Enhancing Operational Safety via Agentic Dialogue Hazard Identification Analysis
Pith reviewed 2026-06-28 09:41 UTC · model grok-4.3
The pith
Structured multi-agent dialogue improves NLP-based hazard identification over single-pass LLM baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
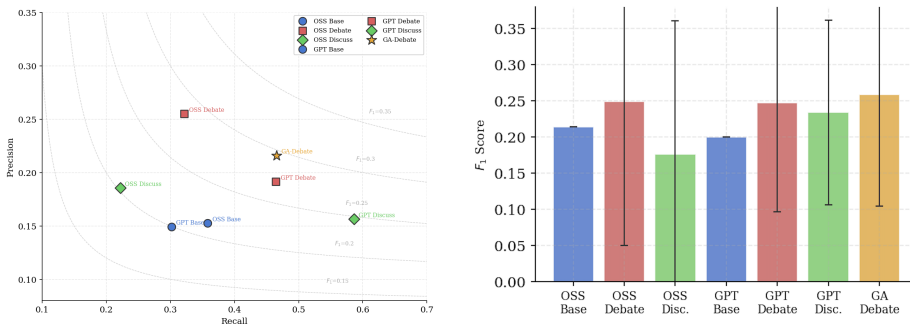
The HAZDIAL framework demonstrates that structured agentic dialogue, implemented through adversarial debate or constructive discussion among multiple agents, produces higher-quality hazard identifications than single-pass LLM inference when measured by accuracy, precision, recall, F1, and novel dialogue metrics on a curated golden dataset.
What carries the argument
HAZDIAL, a multi-agent multi-turn dialogue framework that enables iterative self-correction and contextual refinement for hazard analysis.
If this is right
- Multi-turn agent interactions reduce the brittleness of single-turn LLM outputs in safety tasks.
- Both adversarial debate and constructive discussion modalities outperform monolithic inference on the reported metrics.
- Novel dialogue metrics provide a way to quantify deliberation quality beyond final classification scores.
- Algorithm-based optimization of agent interactions can be used to tune the dialogue process for better results.
Where Pith is reading between the lines
- The same dialogue structure might be tested on other iterative reasoning tasks such as root-cause analysis or regulatory compliance checks.
- Real-time operational use would require evaluating performance on live, non-curated inputs rather than pre-selected golden sets.
- Pairing the agent dialogue with human review loops could be measured for combined error reduction in actual safety workflows.
Load-bearing premise
The curated golden dataset represents real operational hazards and the chosen metrics measure actual gains in safety-analysis quality rather than surface text properties.
What would settle it
A new evaluation on an independently collected set of real incident hazards showing no metric improvement for either dialogue mode over single-pass baselines would falsify the central claim.
Figures

read the original abstract
Operational safety in high-stakes domains such as industrial process control, autonomous, and safety-critical systems, demand reliable hazard identification. While large language models (LLMs) have shown promise in automating safety analysis tasks, single-turn, monolithic inference is brittle: it lacks the self-correction, deliberation, and contextual refinement that safety engineers apply iteratively. In this paper, we introduce HAZDIAL, a framework that investigates whether structured agentic dialogue-multi-agent, multi-turn interactions improves the quality of NLP- based hazard identification over single-pass baselines. We systematically compare two dialogue modalities: adversarial debate and constructive discussion, and propose an algorithm-based agentic interaction optimization. We evaluate all configurations against a curated golden dataset using standard classification metrics (accuracy, precision, recall, F1) and novel dialogue metrics. This work advances the intersection of dialogue systems, multi-agent reasoning, and AI safety, providing an empirical evidence for dialogue-driven hazard analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the HAZDIAL framework for structured agentic dialogue (adversarial debate and constructive discussion) to improve LLM-based hazard identification in safety-critical domains over single-pass baselines. It proposes an algorithm-based optimization for agentic interactions and claims to evaluate all configurations on a curated golden dataset using accuracy, precision, recall, F1, and novel dialogue metrics, thereby providing empirical evidence for dialogue-driven improvements in operational safety analysis.
Significance. If supported by results, the work would be significant for integrating multi-agent dialogue systems with AI safety applications, potentially offering a more robust alternative to monolithic LLM inference for iterative hazard analysis. The emphasis on novel dialogue metrics could advance evaluation practices in this intersection of fields. However, the manuscript supplies no numerical results, dataset statistics, baseline values, or error analysis, rendering the claimed improvements unverifiable and the practical significance for real-world safety currently unassessable.
major comments (3)
- [Abstract] Abstract and evaluation description: The manuscript states that it 'evaluate[s] all configurations against a curated golden dataset using standard classification metrics... and novel dialogue metrics' and 'provid[es] an empirical evidence,' yet supplies no numerical results, dataset statistics, baseline comparisons, or error analysis. This absence is load-bearing for the central claim of measurable improvement via agentic dialogue.
- [Evaluation] Dataset section (implied by evaluation claim): No information is given on golden dataset construction, including source material, hazard coverage, annotation protocol, or inter-rater reliability. Without these details, it cannot be determined whether the dataset is representative of real operational hazards, directly affecting the validity of any accuracy/precision/recall/F1 gains.
- [Evaluation] Metrics section: The 'novel dialogue metrics' are referenced but neither defined nor shown to correlate with downstream safety outcomes rather than surface properties such as dialogue length or lexical overlap. This undermines the claim that the metrics validly measure improvements in safety-analysis quality.
minor comments (1)
- [Abstract] Abstract: Minor grammatical issues include 'demand reliable' (should be 'demands reliable') and 'providing an empirical evidence' (should be 'providing empirical evidence').
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important gaps in the presentation of empirical results and supporting details. We agree that these elements are necessary to substantiate the central claims and will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: The manuscript states that it 'evaluate[s] all configurations against a curated golden dataset using standard classification metrics... and novel dialogue metrics' and 'provid[es] an empirical evidence,' yet supplies no numerical results, dataset statistics, baseline comparisons, or error analysis. This absence is load-bearing for the central claim of measurable improvement via agentic dialogue.
Authors: We acknowledge that the submitted manuscript does not include the specific numerical results, statistics, or error analysis in the main text. In the revised version we will add a complete results section reporting accuracy, precision, recall, and F1 scores for all configurations and baselines, along with dataset statistics and error analysis to make the claimed improvements verifiable. revision: yes
-
Referee: [Evaluation] Dataset section (implied by evaluation claim): No information is given on golden dataset construction, including source material, hazard coverage, annotation protocol, or inter-rater reliability. Without these details, it cannot be determined whether the dataset is representative of real operational hazards, directly affecting the validity of any accuracy/precision/recall/F1 gains.
Authors: We will expand the evaluation section with a detailed description of the golden dataset, covering its source material, hazard coverage, annotation protocol, and inter-rater reliability metrics. This addition will allow readers to assess representativeness and the validity of the reported gains. revision: yes
-
Referee: [Evaluation] Metrics section: The 'novel dialogue metrics' are referenced but neither defined nor shown to correlate with downstream safety outcomes rather than surface properties such as dialogue length or lexical overlap. This undermines the claim that the metrics validly measure improvements in safety-analysis quality.
Authors: We will define the novel dialogue metrics with explicit formulas and descriptions in the revised metrics subsection. We will also add discussion or preliminary validation showing their relationship to safety-relevant outcomes beyond surface features, to strengthen the justification for their use. revision: yes
Circularity Check
No circularity: empirical evaluation with no derivations or self-referential reductions
full rationale
The paper introduces HAZDIAL as an empirical framework for comparing multi-agent dialogue modalities (adversarial debate, constructive discussion) against single-pass baselines on a curated golden dataset, using accuracy/precision/recall/F1 and novel dialogue metrics. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is a direct empirical comparison that does not reduce by construction to its inputs or prior author work; dataset construction and metric validity are external assumptions, not circular steps. This is the expected non-finding for an empirical methods paper without mathematical self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tenenbaum and Igor Mordatch , title =
Yilun Du and Shuang Li and Antonio Torralba and Joshua B. Tenenbaum and Igor Mordatch , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[2]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Tian Liang and Zhiwei He and Wenxiang Jiao and Xing Wang and Yan Wang and Rui Wang and Yue Zhang and Zhaopeng Tu and Shuming Shi , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2024
-
[3]
Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
Chi-Min Chan and Weize Chen and Yusheng Su and Jianxuan Yu and Wei Xue and Shanghang Zhang and Jie Fu and Zhiyuan Liu , title =. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
-
[4]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and ...
2020
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed Chi and Quoc Le and Denny Zhou , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Takeshi Kojima and Shixiang Shane Gu and Machel Reid and Yutaka Matsuo and Yusuke Iwasawa , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[7]
Griffiths and Yuan Cao and Karthik Narasimhan , title =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Thomas L. Griffiths and Yuan Cao and Karthik Narasimhan , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2023 , url =
2023
-
[8]
Proceedings of the 11th International Conference on Learning Representations (ICLR) , year =
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc Le and Ed Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. Proceedings of the 11th International Conference on Learning Representations (ICLR) , year =
-
[9]
Proceedings of the 11th International Conference on Learning Representations (ICLR) , year =
Peiyi Wang and Lei Li and Liang Chen and Zefan Cai and Dawei Zhu and Binghuai Lin and Yunbo Cao and Qi Liu and Tianyu Liu and Zhifang Sui , title =. Proceedings of the 11th International Conference on Learning Representations (ICLR) , year =
-
[10]
ACM Computing Surveys , volume =
Ziwei Ji and Nayeon Lee and Rita Frieske and Tiezheng Yu and Dan Su and Yan Xu and Etsuko Ishii and Yejin Bang and Andrea Madotto and Pascale Fung , title =. ACM Computing Surveys , volume =. 2023 , doi =
2023
-
[11]
O'Brien and Carrie J
Joon Sung Park and Joseph C. O'Brien and Carrie J. Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[12]
Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
Miao Xiong and Zhiyuan Hu and Xinyang Lu and YIFEI LI and Jie Fu and Junxian He and Bryan Hooi , title =. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
-
[13]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. Proceedings of the 10th International Conference on Learning Representations (ICLR) , year =
-
[14]
Proceedings of the 2021 international conference on management of data , pages=
Auto-fuzzyjoin: Auto-program fuzzy similarity joins without labeled examples , author=. Proceedings of the 2021 international conference on management of data , pages=
2021
-
[15]
European conference on information retrieval , pages=
A probabilistic interpretation of precision, recall and F-score, with implication for evaluation , author=. European conference on information retrieval , pages=. 2005 , organization=
2005
-
[16]
, author=
How does GPT-4.1 comprehend conversational implicatures? Reasoning with contextual alternatives in discourse frames. , author=. Linguistic Research , volume=
-
[17]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[18]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[19]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[20]
arXiv preprint arXiv:2411.13757 , year=
Genbfa: An evolutionary optimization approach to bit-flip attacks on llms , author=. arXiv preprint arXiv:2411.13757 , year=
-
[21]
arXiv preprint arXiv:2104.01459 , year=
A surrogate loss function for optimization of F\_ score in binary classification with imbalanced data , author=. arXiv preprint arXiv:2104.01459 , year=
-
[22]
Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B
Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul Christiano and Geoffrey Irving , title =. arXiv preprint arXiv:1909.08593 , year =
Pith/arXiv arXiv 1909
-
[23]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Jiwei Li and Will Monroe and Alan Ritter and Michel Galley and Jianfeng Gao and Dan Jurafsky , title =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2016 , url =
2016
-
[24]
Williams , title =
Ronald J. Williams , title =. Machine Learning , volume =. 1992 , doi =
1992
-
[25]
Nils Reimers and Iryna Gurevych , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =. 2019 , url =
2019
-
[26]
Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
Qingyan Guo and Rui Wang and Junliang Guo and Bei Li and Kaitao Song and Xu Tan and Guoqing Liu and Jiang Bian and Yujiu Yang , title =. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
-
[27]
2018 , publisher=
Hazop & Hazan: identifying and assessing process industry hazards , author=. 2018 , publisher=
2018
-
[28]
2003 , publisher=
Failure mode and effect analysis , author=. 2003 , publisher=
2003
-
[29]
1981 , institution =
Fault tree handbook , author=. 1981 , institution =
1981
-
[30]
Leveson , title =
Nancy G. Leveson , title =
-
[31]
Safety science , volume=
Learning about risk: Machine learning for risk assessment , author=. Safety science , volume=. 2019 , publisher=
2019
-
[32]
International Journal of Environmental Research and Public Health , volume =
Atsuo Murata and Takami Nakamura and Waldemar Karwowski , title =. International Journal of Environmental Research and Public Health , volume =. 2020 , doi =
2020
-
[33]
Proceedings of the Annual Reliability and Maintainability Symposium (RAMS) , year =
Jianwei Liao and Yue Zhang and Others , title =. Proceedings of the Annual Reliability and Maintainability Symposium (RAMS) , year =
-
[34]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Pranav Rajpurkar and Robin Jia and Percy Liang , title =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =. 2018 , url =
2018
-
[35]
Journal of System Safety , volume=
Overview of the second edition of iso 26262: Functional safety—road vehicles , author=. Journal of System Safety , volume=
-
[36]
2024 , url =
OpenAI , title =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.