A 3D Isovist World Model -- Revealing a City's Unseen Geometry and Its Emergent Cross-City Signature
Pith reviewed 2026-06-28 09:51 UTC · model grok-4.3
The pith
A city-blind 3D isovist world model trained on Manhattan and Paris encodes city identity in its temporal dynamics rather than appearance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
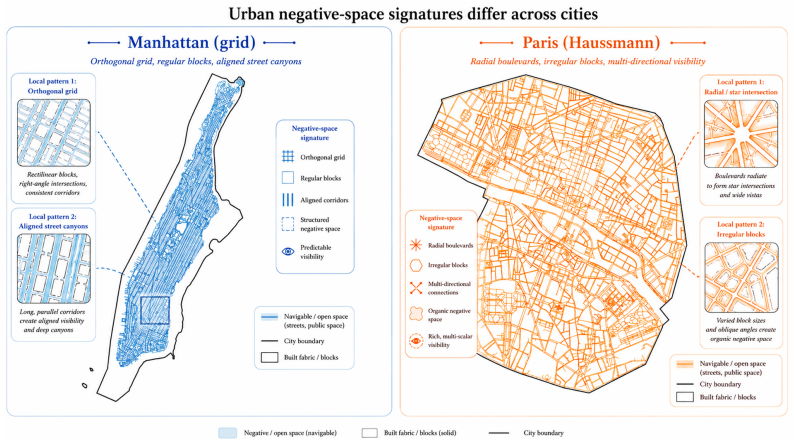
A single model trained to predict the next 3D isovist from a short history of past isovists and an action, using data from Manhattan and Paris, produces temporal latents from which city identity is linearly decodable far above single-frame baselines, showing that the cross-city signature lives in the learned dynamics rather than in appearance.
What carries the argument
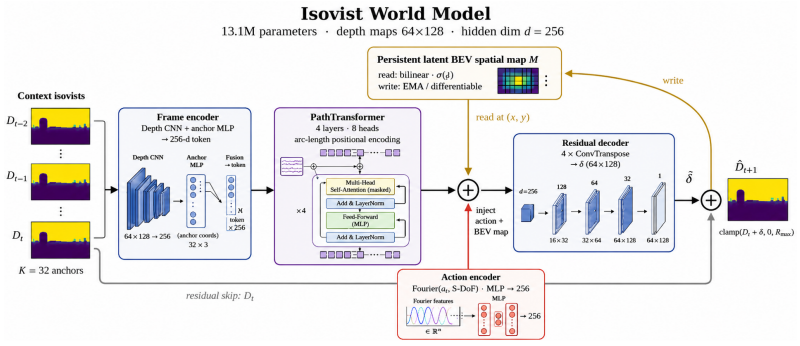
The 3D isovist, a spherical visibility-depth map recording distance to the nearest surface in every direction, serves as the predictive target that isolates navigable geometry.
If this is right
- The model supplies a geometric substrate for spatial reasoning in embodied AI and robotics that avoids appearance-based or flattened representations.
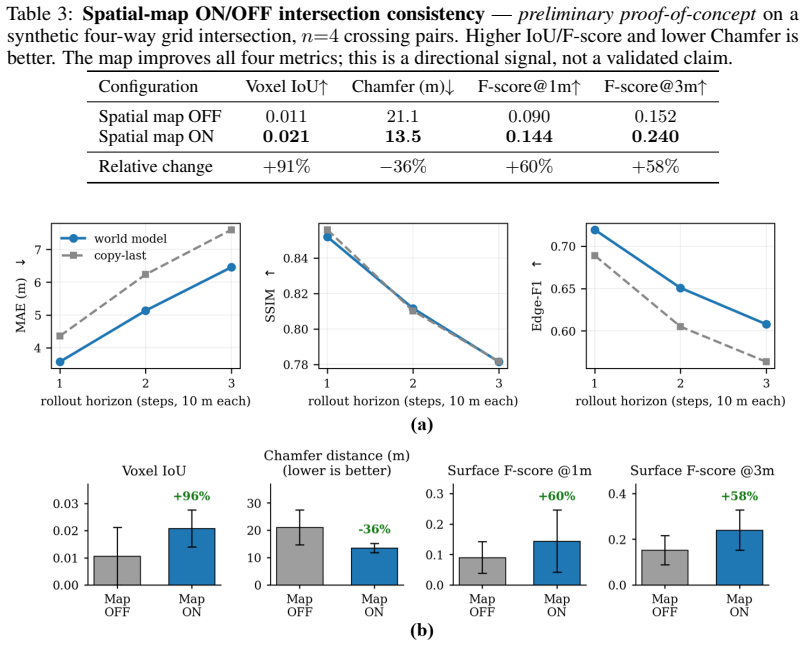
- A persistent latent bird's-eye-view spatial map maintains cross-path consistency during prediction.
- Self-rollout scheduled sampling during training keeps corrupted context on the geometry manifold.
- The representation is lightweight and interpretable, supporting urban analysis beyond the two training cities.
Where Pith is reading between the lines
- The same training procedure applied to additional cities could produce a broader taxonomy of urban spatial signatures based on movement dynamics.
- The temporal latents might support downstream tasks such as long-horizon planning that exploit the discovered city-specific patterns.
- Testing the decoder on simulated navigation in a third city would indicate whether the signature transfers or remains specific to the Manhattan-Paris pair.
Load-bearing premise
The 3D isovist representation captures the navigable geometry an agent actually traverses without photometric entanglement and without collapsing the third dimension.
What would settle it
If linear probes recover city identity from the model's temporal latents on held-out paths at rates no higher than from single-frame inputs, the claim that the signature resides in the learned dynamics would not hold.
Figures



read the original abstract
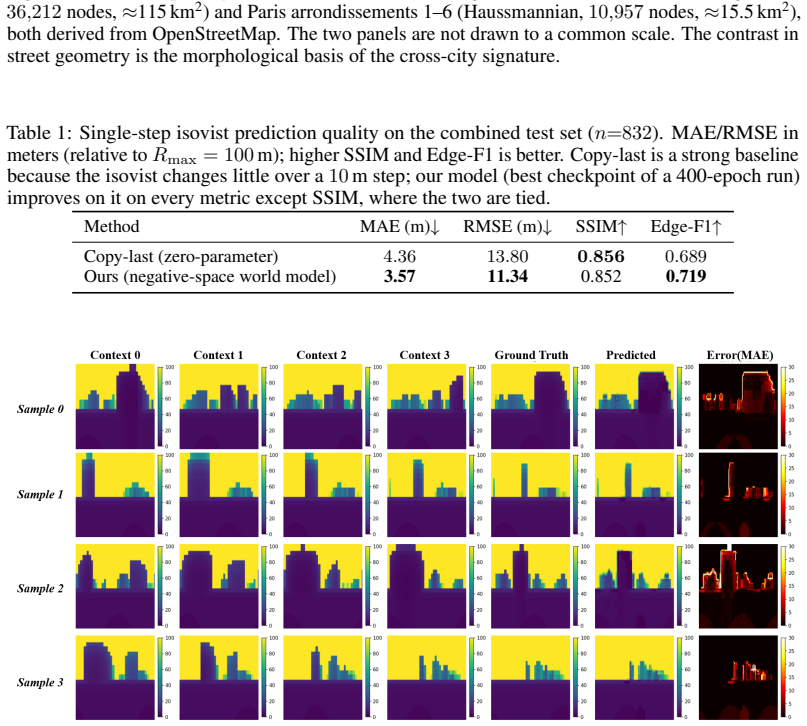
Embodied agents that navigate cities rely on world models that predict how their surroundings will change as they move. But for navigation, what matters is not what the buildings look like; it is where the agent can go. Most world models nonetheless predict appearance, learning how a scene looks rather than the space an agent can move through. Those that do target geometry, such as bird's-eye-view occupancy grids, flatten the three-dimensional environment onto a ground plane, discarding the above-ground and multi-level structure that shapes real navigation. What is missing is a predictive target that captures the navigable geometry an agent actually traverses, without photometric entanglement and without collapsing the third dimension. Our key idea is to model the open volume between buildings, the negative space, encoded as a 3D isovist: a spherical visibility-depth map recording the distance to the nearest surface in every direction. We introduce an embodied world model that predicts the next isovist from a short history of past isovists and a movement action. The prediction is formulated as a depth residual so the decoder inherits sharp building edges, trained with self-rollout scheduled sampling to keep corrupted context on the geometry manifold, and equipped with a persistent latent bird's-eye-view spatial map for cross-path consistency. Our central finding is emergent and unexpected: a single city-blind model trained on Manhattan and Paris develops a cross-city spatial signature, with city identity linearly decodable from its temporal latents far above single-frame baselines, so the signature lives in the learned dynamics rather than in appearance. The representation is lightweight, interpretable, and reproducible, offering a geometric substrate for spatial reasoning in embodied AI, robotics, and urban analysis, released with an open dataset and pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a 3D isovist world model that predicts navigable geometry via spherical visibility-depth maps from short histories of past isovists and actions, formulated as depth residuals with self-rollout training and a persistent latent BEV map for consistency. Trained city-blind on Manhattan and Paris data, the model yields an emergent cross-city spatial signature in which city identity is linearly decodable from temporal latents at rates far above single-frame baselines, indicating the signature resides in learned dynamics rather than appearance. The representation is positioned as lightweight and interpretable for embodied AI, with an open dataset and pipeline released.
Significance. If the central claim is isolated from confounds, the work supplies a geometric inductive bias for world models that avoids photometric entanglement and 2D collapse, with potential utility in robotics navigation and urban analysis. The open release of data and code is a clear strength supporting reproducibility. The unexpected emergence of a cross-city signature from dynamics is noteworthy if properly attributed.
major comments (2)
- [Model description (abstract and methods)] The central claim (abstract) that 'the signature lives in the learned dynamics rather than in appearance' rests on linear decodability from temporal latents exceeding single-frame baselines. However, the architecture description includes a persistent latent bird's-eye-view spatial map for cross-path consistency; without an explicit ablation (e.g., decoding performance with the BEV map removed or separate decoding from BEV latents alone), it remains possible that city identity information aggregates in the BEV component and transfers to temporal latents via shared processing, undermining isolation of the dynamics contribution.
- [Experimental results (abstract)] The abstract reports decoding 'far above single-frame baselines' but provides no quantitative values, error bars, statistical tests, or details on how single-frame baselines are constructed relative to the full temporal model. This information is load-bearing for the claim that the signature is dynamics-specific rather than static geometry.
minor comments (2)
- [Abstract] The abstract is information-dense; separating the model description from the emergent finding into distinct sentences would improve readability.
- [Abstract] Notation for the 3D isovist (spherical visibility-depth map) and the depth residual formulation could be introduced with a brief equation or diagram reference for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing where revisions are needed to strengthen the claims and providing clarifications on the architecture and results.
read point-by-point responses
-
Referee: [Model description (abstract and methods)] The central claim (abstract) that 'the signature lives in the learned dynamics rather than in appearance' rests on linear decodability from temporal latents exceeding single-frame baselines. However, the architecture description includes a persistent latent bird's-eye-view spatial map for cross-path consistency; without an explicit ablation (e.g., decoding performance with the BEV map removed or separate decoding from BEV latents alone), it remains possible that city identity information aggregates in the BEV component and transfers to temporal latents via shared processing, undermining isolation of the dynamics contribution.
Authors: We acknowledge the validity of this concern. The persistent latent BEV map is designed to enforce cross-path spatial consistency, but its potential role in carrying city-specific information that could propagate to the temporal latents is not explicitly ruled out by the current experiments. The single-frame baseline uses only the current isovist input without temporal history, while the full model incorporates sequence processing, yet this does not fully isolate the BEV's contribution. We will add an ablation study in the revision, including decoding performance with the BEV map removed and separate decoding from BEV latents alone, to better attribute the signature to the learned dynamics. revision: yes
-
Referee: [Experimental results (abstract)] The abstract reports decoding 'far above single-frame baselines' but provides no quantitative values, error bars, statistical tests, or details on how single-frame baselines are constructed relative to the full temporal model. This information is load-bearing for the claim that the signature is dynamics-specific rather than static geometry.
Authors: We agree that the abstract should include these quantitative details to support the central claim. The body of the manuscript contains the relevant decoding accuracies, but they are not summarized in the abstract with error bars or statistical tests, nor is the baseline construction (single-frame vs. temporal history) explicitly described there. We will revise the abstract to report the specific values (e.g., temporal latent decoding accuracy with standard deviation and p-value compared to single-frame), along with a brief description of baseline construction. revision: yes
Circularity Check
No significant circularity; central claim is an experimental observation from cross-city training and decoding tests.
full rationale
The paper's derivation chain consists of defining a 3D isovist representation, training a predictive world model with a decoder and persistent BEV map, and then reporting an emergent experimental result: city identity is linearly decodable from temporal latents above single-frame baselines. No step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. The signature claim is presented as an unexpected outcome of training on Manhattan and Paris data, not as a quantity defined via the model's own equations or prior self-citations. The architecture details (e.g., BEV for consistency) are design choices, not load-bearing justifications that loop back to the target finding. This matches the default case of a self-contained experimental paper against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D isovists capture navigable geometry without photometric entanglement and without collapsing the third dimension
Reference graph
Works this paper leans on
-
[1]
Environment and Planning B: Planning and Design , volume =
To take hold of space: isovists and isovist fields , author =. Environment and Planning B: Planning and Design , volume =. 1979 , publisher =
1979
-
[2]
Environment and Planning B: Planning and Design , volume =
From isovists to visibility graphs: a methodology for the analysis of architectural space , author =. Environment and Planning B: Planning and Design , volume =. 2001 , publisher =
2001
-
[3]
Environment and Planning B: Planning and Design , volume =
From space syntax to space semantics: a behaviorally and perceptually oriented methodology for the efficient description of the geometry and topology of environments , author =. Environment and Planning B: Planning and Design , volume =. 2008 , publisher =
2008
-
[4]
1984 , publisher =
The Social Logic of Space , author =. 1984 , publisher =
1984
-
[5]
Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David , booktitle =
-
[6]
Sun, Jiaming and others , journal =
-
[7]
Corsetti, Matteo and others , journal =
-
[8]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second , author =. arXiv preprint arXiv:2410.02073 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Piccinelli, Luigi and Yang, Yung-Hsu and Sakaridis, Christos and Segu, Mattia and Li, Siyuan and Van Gool, Luc and Yu, Fisher , booktitle =
-
[10]
and Tancik, Matthew and Barron, Jonathan T
Mildenhall, Ben and Srinivasan, Pratul P. and Tancik, Matthew and Barron, Jonathan T. and Ramamoorthi, Ravi and Ng, Ren , booktitle =
-
[11]
ACM Transactions on Graphics , volume =
Kerbl, Bernhard and Kopanas, Georgios and Leimk. ACM Transactions on Graphics , volume =
-
[12]
Ortiz, Joseph and Clegg, Alexander and Dong, Jing and Sucar, Edgar and Nowrouzezahrai, Derek and Sherrill, Conor and Mukadam, Mustafa , booktitle =
-
[13]
Cosmos World Foundation Models for Physical
Agarwal, Niket and Ali, Ahmed and Bala, Maciej and Balaji, Yogesh and Barker, Erik and Cai, Tiffany and others , journal =. Cosmos World Foundation Models for Physical
-
[14]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author =. arXiv preprint arXiv:2503.20314 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint , note =
Aether: Geometric-Aware World Models for Physical. arXiv preprint , note =
-
[16]
Yang, Ze and Chen, Yun and Wang, Jingkang and Hu, Sivabalan and Li, Ze and Gaidon, Adrien and Urtasun, Raquel , booktitle =
-
[17]
Wang, Xiaofeng and Zhu, Zheng and Huang, Guan and Chen, Xinze and Lu, Jiwen , booktitle =
-
[18]
Zheng, Wenzhao and Chen, Weiliang and Huang, Yuanhui and Zhang, Borui and Duan, Yueqi and Lu, Jiwen , booktitle =
-
[19]
Genad: Generalized predictive model for autonomous driving.arXiv preprint arXiv:2403.09630, 2024
Generalized Predictive Model for Autonomous Driving , author =. arXiv preprint arXiv:2403.09630 , note =
-
[20]
World Models , author =. arXiv preprint arXiv:1803.10122 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
International Conference on Learning Representations (ICLR) , year =
Dream to Control: Learning Behaviors by Latent Imagination , author =. International Conference on Learning Representations (ICLR) , year =
-
[22]
European Conference on Computer Vision (ECCV) , pages =
Group Normalization , author =. European Conference on Computer Vision (ECCV) , pages =
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[24]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Deep Residual Learning for Image Recognition , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[27]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[28]
Layer Normalization , author =. arXiv preprint arXiv:1607.06450 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Spatial Cognition V: Reasoning, Action, Interaction , pages =
The isovist concept — its relevance to spatial cognition and spatial behavior , author =. Spatial Cognition V: Reasoning, Action, Interaction , pages =. 2007 , publisher =
2007
-
[30]
Occupancy Networks: Learning
Mescheder, Lars and Oechsle, Michael and Niemeyer, Michael and Nowozin, Sebastian and Geiger, Andreas , booktitle =. Occupancy Networks: Learning
-
[31]
and Pollefeys, Marc , booktitle =
Zhu, Zihan and Peng, Songyou and Larsson, Viktor and Xu, Weiwei and Bao, Hujun and Cui, Zhaopeng and Oswald, Martin R. and Pollefeys, Marc , booktitle =
-
[32]
Nature Machine Intelligence , volume =
Automated construction of cognitive maps with visual predictive coding , author =. Nature Machine Intelligence , volume =. 2024 , publisher =
2024
-
[33]
Nature , volume =
Vector-based navigation using grid-like representations in artificial agents , author =. Nature , volume =. 2018 , publisher =
2018
-
[34]
International Conference on Learning Representations (ICLR) , year =
Emergence of grid-like representations by training recurrent neural networks to perform spatial localization , author =. International Conference on Learning Representations (ICLR) , year =
-
[35]
Mastering Diverse Domains through World Models
Mastering Diverse Domains through World Models , author =. arXiv preprint arXiv:2301.04104 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
International Conference on Machine Learning (ICML) , year =
Genie: Generative Interactive Environments , author =. International Conference on Machine Learning (ICML) , year =
-
[37]
Xie, Haozhe and Chen, Zhaoxi and Hong, Fangzhou and Liu, Ziwei , booktitle =
-
[38]
Chen, Zhaoxi and Wang, Guangcong and Liu, Ziwei , journal =
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[40]
Communications of the ACM , volume =
Datasheets for Datasets , author =. Communications of the ACM , volume =. 2021 , publisher =
2021
-
[41]
2024 , howpublished =
2024
-
[42]
2024 , note =
Che, Yangzi and others , journal =. 2024 , note =
2024
-
[43]
Environment and Planning B: Planning and Design , volume =
Exploring Isovist Fields: Space and Shape in Architectural and Urban Morphology , author =. Environment and Planning B: Planning and Design , volume =. 2001 , doi =
2001
-
[44]
A Digital Image of the City:
Morello, Eugenio and Ratti, Carlo , journal =. A Digital Image of the City:. 2009 , doi =
2009
-
[45]
2008 , doi =
Haklay, Mordechai and Weber, Patrick , journal =. 2008 , doi =
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.