Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
Pith reviewed 2026-06-28 10:45 UTC · model grok-4.3
The pith
Reinforcement learning on automatically extracted wide-baseline view pairs trains MLLMs to perform complex spatial matching without chain-of-thought labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
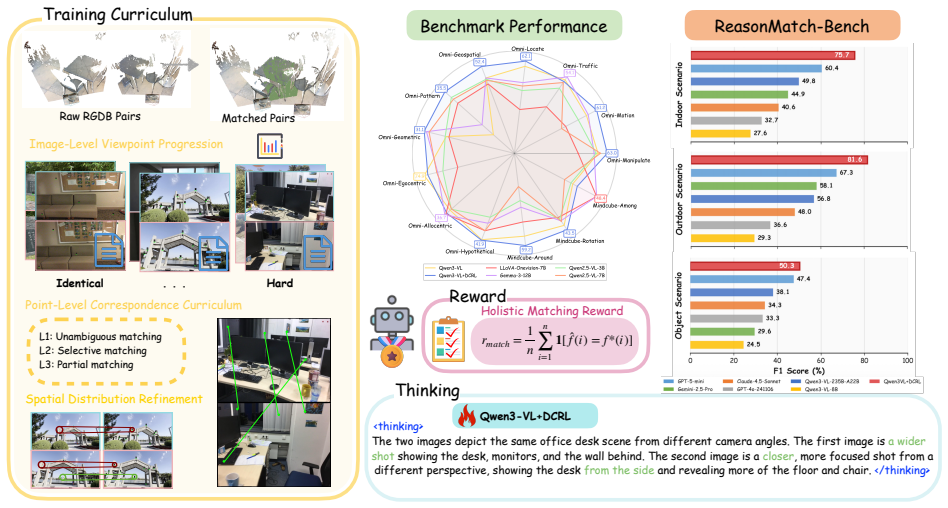
ReasonMatch-Bench reveals that existing MLLMs reach only 37.2 F1 on a hard wide-baseline subset where humans reach 84.0. A scalable extraction pipeline yields diverse, verifiable training pairs from RGB-D videos and SfM reconstructions. Dynamic Correspondence Reinforcement Learning combines Image-Level Viewpoint Progression with Point-Level Correspondence Curriculum to deliver training through verifiable rewards, producing substantial gains on ReasonMatch-Bench, positive transfer to other spatial benchmarks, and modest gains or stability on general visual understanding tasks.
What carries the argument
Dynamic Correspondence Reinforcement Learning (DCRL), which supplies reinforcement signals by progressing first across image-level viewpoint changes and then across point-level correspondences.
Load-bearing premise
The automatically extracted wide-baseline view pairs from video-3D corpora supply accurate, verifiable supervision that does not introduce systematic errors or biases into the training signal.
What would settle it
Applying DCRL to the generated pairs produces no improvement on ReasonMatch-Bench, or replacing the extracted pairs with random or noisy matches still yields the same reported gains.
Figures



read the original abstract
Wide-baseline matching (WBM) requires integrating geometric understanding, viewpoint changes, fine-grained perception, and occlusion reasoning, making it a challenging testbed for spatial reasoning in multimodal large language models (MLLMs) deployed in physical environments. However, current MLLMs lack systematic evaluation and training frameworks for these capabilities. We introduce ReasonMatch-Bench, a benchmark stratified by viewpoint displacement and matching granularity across indoor, outdoor, and object-centric scenarios, and show that current MLLMs still struggle with fine-grained wide-baseline correspondence: on a difficult 90-sample subset, human annotators achieve 84.0 F1, while the best existing baseline reaches 37.2. To bridge this gap, we build a scalable data-generation pipeline that automatically extracts wide-baseline view pairs from large-scale video-3D corpora, including RGB-D videos and SfM reconstructions, yielding diverse and verifiable supervision. We further propose Dynamic Correspondence Reinforcement Learning (DCRL), which combines Image-Level Viewpoint Progression and Point-Level Correspondence Curriculum to improve WBM training through verifiable rewards without explicit CoT supervision. Extensive experiments show that DCRL substantially improves ReasonMatch-Bench and transfers to related spatial benchmarks, while maintaining general visual understanding performance with modest gains on several benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReasonMatch-Bench, a benchmark for wide-baseline matching (WBM) in MLLMs stratified by viewpoint displacement and granularity, shows that existing models perform poorly (best baseline 37.2 F1 vs. human 84.0 on a 90-sample subset), describes an automatic pipeline extracting view pairs from RGB-D and SfM video-3D corpora, and proposes Dynamic Correspondence Reinforcement Learning (DCRL) combining viewpoint progression and point-level curriculum to train via verifiable rewards, claiming substantial gains on ReasonMatch-Bench, positive transfer to related spatial tasks, and maintained general visual performance.
Significance. If the auto-extracted supervision is shown to be accurate, the scalable pipeline and DCRL approach could offer a practical route to elicit geometric and occlusion reasoning in MLLMs without explicit chain-of-thought, with potential downstream value for embodied AI and 3D perception tasks.
major comments (2)
- [Data Generation Pipeline] Abstract and Data Generation Pipeline: the assertion of 'diverse and verifiable supervision' from the RGB-D/SfM extraction pipeline is not accompanied by quantitative validation (e.g., reprojection error statistics, dynamic-object failure rates, or inter-annotator agreement on a held-out subset). This is load-bearing for the central claim that DCRL gains reflect improved spatial reasoning rather than adaptation to pipeline artifacts.
- [Experiments] Experiments section: reported improvements on ReasonMatch-Bench and transfer tasks lack error bars, exact baseline implementations, and ablations isolating the Image-Level Viewpoint Progression versus Point-Level Correspondence Curriculum components, weakening confidence that the observed deltas are robust.
minor comments (2)
- [Abstract] Abstract: the 90-sample difficult subset should state selection criteria and whether results generalize to the full benchmark stratification.
- [DCRL Method] Notation: 'verifiable rewards' is used without a precise definition of the reward function or how correspondence correctness is scored at training time.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Data Generation Pipeline] Abstract and Data Generation Pipeline: the assertion of 'diverse and verifiable supervision' from the RGB-D/SfM extraction pipeline is not accompanied by quantitative validation (e.g., reprojection error statistics, dynamic-object failure rates, or inter-annotator agreement on a held-out subset). This is load-bearing for the central claim that DCRL gains reflect improved spatial reasoning rather than adaptation to pipeline artifacts.
Authors: We agree that the current manuscript lacks explicit quantitative validation metrics for the pipeline. While the extraction relies on established SfM and RGB-D reconstruction techniques, we will add a dedicated subsection reporting reprojection error statistics, dynamic-object failure rates, and agreement metrics on a held-out validation subset to directly support the verifiability of the supervision signals. revision: yes
-
Referee: [Experiments] Experiments section: reported improvements on ReasonMatch-Bench and transfer tasks lack error bars, exact baseline implementations, and ablations isolating the Image-Level Viewpoint Progression versus Point-Level Correspondence Curriculum components, weakening confidence that the observed deltas are robust.
Authors: We concur that these elements are necessary for assessing robustness. The revised version will report error bars computed over multiple random seeds, provide exact implementation details and hyperparameters for all baselines, and include new ablation experiments that separately evaluate the Image-Level Viewpoint Progression and Point-Level Correspondence Curriculum components. revision: yes
Circularity Check
No significant circularity; empirical gains are measured independently of training pipeline definitions
full rationale
The paper's central claims consist of empirical performance improvements on the newly introduced ReasonMatch-Bench (stratified by viewpoint and granularity) plus transfer to external spatial benchmarks, obtained after training DCRL on automatically extracted wide-baseline pairs. These measured F1 scores and benchmark deltas are not shown to reduce by construction to quantities defined inside the data-generation pipeline, the verifiable-reward formulation, or any self-citation chain. No equations, fitted parameters, or uniqueness theorems are presented that equate the reported predictions to the training inputs; the derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 6, 7, 8
Pith/arXiv arXiv 2025
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025. 7
2025
-
[3]
Hot3d: Hand and object tracking in 3d from egocentric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, et al. Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. InCVPR, pages 7061–7071, 2025. 1
2025
-
[4]
Graph-cut ransac
Daniel Barath and Jiri Matas. Graph-cut ransac. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 6733–6741, 2018. 3
2018
-
[5]
Magsac: marginalizing sample consensus
Daniel Barath, Jiri Matas, and Jana Noskova. Magsac: marginalizing sample consensus. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10197–10205, 2019. 3
2019
-
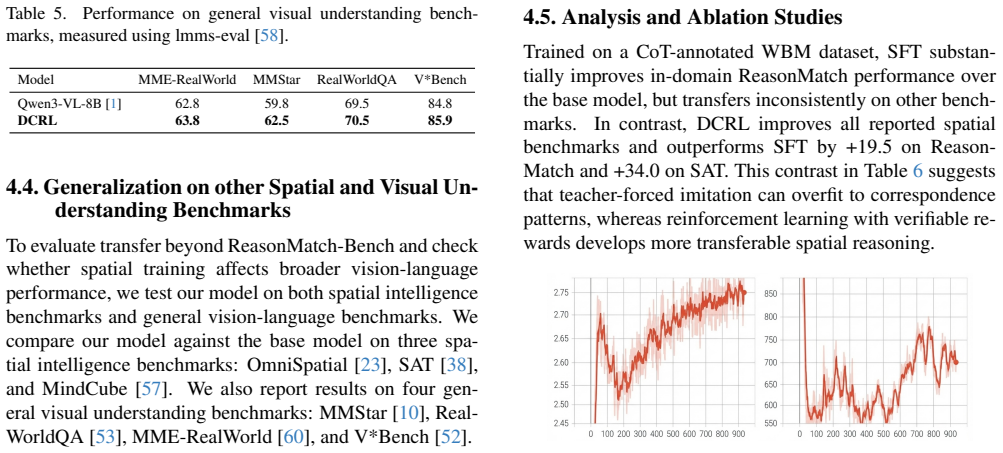
[6]
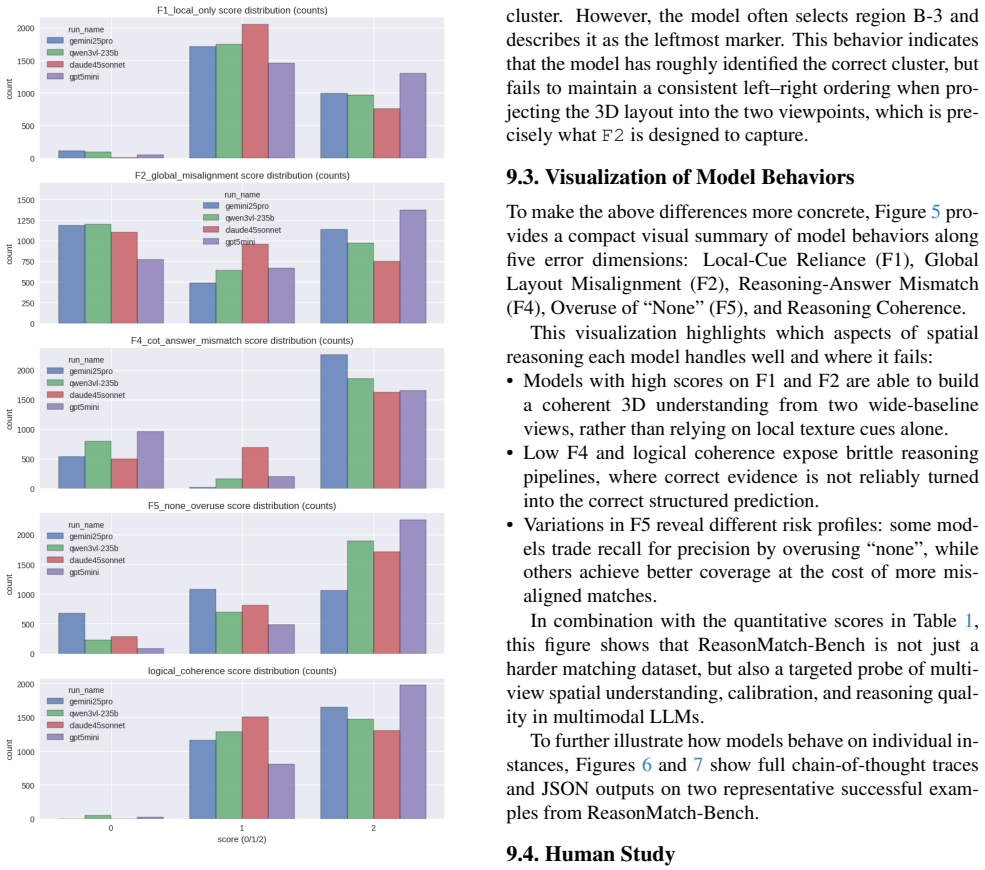
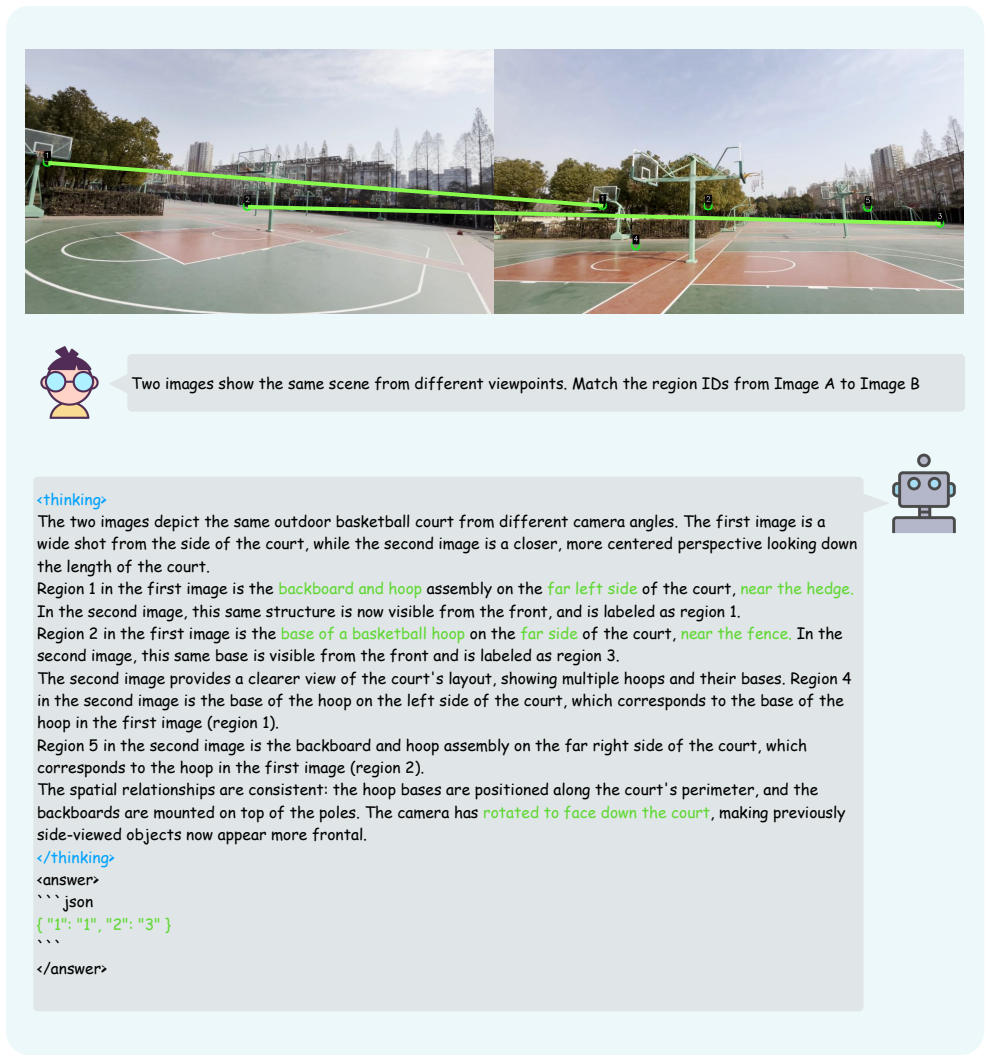
Surf: Speeded up robust features
Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features. InEuropean conference on com- puter vision, pages 404–417. Springer, 2006. 3
2006
-
[7]
Depth pro: Sharp monocular metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024
Aleksei Bochkovskii, Ama ˜AG ¸ l Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024. 1
Pith/arXiv arXiv 2024
-
[8]
Assignment problems: revised reprint
Rainer Burkard, Mauro Dell’Amico, and Silvano Martello. Assignment problems: revised reprint. SIAM, 2012. 3
2012
-
[9]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language mod- els with spatial reasoning capabilities.arXiv preprint arXiv:2401.12168, 2024. 7
arXiv 2024
-
[10]
Are we on the right way for evaluating large vision-language models?Advances in Neural Informa- tion Processing Systems, 37:27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Informa- tion Processing Systems, 37:27056–27087, 2024. 8
2024
-
[11]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 7
Pith/arXiv arXiv 2024
-
[12]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 3, 1
2017
-
[13]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 337–348, 2018. 3
2018
-
[14]
Zihao Dongfang, Xu Zheng, Ziqiao Weng, Yuanhuiyi Lyu, Danda Pani Paudel, Luc Van Gool, Kailun Yang, and Xum- ing Hu. Are multimodal large language models ready for omnidirectional spatial reasoning?arXiv preprint arXiv:2505.11907, 2025. 2
arXiv 2025
-
[15]
D2-net: A trainable cnn for joint detection and description of local features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint detection and description of local features. InCVPR 2019-IEEE Conference on Computer Vi- sion and Pattern Recognition, 2019. 3
2019
-
[16]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 3
1981
-
[17]
A graduated assignment algorithm for graph matching.IEEE Transactions on pattern analysis and machine intelligence, 18(4):377–388, 2002
Steven Gold and Anand Rangarajan. A graduated assignment algorithm for graph matching.IEEE Transactions on pattern analysis and machine intelligence, 18(4):377–388, 2002. 3
2002
-
[18]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025. 2, 3
2025
-
[19]
Projective reconstruction and invariants from multiple images.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 16(10):1036–1041, 1994
Richard I Hartley. Projective reconstruction and invariants from multiple images.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 16(10):1036–1041, 1994. 3
1994
-
[20]
Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE TPAMI, 2024
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE TPAMI, 2024. 1
2024
-
[21]
Zheng Huang, Mingyu Liu, Xiaoyi Lin, Muzhi Zhu, Canyu Zhao, Zongze Du, Xiaoman Li, Yiduo Jia, Hao Zhong, Hao Chen, et al. Notvla: Narrowing of dense action trajecto- ries for generalizable robot manipulation.arXiv preprint arXiv:2510.03895, 2025. 1
Pith/arXiv arXiv 2025
-
[22]
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete.arXiv preprint arXiv:2502.21257, 2025. 7
arXiv 2025
-
[23]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vi- sion language models.arXiv preprint arXiv:2506.03135,
-
[24]
Image matching across wide baselines: From paper to practice
Yuhe Jin, Dmytro Mishkin, Anastasiia Mishchuk, Jiri Matas, Pascal Fua, Kwang Moo Yi, and Eduard Trulls. Image matching across wide baselines: From paper to practice. arXiv preprint arXiv:2003.01587, 2020. 3
arXiv 2003
-
[25]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 1
2023
-
[26]
Building and better understanding vision- language models: Insights and future directions
Hugo Laurenc ¸on, Andr´es Marafioti, Victor Sanh, and L ´eo Tronchon. Building and better understanding vision- language models: Insights and future directions. InWork- shop on Responsibly Building the Next Generation of Multi- modal Foundational Models, 2024. 7
2024
-
[27]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, pages 22160–22169,
-
[28]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 7
2024
-
[29]
Zhang, Natalia Neverova, Andrea Vedaldi, Roman Shapovalov, and David Novotny
Xingchen Liu, Piyush Tayal, Jianyuan Wang, Jesus Zarzar, Tom Monnier, Konstantinos Tertikas, Jiali Duan, Antoine Toisoul, Jason Y . Zhang, Natalia Neverova, Andrea Vedaldi, Roman Shapovalov, and David Novotny. Uncommon objects in 3d. InarXiv, 2025. 3, 1
2025
-
[30]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
Pith/arXiv arXiv 2017
-
[31]
Distinctive image features from scale- invariant keypoints.International journal of computer vi- sion, 60(2):91–110, 2004
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vi- sion, 60(2):91–110, 2004. 3
2004
-
[32]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 6924–6934, 2025. 2
2025
-
[33]
Working hard to know your neighbor’s mar- gins: Local descriptor learning loss
Anastasiia Mishchuk, Dmytro Mishkin, Filip Radenovic, and Jiri Matas. Working hard to know your neighbor’s mar- gins: Local descriptor learning loss. InAdvances in neural information processing systems, pages 4826–4837, 2017. 3
2017
-
[34]
Gpt-4 technical report.CoRR, abs/2303.08774,
OpenAI. Gpt-4 technical report.CoRR, abs/2303.08774,
-
[35]
Hello gpt-4o.OpenAI Blog, 2024
OpenAI. Hello gpt-4o.OpenAI Blog, 2024. Accessed: November 22, 2024. 7
2024
-
[36]
Manivideo: Generating hand-object manipulation video with dexterous and generalizable grasping
Youxin Pang, Ruizhi Shao, Jiajun Zhang, Hanzhang Tu, Yun Liu, Boyao Zhou, Hongwen Zhang, and Yebin Liu. Manivideo: Generating hand-object manipulation video with dexterous and generalizable grasping. InCVPR, pages 12209–12219, 2025. 1
2025
-
[37]
Wide baseline stereo matching
Philip Pritchett and Andrew Zisserman. Wide baseline stereo matching. InICCV, pages 754–760. IEEE, 1998. 1
1998
-
[38]
Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kemb- havi, Bryan A. Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko. Sat: Dynamic spatial aptitude train- ing for multimodal language models.arXiv preprint arXiv:2412.07755, 2024. 2, 8
arXiv 2024
-
[39]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021. 3, 1
2021
-
[40]
R2d2: Repeatable and reliable detector and descrip- tor.arXiv preprint arXiv:1906.06195, 2019
J ´erˆome Revaud, Philippe Weinzaepfel, C´esar De Souza, No´e Pion, Gabriela Csurka, Yohann Cabon, and Martin Humen- berger. R2d2: Repeatable and reliable detector and descrip- tor.arXiv preprint arXiv:1906.06195, 2019. 3
Pith/arXiv arXiv 1906
-
[41]
Orb: An efficient alternative to sift or surf
Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. Orb: An efficient alternative to sift or surf. InInter- national conference on computer vision, pages 2564–2571. IEEE, 2011. 3
2011
-
[42]
PhD thesis, INRIA, 1995
Cordelia Schmid and Roger Mohr.Matching by local invari- ants. PhD thesis, INRIA, 1995. 1
1995
-
[43]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InCVPR, pages 4104–4113, 2016. 3, 4, 1
2016
-
[44]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 15768–15780, 2025. 2
2025
-
[45]
Dai, Anja Hauth, Katie Millican, et al
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, et al. Gem- ini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 7
Pith/arXiv arXiv 2023
-
[46]
Sosnet: Second order similarity reg- ularization for local descriptor learning
Yurun Tian, Xin Yu, Bin Fan, Fuchao Wu, Huub Heijnen, and Vassileios Balntas. Sosnet: Second order similarity reg- ularization for local descriptor learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11494–11503, 2019. 3
2019
-
[47]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 1
2025
-
[48]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.CoRR, abs/2409.12191, 2024. 1
Pith/arXiv arXiv 2024
-
[49]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InCVPR, pages 5261–5271, 2025. 1
2025
-
[50]
Site: towards spatial intelligence thorough evaluation.arXiv preprint arXiv:2505.05456,
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. Site: towards spatial intelligence thorough evaluation.arXiv preprint arXiv:2505.05456,
-
[51]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, et al. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245, 2025. 2
Pith/arXiv arXiv 2025
-
[52]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024. 8
2024
-
[53]
Realworldqa: Real-world visual question answering benchmark.https://x.ai/news/grok-1.5v, 2024
xAI. Realworldqa: Real-world visual question answering benchmark.https://x.ai/news/grok-1.5v, 2024. 8
2024
-
[54]
Runsen Xu, Weiyao Wang, Hao Tang, Xingyu Chen, Xi- aodong Wang, Fu-Jen Chu, Dahua Lin, Matt Feiszli, and Kevin J Liang. Multi-spatialmllm: Multi-frame spatial un- derstanding with multi-modal large language models.arXiv preprint arXiv:2505.17015, 2025. 2
Pith/arXiv arXiv 2025
-
[55]
Thinking in space: How mul- timodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 2
2025
-
[56]
Seeing from another perspective: Evaluating multi-view understanding in mllms
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, and Yi Ma. Seeing from another perspective: Evaluating multi-view understanding in mllms. arXiv preprint arXiv:2504.15280, 2025. 1
arXiv 2025
-
[57]
Mindcube: Spa- tial mental modeling from limited views.arXiv preprint arXiv:2506.21458, 2025
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chan- drasegaran, Han Liu, Ranjay Krishna, Saining Xie, Man- ling Li, Jiajun Wu, and Li Fei-Fei. Mindcube: Spa- tial mental modeling from limited views.arXiv preprint arXiv:2506.21458, 2025. 1, 8
arXiv 2025
-
[58]
Lmms- eval: Reality check on the evaluation of large multimodal models, 2024
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms- eval: Reality check on the evaluation of large multimodal models, 2024. 8
2024
-
[59]
Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024. 7
Pith/arXiv arXiv 2024
-
[60]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qing- song Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024. 8
Pith/arXiv arXiv 2024
-
[61]
Hao Zhong, Muzhi Zhu, Zongze Du, Zheng Huang, Canyu Zhao, Mingyu Liu, Wen Wang, Hao Chen, and Chunhua Shen. Omni-r1: Reinforcement learning for omnimodal reasoning via two-system collaboration.arXiv preprint arXiv:2505.20256, 2025. 2
arXiv 2025
-
[62]
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, et al. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics.arXiv preprint arXiv:2506.04308, 2025. 2
arXiv 2025
-
[63]
Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018. 3, 1
2018
-
[64]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.CoRR, abs/2504.10479, 2025. 1, 7
Pith/arXiv arXiv 2025
-
[65]
Sega- gent: Exploring pixel understanding capabilities in mllms by imitating human annotator trajectories
Muzhi Zhu, Yuzhuo Tian, Hao Chen, Chunluan Zhou, Qing- pei Guo, Yang Liu, Ming Yang, and Chunhua Shen. Sega- gent: Exploring pixel understanding capabilities in mllms by imitating human annotator trajectories. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3686–3696, 2025. 1
2025
-
[66]
Muzhi Zhu, Hao Zhong, Canyu Zhao, Zongze Du, Zheng Huang, Mingyu Liu, Hao Chen, Cheng Zou, Jingdong Chen, Ming Yang, et al. Active-o3: Empowering multimodal large language models with active perception via grpo.arXiv preprint arXiv:2505.21457, 2025. 1 Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching Supplementary Material
Pith/arXiv arXiv 2025
-
[67]
7 – Implementation Details:Complete specifi- cations of data generation pipeline, experimental setup, prompt template, and curriculum progression schedules
Appendix Overview This supplementary material provides comprehensive de- tails supporting our main paper, organized as follows: Sec. 7 – Implementation Details:Complete specifi- cations of data generation pipeline, experimental setup, prompt template, and curriculum progression schedules. Sec. 8 – Additional Ablations:Extended analyses on curriculum desig...
-
[68]
Implementation Details 7.1. Dataset Generation Correspondence Generation from RGB-D Data.Start- ing from RGB-D videos (or RGB with known intrinsics and camera-to-world poses), we back-project every pixel xwith valid depth in imageI 1 into a 3D pointXin the world coordinate system under a static-scene assumption, and reproject it to the consecutive imageI2...
-
[69]
Supervised Fine-tuning
Ablation Studies Reinforcement Learning vs. Supervised Fine-tuning. To assess our curriculum-based reinforcement learning ap- proach, we compare against supervised fine-tuning (SFT) on the same cross-view matching data. The SFT baseline uses 300 steps of supervised training with teacher-forced matching predictions, while our DCRL method employs re- inforc...
-
[70]
None” (F5).ReasonMatch-Bench includes regions that legitimately have no correspondence in the other view. F5 measures whether the model uses the “none
ReasonMatch-Bench Results In this section, we report detailed results on ReasonMatch- Bench and analyze how different multimodal LLMs be- have under our cross-view region matching task. We first summarize the overall quantitative performance across sce- narios and difficulty levels and then provide a fine-grained comparison along several error dimensions ...
-
[71]
1": "1",
Limitations and Future Work Despite substantial improvements over baselines, our ap- proach reveals both the promise and challenges of devel- oping human-level spatial intelligence in MLLMs. Our best model achieves 52.0% F1 compared to untrained hu- mans’ 84.0%, with the gap most pronounced on object- centric scenes where even humans struggle (27.8% vs. 6...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.