Preference-Calibrated Human-in-the-Loop Reinforcement Learning for Robotic Manipulation
Pith reviewed 2026-06-28 10:04 UTC · model grok-4.3
The pith
PACT recalibrates credit assignment in human-in-the-loop RL using preference signals from human interventions to improve robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
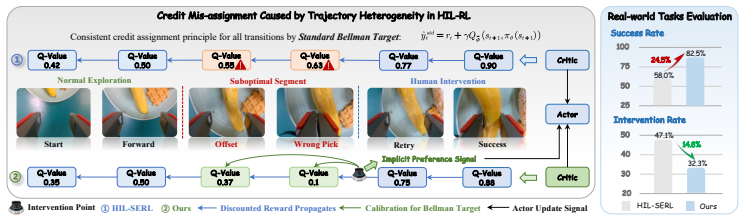
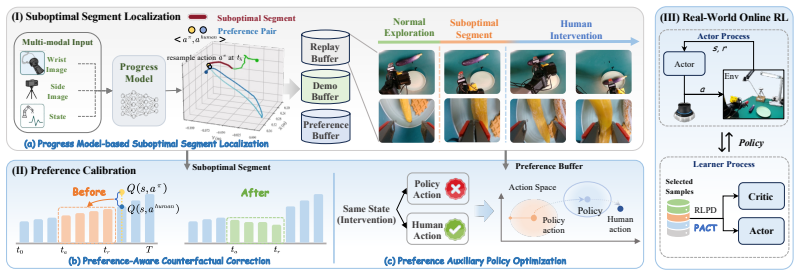
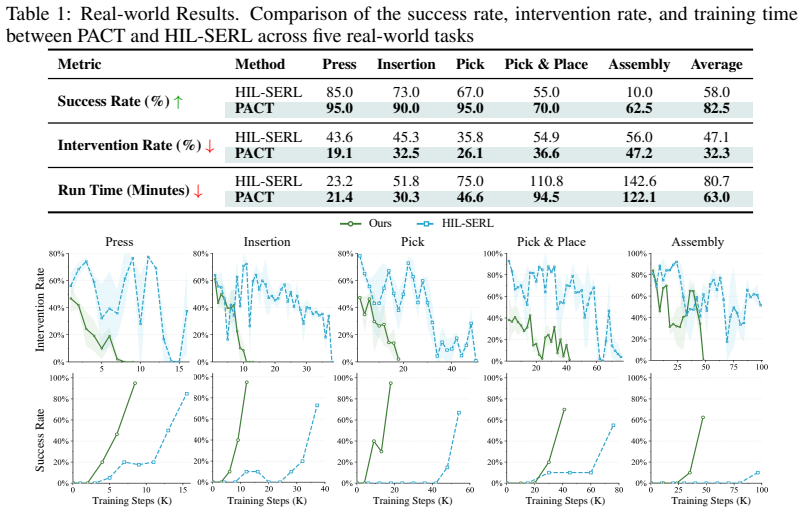
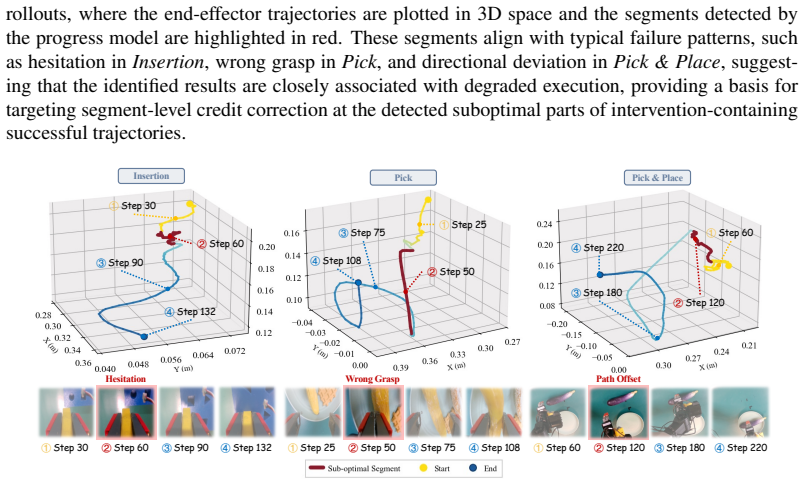
PACT improves the average success rate by 24.5% and achieves 1.3 times faster convergence across five real-robot manipulation tasks by leveraging implicit preference signals induced by human intervention to perform credit reassignment on identified suboptimal segments. The framework first learns a progress model from human demonstrations to identify suboptimal segments. It then constructs a counterfactual advantage from the human action and a resampled policy action at the intervention state to penalize the Bellman targets of those segments. The policy is also directly aligned with human corrective actions in the bounded mean space.
What carries the argument
The counterfactual advantage built from human action versus resampled policy action at intervention states, used to penalize Bellman targets of suboptimal segments identified by a progress model
Load-bearing premise
The progress model learned from human demonstrations can reliably identify suboptimal segments, and the counterfactual advantage constructed from human versus resampled policy actions at intervention states correctly penalizes the Bellman targets of those segments without introducing bias into critic or actor updates.
What would settle it
An experiment that disables the credit reassignment on suboptimal segments while keeping all other components and measures whether the success rate gain disappears would test the claim.
Figures
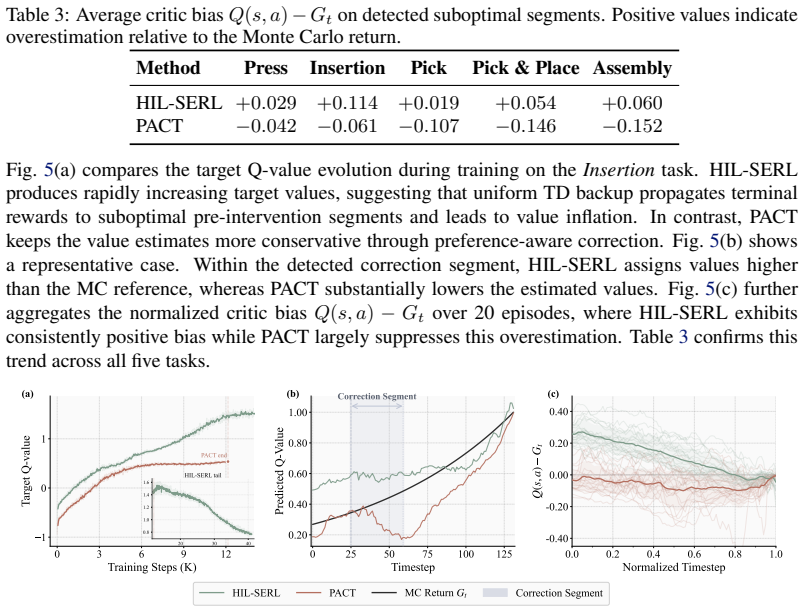
read the original abstract
Human-in-the-loop reinforcement learning (HIL-RL) improves sample efficiency in real-robot manipulation through online human intervention. However, successful trajectories may include suboptimal actions that deviate from the desired task-execution path and force human intervention. Existing HIL-RL methods typically apply the consistent credit assignment principle to all transitions, uniformly propagating discounted terminal rewards through suboptimal segments, ignoring the actual contribution of each transition to task success. This overestimates Q-values for critic learning and indirectly misguides actor updates toward suboptimal behavior patterns. To this end, we propose PACT, a Preference-calibrated Actor-Critic Training framework that leverages the implicit preference signals induced by intervention to perform credit reassignment on identified suboptimal segments while directly guiding policy training for unbiased critic-actor learning. Specifically, we first design a progress model that learns from human demonstration and identifies suboptimal segments for credit correction. Then, from the human action and resampled policy action at the intervention state, we build preference pairs to define a counterfactual advantage that penalizes Bellman targets of the identified suboptimal segment, enabling directional credit calibration. Moreover, we directly align the policy with human corrective actions in the bounded mean space, providing an additional signal beyond critic-guided updates. Across five real-robot manipulation tasks, PACT improves the average success rate by 24.5% and achieves 1.3 times faster convergence, thereby improving both RL sample efficiency and performance. Code is available at https://anonymous.4open.science/r/HILRL-A1X-BC05.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PACT, a Preference-calibrated Actor-Critic Training framework for human-in-the-loop RL in robotic manipulation. It trains a progress model on human demonstrations to identify suboptimal segments in successful trajectories, constructs preference pairs from human corrective actions versus resampled policy actions at intervention states to define a counterfactual advantage that penalizes Bellman targets for those segments, and additionally aligns the policy directly with human actions in bounded mean space. The central empirical claim is a 24.5% average success-rate improvement and 1.3 imes faster convergence across five real-robot manipulation tasks relative to prior HIL-RL methods.
Significance. If the experimental results prove robust, the approach would offer a concrete mechanism for directional credit reassignment in HIL-RL that exploits implicit preference signals from human interventions rather than uniform reward propagation. This could improve both sample efficiency and final policy quality in real-robot settings where trajectories contain mixed optimal and suboptimal actions. The release of code is a clear positive for reproducibility.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the central claim of a 24.5% success-rate gain and 1.3 imes faster convergence is stated without any information on the number of independent runs, variance across seeds, statistical tests performed, baseline implementations, or data-exclusion rules. These omissions make it impossible to assess whether the reported numbers support the attribution to preference calibration.
- [Method (progress model)] Method description (progress model): the manuscript states that a progress model is trained on human demonstrations to identify suboptimal segments for credit correction, yet supplies no accuracy metrics, validation procedure, or ablation on mislabeling rates. Because the entire credit-reassignment pipeline rests on correct identification of those segments, the absence of this evidence leaves the directional calibration claim unsecured.
- [Method (counterfactual advantage)] Method description (counterfactual advantage): the construction of the counterfactual advantage from human action versus resampled policy action at intervention states is presented as penalizing Bellman targets without bias, but no analysis or experiment demonstrates that the resampling distribution matches the policy’s behavior at those states or that the resulting targets remain unbiased for critic and actor updates. This directly matches the weakest assumption identified in the stress test.
minor comments (2)
- [Abstract] The anonymous code link is helpful; ensure a permanent repository is provided in the camera-ready version.
- [Method] Notation for the bounded-mean policy alignment step could be clarified with an explicit equation or pseudocode snippet to avoid ambiguity in implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim of a 24.5% success-rate gain and 1.3 times faster convergence is stated without any information on the number of independent runs, variance across seeds, statistical tests performed, baseline implementations, or data-exclusion rules. These omissions make it impossible to assess whether the reported numbers support the attribution to preference calibration.
Authors: We agree that these experimental details are necessary to evaluate the claims. In the revised manuscript we will report the number of independent runs (five random seeds per task), include standard deviations and error bars, specify baseline implementation details and hyperparameter choices, and add results from paired t-tests for statistical significance. Data-exclusion rules (none were applied beyond standard failure cases) will also be stated explicitly. These additions will appear in both the Experiments section and a revised abstract. revision: yes
-
Referee: [Method (progress model)] Method description (progress model): the manuscript states that a progress model is trained on human demonstrations to identify suboptimal segments for credit correction, yet supplies no accuracy metrics, validation procedure, or ablation on mislabeling rates. Because the entire credit-reassignment pipeline rests on correct identification of those segments, the absence of this evidence leaves the directional calibration claim unsecured.
Authors: We acknowledge the omission of direct validation metrics for the progress model. The revised Method section will include a cross-validation accuracy report on held-out human demonstrations and an appendix ablation that varies simulated mislabeling rates to quantify impact on final policy performance. These additions will directly address the reliability of the segment identification step. revision: yes
-
Referee: [Method (counterfactual advantage)] Method description (counterfactual advantage): the construction of the counterfactual advantage from human action versus resampled policy action at intervention states is presented as penalizing Bellman targets without bias, but no analysis or experiment demonstrates that the resampling distribution matches the policy’s behavior at those states or that the resulting targets remain unbiased for critic and actor updates. This directly matches the weakest assumption identified in the stress test.
Authors: The resampling step draws actions from the current policy at the exact intervention states to form the preference pairs. While the original submission did not contain an explicit distribution-matching experiment or bias analysis, the end-to-end empirical gains across five tasks indicate practical stability. In revision we will add a short discussion of the assumption together with a supplementary plot comparing action distributions; any identified limitations will be noted. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external robot evaluations
full rationale
The paper introduces PACT as a method that trains a progress model on human demonstrations to flag suboptimal segments, constructs counterfactual advantages from human vs. resampled policy actions at intervention points, and applies these to adjust Bellman targets plus direct policy alignment. These steps are defined procedurally from external human data and standard RL components; the reported 24.5% success-rate gain and 1.3× convergence improvement are measured on five separate real-robot tasks rather than recovered by construction from the same fitted quantities. No self-citations, uniqueness theorems, or ansatzes are invoked to close the central argument. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard actor-critic assumptions hold, including existence of Q-values and valid policy gradient updates.
- domain assumption Human interventions provide implicit preference signals that correctly indicate suboptimal segments.
Reference graph
Works this paper leans on
-
[1]
H. Deng, Z. Wu, H. Liu, W. Guo, Y . Xue, Z. Shan, C. Zhang, B. Jia, Y . Ling, G. Lu, et al. A survey on reinforcement learning of vision-language-action models for robotic manipulation. Authorea Preprints, 2025
2025
-
[2]
Cui and J
J. Cui and J. Trinkle. Toward next-generation learned robot manipulation.Science robotics, 6 (54):eabd9461, 2021
2021
-
[3]
M. Yang, Y . Lin, A. Church, J. Lloyd, D. Zhang, D. A. Barton, and N. F. Lepora. Sim-to-real model-based and model-free deep reinforcement learning for tactile pushing.IEEE Robotics and Automation Letters, 8(9):5480–5487, 2023
2023
-
[4]
L. Chen, Y . Lei, S. Jin, Y . Zhang, and L. Zhang. Rlingua: Improving reinforcement learning sample efficiency in robotic manipulations with large language models.IEEE Robotics and Automation Letters, 9(7):6075–6082, 2024
2024
-
[5]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[6]
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao. Conrft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
-
[7]
H. Deng, Y . Lin, Y . Xue, H. Du, Q. Wang, B. Zhou, Z. Wu, and Z. Wang. E2hil: Entropy- guided sample selection for efficient real-world human-in-the-loop reinforcement learning. IEEE Robotics and Automation Letters, 2026
2026
-
[8]
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine. Serl: A software suite for sample-efficient robotic reinforcement learning. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 16961–16969. IEEE, 2024
2024
-
[9]
Zhang and H
T. Zhang and H. Mo. Reinforcement learning for robot research: A comprehensive review and open issues.International Journal of Advanced Robotic Systems, 18(3):17298814211007305, 2021
2021
- [10]
-
[11]
H. Ju, R. Juan, R. Gomez, K. Nakamura, and G. Li. Transferring policy of deep reinforcement learning from simulation to reality for robotics.Nature Machine Intelligence, 4(12):1077– 1087, 2022. 9
2022
-
[12]
Clavera, J
I. Clavera, J. Rothfuss, J. Schulman, Y . Fujita, T. Asfour, and P. Abbeel. Model-based re- inforcement learning via meta-policy optimization. InConference on robot learning, pages 617–629. PMLR, 2018
2018
-
[13]
M. A. Lee, C. Florensa, J. Tremblay, N. Ratliff, A. Garg, F. Ramos, and D. Fox. Guided uncertainty-aware policy optimization: Combining learning and model-based strategies for sample-efficient policy learning. In2020 IEEE international conference on robotics and au- tomation (ICRA), pages 7505–7512. IEEE, 2020
2020
-
[14]
K. Lei, H. Li, D. Yu, Z. Wei, L. Guo, Z. Jiang, Z. Wang, S. Liang, and H. Xu. Rl- 100: Performant robotic manipulation with real-world reinforcement learning.arXiv preprint arXiv:2510.14830, 2025
arXiv 2025
-
[15]
Zhong, K
F. Zhong, K. Wu, H. Ci, C. Wang, and H. Chen. Empowering embodied visual tracking with visual foundation models and offline rl. InEuropean Conference on Computer Vision, pages 139–155. Springer, 2024
2024
-
[16]
Kawaharazuka, T
K. Kawaharazuka, T. Matsushima, A. Gambardella, J. Guo, C. Paxton, and A. Zeng. Real- world robot applications of foundation models: A review.Advanced Robotics, 38(18):1232– 1254, 2024
2024
-
[17]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[18]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[19]
M. Vecerik, T. Hester, J. Scholz, F. Wang, O. Pietquin, B. Piot, N. Heess, T. Roth¨orl, T. Lampe, and M. Riedmiller. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards.arXiv preprint arXiv:1707.08817, 2017
Pith/arXiv arXiv 2017
-
[20]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[21]
Van Hasselt, A
H. Van Hasselt, A. Guez, and D. Silver. Deep reinforcement learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016
2016
-
[22]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
2018
-
[23]
Kumar, A
A. Kumar, A. Zhou, G. Tucker, and S. Levine. Conservative q-learning for offline reinforce- ment learning.Advances in neural information processing systems, 33:1179–1191, 2020
2020
-
[24]
Y . Cao, H. Zhao, Y . Cheng, T. Shu, Y . Chen, G. Liu, G. Liang, J. Zhao, J. Yan, and Y . Li. Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods.IEEE Transactions on Neural Networks and Learning Systems, 36(6):9737–9757, 2024
2024
-
[25]
Memarian, W
F. Memarian, W. Goo, R. Lioutikov, S. Niekum, and U. Topcu. Self-supervised online re- ward shaping in sparse-reward environments. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2369–2375. IEEE, 2021
2021
-
[26]
Devidze, P
R. Devidze, P. Kamalaruban, and A. Singla. Exploration-guided reward shaping for reinforce- ment learning under sparse rewards.Advances in Neural Information Processing Systems, 35: 5829–5842, 2022. 10
2022
-
[27]
Phan-Minh, F
T. Phan-Minh, F. Howington, T.-S. Chu, M. S. Tomov, R. E. Beaudoin, S. U. Lee, N. Li, C. Dicle, S. Findler, F. Suarez-Ruiz, et al. Driveirl: Drive in real life with inverse reinforcement learning. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 1544–1550. IEEE, 2023
2023
-
[28]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[29]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[30]
J. Hong, N. Lee, and J. Thorne. Orpo: Monolithic preference optimization without reference model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170–11189, 2024. 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.