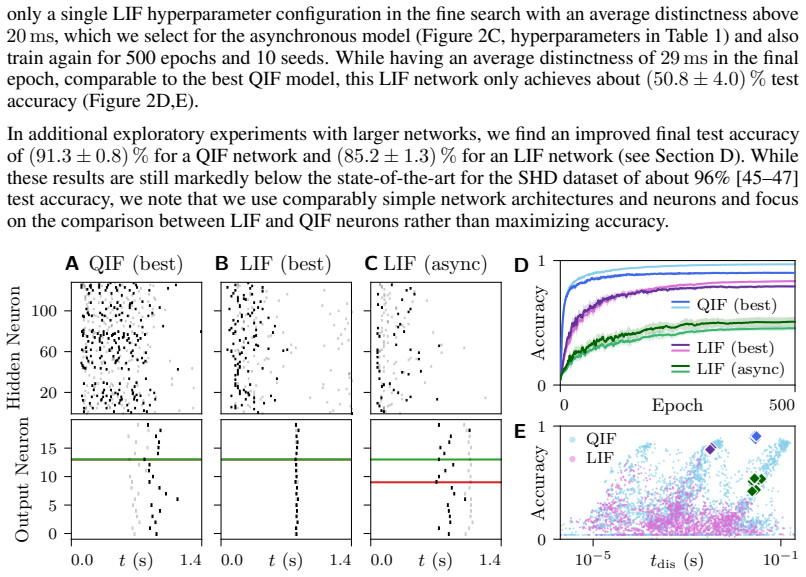
Quadratic integrate-and-fire neurons exhibit less fragmented loss landscapes and outperform leaky integrate-and-fire neurons in spike-based gradient descent
Pith reviewed 2026-06-28 07:19 UTC · model grok-4.3
The pith
QIF neurons produce less fragmented loss landscapes and outperform LIF neurons in spike-based gradient descent on the Spiking Heidelberg Digits dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
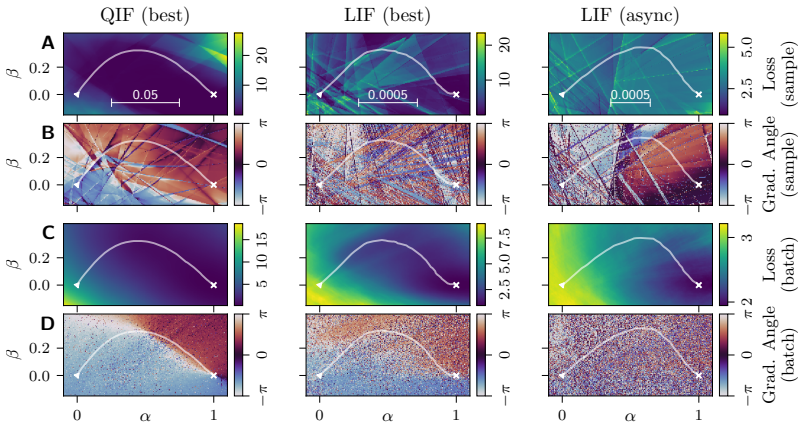
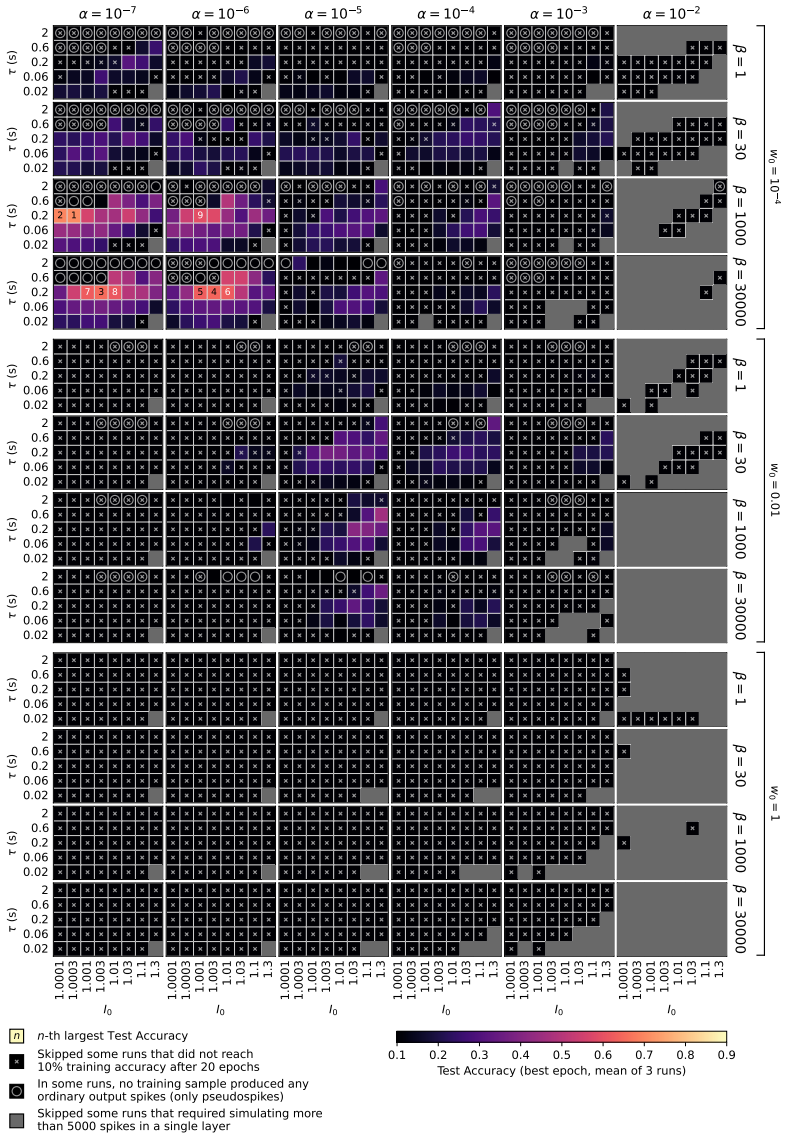
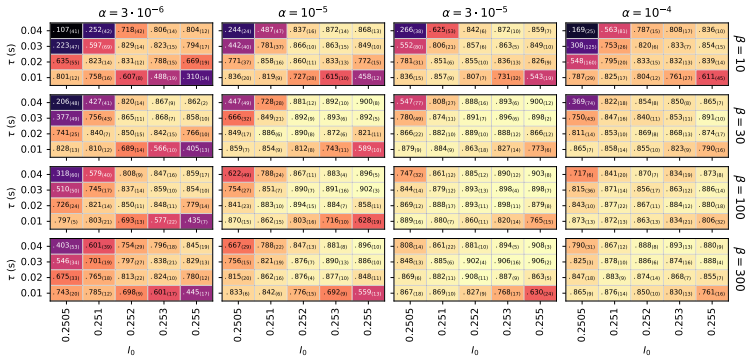
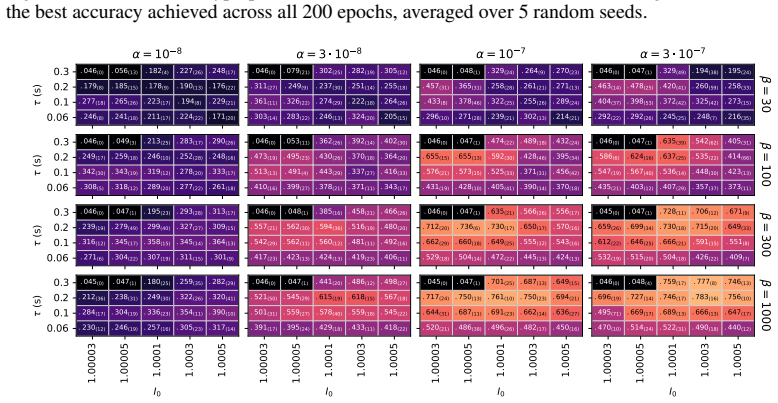
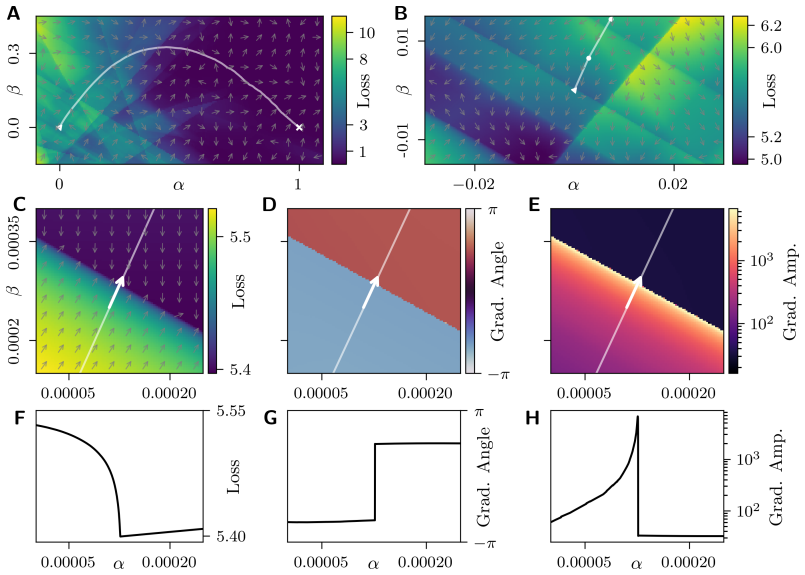
QIF neurons exhibit less fragmented loss landscapes and outperform LIF neurons in spike-based gradient descent because their continuous spiking dynamics avoid the discontinuities that cause spike (dis)appearances and unstable representations in LIF neurons, as demonstrated by superior accuracy and smoother visualized landscapes on the Spiking Heidelberg Digits dataset after hyperparameter optimization.
What carries the argument
The continuity of spiking dynamics in the QIF neuron model, which eliminates parameter-induced discontinuities in spike timing that fragment loss landscapes in the LIF model.
If this is right
- QIF networks achieve higher classification accuracy than LIF networks on the Spiking Heidelberg Digits dataset.
- Loss landscapes for LIF appear more fragmented due to changes in the temporal order of spikes.
- Gradients in QIF training are less erratic than in LIF training.
- Replacing LIF with QIF or similar continuous models is advocated for stable gradient descent training of spiking networks.
Where Pith is reading between the lines
- Continuous dynamics might benefit other spike-based learning methods beyond exact gradient descent.
- QIF models could lead to more reliable training on neuromorphic hardware where on-chip learning is desired.
- Similar advantages may appear on other datasets or with different network architectures.
Load-bearing premise
The hyperparameter search was equally exhaustive and unbiased for both neuron models, with any performance gap due to spiking continuity rather than optimization differences.
What would settle it
Finding that an equally exhaustive hyperparameter search allows LIF networks to match or exceed QIF accuracy on the same dataset would falsify the performance advantage.
Figures








read the original abstract
The ability to train spiking neural networks is essential for modeling biological neural networks as well as for neuromorphic computing. However, for the extensively used leaky integrate-and-fire (LIF) neurons, arbitrarily small parameter changes can induce spike (dis)appearances that disrupt subsequent activity, leading to unstable neural representations and permanently silent neurons during exact spike-based gradient descent. Recent work shows that a class of neuron models, which includes the quadratic integrate-and-fire (QIF) neuron, avoids these discontinuities and enables continuous and even smooth spike-based gradient descent. However, it remains unclear whether these advantages translate into practice. Here, we demonstrate that they do so via a controlled comparison between networks of LIF and QIF neurons on the popular Spiking Heidelberg Digits dataset. Specifically, in a first step, we perform a thorough hyperparameter search to optimize both models, revealing a clear performance advantage of QIF neurons. In a second step, we visualize the loss and gradient landscapes. Consistent with their inferior performance, we find that the loss landscapes of LIF neurons, which are discontinuous, appear more fragmented and the related gradients more erratic. An analysis of the landscapes of single samples indicates that these features arise from changes in the temporal order of spikes, which often cause disruptive spike (dis)appearances. Overall, our results advocate replacing LIF neurons with neuron models exhibiting continuous spiking dynamics, such as QIF neurons, for gradient descent training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that quadratic integrate-and-fire (QIF) neurons produce less fragmented loss landscapes and outperform leaky integrate-and-fire (LIF) neurons when training spiking networks via exact spike-based gradient descent on the Spiking Heidelberg Digits dataset, attributing the advantage to the continuity of QIF spiking dynamics that avoids disruptive spike (dis)appearances.
Significance. If the attribution holds, the result would provide empirical support for preferring neuron models with continuous spiking dynamics over standard LIF models in gradient-based training of spiking networks, with potential benefits for stability in neuromorphic hardware and biological modeling. The controlled comparison on a public benchmark together with loss-landscape visualizations constitutes a direct test of the theoretical continuity advantage.
major comments (1)
- [Abstract] Abstract (and the corresponding methods description): the central performance claim rests on a 'thorough hyperparameter search' having been performed equally for both models, yet no quantitative information is supplied on search ranges, number of trials, adaptation of ranges between models, or statistical comparison of the resulting optima. Without these details the reported accuracy gap cannot be confidently attributed to spiking continuity rather than differences in optimization effort or implementation.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our hyperparameter search procedure. We agree that this information is essential for attributing performance differences to the neuron model rather than optimization effort, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the corresponding methods description): the central performance claim rests on a 'thorough hyperparameter search' having been performed equally for both models, yet no quantitative information is supplied on search ranges, number of trials, adaptation of ranges between models, or statistical comparison of the resulting optima. Without these details the reported accuracy gap cannot be confidently attributed to spiking continuity rather than differences in optimization effort or implementation.
Authors: We acknowledge that the current manuscript lacks sufficient quantitative details on the hyperparameter optimization. In the revised version, we will expand the methods section (and update the abstract if space permits) to specify the search ranges used for each model, the total number of trials or evaluations performed, whether ranges were adapted differently between LIF and QIF, and any statistical comparisons (e.g., mean and variance of top-performing configurations). This will enable readers to evaluate the fairness of the comparison. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmark.
full rationale
The paper's central claims rest on a controlled empirical comparison: hyperparameter search followed by training and loss-landscape visualization on the public Spiking Heidelberg Digits dataset. No equations, fitted parameters, or predictions are shown to reduce by construction to inputs inside the paper. The continuity property of QIF is attributed to prior work (not self-cited as load-bearing uniqueness theorem here), while the performance and landscape differences are measured directly. This is a standard experimental design against external benchmarks; no self-definitional, fitted-input, or self-citation-chain reductions occur.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kistler, Richard Naud, and Liam Paninski.Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition
Wulfram Gerstner, Werner M. Kistler, Richard Naud, and Liam Paninski.Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition. Cambridge University Press, 2014. ISBN 978-1- 107-06083-8
2014
-
[2]
Peter Dayan and L. F. Abbott.Theoretical Neuroscience. MIT Press, Cambridge, 2001. ISBN 0-262- 04199-5
2001
-
[3]
Rapid Neural Coding in the Retina with Relative Spike Latencies
Tim Gollisch and Markus Meister. Rapid Neural Coding in the Retina with Relative Spike Latencies. Science, 319(5866):1108–1111, 2008. doi: 10.1126/science.1149639
-
[4]
Sparse and powerful cortical spikes.Current Opinion in Neurobiology, 20(3):306–312, 2010
Jason Wolfe, Arthur R Houweling, and Michael Brecht. Sparse and powerful cortical spikes.Current Opinion in Neurobiology, 20(3):306–312, 2010. doi: 10.1016/j.conb.2010.03.006
-
[5]
Hannes P Saal, Xiaoqin Wang, and Sliman J Bensmaia. Importance of spike timing in touch: an analogy with hearing?Current Opinion in Neurobiology, 40:142–149, 2016. doi: 10.1016/j.conb.2016.07.013
-
[6]
Sober, Simon Sponberg, Ilya Nemenman, and Lena H
Samuel J. Sober, Simon Sponberg, Ilya Nemenman, and Lena H. Ting. Millisecond Spike Timing Codes for Motor Control.Trends in Neurosciences, 41(10):644–648, 2018. doi: 10.1016/j.tins.2018.08.010
-
[7]
Weizhen Xie, John H. Wittig, Julio I. Chapeton, Mostafa El-Kalliny, Samantha N. Jackson, Sara K. Inati, and Kareem A. Zaghloul. Neuronal sequences in population bursts encode information in human cortex. Nature, 635(8040):935–942, 2024. doi: 10.1038/s41586-024-08075-8
-
[8]
Mehonic and A
A. Mehonic and A. J. Kenyon. Brain-inspired computing needs a master plan.Nature, 604(7905):255–260,
-
[9]
doi: 10.1038/s41586-021-04362-w
-
[10]
Vineyard, Tej Pandit, Cory Merkel, Rajkumar Kubendran, James B
Dhireesha Kudithipudi, Catherine Schuman, Craig M. Vineyard, Tej Pandit, Cory Merkel, Rajkumar Kubendran, James B. Aimone, Garrick Orchard, Christian Mayr, Ryad Benosman, Joe Hays, Cliff Young, Chiara Bartolozzi, Amitava Majumdar, Suma George Cardwell, Melika Payvand, Sonia Buckley, Shruti Kulkarni, Hector A. Gonzalez, Gert Cauwenberghs, Chetan Singh Thak...
2025
-
[11]
MIT Press, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016
2016
-
[12]
Bishop and Hugh Bishop.Deep Learning - Foundations and Concepts
Christopher M. Bishop and Hugh Bishop.Deep Learning - Foundations and Concepts. Springer, 2024. ISBN 978-3-031-45467-7
2024
-
[13]
Visualizing the Loss Landscape of Neural Nets
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the Loss Landscape of Neural Nets. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[14]
How Does Batch Normalization Help Optimization? InAdvances in Neural Information Processing Systems, volume 31, pages 2488–2498
Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. How Does Batch Normalization Help Optimization? InAdvances in Neural Information Processing Systems, volume 31, pages 2488–2498. Curran Associates, Inc., 2018
2018
-
[15]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InProceedings of the 30th International Conference on Machine Learning, volume 28, pages 1310–1318. PMLR, 2013
2013
-
[16]
Christian Klos and Raoul-Martin Memmesheimer. Smooth Exact Gradient Descent Learning in Spiking Neural Networks.Physical Review Letters, 134(2):027301, 2025. doi: 10.1103/PhysRevLett.134.027301
-
[17]
Sander M. Bohte, Joost N. Kok, and Han La Poutré. Error-backpropagation in temporally encoded networks of spiking neurons.Neurocomputing, 48(1):17–37, 2002. doi: 10.1016/S0925-2312(01)00658-0. 10
-
[18]
Jason K. Eshraghian, Max Ward, Emre O. Neftci, Xinxin Wang, Gregor Lenz, Girish Dwivedi, Mohammed Bennamoun, Doo Seok Jeong, and Wei D. Lu. Training Spiking Neural Networks Using Lessons From Deep Learning.Proceedings of the IEEE, 111(9):1016–1054, 2023. doi: 10.1109/JPROC.2023.3308088
-
[19]
2020, in ICASSP 2020, 1434–1438, doi: 10.1109/ICASSP40776.2020.9053284
Iulia M. Comsa, Krzysztof Potempa, Luca Versari, Thomas Fischbacher, Andrea Gesmundo, and Jyrki Alakuijala. Temporal Coding in Spiking Neural Networks with Alpha Synaptic Function: Learning with Backpropagation. InICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 8529–8533. IEEE, 2020. doi: 10.1109/ICASSP40...
-
[20]
J. Göltz, L. Kriener, A. Baumbach, S. Billaudelle, O. Breitwieser, B. Cramer, D. Dold, A. F. Kungl, W. Senn, J. Schemmel, K. Meier, and M. A. Petrovici. Fast and energy-efficient neuromorphic deep learning with first-spike times.Nature Machine Intelligence, 3(9):823–835, 2021. doi: 10.1038/s42256-021-00388-x
-
[21]
Hesham Mostafa. Supervised Learning Based on Temporal Coding in Spiking Neural Networks.IEEE Transactions on Neural Networks and Learning Systems, pages 1–9, 2017. doi: 10.1109/TNNLS.2017. 2726060
-
[22]
Loss shaping enhances exact gradient learning with Eventprop in spiking neural networks.Neuromorphic Computing and Engineering, 5(1):014001,
Thomas Nowotny, James P Turner, and James C Knight. Loss shaping enhances exact gradient learning with Eventprop in spiking neural networks.Neuromorphic Computing and Engineering, 5(1):014001,
-
[23]
doi: 10.1088/2634-4386/ada852
-
[24]
Saeed Reza Kheradpisheh and Timothée Masquelier. S4NN: temporal backpropagation for spiking neural networks with one spike per neuron.International Journal of Neural Systems, 30(06):2050027, 2020. doi: 10.1142/S0129065720500276
-
[25]
Wunderlich and Christian Pehle
Timo C. Wunderlich and Christian Pehle. Event-based backpropagation can compute exact gradients for spiking neural networks.Scientific Reports, 11(1):12829, 2021. doi: 10.1038/s41598-021-91786-z
-
[26]
jaxsnn: Event-driven Gradient Estimation for Analog Neuromorphic Hardware, 2024
Eric Müller, Moritz Althaus, Elias Arnold, Philipp Spilger, Christian Pehle, and Johannes Schemmel. jaxsnn: Event-driven Gradient Estimation for Analog Neuromorphic Hardware, 2024
2024
-
[27]
Training event-based neural networks with exact gradients via Differentiable ODE Solving in JAX, 2026
Lukas König, Manuel Kuhn, David Kappel, and Anand Subramoney. Training event-based neural networks with exact gradients via Differentiable ODE Solving in JAX, 2026
2026
-
[28]
SparseProp: Efficient Event-Based Simulation and Training of Sparse Recurrent Spiking Neural Networks
Rainer Engelken. SparseProp: Efficient Event-Based Simulation and Training of Sparse Recurrent Spiking Neural Networks. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[29]
From LIF to QIF: Toward Differentiable Spiking Neurons for Scientific Machine Learning, 2025
Ruyin Wan, George Em Karniadakis, and Panos Stinis. From LIF to QIF: Toward Differentiable Spiking Neurons for Scientific Machine Learning, 2025
2025
-
[30]
Neftci, Hesham Mostafa, and Friedemann Zenke
Emre O. Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-Based Optimization to Spiking Neural Networks.IEEE Signal Processing Magazine, 36(6):51–63, 2019. doi: 10.1109/MSP.2019.2931595
-
[31]
Julia Gygax and Friedemann Zenke. Elucidating the theoretical underpinnings of surrogate gradient learning in spiking neural networks.Neural Computation, 37(5):886–925, 2025. doi: 10.1162/neco_a_01752
-
[32]
David Balduzzi, Marcus Frean, Lennox Leary, J. P. Lewis, Kurt Wan-Duo Ma, and Brian McWilliams. The shattered gradients problem: if resnets are the answer, then what is the question? InProceedings of the 34th International Conference on Machine Learning, volume 70, pages 342–350. PMLR, 2017
2017
-
[33]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. InInternational Conference on Learning Representations, 2017
2017
-
[34]
Flat minima.Neural Computation, 9(1):1–42, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Flat minima.Neural Computation, 9(1):1–42, 1997. doi: 10.1162/neco.1997.9.1.1
-
[35]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-Aware Minimization for Efficiently Improving Generalization. InInternational Conference on Learning Representations, 2021
2021
-
[36]
Loss surfaces, mode connectivity, and fast ensembling of DNNs
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, and Andrew Gordon Wilson. Loss surfaces, mode connectivity, and fast ensembling of DNNs. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[37]
Hamprecht
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred A. Hamprecht. Essentially no barriers in neural network energy landscape. InProceedings of the 35th International Conference on Machine Learning, volume 80, pages 1309–1318. PMLR, 2018. 11
2018
-
[38]
Stable irregular dynamics in complex neural networks.Physical Review Letters, 100(4):048102, 2008
Sven Jahnke, Raoul-Martin Memmesheimer, and Marc Timme. Stable irregular dynamics in complex neural networks.Physical Review Letters, 100(4):048102, 2008. doi: 10.1103/PhysRevLett.100.048102
-
[39]
Dynamic Flux Tubes Form Reservoirs of Stability in Neuronal Circuits
Michael Monteforte and Fred Wolf. Dynamic Flux Tubes Form Reservoirs of Stability in Neuronal Circuits. Physical Review X, 2(4):041007, 2012. doi: 10.1103/PhysRevX.2.041007
-
[40]
Sparse chaos in cortical circuits, 2024
Rainer Engelken, Michael Monteforte, and Fred Wolf. Sparse chaos in cortical circuits, 2024
2024
-
[41]
Causal pieces: analysing and improving spiking neural networks piece by piece, 2025
Dominik Dold and Philipp Christian Petersen. Causal pieces: analysing and improving spiking neural networks piece by piece, 2025
2025
-
[42]
Bower, Markus Diesmann, Abigail Morrison, Philip H
Romain Brette, Michelle Rudolph, Ted Carnevale, Michael Hines, David Beeman, James M. Bower, Markus Diesmann, Abigail Morrison, Philip H. Goodman, Frederick C. Harris, Milind Zirpe, Thomas Natschläger, Dejan Pecevski, Bard Ermentrout, Mikael Djurfeldt, Anders Lansner, Olivier Rochel, Thierry Vieville, Eilif Muller, Andrew P. Davison, Sami El Boustani, and...
-
[43]
Benjamin Cramer, Yannik Stradmann, Johannes Schemmel, and Friedemann Zenke. The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks.IEEE Transactions on Neural Networks and Learning Systems, 33(7):2744–2757, 2022. doi: 10.1109/TNNLS.2020.3044364
-
[44]
Johansson and Ingvars Birznieks
Roland S. Johansson and Ingvars Birznieks. First spikes in ensembles of human tactile afferents code complex spatial fingertip events.Nature Neuroscience, 7(2):170–177, 2004. doi: 10.1038/nn1177
-
[45]
Spike-based strategies for rapid processing
Simon Thorpe, Arnaud Delorme, and Rufin Van Rullen. Spike-based strategies for rapid processing. Neural Networks, 14(6):715–725, 2001. doi: 10.1016/S0893-6080(01)00083-1
-
[46]
Kaushik Roy, Akhilesh Jaiswal, and Priyadarshini Panda. Towards spike-based machine intelligence with neuromorphic computing.Nature, 575(7784):607–617, 2019. doi: 10.1038/s41586-019-1677-2
-
[47]
Towards parameter-free attentional spiking neural networks.Neural Networks, 185:107154, 2025
Pengfei Sun, Jibin Wu, Paul Devos, and Dick Botteldooren. Towards parameter-free attentional spiking neural networks.Neural Networks, 185:107154, 2025. doi: 10.1016/j.neunet.2025.107154
-
[48]
Scalable Event-by-event Processing of Neuromorphic Sensory Signals With Deep State-Space Models, 2024
Mark Schöne, Neeraj Mohan Sushma, Jingyue Zhuge, Christian Mayr, Anand Subramoney, and David Kappel. Scalable Event-by-event Processing of Neuromorphic Sensory Signals With Deep State-Space Models, 2024
2024
-
[49]
Advancing Spatio- Temporal Processing in Spiking Neural Networks through Adaptation, 2025
Maximilian Baronig, Romain Ferrand, Silvester Sabathiel, and Robert Legenstein. Advancing Spatio- Temporal Processing in Spiking Neural Networks through Adaptation, 2025
2025
-
[50]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In2015 IEEE International Conference on Computer Vision (ICCV). IEEE, 2015. doi: 10.1109/iccv.2015.123
-
[51]
Alexandre Bittar and Philip N. Garner. A surrogate gradient spiking baseline for speech command recognition.Frontiers in Neuroscience, 16:865897, 2022. doi: 10.3389/fnins.2022.865897
-
[52]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018
2018
-
[53]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
2020
-
[54]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[55]
Data Structures for Statistical Computing in Python
Wes McKinney. Data Structures for Statistical Computing in Python. InProceedings of the 9th Python in Science Conference, volume 445, pages 51–56, 2010. doi: 10.25080/Majora-92bf1922-00a
-
[56]
pandas-dev/pandas: Pandas, 2020
The pandas development team. pandas-dev/pandas: Pandas, 2020
2020
-
[57]
J. D. Hunter. Matplotlib: A 2D Graphics Environment.Computing in Science & Engineering, 9(3):90–95,
-
[58]
2007 Matplotlib: A 2D Graphics Environment
doi: 10.1109/MCSE.2007.55. 12 A Model details The model description was intentionally kept short in the main text to keep the focus on the main results. For completeness, we give more details about the models used in this work in this section. This is intended to be an extension of Section 2.1. A.1 Phase representation To simplify and unify the dynamics o...
-
[59]
The resulting threshold phases are ϕLIF Θ =−τlog 1− VΘ I0 , ϕ QIF Θ = πτ a .(6) The inverse phase transformations are (ΦLIF)−1(ϕ) =I 0 1−e −ϕ/τ ,(Φ QIF)−1(ϕ) = 1 2 +atan aϕ τ − π 2 .(7) For infinitesimally short input currents, the membrane potential of neuron i jumps by wij when receiving an input spike from neuron j. The effect of this potential jump on...
-
[60]
This could either be an input spike or a spike in the layer that is simulated, depending on which appears earlier
Determine the neuron index jk+1 and spike time tk+1 of the next spike. This could either be an input spike or a spike in the layer that is simulated, depending on which appears earlier. Because the phase grows linearly with time between spikes, the neuron that spikes next is always the one with the largest phase,j k+1 =argmax iϕik
-
[61]
This is trivial due to the linear dynamics between spikes
Evolve neurons freely until shortly before the next spike at t− k+1. This is trivial due to the linear dynamics between spikes. We have ˙ϕi = 1 and, thus, ϕi(t− k+1) =ϕ ik + (tk+1 −t k)
-
[62]
Otherwise, if the spike occurs in the simulated layer itself, reset the phase of the spiking neuron, ϕj+1,k+1 = 0, and set ϕi,k+1 =ϕ i(t− k+1)for all other neurons
If the next spike is an input spike, transfer it to the neurons in the simulated layer, using the phase transfer function ϕi,k+1 =H wijk+1 (ϕi(t− k+1)). Otherwise, if the spike occurs in the simulated layer itself, reset the phase of the spiking neuron, ϕj+1,k+1 = 0, and set ϕi,k+1 =ϕ i(t− k+1)for all other neurons. This process has to be repeated until t...
-
[63]
for principle component analysis, pandas [53, 54] for data management, and Matplotlib [55] for visualizations. 27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.