep spatiotemporal networks encode: Quantifying static vs. dynamic information. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 13999–14009, 2022
2022
-
[75]
RESOUND: Towards Action Recognition without Representation Bias
Yingwei Li, Yi Li, and Nuno Vasconcelos. RESOUND: Towards Action Recognition without Representation Bias. InProceedings of the European Conference on Computer Vision (ECCV), September 2018
2018
-
[76]
De-An Huang, Vignesh Ramanathan, Dhruv Mahajan, Lorenzo Torresani, Manohar Paluri, Li Fei-Fei, and Juan Carlos Niebles. What Makes a Video a Video: Analyzing Temporal Information in Video Understanding Models and Datasets. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7366–7375, 2018. doi: 10.1109/CVPR.2018. 00769
-
[77]
cut”, “open
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations, 2019. 15 A Datasets We evaluate our method on five action recognition datasets covering a range of video domains, label granularities, and motion characteristics. Table 5 summarizes the key statistics for each dataset. Kinetics-...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.