FindIt: A Format-Informed Visual Detection Benchmark for Generalist Multimodal LLMs
Pith reviewed 2026-06-28 10:15 UTC · model grok-4.3
The pith
A new benchmark for multimodal LLMs reveals they fail at localization tasks because they cannot reliably follow output formatting rules for bounding boxes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
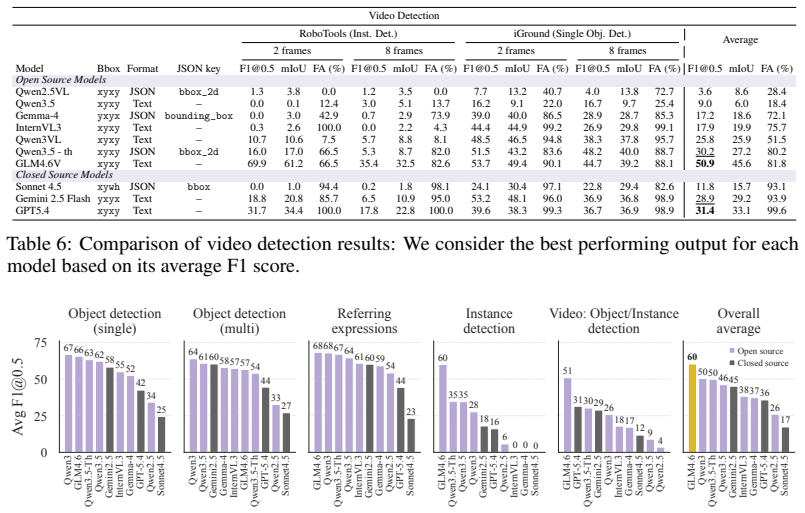
The paper establishes that no prior benchmark systematically measures the promptable localization abilities of generalist MLLMs at scale, and that the new FindIt suite—with its four task categories, standardized inputs, and enforced parsable bounding-box outputs—demonstrates that current models remain highly sensitive to formatting constraints and fail to generalize even to minor variations in localization settings.
What carries the argument
The FindIt benchmark, which standardizes inputs across four localization task categories, requires parsable bounding-box outputs, and applies transparent evaluation protocols to measure both accuracy and format adherence.
If this is right
- Current MLLMs are highly sensitive to formatting constraints in localization tasks.
- Models often fail to generalize to even minor variations in localization settings.
- Performance must be measured on both accuracy and adherence to output format specifications.
- The benchmark identifies concrete directions for improving multimodal model design for structured vision tasks.
Where Pith is reading between the lines
- Training pipelines may need explicit objectives that reward consistent structured output across format variations.
- Unreliable localization could propagate errors in downstream agentic decision systems that rely on MLLM outputs.
- Similar format-robustness tests could be applied to other structured outputs such as segmentation masks or keypoint lists.
Load-bearing premise
The chosen task categories together with the unified input standardization and parsable bounding-box output requirement provide a representative and unbiased measure of real-world promptable localization ability.
What would settle it
A controlled test in which the same models receive the identical localization prompts but with relaxed or randomized output-format instructions, then measuring whether success rates rise substantially or remain low.
Figures





read the original abstract
Multimodal large language models (MLLMs) are predominantly evaluated on free-form vision-language tasks such as visual question answering, captioning, and summarization. However, their practical use is rapidly expanding to more structured computer vision settings, where users prompt models to perform localization-centric tasks such as object detection, often within larger agentic or decision-making systems. Despite this shift, there is currently no standardized benchmark that systematically evaluates these capabilities at scale. In this work, we introduce the first comprehensive benchmark specifically designed to assess the promptable localization abilities of generalist MLLMs. Our benchmark spans four core task categories: object detection, referring expression detection, instance-level detection, and video-based detection. To enable consistent and fair evaluation, we develop a unified framework that standardizes inputs, enforces parsable bounding box outputs, and defines transparent evaluation protocols across tasks. Using this suite, we evaluate a diverse set of open-source and proprietary MLLMs, providing an in-depth analysis of their performance and limitations. Beyond accuracy, we examine models' ability to adhere to output format specifications, showing that current systems are highly sensitive to formatting constraints and often fail to generalize even to minor variations. Our results highlight both the strengths and shortcomings of state-of-the-art MLLMs in localization settings, and point toward important directions for improving multimodal model design and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FindIt, the first comprehensive benchmark designed to assess the promptable localization abilities of generalist multimodal LLMs. It spans four core task categories (object detection, referring expression detection, instance-level detection, and video-based detection), develops a unified framework that standardizes inputs, enforces parsable bounding-box outputs, and defines transparent evaluation protocols, evaluates a diverse set of open-source and proprietary MLLMs, and analyzes both accuracy and adherence to output format specifications, concluding that current systems are highly sensitive to formatting constraints and often fail to generalize even to minor variations.
Significance. If the benchmark construction and evaluation protocols are robust, the work is significant for filling a gap in standardized assessment of MLLMs on structured, localization-centric tasks that are increasingly used in agentic and decision-making systems. The explicit focus on format sensitivity and generalization provides actionable insights for model design. The paper earns credit for its unified input/output standardization and transparent protocols across tasks.
minor comments (3)
- Abstract: the claim of 'in-depth analysis' would be strengthened by briefly noting the number of models evaluated and the scale of the benchmark (e.g., number of images or prompts) to give readers an immediate sense of scope.
- The manuscript should include a dedicated section or table that explicitly lists the exact evaluation metrics (e.g., IoU thresholds, parsing success rate) used for each task category to ensure reproducibility.
- Figure or table captions describing model outputs should clarify how 'parsable bounding box' success is measured when models produce free-form text, as this directly supports the format-sensitivity claim.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and positive assessment of FindIt as a significant contribution for standardizing evaluation of MLLMs on localization tasks. The recommendation for minor revision is noted. No specific major comments were listed in the report, so we provide no point-by-point responses below.
Circularity Check
Benchmark introduction with no derivation chain or self-referential predictions
full rationale
The paper introduces a new benchmark (FindIt) spanning four task categories for promptable localization in MLLMs, standardizes inputs/outputs, and reports direct evaluation results on model performance and format sensitivity. No equations, fitted parameters, predictions, or load-bearing derivations appear in the provided text. Claims rest on empirical evaluation protocols rather than any reduction to self-defined inputs or self-citations. This is the expected outcome for a benchmark paper; the derivation chain is absent by design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude sonnet 4.5, 2025
Anthropic. Claude sonnet 4.5, 2025. URL https://www.anthropic.com/news/ claude-sonnet-4-5
2025
-
[2]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers. InECCV, 2020
2020
-
[3]
J. Chen, F. Wei, J. Zhao, S. Song, B. Wu, Z. Peng, S. H. G. Chan, and H. Zhang. Revisiting referring expression comprehension evaluation in the era of large multimodal models, 2024. URLhttps://arxiv.org/abs/2406.16866
arXiv 2024
-
[4]
G. Comanici, E. Bieber, M. Schaekermann, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[5]
Everingham, L
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. http://www.pascal- network.org/challenges/VOC/voc2007/workshop/index.html, 2007
2007
-
[6]
GLM-V Team. Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning, 2025. URLhttps://arxiv.org/abs/2507.01006
Pith/arXiv arXiv 2025
-
[7]
Gemma 4, 2025
Google DeepMind. Gemma 4, 2025. URL https://deepmind.google/models/gemma/ gemma-4/
2025
-
[8]
K. Goto, T. Hirose, M. Ukai, S. Kurita, and N. Inoue. Referring expression comprehension for small objects. InICCV, 2025
2025
-
[9]
Gupta, P
A. Gupta, P. Dollár, and R. Girshick. Lvis: A dataset for large vocabulary instance segmentation. InCVPR, 2019
2019
-
[10]
Huang, A
J. Huang, A. Kane, F. Zhou, Y . Wei, and H. Shi. Le-detr: Revisiting real-time detection transformer with efficient encoder design. InCVPR Findings, 2026
2026
-
[11]
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025
InternVL3 Team. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025. URLhttps://arxiv.org/abs/2504.10479
Pith/arXiv arXiv 2025
-
[12]
G. Jin, J. Wu, T. Guo, Y . Niu, W. Zhou, and G. Liu. Knowdr-rec: A benchmark for referring expression comprehension with real-world knowledge.preprint arXiv:2508.14080, 2025
arXiv 2025
-
[13]
Kazakos, C
E. Kazakos, C. Schmid, and J. Sivic. Large-scale pre-training for grounded video caption generation. InICCV, 2025
2025
-
[14]
Kazemzadeh, V
S. Kazemzadeh, V . Ordonez, M. Matten, and T. Berg. ReferItGame: Referring to objects in photographs of natural scenes. InEMNLP, 2014. 10
2014
-
[15]
R. Krishna, Y . Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y . Kalantidis, L.-J. Li, D. A. Shamma, M. S. Bernstein, and L. Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International Journal of Computer Vision, 123:32–73, 2017. doi: 10.1007/s11263-016-0981-7. URL https://doi.org/10. 1007/s1...
-
[16]
Kuznetsova, H
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov, T. Duerig, and V . Ferrari. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.IJCV, 2020
2020
-
[17]
B. Li, J. Wang, Y . Hu, C. Wang, and S. Scherer. V oxdet: V oxel learning for novel instance detection. InNeurIPS, 2023
2023
-
[18]
Y .-H. Liao, R. Mahmood, S. Fidler, and D. Acuna. Can large vision-language models correct semantic grounding errors by themselves? InCVPR, 2025
2025
-
[19]
T.-Y . Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár. Microsoft coco: Common objects in context.arXiv preprint arxiv:1405.0312, 2015
Pith/arXiv arXiv 2015
-
[20]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. arXiv:2310.03744, 2023
Pith/arXiv arXiv 2023
-
[21]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. InNeurIPS, 2023
2023
-
[22]
H. Liu, C. Li, Y . Li, B. Li, Y . Zhang, S. Shen, and Y . J. Lee. Llava-next: Improved rea- soning, ocr, and world knowledge, 2024. URL https://llava-vl.github.io/blog/ 2024-01-30-llava-next/
2024
-
[23]
J. Mao, J. Huang, A. Toshev, O. Camburu, A. Yuille, and K. Murphy. Generation and compre- hension of unambiguous object descriptions. InCVPR, 2016
2016
-
[24]
Molmo and PixMo Team. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models.arXiv preprint arXiv:2409.17146, 2024
Pith/arXiv arXiv 2024
-
[25]
Gpt-5, 2025
OpenAI. Gpt-5, 2025. URLhttps://openai.com/index/gpt-5-system-card/
2025
-
[26]
J. S. Park, Z. Ma, L. Li, C. Zheng, C.-Y . Hsieh, X. Lu, K. Chandu, Q. Kong, N. Kobori, A. Farhadi, Y . Choi, and R. Krishna. Synthetic visual genome: Dense scene graphs at scale with multimodal language models. InCVPR, 2025
2025
-
[27]
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. InICCV, 2016
2016
-
[28]
Pyatkin, S
V . Pyatkin, S. Malik, V . Graf, H. Ivison, S. Huang, P. Dasigi, N. Lambert, and H. Hajishirzi. Generalizing verifiable instruction following. InNeurIPS, 2025
2025
-
[29]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[30]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[31]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Qwen2.5-VL Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[32]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Qwen3-VL. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[33]
Robinson, P
I. Robinson, P. Robicheaux, M. Popov, D. Ramanan, and N. Peri. Rf-detr: Neural architecture search for real-time detection transformers. InICLR, 2026
2026
-
[34]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge.IJCV, 2015
2015
-
[35]
Samuel, R
D. Samuel, R. Ben-Ari, M. Levy, N. Darshan, and G. Chechik. Where’s waldo: Diffusion features for personalized segmentation and retrieval. InNeurIPS, 2024. 11
2024
-
[36]
R. Sapkota and M. Karkee. Ultralytics yolo evolution: An overview of yolo26, yolo11, yolov8 and yolov5 object detectors for computer vision and pattern recognition, 2026. URL https://arxiv.org/abs/2510.09653
arXiv 2026
-
[37]
Schulter, V
S. Schulter, V . K. B. G, Y . Suh, K. M. Dafnis, Z. Zhang, S. Zhao, and D. Metaxas. Omnilabel: A challenging benchmark for language-based object detection. InICCV, 2023
2023
-
[38]
S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, J. Li, X. Zhang, and J. Sun. Objects365: A large-scale, high-quality dataset for object detection. InICCV, 2019
2019
-
[39]
Q. Shen, Y . Zhao, N. Kwon, J. Kim, Y . Li, and S. Kong. Solving instance detection from an open-world perspective. InCVPR, 2025
2025
-
[40]
Shihua, L
H. Shihua, L. Zhichao, C. Xiaodong, Y . Yongjun, Z. Xiao, and S. Xi. Deim: Detr with improved matching for fast convergence. InCVPR, 2025
2025
-
[41]
W. Wang, Q. Lv, W. Yu, W. Hong, J. Qi, Y . Wang, J. Ji, Z. Yang, L. Zhao, X. Song, J. Xu, B. Xu, J. Li, Y . Dong, M. Ding, and J. Tang. Cogvlm: Visual expert for pretrained language models. preprint arXiv:2311.03079, 2023
Pith/arXiv arXiv 2023
-
[42]
F. Wei, J. Zhao, K. Yan, H. Zhang, and C. Xu. A large-scale human-centric benchmark for referring expression comprehension in the LMM era. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[43]
C. Wu, Z. Lin, S. Cohen, T. Bui, and S. Maji. Phrasecut: Language-based image segmentation in the wild. InCVPR, 2020
2020
-
[44]
C. Xie, Z. Zhang, Y . Wu, F. Zhu, R. Zhao, and S. Liang. Described object detection: Liberating object detection with flexible expressions. InNeurIPS, 2023
2023
-
[45]
Y . Xu, L. Zhu, and Y . Yang. Mc-bench: A benchmark for multi-context visual grounding in the era of mllms. InICCV, 2025
2025
-
[46]
H. Yin, Y . Ren, K. Yan, S. Ding, and Y . Hao. Rod-mllm: Towards more reliable object detection in multimodal large language models. InCVPR, 2025
2025
-
[47]
L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg. Modeling context in referring expressions. InECCV, 2016
2016
-
[48]
Zhang, X
J. Zhang, X. Chen, Q. Wang, M. Li, Y . Guo, Y . Hu, J. Zhang, S. Bai, J. Lin, and J. Chen. Vlm4vla: Revisiting vision-language-models in vision-language-action models, 2026
2026
-
[49]
<key>": [<bbox>]}, ...] Repeat the
R. Zhang, Z. Jiang, Z. Guo, S. Yan, J. Pan, H. Dong, P. Gao, and H. Li. Personalize segment anything model with one shot.arXiv preprint arXiv:2305.03048, 2023. 12 A Appendix A.1 Overview This appendix collects supplementary material referenced from the main paper. Section A.2 describes the multi-stage format search that selects each model’s bounding-box r...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.