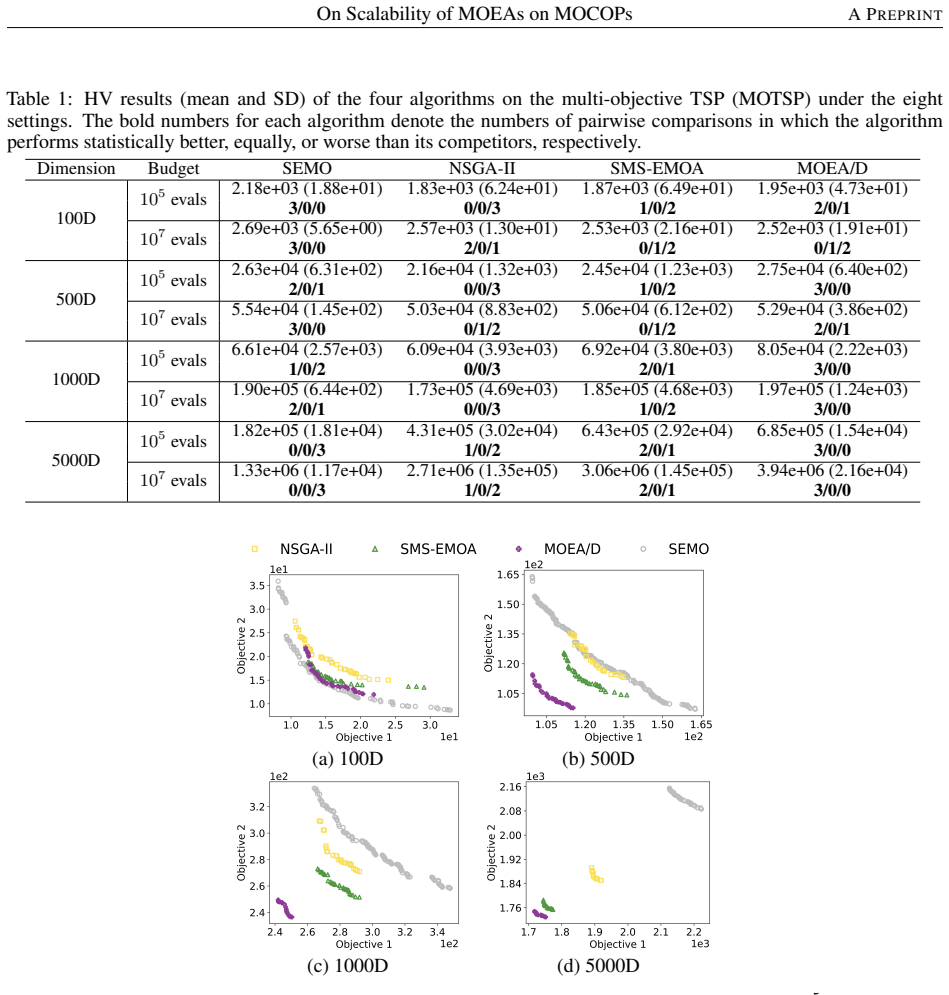
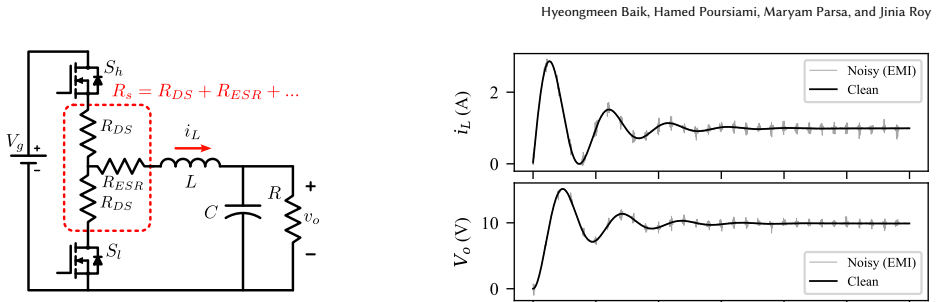
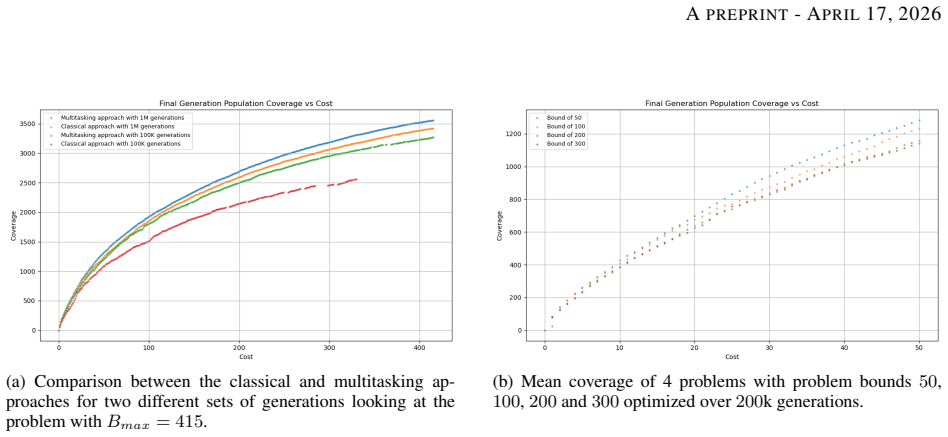
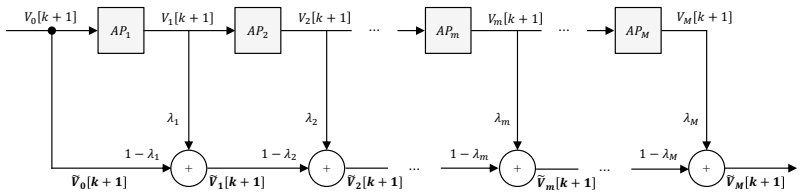
0
Spiking neurons split frequency choice from timing adjustment
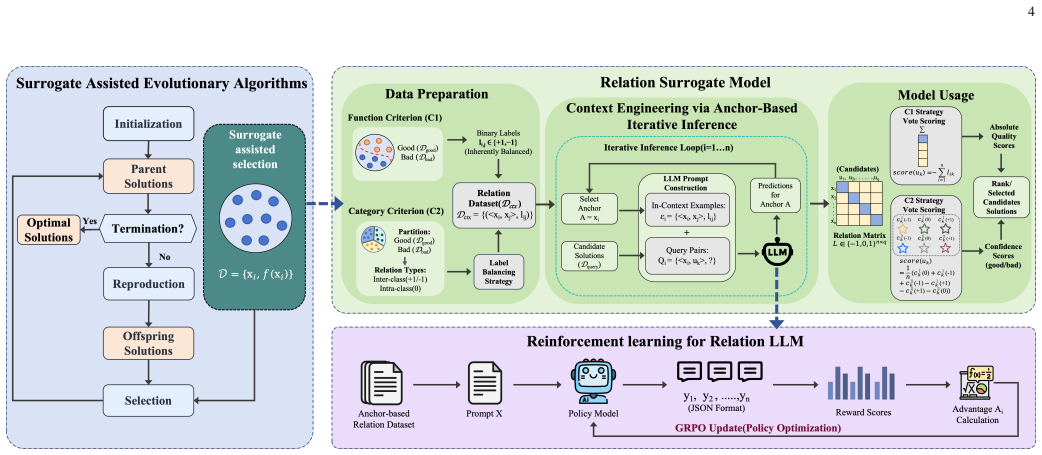
FiTS: Interpretable Spiking Neurons via Frequency Selectivity and Temporal Shaping
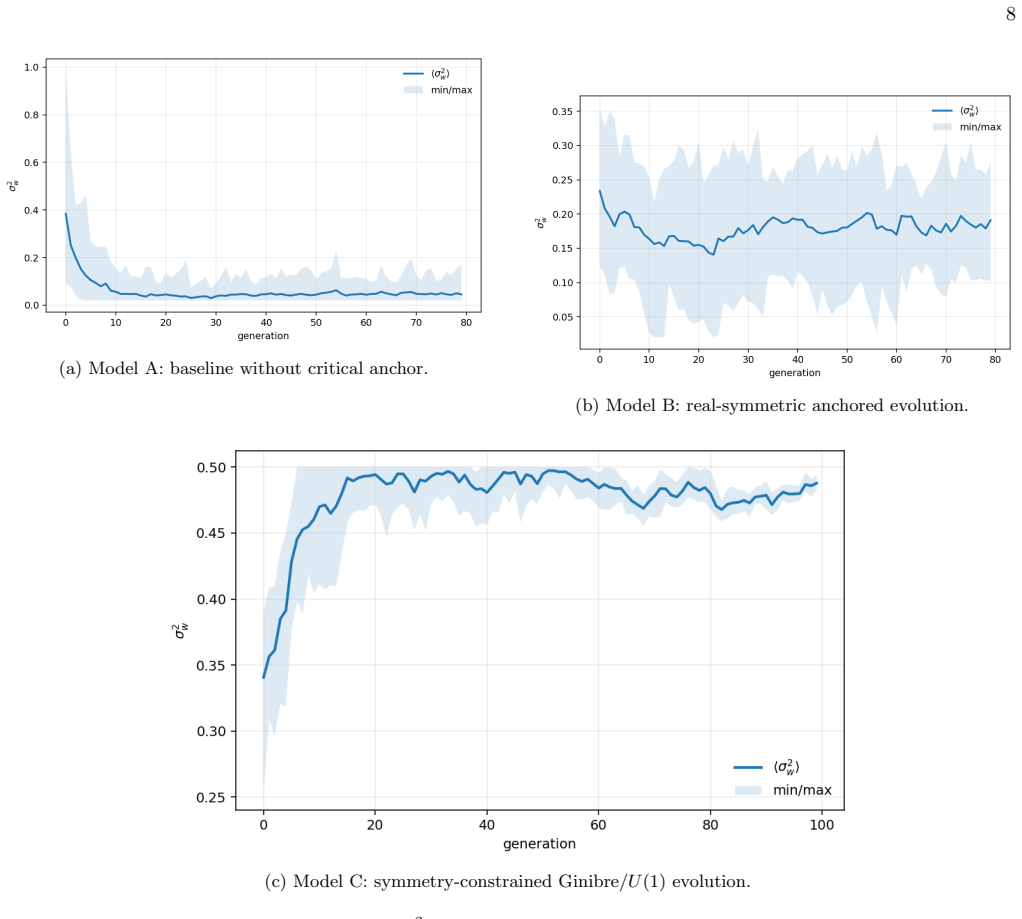
Each FiTS cell sets its own target frequency and uses group-delay shifts to control when components accumulate, raising accuracy in plain S1
 full image
full image
abstract click to expand
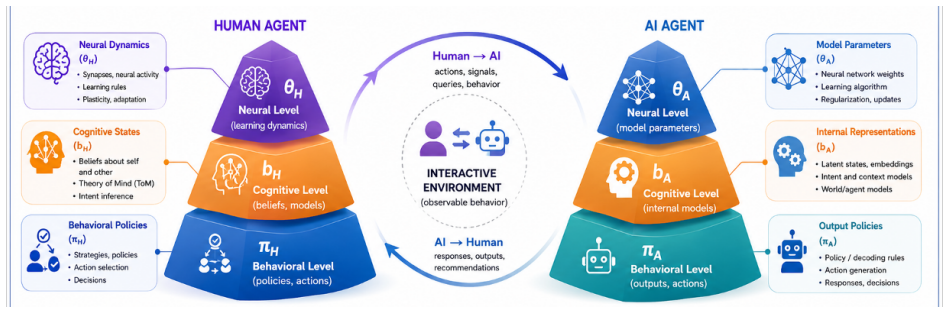
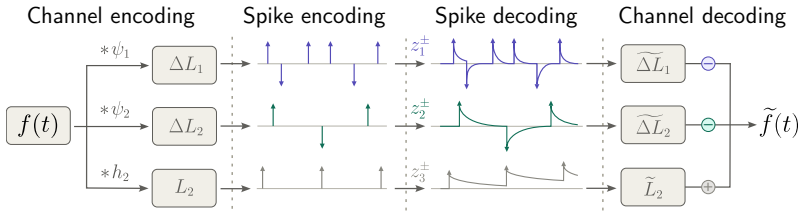
Spiking Neural Networks (SNNs) are a promising framework for event-driven temporal processing. Prior work has improved temporal modeling through richer neuron dynamics and network-level mechanisms such as recurrence and delays, but it remains unclear how individual spiking neurons should specialize within a network. In this work, we introduce FiTS, a spiking neuron that factorizes temporal computation within each neuron into Frequency Selectivity (FS) and Temporal Shaping (TS). The FS module parameterizes each neuron's target frequency as the maximizer of its subthreshold magnitude response, while the TS module reshapes when frequency components contribute to membrane voltage accumulation through group-delay modulation. On auditory benchmarks where frequency selectivity and timing are central to the input structure, FiTS consistently improves over a plain Leaky Integrate-and-Fire (LIF) baseline in simple feedforward SNNs without recurrence or network-level delays, while remaining competitive with strong temporal SNN baselines. Beyond accuracy, the learned target frequencies and group-delay shifts provide interpretable neuron-level summaries of the frequency and timing organization learned within the network.