Spatially Grounded Concept Bottleneck Models via Part-Factorized Attention
Pith reviewed 2026-06-28 07:08 UTC · model grok-4.3
The pith
A part-factorized attention model with a dataset-average Gaussian prior lets concept bottleneck models reach 88.85 percent accuracy on CUB-200-2011 while lifting pointing accuracy 16 points without per-image keypoint labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a fixed concept-to-part routing map, a learned foreground gate on DINOv3 patch features, and a learnable two-dimensional Gaussian prior added in log space to the attention logits—initialized from dataset-average keypoint locations—resolve part-query permutation symmetry and ground each attribute to its named body part, producing 88.85 percent top-1 accuracy and 52.6 percent pointing accuracy on CUB-200-2011 while matching a fully supervised baseline.
What carries the argument
Part-factorized cross-attention in which each of the 312 attributes reads exclusively from the part token assigned by a fixed map, modulated by an additive learnable Gaussian prior and a foreground gate.
If this is right
- The spatial-prior model matches fully supervised top-1 accuracy at 88.85 percent versus 88.95 percent.
- Pointing accuracy rises from 36.4 percent to 52.6 percent.
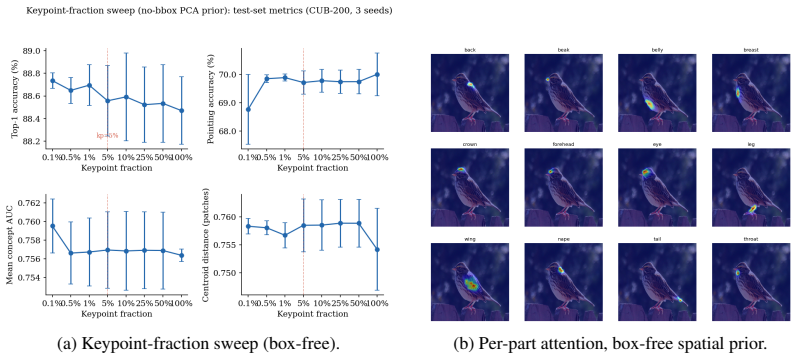
- All per-image supervision can be removed by substituting a PCA foreground target, still yielding 88.6 percent top-1 accuracy at about 70 percent pointing accuracy.
- Initializing the prior from only 0.5 percent of the training set, roughly 27 images, produces no measurable loss.
- Removing the spatial prior entirely collapses pointing accuracy to 2.9 percent.
Where Pith is reading between the lines
- The same average-keypoint initialization could substitute for per-image labels on other fine-grained datasets that supply only class labels.
- The factorization suggests a route to scale concept bottleneck models to domains where dense part annotations are unavailable.
- The foreground gate and part routing could be combined with other frozen vision transformers beyond DINOv3 to test whether the grounding benefit is architecture-specific.
Load-bearing premise
The fixed assignment of each of the 312 CUB attributes to one body part is accurate and the single dataset-average keypoint location per part is enough to let the learnable Gaussian prior resolve which query token belongs to which part without any per-image labels.
What would settle it
If adding the part routing and Gaussian prior leaves pointing accuracy near 36 percent or drops top-1 accuracy below the supervised baseline of 88.95 percent, the claim that the spatial prior successfully grounds the concepts would be refuted.
Figures

read the original abstract
Concept bottleneck models (CBMs) predict a layer of human-named attributes before predicting a class, which makes their decisions auditable. On fine-grained recognition tasks the concept heads are usually free to attend anywhere in the image, so a head named for one body region can be satisfied by evidence on another. This work studies a part-factorized CBM that removes that freedom by construction. The method has three components built on a frozen DINOv3 vision transformer. A learned foreground gate, trained on DINOv3 patch features, suppresses background patches inside the part attention. A set of part queries cross-attends to patch features and each of the 312 CUB attributes is routed, through a fixed concept-to-part map, to read only from the part token its name implies. A learnable two-dimensional Gaussian prior, injected additively in log space into the attention logits, breaks the permutation symmetry among part queries; its means are initialized from the dataset-average keypoint location of each part, which requires no per-image keypoint supervision at training or test time. On CUB-200-2011 the spatial-prior model matches a fully supervised baseline (88.85% versus 88.95% top-1) while raising pointing accuracy by 16 points (52.6% versus 36.4%). Replacing bounding-box supervision with a PCA foreground target and combining it with the Gaussian prior removes all per-image supervision and reaches 88.6% top-1 at about 70% pointing accuracy. A keypoint-fraction sweep shows that 0.5% of the training set (about 27 images) suffices to initialize the prior with no measurable loss. Removing part identity entirely is the harder case: without any spatial prior, pointing accuracy collapses to $2.9\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a part-factorized concept bottleneck model (CBM) built on a frozen DINOv3 vision transformer for fine-grained recognition on CUB-200-2011. It adds a learned foreground gate on patch features, part queries that cross-attend to patches, fixed routing of each of the 312 attributes to its named part token via a concept-to-part map, and a learnable 2D Gaussian prior (initialized from dataset-average keypoint locations) injected into attention logits to resolve part-query symmetry. The spatial-prior model matches a fully supervised baseline at 88.85% top-1 accuracy while improving pointing accuracy by 16 points (52.6% vs. 36.4%); a PCA-foreground variant with the prior reaches 88.6% top-1 at ~70% pointing accuracy with no per-image supervision.
Significance. If the grounding claim holds, the work shows that part factorization plus a data-average prior can enforce spatially localized concept heads in CBMs while preserving accuracy and reducing supervision requirements. The keypoint-fraction sweep demonstrating that 0.5% of the training set (~27 images) suffices for prior initialization is a concrete, reproducible strength that supports practical deployment.
major comments (2)
- [Method (concept-to-part map)] Method section (concept-to-part routing): The claim that attention is spatially grounded 'by construction' rests on the fixed concept-to-part map correctly assigning each of the 312 attributes to its semantically appropriate part query. No construction details for the map are provided, and no ablation that randomizes or perturbs the assignments is reported. This is load-bearing; incorrect assignments would allow high classification accuracy while rendering the reported pointing gains (52.6% and ~70%) uninterpretable as evidence of intended part-specific grounding.
- [Experiments (pointing accuracy)] Experiments (pointing accuracy results): The 16-point pointing gain and the 70% accuracy of the PCA+prior variant are presented without error bars, multiple random seeds, or sensitivity analysis to the map. Given that the Gaussian prior is initialized from dataset averages and the foreground gate is learned, these metrics require statistical support to substantiate the central claim that the architecture removes per-image supervision while retaining spatial grounding.
minor comments (2)
- [Method (Gaussian prior)] The notation for the additive Gaussian prior in log-attention space should be made explicit (e.g., which parameters are learned vs. fixed) to allow exact reproduction of the initialization from keypoint averages.
- [Experiments (keypoint-fraction sweep)] Clarify whether the dataset-average keypoint locations used for prior initialization are computed on the full training set or only on the 0.5% subset in the main reported runs.
Circularity Check
No circularity: architectural routing and empirical metrics remain independent of fitted inputs
full rationale
The paper's central construction routes attributes to part tokens via a fixed external concept-to-part map on top of a frozen DINOv3 backbone, with a Gaussian prior initialized from dataset averages but then learned. Reported top-1 accuracy and pointing accuracy are measured outcomes on CUB-200-2011, not quantities that reduce by definition to the prior parameters or the map. No equations equate a prediction to a fitted input, no self-citation chain supports a uniqueness claim, and the 'by construction' phrasing refers to the routing architecture rather than a tautological redefinition. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable 2D Gaussian prior parameters
- foreground gate weights
axioms (1)
- domain assumption A fixed concept-to-part map accurately routes each attribute to its corresponding part token.
Reference graph
Works this paper leans on
-
[1]
and Branson, S
Wah, C. and Branson, S. and Welinder, P. and Perona, P. and Belongie, S. , title =
-
[2]
Proceedings of the 37th International Conference on Machine Learning , series =
Koh, Pang Wei and Nguyen, Thao and Tang, Yew Siang and Mussmann, Stephen and Pierson, Emma and Kim, Been and Liang, Percy , title =. Proceedings of the 37th International Conference on Machine Learning , series =
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Discovering fine-grained visual-concept relations by disentangled optimal transport concept bottleneck models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Advances in Neural Information Processing Systems , volume=
Vlg-cbm: Training concept bottleneck models with vision-language guidance , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Language in a bottle: Language model guided concept bottlenecks for interpretable image classification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
and Weng, Tsui-Wei , title =
Oikarinen, Tuomas and Das, Subhro and Nguyen, Lam M. and Weng, Tsui-Wei , title =. The Eleventh International Conference on Learning Representations (
-
[7]
ICLR 2022 Workshop on PAIR
Post-hoc Concept Bottleneck Models , author=. ICLR 2022 Workshop on PAIR. 2022 , url=
2022
-
[8]
arXiv preprint arXiv:2106.13314 , year =
Mahinpei, Anita and Clark, Justin and Lage, Isaac and Doshi-Velez, Finale and Pan, Weiwei , title =. arXiv preprint arXiv:2106.13314 , year =
-
[9]
Advances in Neural Information Processing Systems , volume=
Concept Embedding Models: Beyond the accuracy-explainability trade-off , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
International Conference on Machine Learning , pages=
DCBM: Data-Efficient Visual Concept Bottleneck Models , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[11]
Transactions on Machine Learning Research , issn=
Oriane Sim. Transactions on Machine Learning Research , issn=. 2026 , url=
2026
-
[12]
European Conference on Computer Vision , pages=
Pdiscoformer: Relaxing part discovery constraints with vision transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[13]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Pdisconet: Semantically consistent part discovery for fine-grained recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[14]
Advances in neural information processing systems , volume=
Object-centric learning with slot attention , author=. Advances in neural information processing systems , volume=
-
[15]
arXiv preprint arXiv:2305.19550 , year =
Kakogeorgiou, Ioannis and Gidaris, Spyros and Karantzalos, Konstantinos and Komodakis, Nikos , title =. arXiv preprint arXiv:2305.19550 , year =
-
[16]
, title =
Chen, Chaofan and Li, Oscar and Tao, Daniel and Barnett, Alina and Rudin, Cynthia and Su, Jonathan K. , title =. Advances in Neural Information Processing Systems , volume =
-
[17]
Advances in Neural Information Processing Systems , volume =
Ma, Chiyu and Donnelly, Jon and Liu, Wenjun and Vosoughi, Soroush and Rudin, Cynthia and Chen, Chaofan , title =. Advances in Neural Information Processing Systems , volume =
-
[18]
and Lewis, Mike , title =
Press, Ofir and Smith, Noah A. and Lewis, Mike , title =. International Conference on Learning Representations (
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.