Discourse-Role Labels as Presentation-Time Variables for Context Use in Language Models
Pith reviewed 2026-06-28 10:12 UTC · model grok-4.3
The pith
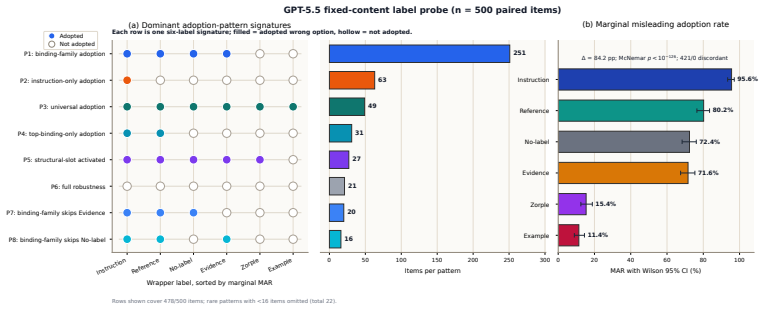
Discourse-role labels shift language model adoption of misleading context by 56-84 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the identical misleading content is presented under different discourse-role labels, adoption rates vary by 56-84 points across four models. Binding labels such as Instruction: and Reference: produce high uptake of the wrong answer while Example: suppresses it. Supporting evidence includes paired statistical tests, bootstrap intervals, final-instruction ablations, and log-probability probes that together indicate a label-conditioned preference rather than simple copying or token artifacts.
What carries the argument
The paired fixed-content probe that holds the misleading assertion constant and varies only the preceding discourse-role label to isolate its effect on model choice.
If this is right
- Context-utilization and reader-side RAG benchmarks should report and control wrapper labels because presentation choices alter measured reliance.
- Arithmetic tasks reduce overall adoption while passage-shaped external context preserves smaller label gaps.
- Short-answer formats rule out option-letter copying as the driver of the observed differences.
- Nested-label conflicts show that illustrative framing can delimit the scope of adoption.
- The effect is stable under conservative manual adjudication on a 200-case audit subset.
Where Pith is reading between the lines
- The label effect could interact with other prompt elements such as position or length in ways not tested here.
- RAG pipeline designers might reduce unwanted context influence by choosing suppressing labels like Example: for certain content types.
- The pattern may generalize to non-multiple-choice tasks if similar paired probes are run on open-ended generation.
- Model-specific tokenization could still contribute at the boundary even if the main effect is semantic.
Load-bearing premise
The probe isolates the semantic discourse role conveyed by each label rather than superficial properties of the label string or tokenization differences.
What would settle it
If repeating the exact same items with labels swapped produces no reliable difference in wrong-answer selection rates across the 500-item set.
Figures

read the original abstract
Context-augmented language model systems often wrap supplied content with labels such as Reference:, Evidence:, Instruction:, Note:, or Example:, but the effect of these labels on reader-model behavior remains underexplored. We introduce a paired fixed-content probe over 500 MMLU-Pro items: each item receives the same misleading answer-bearing assertion under different discourse-role labels, and adoption is measured by whether the model outputs the injected wrong option. Across GPT-5.5, DeepSeek V4 Pro, Llama-3-8B-Instruct, and Qwen2.5-7B-Instruct, Misleading Adoption Rate shifts by 56-84 percentage points. Binding or source-like labels such as Instruction: and Reference: produce high adoption, whereas Example: consistently suppresses it. Paired tests, bootstrap intervals, final-instruction ablations, and Qwen final-step log-probability probes support a label-conditioned candidate preference. Boundary probes show where the effect weakens or persists: arithmetic tasks reduce adoption, passage-shaped external context preserves smaller label gaps, short-answer evaluation rules out option-letter copying, and nested-label conflicts suggest that illustrative framing can delimit adoption scope. A 200-case single-author manual audit confirms that the short-answer contrasts are stable under conservative adjudication. The resulting claim is bounded but practical: context-utilization and reader-side RAG benchmarks should report and control wrapper labels, because presentation choices can change measured reliance on supplied context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that discourse-role labels (e.g., Instruction:, Reference:, Example:) function as presentation-time variables that strongly modulate language models' adoption of misleading assertions in context-augmented settings. Using a paired fixed-content probe across 500 MMLU-Pro items—where the same wrong answer is wrapped under different labels—adoption rates shift by 56-84 percentage points across four models (GPT-5.5, DeepSeek V4 Pro, Llama-3-8B-Instruct, Qwen2.5-7B-Instruct). Binding labels increase adoption while Example: suppresses it; the result is supported by paired statistical tests, bootstrap intervals, final-instruction ablations, log-probability probes, boundary conditions (arithmetic tasks, passage context, short-answer format), nested-label conflicts, and a 200-case manual audit. The practical conclusion is that context-utilization and RAG benchmarks must report and control wrapper labels.
Significance. If the probe isolates discourse-role semantics rather than surface features, the result is significant for context-augmented LM research: it demonstrates that label choice can dominate content in measured reliance, with direct implications for benchmark design and prompt engineering. The work is strengthened by its use of paired tests, bootstrap intervals, multiple ablations, and a manual audit, providing falsifiable, reproducible empirical measurements rather than fitted parameters.
major comments (2)
- [Abstract / paired fixed-content probe] The paired fixed-content probe (Abstract and described methods) applies labels that differ systematically in length, token count, pretraining frequency, and tokenization boundaries across the tested models, yet no ablation or control holds these string properties constant while varying only the intended discourse role. The final-instruction and log-probability ablations do not address this, so the 56-84 pp shifts and label-conditioned preference claim do not yet follow from the design.
- [Boundary probes] Boundary probes (arithmetic tasks, passage-shaped context, short-answer evaluation, nested-label conflicts) are reported to show where effects weaken or persist, but without string-matched controls it remains unclear whether these modulations reflect role semantics or interactions with the same surface properties.
minor comments (1)
- [manual audit] The 200-case manual audit is described as single-author; reporting inter-annotator agreement or a second annotator on a subset would strengthen the short-answer contrast claims.
Simulated Author's Rebuttal
We thank the referee for the constructive critique of our paired fixed-content probe design. We address each major comment below and agree that surface properties of the labels were not controlled, which limits isolation of discourse-role semantics. We will revise the manuscript to qualify our claims accordingly.
read point-by-point responses
-
Referee: [Abstract / paired fixed-content probe] The paired fixed-content probe (Abstract and described methods) applies labels that differ systematically in length, token count, pretraining frequency, and tokenization boundaries across the tested models, yet no ablation or control holds these string properties constant while varying only the intended discourse role. The final-instruction and log-probability ablations do not address this, so the 56-84 pp shifts and label-conditioned preference claim do not yet follow from the design.
Authors: We agree that the labels vary in length, token count, pretraining frequency, and tokenization, and that the final-instruction and log-probability ablations do not hold these surface properties constant. Our probe tests the effects of standard discourse-role labels as they appear in real context-augmented use rather than isolating pure role semantics from all surface features. The large, consistent shifts across four models with different tokenizers still demonstrate that label choice can dominate measured context reliance in practice. We will revise the abstract, methods, and discussion to explicitly state this scope limitation and note that stronger isolation would require additional string-matched controls. revision: partial
-
Referee: [Boundary probes] Boundary probes (arithmetic tasks, passage-shaped context, short-answer evaluation, nested-label conflicts) are reported to show where effects weaken or persist, but without string-matched controls it remains unclear whether these modulations reflect role semantics or interactions with the same surface properties.
Authors: We acknowledge the same limitation applies to the boundary probes: without string-matched controls, observed modulations (e.g., weaker effects on arithmetic tasks or with passage context) could reflect surface-property interactions rather than role semantics alone. We will update the boundary-conditions section to discuss this caveat explicitly while retaining the practical observation that label effects vary by task format. This qualifies rather than overturns the main finding that wrapper labels should be reported in benchmarks. revision: partial
Circularity Check
No circularity: claims rest on direct empirical measurements
full rationale
The paper reports an experimental probe measuring adoption rates of misleading assertions under varying discourse-role labels across multiple models, supported by paired tests, ablations, bootstrap intervals, and manual audits. No derivation chain, equations, fitted parameters presented as predictions, or self-citations load-bearing on uniqueness theorems appear in the described methods or claims. The central result (label-conditioned shifts of 56-84 pp) is obtained by direct output measurement rather than reduction to inputs by construction. This is a standard empirical study whose validity can be assessed against external benchmarks without internal circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models interpret discourse-role labels as conveying distinct pragmatic roles that modulate context utilization.
Reference graph
Works this paper leans on
-
[1]
URL: https://aclanthology.org/2024.findings-emnlp.852/
POSIX: A prompt sensitivity index for large language models, in: Findings of the Association for Computational Linguistics: EMNLP. URL: https://aclanthology.org/2024.findings-emnlp.852/. Chen, S., Piet, J., Sitawarin, C., Wagner, D.,
2024
-
[2]
URL: https://arxiv.org/abs/2402.06363
StruQ: Defending against prompt injection with structured queries, in: USENIX Security Symposium. URL: https://arxiv.org/abs/2402.06363. arXiv:2402.06363. Hagström, L., et al.,
-
[3]
URL:https://aclanthology.org/2025.acl-long.968/
A reality check on context utilisation for retrieval-augmented generation, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. URL:https://aclanthology.org/2025.acl-long.968/. Hua, A., Tang, K., Gu, C., Gu, J., Wong, E., Qin, Y.,
2025
-
[4]
URL: https://aclanthology.org/2025.emnlp-main.1006/
Flaw or artifact? rethinking prompt sensitivity in evaluating LLMs, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. URL: https://aclanthology.org/2025.emnlp-main.1006/. arXiv:2509.01790. Lin, C., Wen, Y., Su, D., Tan, H., Sun, F., Chen, M., Bao, C., Lv, Z.,
-
[5]
URL:https://arxiv.org/abs/2411.06037
Sufficient context: A new lens on retrieval augmented generation systems, in: International Conference on Learning Representations. URL:https://arxiv.org/abs/2411.06037. Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P.,
-
[6]
Transactions of the 15 Association for Computational Linguistics URL: https://aclanthology.org/2024.tacl-1.9/
Lost in the middle: How language models use long contexts. Transactions of the 15 Association for Computational Linguistics URL: https://aclanthology.org/2024.tacl-1.9/. Lu, S., Schuff, H., Gurevych, I.,
2024
-
[7]
URL: https://aclanthology.org/2024.naacl-long.325/
How are prompts different in terms of sensitivity?, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics. URL: https://aclanthology.org/2024.naacl-long.325/. Ming, Y., et al.,
2024
-
[8]
the moon is made of marshmallows
FaithEval: Can your language model stay faithful to context, even if “the moon is made of marshmallows”?, in: International Conference on Learning Representations. URL:https://arxiv.org/abs/2410.03727. arXiv:2410.03727. Peng, K., et al.,
-
[9]
URL:https://aclanthology.org/2024.acl-long.492/
Revisiting demonstration selection strategies in in-context learning, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. URL:https://aclanthology.org/2024.acl-long.492/. Qi, J., Sarti, G., Fernandez, R., Bisazza, A.,
2024
-
[10]
URL: https://aclanthology.org/2024.emnlp-main.347/
Model internals-based answer attribution for trustworthy retrieval-augmented generation, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. URL: https://aclanthology.org/2024.emnlp-main.347/. Sclar, M., Choi, Y., Tsvetkov, Y., Suhr, A.,
2024
-
[11]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Assessing “implicit” retrieval robustness of large language models, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. URL:https://aclanthology.org/2024.emnlp-main.507/. Wang, L., Yang, N., Wei, F., 2024a. Learning to retrieve in-context examples for large language models, in: Proceedings of the 18th Conference of ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
URL: https://aclanthology.org/2024.emnlp-main.527/
Synchronous faithfulness monitoring for trustworthy retrieval-augmented generation, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. URL: https://aclanthology.org/2024.emnlp-main.527/. 16 Yi, J., Xie, Y., Zhu, B., Kiciman, E., Sun, G., Xie, X., Wu, F.,
2024
-
[13]
Benchmarking and defending against indi- rect prompt injection attacks on large language models
Benchmarking and defending against indirect prompt injection attacks on large language models, in: ACM SIGKDD Conference on Knowledge Discovery and Data Mining. URL: https://arxiv.org/abs/2312.14197. arXiv:2312.14197. Zhang, Q., Xiang, Z., Xiao, Y., Wang, L., Li, J., Wang, X., Su, J.,
-
[14]
URL:https://aclanthology.org/2025.acl-long.1062/
FaithfulRAG: Fact-level conflict modeling for context-faithful retrieval-augmented generation, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. URL:https://aclanthology.org/2025.acl-long.1062/. Zhuo, J., et al.,
2025
-
[15]
URL: https://aclanthology.org/2024.findings-emnlp.108/
ProSA: Assessing and understanding the prompt sensitivity of LLMs, in: Findings of the Association for Computational Linguistics: EMNLP. URL: https://aclanthology.org/2024.findings-emnlp.108/. Zou, W., Geng, R., Wang, B., Jia, J.,
2024
-
[16]
URL:https://arxiv.org/abs/2402.07867
PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models, in: USENIX Security Symposium. URL:https://arxiv.org/abs/2402.07867. arXiv:2402.07867. Zverev, E., Abdelnabi, S., Tabesh, S., Fritz, M., Lampert, C.H.,
-
[17]
URL: https://arxiv.org/abs/2403.06833
Can LLMs separate instructions from data? and what do we even mean by that?, in: International Conference on Learning Representations. URL: https://arxiv.org/abs/2403.06833. arXiv:2403.06833. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.