Skill Is Not Document: A Query-Conditional Benchmark and Two-Stage Retriever for LLM Agent Skill Routing
Pith reviewed 2026-06-28 08:11 UTC · model grok-4.3
The pith
LLM rejection decisions supply direct supervision for skill compatibility in agent retrieval, improving joint correctness over relevance-only methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
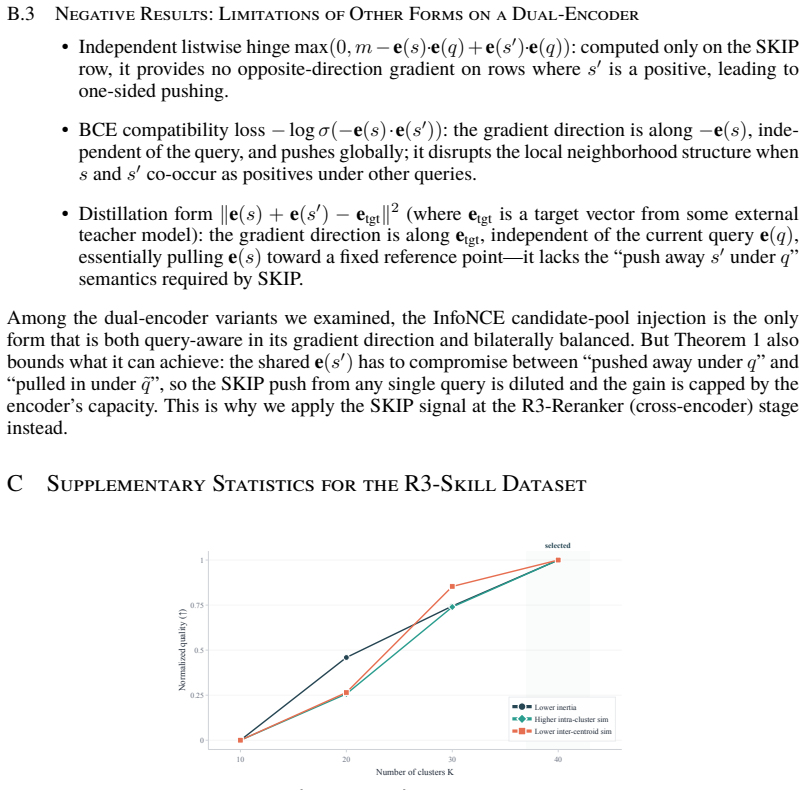
The R3-Embedding plus R3-Reranker pipeline treats LLM rejection decisions as an explicit training signal for query-conditional skill compatibility; gradient analysis shows the push-away signal is diluted under bilateral balancing in the bi-encoder but supplies lossless graded supervision in the cross-encoder, which is why compatibility training is placed only at the reranker stage.
What carries the argument
Two-stage R3 retriever (embedding model followed by cross-encoder reranker) trained with rejection decisions as the compatibility supervision signal.
If this is right
- The bi-encoder stage can remain a standard relevance model while only the cross-encoder needs the extra compatibility objective.
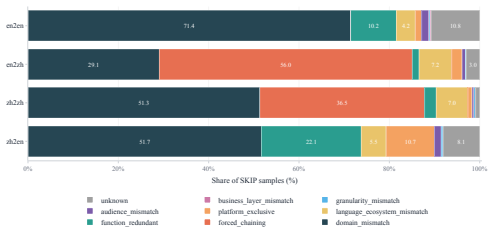
- Ablations on two datasets confirm that moving the rejection signal to the bi-encoder degrades performance.
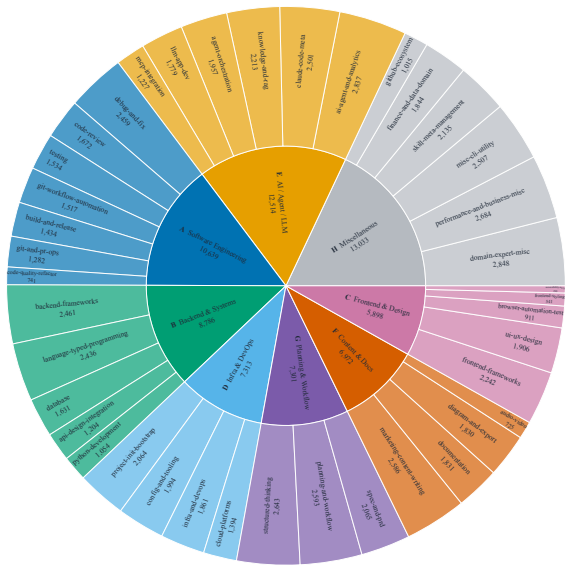
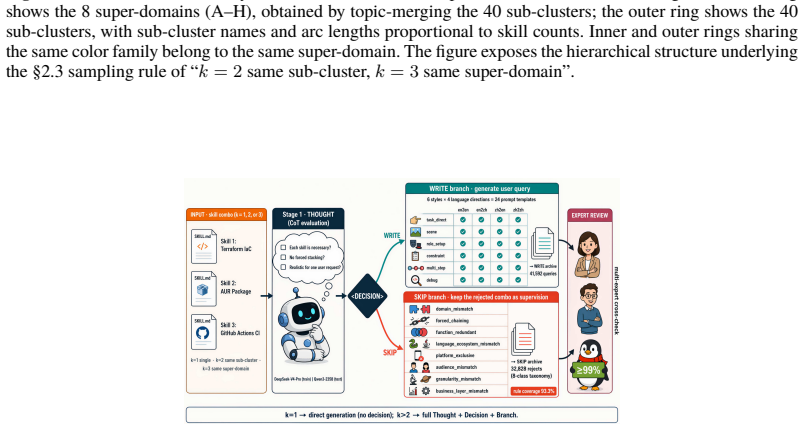
- The R3-Skill benchmark supplies query phrasings and multi-expert verification that match realistic agent routing scenarios across four language directions.
Where Pith is reading between the lines
- Collecting rejections at deployment time could create a continual training loop that refines the retriever without new human labels.
- The same rejection-as-resource pattern may apply to other composition tasks such as tool selection or multi-document summarization where joint correctness matters.
- Because the signal is query-conditional, the method could extend to dynamic skill sets that change over time without retraining the entire embedding space.
Load-bearing premise
The LLM's rejection decisions under a given query reliably indicate which skills are incompatible rather than reflecting unrelated model shortcomings.
What would settle it
A retriever trained on the same data but without any rejection-derived compatibility signal matching or exceeding the reported Hit@1 and Set-Compat scores on R3-Skill would falsify the value of the signal.
Figures



read the original abstract
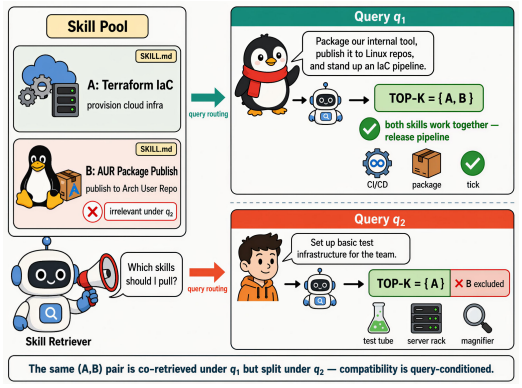
LLM agents complete complex tasks by composing multiple skills, and skill retrieval is a front-end stage for agents. Skill retrieval differs fundamentally from traditional document retrieval at the supervision level: top-K joint correctness depends not only on the semantic relevance of each individual query-skill pair, but also on whether the skills retrieved together can collaborate to fulfill the task under the given query. Such "skill compatibility" cannot be derived from independent relevance alone. Yet existing LLM-based data synthesis pipelines can produce a direct supervision signal for "which skills should not be jointly retrieved under this query" -- namely the LLM's own rejection decisions -- and this signal is routinely discarded as low-quality data. To address this gap, we propose Reject-as-Resource Retriever (R3) and construct R3-Skill, a bilingual (Chinese-English) skill retrieval benchmark targeting realistic agent skill routing. R3-Skill spans four language directions, features query phrasings close to real user requests, and is verified through multi-expert cross-checking. On R3-Skill, we build a two-stage retrieval system (R3-Embedding + R3-Reranker) with skill compatibility as an explicit training signal. Gradient analysis shows that the "push-away" signal is diluted by bilateral balancing in the bi-encoder but acts as lossless graded ranking supervision in the cross-encoder -- motivating its placement at the cross-encoder stage, as confirmed by ablations on two datasets. The R3-Embedding + R3-Reranker pipeline attains Hit@1 = 0.7714, NDCG@10 = 0.8327 and Set-Compat = 0.3525 on R3-Skill. The dataset, training code and model weights are released as open source for agent skill routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that skill retrieval for LLM agents requires explicit modeling of query-conditional skill compatibility (beyond per-skill relevance), which can be supervised via LLM rejection decisions that are normally discarded. It introduces the bilingual R3-Skill benchmark (query phrasings close to real requests, multi-expert cross-checked) and the R3 two-stage retriever (R3-Embedding bi-encoder followed by R3-Reranker cross-encoder) trained with compatibility as an explicit signal. Gradient analysis shows the push-away gradient is diluted under bilateral balancing in the bi-encoder but remains lossless graded supervision for the cross-encoder; ablations on two datasets confirm the placement. The pipeline reports Hit@1 = 0.7714, NDCG@10 = 0.8327 and Set-Compat = 0.3525 on R3-Skill, with dataset, code and weights released.
Significance. If the results and ablations hold, the work is significant for LLM agent systems: it formalizes a distinction between document and skill retrieval, repurposes a routinely discarded supervision signal, supplies a verified bilingual benchmark, and demonstrates a practical two-stage architecture with mechanistic justification. The open release of data, training code and weights directly supports reproducibility and follow-on work in agent skill routing.
major comments (2)
- [Benchmark construction] Benchmark construction section: the claim of multi-expert cross-checking is central to treating R3-Skill as reliable ground truth, yet no inter-annotator agreement statistics, annotation protocol, or disagreement resolution procedure are provided; without these the reported metrics rest on an unquantified verification step.
- [Gradient analysis / Ablations] Gradient analysis and ablations: the statement that the rejection signal supplies 'non-redundant' compatibility supervision (distinct from independent relevance) is load-bearing for the two-stage design; the manuscript must show an explicit control (e.g., training the reranker on relevance-only labels) to confirm the observed Hit@1 / NDCG@10 gains are not explainable by standard ranking objectives alone.
minor comments (2)
- [Results] Results tables: report the full set of baselines (including relevance-only bi-encoder and cross-encoder variants) so that the incremental contribution of the rejection signal can be directly compared.
- [Evaluation metrics] Metric definitions: provide the exact formula or reference for Set-Compat; if it is a custom set-level compatibility measure it should be defined in the main text rather than assumed known.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive feedback. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the claim of multi-expert cross-checking is central to treating R3-Skill as reliable ground truth, yet no inter-annotator agreement statistics, annotation protocol, or disagreement resolution procedure are provided; without these the reported metrics rest on an unquantified verification step.
Authors: We agree that quantitative validation of the annotation process is necessary to support the benchmark's reliability. In the revised manuscript we will add a subsection detailing the annotation protocol, the number of experts, inter-annotator agreement statistics (including percentage agreement and Cohen's kappa), and the disagreement resolution procedure. revision: yes
-
Referee: [Gradient analysis / Ablations] Gradient analysis and ablations: the statement that the rejection signal supplies 'non-redundant' compatibility supervision (distinct from independent relevance) is load-bearing for the two-stage design; the manuscript must show an explicit control (e.g., training the reranker on relevance-only labels) to confirm the observed Hit@1 / NDCG@10 gains are not explainable by standard ranking objectives alone.
Authors: While the existing ablations on two datasets already demonstrate the benefit of placing the compatibility signal at the cross-encoder, we acknowledge that an explicit relevance-only control would strengthen the claim of non-redundancy. We will add this control experiment (training the reranker without the rejection signal) and report the resulting Hit@1 and NDCG@10 metrics in the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation relies on an externally generated supervision signal (LLM rejection decisions) that the paper explicitly argues cannot be derived from independent relevance scores, a new benchmark constructed and verified via multi-expert cross-checking, gradient analysis demonstrating differential behavior of the signal in bi- versus cross-encoders, and ablations isolating its contribution on two datasets. None of these elements reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations; the performance numbers are presented as empirical outcomes of the proposed pipeline rather than tautological restatements of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
҂ିԛགྷ skill֥nameĠ҂ିԛགྷૼཁՖႇ໓ nameಪ෪ཿ čPDF / API / SQL / GitHub ᆃোĎᄍྸb
-
[2]
҂ေᅶӒ description / bodyb
-
[3]
۱skill টϺປӮ
сྶିಞ AI؎"۱skill টϺປӮ"b 5.b Skill: {skill_rendered} en2zh — English skill → Chinese query. ۱AI ᇹ൭Ϻફቓ൙b ٺ**ႇ໓ skill**ି৯čname / description / bodyऌ ۱**໙ี**đѩ **҂ି** ԛགྷ skillႇ໓ nameᇏ໓ᆰၲđ ္҂ିᅶӒ description / bodyჰओb ࿖Ď ğ{style_desc} ཿቔ႗ჿඏğ
-
[4]
Ⴈ**ᇏ໓**؇50~300ࡆן1~2۬ڄ Ќӻഈ૫ପ่b
-
[5]
ປಆႨᇏ໓đ**҂ေԛགྷႇ໓ֆՍ**ಪ෪ཿೂ PDF / API / SQL / GitHub ᆃোᄍྸĎ b
-
[6]
҂ିԛགྷ skillႇ໓ nameି/ಀ૭ඍb
-
[7]
҂ေᅶӒ description / bodyओሰb
-
[8]
You play a real user asking an AI assistant for help
сྶିಞ AI؎"۱skill"b 6.b Skill: {skill_rendered} en2en — English skill → English query. You play a real user asking an AI assistant for help. You can only see the skill below (name / description / body excerpt). The question you write **must not** mention the skill's name (or close synonyms), and **must not** copy sentences from description / body verbatim....
-
[9]
You may layer in 1~2 secondary styles to keep it natural, but stay anchored to the main style above
Write in English, 50~300 words. You may layer in 1~2 secondary styles to keep it natural, but stay anchored to the main style above
-
[10]
Do not mention the skill's name or any near-synonym translation of it
-
[11]
Do not copy whole sentences from description / body; rephrase
-
[13]
Skill: {skill_rendered} zh2en — Chinese skill → English query
Output only the question itself; no prefixes, tags, or explanations. Skill: {skill_rendered} zh2en — Chinese skill → English query. You play a real user asking an AI assistant for help in English. The skill below is in **Chinese** (name / description / body excerpt). Write an **English user question** based on it; you **must not** mention the skill's name...
-
[14]
You may layer 1~2 secondary styles for naturalness, but the main style above must show
Write in **English** only, 50~300 words. You may layer 1~2 secondary styles for naturalness, but the main style above must show
-
[15]
No Chinese characters in the output
-
[16]
Do not surface the skill's name or any direct translation of it; describe by function/scenario instead
-
[17]
Do not copy sentences from description / body
-
[18]
I should use this skill
The AI must be able to read your question and infer "I should use this skill"
-
[19]
۱X"ᆃᇕ႗ೖĠ -ᆃહ໙b Ď ğ -ğᄝ <DECISION>WRITE</DECISION>໙ีĠ -ğᄝ <DECISION>SKIP</DECISION>ඪૼჰၹđ҂ေᄜཿ໙ีb ֒ࣇWRITE ൈĎ ğ -ေğ{style_desc} -؇50~300ࡆן1~2Ġ - сྶ**ൈ**ླေᆃ {k}۱skillൔ
Output only the question itself; no prefixes, tags, or explanations. Skill: {skill_rendered} 17 D.3 Multi-skill prompts ( k = 2 / k = 3, two-stage CoT WRITE/SKIP) zh2zh — Chinese skill set → Chinese query. b {k}۱skillି৯čname / description / bodyൻԛğ ᆃ{k}۱skill ** ൈ**ᄝ **߅/ླ** ѓሙğ -ປӮ҂ਔ / ૼཁҗಌĠ - ҂఼ྛğ҂ି൞"۱X"ᆃᇕ႗ೖĠ -ᆃહ໙b Ď ğ -ğᄝ <DECISION>WRITE</DECISI...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.