GARDEN: Gravity-Aligned Reconstruction of Disentangled ENvironments from RGB images
Pith reviewed 2026-06-28 10:38 UTC · model grok-4.3
The pith
Gravity alignment from RGB images produces disentangled 3D scenes with explicit rigid bodies for direct physics simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
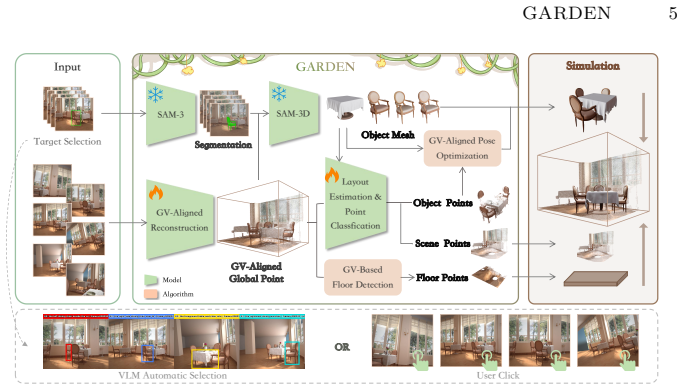
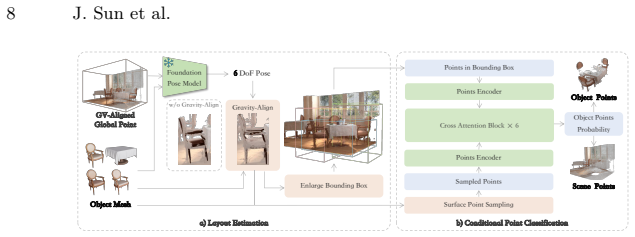
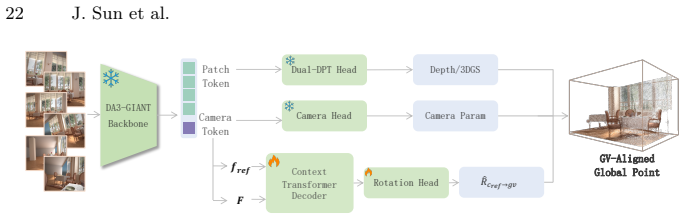
GARDEN reformulates reconstruction as physically-grounded scene factorization using gravity as a universal prior: it aligns to a Gravity-View frame to resolve gauge ambiguity, recovers object-centric rigid meshes with accurate placement, and removes duplicate geometry from the background via conditional 3D point classification, yielding explicit rigid bodies decoupled from background geometry.
What carries the argument
Gravity-View frame alignment combined with conditional 3D point classification to disentangle rigid objects from background.
If this is right
- Object placement becomes more reliable in reconstructed scenes.
- Disentanglement quality improves over retrieval-based methods.
- Rendering and simulation efficiency increases due to the structured representation.
- Direct physics simulation is possible without replacing objects with CAD assets.
Where Pith is reading between the lines
- Scenes with strong vertical structure would benefit most from this gravity prior.
- The method could extend to videos by tracking gravity-aligned objects over time.
- Integration with other physical priors like friction might further enhance simulation fidelity.
Load-bearing premise
Gravity direction can be reliably estimated from RGB images alone and acts as a universal prior that resolves scene rotation ambiguity.
What would settle it
A set of multi-view RGB images from a scene where gravity estimation from images fails to match the true direction, leading to misaligned objects that cannot be simulated stably.
Figures
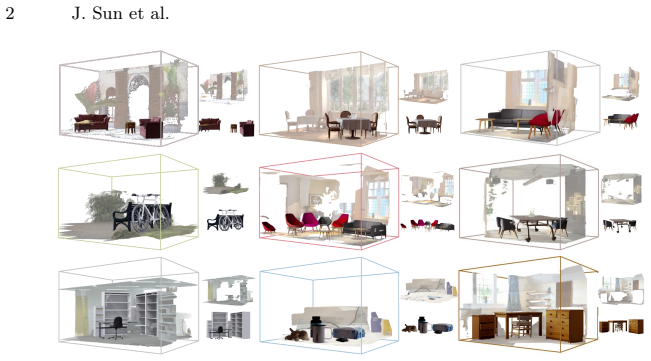



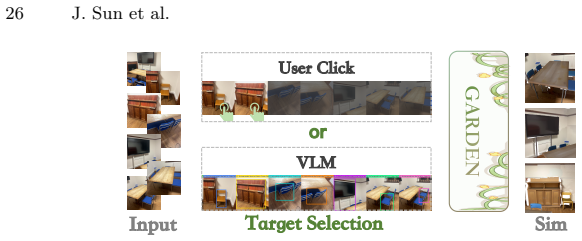


read the original abstract
Converting multi-view RGB observations into simulation-ready 3D environments remains challenging because current reconstruction pipelines produce monolithic scene representations without explicit physical structure. They are typically defined up to an arbitrary global rotation and entangle rigid foreground objects with background geometry, which hinders stable physical interaction. Existing solutions often recover interactivity by replacing reconstructed objects with retrieved CAD assets, but this introduces a slow retrieval-and-replacement stage and weakens scene-specific geometric fidelity. We propose GARDEN, an RGB-only framework that reformulates reconstruction as physically-grounded scene factorization and outputs a structured hybrid scene representation. The key idea is to use gravity as a universal physical prior: we first align the reconstruction to a unified Gravity-View frame to resolve gauge ambiguity, then recover object-centric rigid meshes with accurate 6-DoF placement, and finally remove duplicate object geometry from the background through conditional 3D point classification. The resulting representation combines explicit rigid bodies with a decoupled background, enabling direct physics simulation while preserving visual realism. Experiments on both simulated and real multi-view scenes show that GARDEN improves object placement reliability, disentanglement quality, and rendering-simulation efficiency compared with retrieval-based baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GARDEN, an RGB-only pipeline that factorizes multi-view scene reconstructions into explicit rigid foreground objects and a decoupled background by first aligning to a gravity-defined frame (to resolve gauge ambiguity), then recovering object-centric meshes with 6-DoF poses, and finally applying conditional 3D point classification to remove duplicate geometry. The resulting hybrid representation is intended to support direct physics simulation while preserving visual realism, with claimed gains over retrieval-based baselines on simulated and real multi-view data.
Significance. If the quantitative claims hold, the work would offer a meaningful step toward physically grounded, simulation-ready scene representations from images alone, avoiding the geometric compromises of CAD replacement while addressing rotational gauge freedom via an external physical prior. The gravity-alignment idea is a clean way to inject structure without learned parameters, and the disentanglement step could improve downstream robotics and AR applications if robust.
major comments (2)
- [Abstract] Abstract (key idea paragraph): The pipeline's first step requires reliable gravity-direction estimation from RGB alone as a 'universal physical prior' independent of scene content. Standard monocular estimators (horizon or vertical-line detection) are known to degrade in textureless, indoor, or natural scenes lacking consistent vertical structure; if this alignment fails, the subsequent 6-DoF placement and conditional point classification become ill-posed, directly undermining the central claim of stable physics-ready output.
- [Abstract] Abstract: The manuscript asserts 'improvements in object placement reliability, disentanglement quality, and rendering-simulation efficiency' yet supplies no quantitative metrics, error bars, dataset sizes, ablation studies, or baseline comparisons. Without these, the experimental support for the central claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the gravity alignment assumption and the presentation of experimental claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (key idea paragraph): The pipeline's first step requires reliable gravity-direction estimation from RGB alone as a 'universal physical prior' independent of scene content. Standard monocular estimators (horizon or vertical-line detection) are known to degrade in textureless, indoor, or natural scenes lacking consistent vertical structure; if this alignment fails, the subsequent 6-DoF placement and conditional point classification become ill-posed, directly undermining the central claim of stable physics-ready output.
Authors: We agree that gravity estimation from RGB is a critical prerequisite and that monocular methods can be unreliable in textureless or unstructured scenes. The manuscript presents gravity alignment as an external physical prior obtained via standard RGB-based estimators (e.g., vertical vanishing points). In the evaluated simulated and real multi-view scenes, these estimates were sufficiently accurate to enable stable 6-DoF placement and classification. We will add a limitations paragraph discussing estimator failure modes and their potential impact on the pipeline. revision: partial
-
Referee: [Abstract] Abstract: The manuscript asserts 'improvements in object placement reliability, disentanglement quality, and rendering-simulation efficiency' yet supplies no quantitative metrics, error bars, dataset sizes, ablation studies, or baseline comparisons. Without these, the experimental support for the central claim cannot be evaluated.
Authors: The abstract is intended as a concise summary. Full quantitative results—including metrics with error bars, dataset sizes, ablation studies, and comparisons to retrieval-based baselines on simulated and real data—are reported in the Experiments section. We will revise the abstract to incorporate one or two key quantitative highlights to better support the claims at the summary level. revision: yes
Circularity Check
No circularity; gravity prior is external and independent of outputs
full rationale
The paper presents gravity alignment as an external physical prior applied to RGB inputs to resolve gauge ambiguity before factorization into rigid objects and background. No equations, fitted parameters, or self-citations are shown that reduce any claimed prediction or uniqueness result to the method's own outputs by construction. The derivation chain remains self-contained against external benchmarks because the key step invokes a scene-independent prior rather than a quantity defined from the reconstruction itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gravity direction can be estimated from RGB images and used to resolve reconstruction gauge ambiguity
Reference graph
Works this paper leans on
-
[1]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotny. Vggt: Visual geometry grounded transformer. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[2]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[3]
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He.π 3: Permutation- Equivariant Visual Geometry Learning.arXiv preprint arXiv:2507.13347, 2025
Pith/arXiv arXiv 2025
-
[4]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[5]
Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
2022
-
[6]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[7]
A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
2022
-
[8]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[9]
Isaac gym: High performance gpu-based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[10]
Hamid Izadinia, Qi Shan, and Steven M Seitz. Im2cad. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5134–5143, 2017
2017
-
[11]
Mask2cad: 3d shape prediction by learning to segment and retrieve
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. Mask2cad: 3d shape prediction by learning to segment and retrieve. InEuropean Conference on Computer Vision, pages 260–277. Springer, 2020. GARDEN17
2020
-
[12]
Florian Langer, Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. Sparc: Sparse render-and-compare for cad model alignment in a single rgb image.arXiv preprint arXiv:2210.01044, 2022
arXiv 2022
-
[13]
Litereality: Graphic-ready 3d scene reconstruction from rgb-d scans
Zhening Huang, Xiaoyang Wu, Fangcheng Zhong, Hengshuang Zhao, Matthias Nießner, and Joan Lasenby. Litereality: Graphic-ready 3d scene reconstruction from rgb-d scans. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[14]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[15]
Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Pith/arXiv arXiv 2025
-
[16]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024
2024
-
[17]
Kinectfusion: real-time 3d reconstruction and interaction using a moving depthcamera
Shahram Izadi, David Kim, Otmar Hilliges, David Molyneaux, Richard Newcombe, Pushmeet Kohli, Jamie Shotton, Steve Hodges, Dustin Freeman, Andrew Davison, et al. Kinectfusion: real-time 3d reconstruction and interaction using a moving depthcamera. InProceedings of the 24th annual ACM symposium on User interface software and technology, pages 559–568, 2011
2011
-
[18]
Poisson surface recon- struction
Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface recon- struction. InProceedings of the fourth Eurographics symposium on Geometry pro- cessing, volume 7, 2006
2006
-
[19]
Real- time3dreconstructionatscaleusingvoxelhashing.ACM Transactions on Graphics (ToG), 32(6):1–11, 2013
Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Marc Stamminger. Real- time3dreconstructionatscaleusingvoxelhashing.ACM Transactions on Graphics (ToG), 32(6):1–11, 2013
2013
-
[20]
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5855–5864, 2021
2021
-
[21]
Zip-nerf: Anti-aliased grid-based neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid-based neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19697–19705, 2023
2023
-
[22]
Mip- splatting: Alias-free 3d gaussian splatting
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip- splatting: Alias-free 3d gaussian splatting. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 19447–19456, 2024
2024
-
[23]
Neuralangelo: High-fidelity neural surface reconstruction
Zhaoshuo Li, Thomas Müller, Alex Evans, Russell H Taylor, Mathias Unberath, Ming-Yu Liu, and Chen-Hsuan Lin. Neuralangelo: High-fidelity neural surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8456–8465, 2023
2023
-
[24]
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wen- ping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi- view reconstruction.arXiv preprint arXiv:2106.10689, 2021
Pith/arXiv arXiv 2021
-
[25]
Volumerenderingofneural implicit surfaces.Advances in neural information processing systems, 34:4805– 4815, 2021
LiorYariv,JiataoGu,YoniKasten,andYaronLipman. Volumerenderingofneural implicit surfaces.Advances in neural information processing systems, 34:4805– 4815, 2021. 18 J. Sun et al
2021
-
[26]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Re- vaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[27]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[28]
Panoptic 3d scene reconstruction from a single rgb image.Advances in Neural Information Processing Systems, 34:8282–8293, 2021
Manuel Dahnert, Ji Hou, Matthias Nießner, and Angela Dai. Panoptic 3d scene reconstruction from a single rgb image.Advances in Neural Information Processing Systems, 34:8282–8293, 2021
2021
-
[29]
Frodo: From detectionsto3dobjects
Martin Runz, Kejie Li, Meng Tang, Lingni Ma, Chen Kong, Tanner Schmidt, Ian Reid, Lourdes Agapito, Julian Straub, Steven Lovegrove, et al. Frodo: From detectionsto3dobjects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14720–14729, 2020
2020
-
[30]
Revealnet: Seeing behind objects in rgb-d scans
Ji Hou, Angela Dai, and Matthias Nießner. Revealnet: Seeing behind objects in rgb-d scans. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2098–2107, 2020
2098
-
[31]
Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
Pith/arXiv arXiv 2017
-
[32]
Habitat 3.0: A co-habitat for humans, avatars and robots
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexander William Clegg, Michal Hlavac, So Yeon Min, et al. Habitat 3.0: A co-habitat for humans, avatars and robots. arXiv preprint arXiv:2310.13724, 2023
arXiv 2023
-
[33]
Behavior-1k: A benchmark for embodied ai with 1,000 everyday ac- tivities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday ac- tivities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023
2023
-
[34]
Procthor:Large-scaleembodiedaiusingproceduralgeneration.Advances in Neural Information Processing Systems, 35:5982–5994, 2022
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor:Large-scaleembodiedaiusingproceduralgeneration.Advances in Neural Information Processing Systems, 35:5982–5994, 2022
2022
-
[35]
Holodeck: Language guided generation of 3d embodied ai environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Language guided generation of 3d embodied ai environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16227–16237, 2024
2024
-
[36]
Phone2proc: Bringing robust robots into our chaotic world
Matt Deitke, Rose Hendrix, Ali Farhadi, Kiana Ehsani, and Aniruddha Kembhavi. Phone2proc: Bringing robust robots into our chaotic world. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9665– 9675, 2023
2023
-
[37]
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning.arXiv preprint arXiv:2410.07408, 2024
arXiv 2024
-
[38]
Holoscene: Simulation- ready interactive 3d worlds from a single video.Advances in Neural Information Processing Systems, 38:32501–32524, 2026
Hongchi Xia, Chih-Hao Lin, Hao-Yu Hsu, Quentin Leboutet, Katelyn Gao, Michael Paulitsch, Benjamin Ummenhofer, and Shenlong Wang. Holoscene: Simulation- ready interactive 3d worlds from a single video.Advances in Neural Information Processing Systems, 38:32501–32524, 2026
2026
-
[39]
Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view
Andreea Ardelean, Mert Özer, and Bernhard Egger. Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view. In2025 Interna- tional Conference on 3D Vision (3DV), pages 616–626. IEEE, 2025. GARDEN19
2025
-
[40]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi- Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23646–23657, 2025
2025
-
[41]
Cast: Component-aligned 3d scene reconstruc- tion from an rgb image.ACM Transactions on Graphics (TOG), 44(4):1–19, 2025
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Lan Xu, Wei Yang, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruc- tion from an rgb image.ACM Transactions on Graphics (TOG), 44(4):1–19, 2025
2025
-
[42]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[43]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drewHuang,JieLei,TengyuMa,BaishanGuo,ArpitKalla,MarkusMarks,Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane Momeni, Ri...
2025
-
[44]
Weipeng Zhong, Peizhou Cao, Yichen Jin, Li Luo, Wenzhe Cai, Jingli Lin, Hanqing Wang, Zhaoyang Lyu, Tai Wang, Bo Dai, et al. Internscenes: A large-scale simulat- able indoor scene dataset with realistic layouts.arXiv preprint arXiv:2509.10813, 2025
Pith/arXiv arXiv 2025
-
[45]
Hypersim: A pho- torealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A pho- torealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision,pages10912–10922, 2021
2021
-
[46]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020
2020
-
[47]
Keunhong Park, Konstantinos Rematas, Ali Farhadi, and Steven M Seitz. Pho- toshape: Photorealistic materials for large-scale shape collections.arXiv preprint arXiv:1809.09761, 2018
Pith/arXiv arXiv 2018
-
[48]
Make-it-real: Unleashing large multimodal model for painting 3d objects with realistic materials.Advances in Neural Information Processing Systems, 37:99262– 99298, 2024
Ye Fang, Zeyi Sun, Tong Wu, Jiaqi Wang, Ziwei Liu, Gordon Wetzstein, and Dahua Lin. Make-it-real: Unleashing large multimodal model for painting 3d objects with realistic materials.Advances in Neural Information Processing Systems, 37:99262– 99298, 2024
2024
-
[49]
Geocalib: Learning single-image calibration with geometric optimization
Alexander Veicht, Paul-Edouard Sarlin, Philipp Lindenberger, and Marc Pollefeys. Geocalib: Learning single-image calibration with geometric optimization. InEuro- pean Conference on Computer Vision, pages 1–20. Springer, 2024
2024
-
[50]
Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020
Pith/arXiv arXiv 2001
-
[51]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022
2022
-
[52]
A multi-view stereo benchmark 20 J
ThomasSchops,JohannesLSchonberger,SilvanoGalliani,TorstenSattler,Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark 20 J. Sun et al. with high-resolution images and multi-camera videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017
2017
-
[53]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[54]
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learn- ing from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017
Pith/arXiv arXiv 2017
-
[55]
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897, 2021
Pith/arXiv arXiv 2021
-
[56]
Rio: 3d object instance re-localization in changing indoor environments
Johanna Wald, Armen Avetisyan, Nassir Navab, Federico Tombari, and Matthias Nießner. Rio: 3d object instance re-localization in changing indoor environments. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7658–7667, 2019
2019
-
[57]
# "Context Transformer Decoder Rotation Head !
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on pattern analysis and machine intelli- gence, 13(4):376–380, 2002. GARDEN21 Supplementary Material Overview This supplementary material provides additional technical details and experi- mental results for GARDEN. Section A describes the arc...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.