On prediction-powered inference for quantile regression via convolution smoothing
Pith reviewed 2026-06-28 08:35 UTC · model grok-4.3
The pith
Convolution smoothing of the check-loss objective makes prediction-powered quantile regression computationally tractable while reducing overcoverage in confidence intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
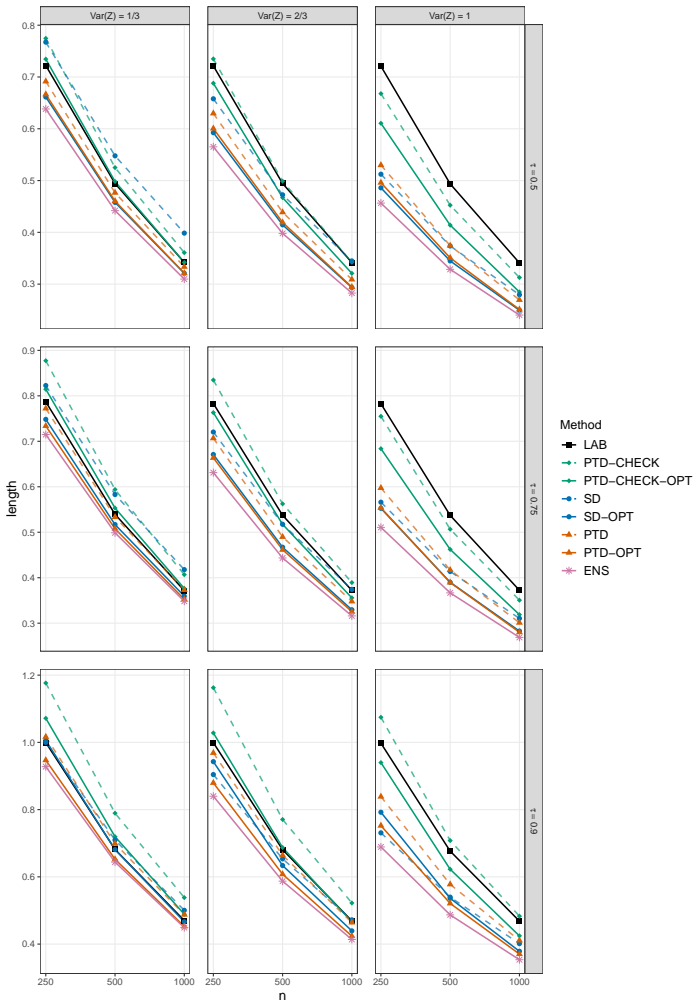
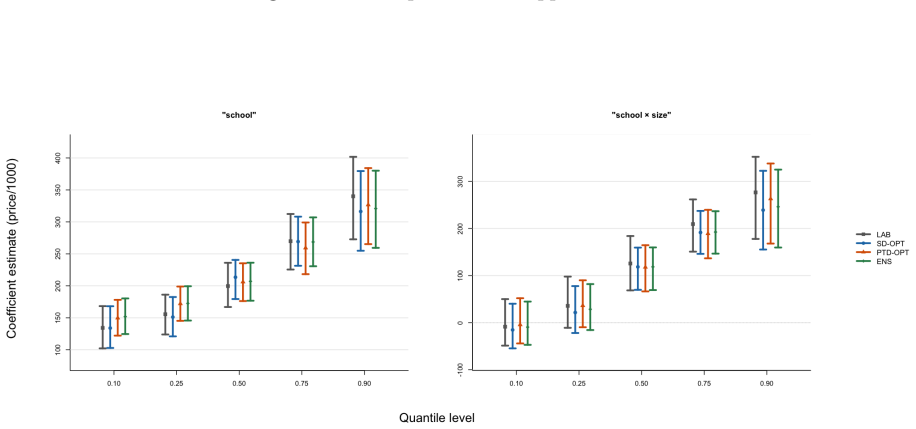
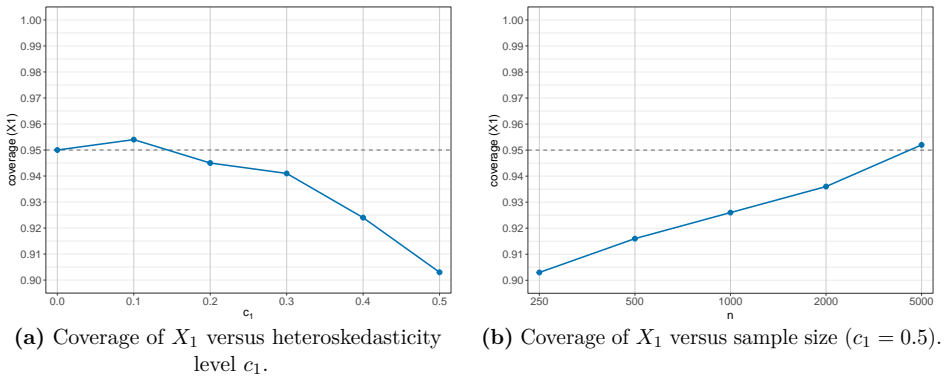
We propose a convolution-based smoothing of the check-loss objective and develop two variants of the estimator. The proposed estimators are computationally tractable, and our numerical studies show that they mitigate overcoverage. As a theoretical contribution, we establish the asymptotic distributions of the proposed estimators under a possibly misspecified linear quantile regression model. We further propose an ensemble of the two estimators.
What carries the argument
Convolution smoothing of the check-loss objective, which replaces the non-differentiable loss with a smoothed version that supports gradient-based computation while retaining the asymptotic properties needed for valid inference.
If this is right
- The two smoothed estimators can be computed efficiently even when the surrogate dataset is large.
- Asymptotic normality supplies explicit confidence intervals whose coverage improves over the naive extension.
- An ensemble of the two variants can be formed to balance their individual properties.
- The approach extends directly to applications such as housing price quantiles where limited gold-standard observations are supplemented by predictions.
Where Pith is reading between the lines
- The same smoothing idea could be applied to other non-smooth estimating equations that arise in prediction-powered settings.
- In domains that rely on AI surrogates, such as medical risk scores or financial forecasting, the method may yield tighter quantile estimates without sacrificing validity.
- Empirical choice of the smoothing bandwidth could be studied to optimize the trade-off between computational speed and interval width.
Load-bearing premise
The convolution smoothing preserves the key properties of the check loss so that the derived asymptotic distributions remain valid and do not introduce bias that invalidates the central limit theorem results, even under model misspecification.
What would settle it
If repeated simulations under the misspecified linear model show that the smoothed estimators fail to achieve the stated asymptotic normality or that their confidence intervals continue to exhibit the same degree of overcoverage as the unsmoothed version, the central claims would be falsified.
Figures

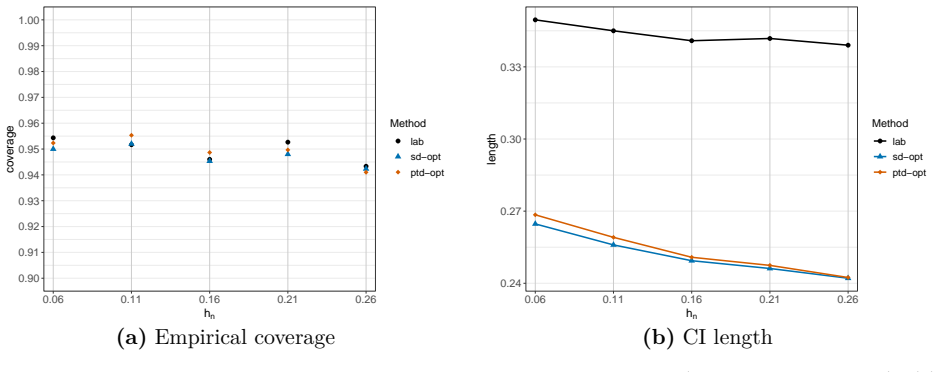

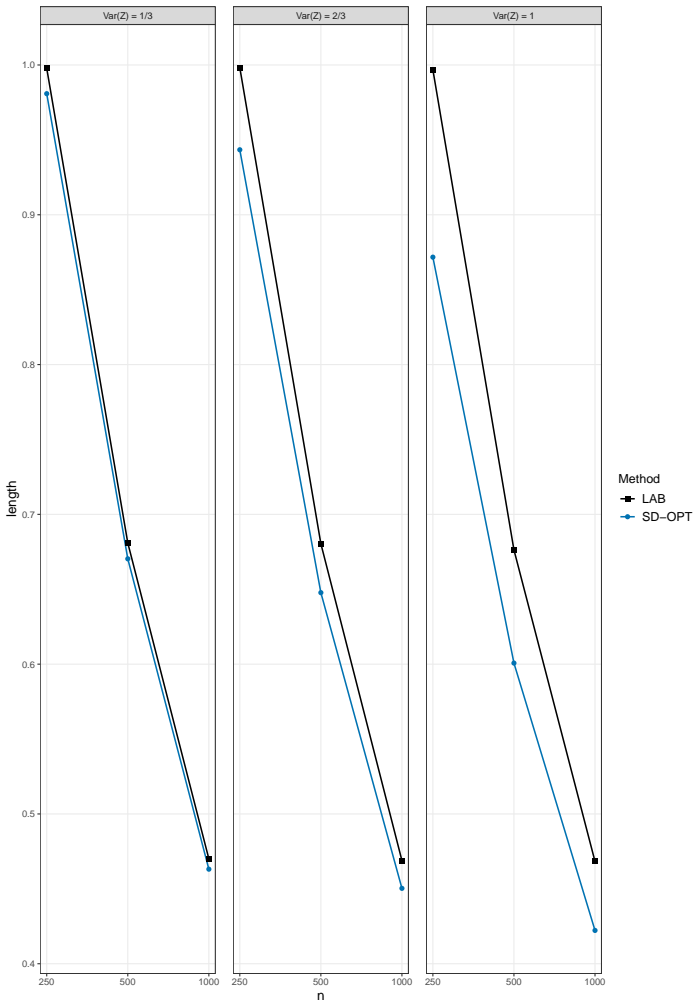
read the original abstract
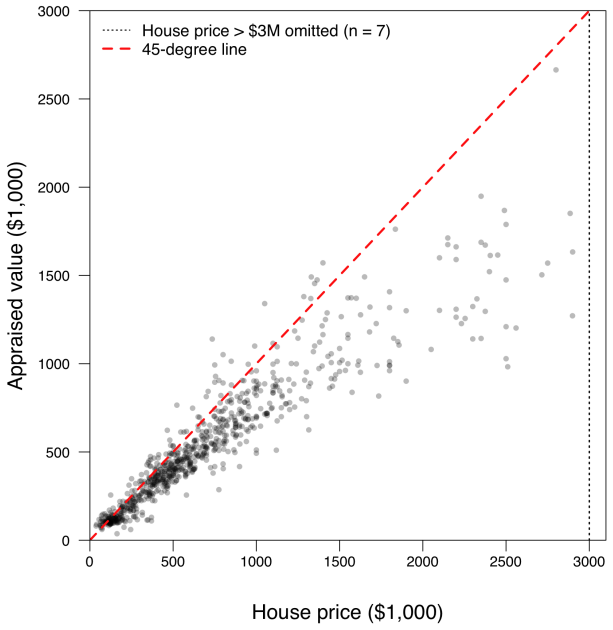
This paper studies quantile regression in a data-limited setting where the gold-standard outcome is available only for a limited number of observations, whereas a surrogate outcome is widely available. Such settings are becoming increasingly common with the availability of low-cost predictions from modern AI, motivating a growing line of research on "prediction-powered inference," for improved statistical inference. Naively extending this framework to quantile regression, however, raises two challenges: computational difficulties due to the discontinuity of the subgradient, and overly conservative confidence intervals. To address these issues, we propose a convolution-based smoothing of the check-loss objective and develop two variants of the estimator. The proposed estimators are computationally tractable, and our numerical studies show that they mitigate overcoverage. As a theoretical contribution, we establish the asymptotic distributions of the proposed estimators under a possibly misspecified linear quantile regression model. We further propose an ensemble of the two estimators and illustrate the proposed methods through simulations and an application to a local housing dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes convolution-based smoothing of the check-loss objective for quantile regression in the prediction-powered inference setting, where gold-standard outcomes are limited but surrogate predictions are abundant. It develops two variants of the resulting estimator, establishes their asymptotic distributions under a possibly misspecified linear quantile regression model, proposes an ensemble of the two, and reports that numerical studies show mitigation of overcoverage, with an illustration on a local housing dataset.
Significance. If the asymptotic results hold, the work supplies a computationally tractable route to quantile regression under PPI that addresses both non-differentiability and conservative intervals. The simulation evidence on overcoverage reduction and the real-data application constitute concrete strengths.
major comments (2)
- [Theoretical contribution (abstract)] Theoretical contribution paragraph: the assertion that the smoothed estimators retain the same asymptotic normal distribution (after centering) as the unsmoothed quantile regression estimator under misspecification requires that the convolution bias term is o_p(n^{-1/2}). The manuscript must specify the bandwidth sequence h_n and kernel conditions that guarantee this rate uniformly in the misspecified regime; without an explicit argument controlling the approximation error, the central CLT claim is not yet load-bearing.
- [Numerical studies] Numerical studies section: the reported mitigation of overcoverage is central to the practical claim, yet the abstract supplies no information on how standard errors or coverage probabilities were computed, what data-exclusion rules were applied, or how the bandwidth was selected in finite samples. These details are needed to evaluate whether the simulation design actually supports the overcoverage claim.
minor comments (2)
- [Abstract] The abstract refers to 'two variants of the estimator' without naming or briefly characterizing them; adding one-sentence descriptors would improve readability.
- [Methods] Notation for the convolution kernel and bandwidth should be introduced consistently when first used in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Theoretical contribution (abstract)] Theoretical contribution paragraph: the assertion that the smoothed estimators retain the same asymptotic normal distribution (after centering) as the unsmoothed quantile regression estimator under misspecification requires that the convolution bias term is o_p(n^{-1/2}). The manuscript must specify the bandwidth sequence h_n and kernel conditions that guarantee this rate uniformly in the misspecified regime; without an explicit argument controlling the approximation error, the central CLT claim is not yet load-bearing.
Authors: We agree that an explicit statement of the bandwidth and kernel conditions is necessary to rigorously justify that the smoothing bias is o_p(n^{-1/2}) uniformly under misspecification. The current derivation assumes this rate but does not list the precise requirements (e.g., h_n = o(n^{-1/4}) with a second-order kernel). We will add these conditions and the corresponding approximation-error bound to the theoretical section in the revision. revision: yes
-
Referee: [Numerical studies] Numerical studies section: the reported mitigation of overcoverage is central to the practical claim, yet the abstract supplies no information on how standard errors or coverage probabilities were computed, what data-exclusion rules were applied, or how the bandwidth was selected in finite samples. These details are needed to evaluate whether the simulation design actually supports the overcoverage claim.
Authors: The computational details for standard errors (via the asymptotic variance formula), coverage evaluation, data-exclusion rules, and bandwidth selection (cross-validation) are fully specified in Section 4. To improve transparency, we will revise the abstract to include a short clause noting that these quantities follow the procedures described in the numerical studies section. revision: partial
Circularity Check
No circularity; asymptotics and estimators derived independently
full rationale
The paper introduces convolution smoothing of the check-loss for quantile regression under prediction-powered inference with limited gold-standard outcomes. It develops two estimator variants, reports numerical mitigation of overcoverage, and states that asymptotic distributions are established under possible misspecification of the linear quantile model. No equations, definitions, or claims in the abstract or description reduce the target asymptotic result to a fitted parameter by construction, nor do they rely on self-citation chains or imported uniqueness theorems. The derivation chain appears self-contained against external benchmarks, with smoothing introduced as a computational device whose bias control is asserted via separate theoretical arguments rather than by redefinition of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Smoothed quantile regression with large-scale inference , journal =
Xuming He and Xiaoou Pan and Kean Ming Tan and Wen-Xin Zhou , keywords =. Smoothed quantile regression with large-scale inference , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.jeconom.2021.07.010 , url =
-
[2]
A. W. van der Vaart and Jon A. Wellner , title =. 2023 , doi =
2023
-
[3]
Probability in Banach Spaces , subtitle=
Ledoux, Michel and Talagrand, Michel , year=. Probability in Banach Spaces , subtitle=. doi:10.1007/978-3-642-20212-4 , isbn=
-
[4]
arXiv preprint arXiv:2501.09731 , year=
Predictions as surrogates: Revisiting surrogate outcomes in the age of ai , author=. arXiv preprint arXiv:2501.09731 , year=
-
[5]
van der Vaart, A. W. , TITLE =. 1998 , PAGES =. doi:10.1017/CBO9780511802256 , URL =
-
[6]
Knight, Keith , TITLE =. Ann. Statist. , FJOURNAL =. 1998 , NUMBER =. doi:10.1214/aos/1028144858 , URL =
-
[7]
arXiv preprint arXiv:2501.18577 , year=
Prediction-powered inference with imputed covariates and nonuniform sampling , author=. arXiv preprint arXiv:2501.18577 , year=
-
[8]
Scandinavian Journal of Statistics , volume=
Asymptotic properties of the maximum smoothed partial likelihood estimator in the change-plane Cox model , author=. Scandinavian Journal of Statistics , volume=. 2023 , publisher=
2023
-
[9]
Kosorok, Michael R. , TITLE =. 2008 , PAGES =. doi:10.1007/978-0-387-74978-5 , URL =
-
[10]
Angrist, Joshua and Chernozhukov, Victor and Fern\'andez-Val, Iv\'an , TITLE =. Econometrica , FJOURNAL =. 2006 , NUMBER =. doi:10.1111/j.1468-0262.2006.00671.x , URL =
-
[11]
Koenker, Roger , TITLE =. 2005 , PAGES =. doi:10.1017/CBO9780511754098 , URL =
-
[12]
Fernandes, Marcelo and Guerre, Emmanuel and Horta, Eduardo , TITLE =. J. Bus. Econom. Statist. , FJOURNAL =. 2021 , NUMBER =. doi:10.1080/07350015.2019.1660177 , URL =
-
[13]
Econometrica46(1), 33–50 (1978) https://doi.org/10.2307/1913643
Koenker, Roger and Bassett, Jr., Gilbert , TITLE =. Econometrica , FJOURNAL =. 1978 , NUMBER =. doi:10.2307/1913643 , URL =
-
[14]
Wang, Yumeng and Panigrahi, Snigdha and He, Xuming , TITLE =. Ann. Statist. , FJOURNAL =. 2025 , NUMBER =. doi:10.1214/24-aos2488 , URL =
-
[15]
Belloni, Alexandre and Chernozhukov, Victor , TITLE =. Ann. Statist. , FJOURNAL =. 2011 , NUMBER =. doi:10.1214/10-AOS827 , URL =
-
[16]
Portnoy, Stephen , TITLE =. J. Amer. Statist. Assoc. , FJOURNAL =. 2003 , NUMBER =. doi:10.1198/016214503000000954 , URL =
-
[17]
Koenker, Roger , TITLE =. J. Multivariate Anal. , FJOURNAL =. 2004 , NUMBER =. doi:10.1016/j.jmva.2004.05.006 , URL =
-
[18]
PLoS biology , volume=
The structural context of posttranslational modifications at a proteome-wide scale , author=. PLoS biology , volume=. 2022 , publisher=
2022
-
[19]
Nature , volume=
Highly accurate protein structure prediction with AlphaFold , author=. Nature , volume=. 2021 , publisher=
2021
-
[20]
and Radivojac, Predrag and Brown, Celeste J
Iakoucheva, Lilia M. and Radivojac, Predrag and Brown, Celeste J. and O’Connor, Timothy R. and Sikes, Jason G. and Obradovic, Zoran and Dunker, A. Keith , title =. Nucleic Acids Research , volume =. 2004 , month =. doi:10.1093/nar/gkh253 , url =
-
[21]
and Rotnitzky, Andrea and Zhao, Lue Ping , TITLE =
Robins, James M. and Rotnitzky, Andrea and Zhao, Lue Ping , TITLE =. J. Amer. Statist. Assoc. , FJOURNAL =. 1994 , NUMBER =
1994
-
[22]
Chen, Yi-Hau and Chen, Hung , TITLE =. J. R. Stat. Soc. Ser. B Stat. Methodol. , FJOURNAL =. 2000 , NUMBER =. doi:10.1111/1467-9868.00243 , URL =
-
[23]
and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I
Angelopoulos, Anastasios N. and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I. and Zrnic, Tijana , TITLE =. Science , FJOURNAL =. 2023 , NUMBER =
2023
-
[24]
arXiv preprint arXiv:2311.01453 , year=
PPI++: Efficient prediction-powered inference , author=. arXiv preprint arXiv:2311.01453 , year=
-
[25]
Miao, Jiacheng and Miao, Xinran and Wu, Yixuan and Zhao, Jiwei and Lu, Qiongshi , TITLE =. J. Mach. Learn. Res. , FJOURNAL =. 2025 , PAGES =
2025
-
[26]
Gan, Feng and Liang, Wanfeng and Zou, Changliang , TITLE =. Aust. N. Z. J. Stat. , FJOURNAL =. 2024 , NUMBER =. doi:10.1111/anzs.12429 , URL =
-
[27]
arXiv preprint arXiv:2411.19908 , year=
Another look at inference after prediction , author=. arXiv preprint arXiv:2411.19908 , year=
-
[28]
Seo, Myung Hwan and Linton, Oliver , TITLE =. J. Econometrics , FJOURNAL =. 2007 , NUMBER =. doi:10.1016/j.jeconom.2006.11.002 , URL =
-
[29]
2022 , url =
R: A Language and Environment for Statistical Computing , author =. 2022 , url =
2022
-
[30]
Falk, Michael , TITLE =. Comm. Statist. Simulation Comput. , FJOURNAL =. 1999 , NUMBER =. doi:10.1080/03610919908813578 , URL =
-
[31]
2002 , note =
Modern Applied Statistics with S , author =. 2002 , note =
2002
-
[32]
Pan, Xiaoou and Zhou, Wen-Xin , TITLE =. Inf. Inference , FJOURNAL =. 2021 , NUMBER =. doi:10.1093/imaiai/iaaa006 , URL =
-
[33]
Nature genetics , volume=
Synthetic surrogates improve power for genome-wide association studies of partially missing phenotypes in population biobanks , author=. Nature genetics , volume=. 2024 , publisher=
2024
-
[34]
Nature genetics , volume=
Valid inference for machine learning-assisted genome-wide association studies , author=. Nature genetics , volume=. 2024 , publisher=
2024
-
[35]
Journal of the Royal Statistical Society Series A: Statistics in Society , pages=
Control function quantile hedonic pricing , author=. Journal of the Royal Statistical Society Series A: Statistics in Society , pages=. 2025 , publisher=
2025
-
[36]
Journal of Housing Economics , volume=
Hedonic house prices and spatial quantile regression , author=. Journal of Housing Economics , volume=. 2012 , publisher=
2012
-
[37]
Missouri School Improvement Program Annual Performance Report (APR) data , year =
-
[38]
and Hall, Peter and Young, G
De Angelis, D. and Hall, Peter and Young, G. A. , TITLE =. J. Amer. Statist. Assoc. , FJOURNAL =. 1993 , NUMBER =
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.