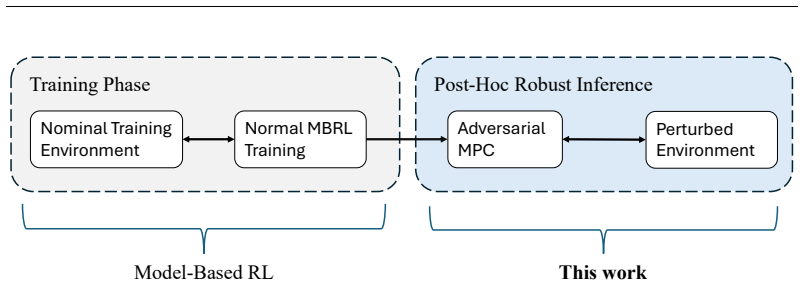
Post-Hoc Robustness for Model-Based Reinforcement Learning
Pith reviewed 2026-06-28 11:13 UTC · model grok-4.3
The pith
A nominal RL policy gains robustness to environment perturbations at inference time by running adversarial model-predictive control on its learned transition model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
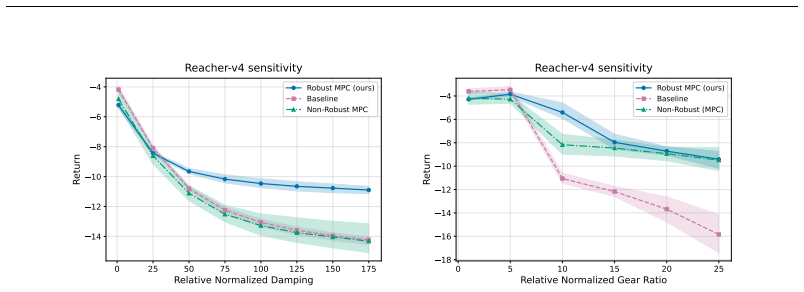
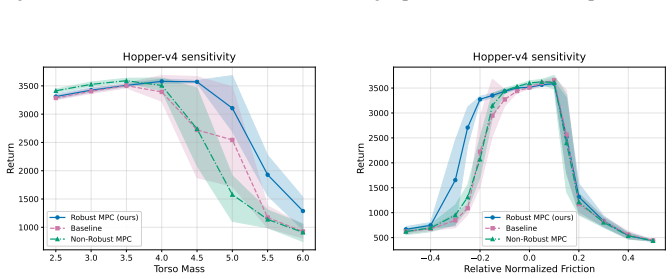
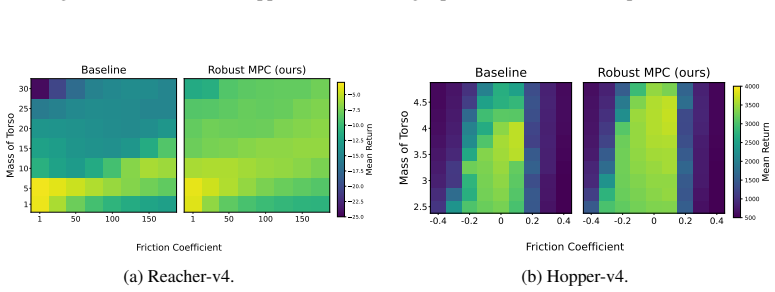
The central claim is that post-hoc robustification of a trained nominal policy is possible by performing model-predictive control under adversarial rollouts that are approximated via projected gradient descent inside a bounded uncertainty set; these offline rollouts incorporate mitigation of out-of-distribution issues and, when evaluated in perturbed Gymnasium MuJoCo environments, produce significant robustness gains without any additional training of neural networks.
What carries the argument
model-predictive control under adversarial rollouts approximated via projected gradient descent within a bounded uncertainty set
If this is right
- Robustness can be improved without any additional training of neural networks.
- The method applies directly to any already-trained nominal policy that comes with a learned transition model.
- Adversarial rollouts performed offline with projected gradient descent inside a bounded uncertainty set yield measurable robustness gains in perturbed continuous-control environments.
- Out-of-distribution mitigation during the offline rollouts is required for the improvements to appear in practice.
Where Pith is reading between the lines
- The separation of nominal training from robustness improvement may let practitioners maintain a single learned model and apply different robustness levels on demand.
- If model accuracy is the main bottleneck, future work could test whether better model learning directly raises the ceiling on post-hoc robustness.
- The approach suggests that inference-time computation can substitute for some of the robustness that would otherwise require adversarial training from the start.
Load-bearing premise
The learned transition model is accurate enough that adversarial improvements found inside its bounded uncertainty set will transfer to the true perturbed environment.
What would settle it
Apply the post-hoc procedure to a trained policy, then compare its return in a perturbed test environment against the return of the original nominal policy; if the post-hoc version does not improve or maintain performance, the central claim is falsified.
Figures

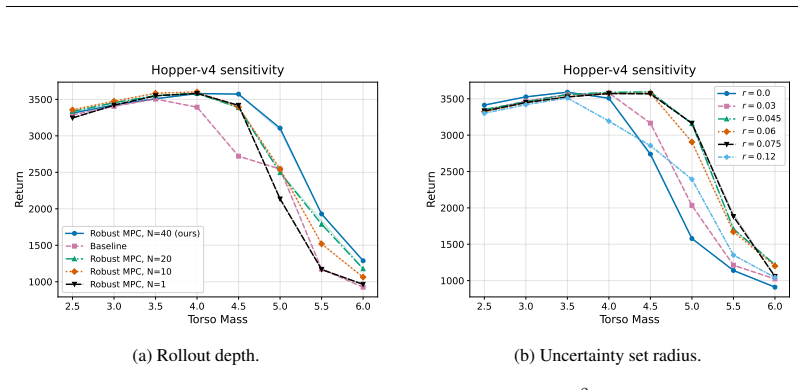
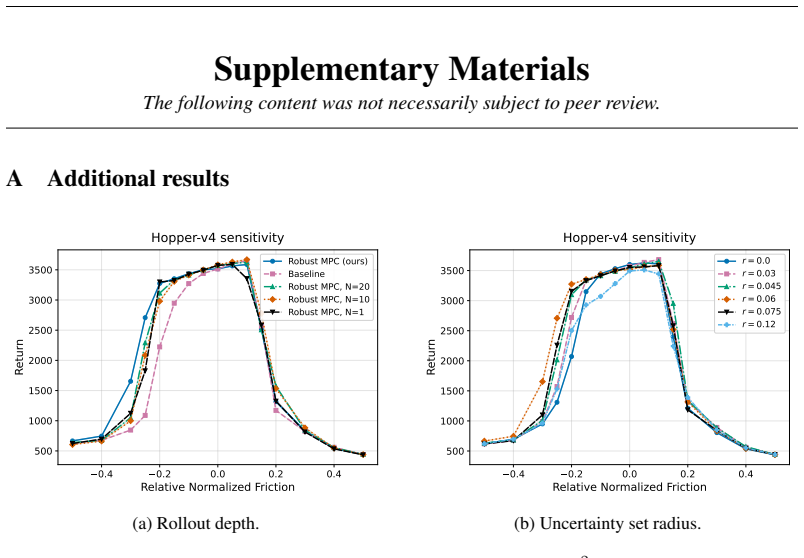
read the original abstract
To improve the real-world applicability of reinforcement learning (RL), the field of adversarially robust RL studies how to train agents under adversarial environment perturbations. In this setting, a protagonist agent optimizes a policy under environmental perturbations from an adversary, resulting in a zero-sum Markov game. When adversarially robust RL is combined with model-based RL, the adversary can target a learned transition model instead of the training environment. Extending this idea, this work introduces post-hoc robustification of deep RL agents at inference time. By using the learned model in combination with a trained nominal policy, our approach performs a robust policy improvement step. The goal is to improve robustness without any additional training of neural networks. Specifically, we utilize model-predictive control under adversarial rollouts, which are approximated via projected gradient descent within a bounded uncertainty set. Furthermore, these offline rollouts are performed while considering and mitigating out-of-distribution issues. The proposed methodology is validated by demonstrating significant improvements in robustness when the algorithm is evaluated in perturbed Gymnasium MuJoCo environments, while considering the computational limitations of the post-hoc inference setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a post-hoc robustification method for model-based RL agents at inference time. Using a pre-trained transition model and nominal policy, it performs model-predictive control with adversarial rollouts approximated via projected gradient descent inside a bounded uncertainty set around the model, while mitigating out-of-distribution issues during offline rollouts. No additional neural network training is required. The approach is claimed to yield significant robustness improvements when evaluated on perturbed Gymnasium MuJoCo environments.
Significance. If the central claims hold, the work would be significant for practical deployment of MBRL agents, as it enables robustness gains without retraining or online adaptation and explicitly accounts for inference-time computational constraints. The post-hoc framing and use of existing models are strengths. However, the significance is limited by the absence of detailed quantitative results, ablation studies, or analysis of model fidelity in the provided abstract, making it difficult to evaluate the magnitude or reliability of the reported gains.
major comments (2)
- [Abstract / method description] The central claim that MPC under PGD-generated adversarial rollouts within a bounded uncertainty set produces transferable robustness improvements rests on the unverified assumption that the learned transition model is sufficiently accurate to avoid spurious attack directions and error accumulation over finite-horizon rollouts. This assumption is load-bearing for the post-hoc method (as noted in the abstract's description of the procedure) but receives no supporting analysis, sensitivity experiments, or comparison to model error bounds.
- [Abstract / evaluation description] The evaluation claims 'significant improvements in robustness' in perturbed MuJoCo environments, yet no quantitative metrics, baselines, or statistical details are provided to substantiate the transfer from model-based adversarial rollouts to true perturbed dynamics. Without these, the empirical support for the method cannot be assessed.
minor comments (1)
- [Abstract] The abstract refers to 'considering and mitigating out-of-distribution issues' but provides no specifics on the mitigation technique or its implementation; this should be clarified with a brief description or reference to the relevant section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and will revise the manuscript to strengthen the presentation of model assumptions and evaluation details.
read point-by-point responses
-
Referee: [Abstract / method description] The central claim that MPC under PGD-generated adversarial rollouts within a bounded uncertainty set produces transferable robustness improvements rests on the unverified assumption that the learned transition model is sufficiently accurate to avoid spurious attack directions and error accumulation over finite-horizon rollouts. This assumption is load-bearing for the post-hoc method (as noted in the abstract's description of the procedure) but receives no supporting analysis, sensitivity experiments, or comparison to model error bounds.
Authors: We agree that the fidelity of the learned transition model is a key assumption. The manuscript already incorporates mitigation of out-of-distribution issues during offline rollouts to reduce the impact of model errors. In the revision we will add sensitivity experiments that vary model error bounds and analyze error accumulation over the finite horizon, along with comparisons to theoretical model error bounds, to provide explicit support for the assumption. revision: yes
-
Referee: [Abstract / evaluation description] The evaluation claims 'significant improvements in robustness' in perturbed MuJoCo environments, yet no quantitative metrics, baselines, or statistical details are provided to substantiate the transfer from model-based adversarial rollouts to true perturbed dynamics. Without these, the empirical support for the method cannot be assessed.
Authors: The abstract is a concise summary; the full manuscript contains the quantitative metrics, baseline comparisons, and statistical details from the perturbed Gymnasium MuJoCo evaluations that substantiate the transfer. We will expand the abstract to include key quantitative results and will ensure the main text makes the connection between model-based adversarial rollouts and true perturbed dynamics explicit. revision: yes
Circularity Check
No significant circularity; post-hoc inference-time procedure is independent of fitted inputs
full rationale
The paper presents a post-hoc method that combines a pre-trained transition model with a nominal policy to perform robust policy improvement via MPC and PGD-based adversarial rollouts inside a bounded uncertainty set, with OOD mitigation. This is an applied inference-time algorithm whose claimed gains on perturbed MuJoCo environments are asserted to follow from the procedure itself rather than any derivation that reduces by construction to the model's fitted parameters or to self-citations. No equations, uniqueness theorems, or ansatzes are shown that would make the central claim self-referential. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , publisher=. Reinforcement Learning:. 1998 , address=
1998
-
[2]
International Conference on Machine Learning , pages=
Robust adversarial reinforcement learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[3]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Trust Region Policy Optimization , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[4]
Available at Optimization Online , volume=
Kullback-Leibler divergence constrained distributionally robust optimization , author=. Available at Optimization Online , volume=
-
[5]
Advances in neural information processing systems , volume=
Rambo-rl: Robust adversarial model-based offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in neural information processing systems , volume=
Natural Actor-Critic for Robust Reinforcement Learning with Function Approximation , author=. Advances in neural information processing systems , volume=
-
[7]
MuJoCo: A physics engine for model-based control , year=
Todorov, Emanuel and Erez, Tom and Tassa, Yuval , booktitle=. MuJoCo: A physics engine for model-based control , year=
-
[8]
International conference on machine learning , pages=
Policy gradient method for robust reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[9]
Mathematics of Operations Research , volume=
Robust markov decision processes: Beyond rectangularity , author=. Mathematics of Operations Research , volume=. 2023 , publisher=
2023
-
[10]
Advances in Neural Information Processing Systems , volume=
Policy Gradient for Rectangular Robust Markov Decision Processes , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Neural computation , volume=
Robust reinforcement learning , author=. Neural computation , volume=. 2005 , publisher=
2005
-
[12]
Advances in Neural Information Processing Systems , volume=
Online robust reinforcement learning with model uncertainty , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Machine Learning and Knowledge Extraction , volume=
Robust reinforcement learning: A review of foundations and recent advances , author=. Machine Learning and Knowledge Extraction , volume=. 2022 , publisher=
2022
-
[14]
Advances in Neural Information Processing Systems , volume=
Distributionally robust Markov decision processes , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Risk-averse model uncertainty for distributionally robust safe reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in neural information processing systems , volume=
When to trust your model: Model-based policy optimization , author=. Advances in neural information processing systems , volume=
-
[17]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[18]
GitHub repository , howpublished =
Feng, Xu , title =. GitHub repository , howpublished =. 2021 , publisher =
2021
-
[19]
2020 , eprint=
D4RL: Datasets for Deep Data-Driven Reinforcement Learning , author=. 2020 , eprint=
2020
-
[20]
Foundations and Trends
Model-based reinforcement learning: A survey , author=. Foundations and Trends. 2023 , publisher=
2023
-
[21]
Machine learning proceedings 1990 , pages=
Integrated architectures for learning, planning, and reacting based on approximating dynamic programming , author=. Machine learning proceedings 1990 , pages=. 1990 , publisher=
1990
-
[22]
Mathematics of Operations Research , volume=
Robust Markov decision processes , author=. Mathematics of Operations Research , volume=. 2013 , publisher=
2013
-
[23]
Bring Your Own (
Gadot, Uri and Wang, Kaixin and Kumar, Navdeep and Levy, Kfir Yehuda and Mannor, Shie , booktitle =. Bring Your Own (. 2024 , volume =
2024
-
[24]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[25]
Advances in neural information processing systems , volume=
Deep reinforcement learning at the edge of the statistical precipice , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , pages=
Generative adversarial nets , author=. Advances in neural information processing systems , pages=
-
[27]
International conference on machine learning , pages=
Learning latent dynamics for planning from pixels , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[28]
arXiv preprint arXiv:2301.04104 , year=
Mastering diverse domains through world models , author=. arXiv preprint arXiv:2301.04104 , year=
-
[29]
2020 IEEE symposium series on computational intelligence (SSCI) , pages=
Sim-to-real transfer in deep reinforcement learning for robotics: a survey , author=. 2020 IEEE symposium series on computational intelligence (SSCI) , pages=. 2020 , organization=
2020
-
[30]
arXiv preprint arXiv:1610.03518 , year=
Transfer from simulation to real world through learning deep inverse dynamics model , author=. arXiv preprint arXiv:1610.03518 , year=
-
[31]
Conference on robot learning , pages=
Sim-to-real robot learning from pixels with progressive nets , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[32]
Maximum Entropy
Benjamin Eysenbach and Sergey Levine , booktitle=. Maximum Entropy. 2022 , url=
2022
-
[33]
2020 , note=
When to Trust Your Model: Model-Based Policy Optimization , author=. 2020 , note=
2020
-
[34]
The Twelfth International Conference on Learning Representations , year=
Reward-Free Curricula for Training Robust World Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[35]
2017 , url=
Aravind Rajeswaran and Sarvjeet Ghotra and Balaraman Ravindran and Sergey Levine , booktitle=. 2017 , url=
2017
-
[36]
Journal of Machine Learning Research , volume=
Distributionally robust model-based offline reinforcement learning with near-optimal sample complexity , author=. Journal of Machine Learning Research , volume=
-
[37]
IEEE Transactions on Automatic Control , year=
Performance-Robustness Tradeoffs in Adversarially Robust Control and Estimation , author=. IEEE Transactions on Automatic Control , year=
-
[38]
Holden-Day , year=
Information and information stability of random variables and processes , author=. Holden-Day , year=
-
[39]
Journal of Machine Learning Research , year =
Antonin Raffin and Ashley Hill and Adam Gleave and Anssi Kanervisto and Maximilian Ernestus and Noah Dormann , title =. Journal of Machine Learning Research , year =
-
[40]
2024 , booktitle =
Wang, Yudan and Zou, Shaofeng and Wang, Yue , title =. 2024 , booktitle =
2024
-
[41]
Transactions on Machine Learning Research , issn=
Optimal Transport Perturbations for Safe Reinforcement Learning with Robustness Guarantees , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[42]
Transactions on Machine Learning Research , issn=
Efficient Action Robust Reinforcement Learning with Probabilistic Policy Execution Uncertainty , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[43]
https://math.stackexchange.com/q/3613688 , URL =
Substitute for triangle inequality for Kullback-Leibler divergence , AUTHOR =. https://math.stackexchange.com/q/3613688 , URL =
-
[44]
2000 , publisher=
Methods of information geometry , author=. 2000 , publisher=
2000
-
[45]
Constrained Differential Optimization , url =
Platt, John and Barr, Alan , booktitle =. Constrained Differential Optimization , url =
-
[46]
International conference on learning representations , year=
beta-vae Learning basic visual concepts with a constrained variational framework , author=. International conference on learning representations , year=
-
[47]
International Conference on Machine Learning , pages=
Responsive safety in reinforcement learning by pid lagrangian methods , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[48]
The Twelfth International Conference on Learning Representations , year=
Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula , author=. The Twelfth International Conference on Learning Representations , year=
-
[49]
Robust Reinforcement Learning via Adversarial training with Langevin Dynamics , url =
Kamalaruban, Parameswaran and Huang, Yu-Ting and Hsieh, Ya-Ping and Rolland, Paul and Shi, Cheng and Cevher, Volkan , booktitle =. Robust Reinforcement Learning via Adversarial training with Langevin Dynamics , url =
-
[50]
Yuval Tassa and Yotam Doron and Alistair Muldal and Tom Erez and Yazhe Li and Diego de Las Casas and David Budden and Abbas Abdolmaleki and Josh Merel and Andrew Lefrancq and Timothy P. Lillicrap and Martin A. Riedmiller , title =. CoRR , volume =. 2018 , url =. 1801.00690 , timestamp =
Pith/arXiv arXiv 2018
-
[51]
The Robustness-Performance Tradeoff in Markov Decision Processes , url =
Xu, Huan and Mannor, Shie , booktitle =. The Robustness-Performance Tradeoff in Markov Decision Processes , url =
-
[52]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[53]
MOReL: Model-Based Offline Reinforcement Learning , url =
Kidambi, Rahul and Rajeswaran, Aravind and Netrapalli, Praneeth and Joachims, Thorsten , booktitle =. MOReL: Model-Based Offline Reinforcement Learning , url =
-
[54]
International Conference on Machine Learning , pages=
Action robust reinforcement learning and applications in continuous control , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[55]
Transactions on Machine Learning Research , issn=
Robust Reinforcement Learning in a Sample-Efficient Setting , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[56]
Mathematics of Operations Research , volume=
Robust dynamic programming , author=. Mathematics of Operations Research , volume=. 2005 , publisher=
2005
-
[57]
arXiv preprint arXiv:1509.01149 , year=
Model predictive path integral control using covariance variable importance sampling , author=. arXiv preprint arXiv:1509.01149 , year=
-
[58]
2024 , url=
Nicklas Hansen and Hao Su and Xiaolong Wang , booktitle=. 2024 , url=
2024
-
[59]
IEEE Robotics and Automation Letters , year=
GRAM: Generalization in Deep RL With a Robust Adaptation Module , author=. IEEE Robotics and Automation Letters , year=
-
[60]
Contextualize Me
Carolin Benjamins and Theresa Eimer and Frederik Schubert and Aditya Mohan and Sebastian D. Contextualize Me. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[61]
An Adaptive Deep
Xiaoyu Chen and Xiangming Zhu and Yufeng Zheng and Pushi Zhang and Li Zhao and Wenxue Cheng and Peng CHENG and Yongqiang Xiong and Tao Qin and Jianyu Chen and Tie-Yan Liu , booktitle=. An Adaptive Deep. 2022 , url=
2022
-
[62]
Proceedings of the 37th International Conference on Machine Learning , pages =
Context-aware Dynamics Model for Generalization in Model-Based Reinforcement Learning , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[63]
International Conference on Learning Representations , year=
Learning to Adapt in Dynamic, Real-World Environments through Meta-Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[64]
Advances in neural information processing systems , volume=
Robust deep reinforcement learning against adversarial perturbations on state observations , author=. Advances in neural information processing systems , volume=
-
[65]
Robust Deep Reinforcement Learning against Adversarial Perturbations on State Observations , url =
Zhang, Huan and Chen, Hongge and Xiao, Chaowei and Li, Bo and Liu, Mingyan and Boning, Duane and Hsieh, Cho-Jui , booktitle =. Robust Deep Reinforcement Learning against Adversarial Perturbations on State Observations , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.