Geometry-Preserving Unsupervised Alignment for Heterogeneous Foundation Models
Pith reviewed 2026-06-28 06:53 UTC · model grok-4.3
The pith
An unsupervised orthogonal mapping aligns VFM features to VLM semantic space while preserving geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
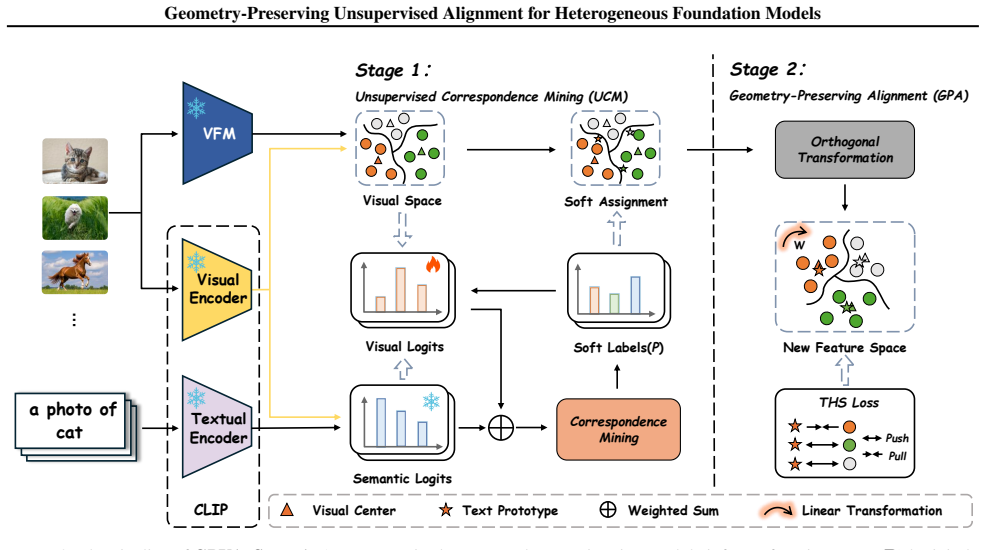
GPUA learns an orthogonal mapping that translates VFM features into the VLM semantic space by viewing the VFM space as a visual language. This mapping is unsupervised and preserves the original perceptual geometry, which narrows the modality gap between the two types of models and leads to gains in zero-shot recognition and segmentation.
What carries the argument
The orthogonal mapping learned to translate VFM features into VLM semantic space while preserving geometry.
If this is right
- Aligned features improve zero-shot recognition accuracy on diverse benchmarks.
- Segmentation performance rises by combining VFM geometry with VLM semantics.
- The method remains task-agnostic and adds negligible computational overhead.
- Only feature-level access to pretrained models is required, with no parameter updates.
Where Pith is reading between the lines
- The same orthogonal-mapping idea could apply to aligning foundation models across other modalities such as audio or text.
- Linear orthogonal transforms may prove sufficient for many cross-model alignments, reducing reliance on paired training data.
- If the linear assumption limits gains on complex tasks, testing non-linear variants would be a direct next step.
Load-bearing premise
An orthogonal linear mapping learned in an unsupervised manner is sufficient to align the two heterogeneous feature spaces while preserving the perceptual geometry learned by the VFM.
What would settle it
If the mapped VFM features produce no gain in zero-shot accuracy on standard benchmarks compared with the original VFM or VLM features alone, the central claim would not hold.
Figures

read the original abstract
Foundation models have driven rapid progress in computer vision, yet the two dominant paradigms, vision-language foundation models (VLMs) and vision-only foundation models (VFMs), remain only partially compatible. VLMs offer language-grounded semantic alignment but are often visually coarse, while VFMs learn discriminative perceptual geometry but lack semantic grounding. We propose GPUA (Geometry-Preserving Unsupervised Alignment), a framework that integrates the complementary strengths of VFMs and VLMs. Inspired by cross-lingual alignment, GPUA treats VFM features as a visual language and learns an orthogonal mapping that translates the VFM space into the VLM semantic space, preserving geometry and narrowing the modality gap without labels or model parameter updates. GPUA is task-agnostic and requires only feature-level access to pretrained models. Experiments across diverse benchmarks demonstrate improved cross-model compatibility and strong gains in downstream zero-shot recognition and segmentation with negligible overhead. Code is available at https://github.com/Yuteam14/GPUA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GPUA, a framework for unsupervised alignment of vision-only foundation models (VFMs) and vision-language models (VLMs). Treating VFM features as a 'visual language,' it learns an orthogonal linear mapping to translate VFM features into VLM semantic space while preserving geometry (inner products), narrowing the modality gap without labels, supervision, or model updates. The method is task-agnostic, requires only feature access, and is claimed to yield improved cross-model compatibility plus gains on zero-shot recognition and segmentation benchmarks.
Significance. If the central claim holds, GPUA would offer a lightweight, label-free bridge between the perceptual geometry of VFMs and the semantic grounding of VLMs, enabling better integration of heterogeneous foundation models with negligible overhead. The public code release is a strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that an orthogonal mapping 'preserves geometry' while aligning the spaces rests on the unstated assumption that VFM and VLM feature distributions differ at most by an orthogonal transformation plus isotropic noise. No derivation, objective function, or ablation is supplied to show that the chosen unsupervised procedure recovers a useful W when this assumption is violated by nonlinear distortions arising from visual-discrimination vs. image-text contrast objectives.
- [Abstract] Abstract: the geometry-preservation guarantee (W^T W = I) is presented as following directly from the orthogonal constraint, yet the manuscript supplies neither the explicit unsupervised loss nor any verification that the learned mapping satisfies the isometry condition on real VFM/VLM features.
minor comments (1)
- [Abstract] The abstract refers to 'diverse benchmarks' and 'strong gains' but provides neither the specific datasets nor any quantitative numbers, making the empirical support impossible to evaluate from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below by clarifying the content already present in the full manuscript while offering to improve the abstract for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that an orthogonal mapping 'preserves geometry' while aligning the spaces rests on the unstated assumption that VFM and VLM feature distributions differ at most by an orthogonal transformation plus isotropic noise. No derivation, objective function, or ablation is supplied to show that the chosen unsupervised procedure recovers a useful W when this assumption is violated by nonlinear distortions arising from visual-discrimination vs. image-text contrast objectives.
Authors: Section 3 of the manuscript derives the method from the orthogonal Procrustes problem used in cross-lingual alignment. The unsupervised objective explicitly minimizes a feature-matching term (e.g., cosine or Euclidean distance between mapped VFM and VLM features) subject to the orthogonality constraint, solved in closed form via SVD. This yields a useful W on real data even when the ideal linear-plus-isotropic-noise model is only approximate, as confirmed by consistent gains on zero-shot tasks. While a formal robustness proof for arbitrary nonlinear distortions is not provided, the empirical validation across heterogeneous model pairs serves as the primary evidence. We will revise the abstract to reference the loss for improved transparency. revision: partial
-
Referee: [Abstract] Abstract: the geometry-preservation guarantee (W^T W = I) is presented as following directly from the orthogonal constraint, yet the manuscript supplies neither the explicit unsupervised loss nor any verification that the learned mapping satisfies the isometry condition on real VFM/VLM features.
Authors: The guarantee holds by construction: the optimization solves the orthogonal Procrustes problem, whose SVD solution mathematically enforces W^T W = I at every step. The explicit loss (feature alignment plus orthogonality) appears in Equation (2) and Algorithm 1 of the method section. Verification on real features is implicit in the reported downstream improvements and can be made explicit by adding a table entry showing ||W^T W - I||_F ≈ 0. We agree the abstract would benefit from a one-sentence mention of the loss and will make this change. revision: partial
Circularity Check
No significant circularity; method is a proposed unsupervised procedure evaluated empirically
full rationale
The paper introduces GPUA as an explicit algorithmic framework that learns an orthogonal matrix to map VFM features into VLM space while enforcing W^T W = I to preserve inner products. This construction is stated up front as the design choice (inspired by cross-lingual alignment) rather than derived as a prediction from prior results. No equations or claims reduce the alignment outcome to a quantity fitted from the target data by definition, and the abstract supplies no self-citation load-bearing steps. Effectiveness is assessed via downstream zero-shot tasks on external benchmarks, keeping the central claim falsifiable outside the fitting procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An orthogonal mapping suffices to align VFM and VLM spaces while preserving geometry.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. Proceedings of the International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[2]
arXiv preprint arXiv:2304.07193 , year=
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
-
[3]
arXiv preprint arXiv:2508.10104 , year=
Dinov3 , author=. arXiv preprint arXiv:2508.10104 , year=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Maskclip: Masked self-distillation advances contrastive language-image pretraining , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
European Conference on Computer Vision , pages=
CLIP-DINOiser: Teaching CLIP a few DINO tricks for open-vocabulary semantic segmentation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[6]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Talking to dino: Bridging self-supervised vision backbones with language for open-vocabulary segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[7]
IEEE Access , volume=
Tuning-free universally-supervised semantic segmentation , author=. IEEE Access , volume=. 2024 , publisher=
2024
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Clip as rnn: Segment countless visual concepts without training endeavor , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Corrclip: Reconstructing patch correlations in clip for open-vocabulary semantic segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[10]
International Conference on Learning Representations , year=
Word translation without parallel data , author=. International Conference on Learning Representations , year=
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Black box few-shot adaptation for vision-language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Enhance vision-language alignment with noise , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dual memory networks: A versatile adaptation approach for vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Skyscript: A large and semantically diverse vision-language dataset for remote sensing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Remoteclip: A vision language foundation model for remote sensing , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2024 , publisher=
2024
-
[17]
Nature medicine , volume=
A visual-language foundation model for computational pathology , author=. Nature medicine , volume=. 2024 , publisher=
2024
-
[18]
European Conference on Computer Vision , pages=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[19]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
Transactions of the Association for Computational Linguistics , volume=
Learning multilingual word embeddings in latent metric space: a geometric approach , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[21]
arXiv preprint arXiv:2404.07983 , year=
Two effects, one trigger: On the modality gap, object bias, and information imbalance in contrastive vision-language representation learning , author=. arXiv preprint arXiv:2404.07983 , year=
-
[22]
arXiv preprint arXiv:1309.4168 , year=
Exploiting similarities among languages for machine translation , author=. arXiv preprint arXiv:1309.4168 , year=
-
[23]
The 22nd International Conference on Artificial Intelligence and Statistics , pages=
Unsupervised alignment of embeddings with wasserstein procrustes , author=. The 22nd International Conference on Artificial Intelligence and Statistics , pages=. 2019 , organization=
2019
-
[24]
Advances in Neural Information Processing Systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
European Conference on Computer Vision , pages=
Sclip: Rethinking self-attention for dense vision-language inference , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[26]
IEEE Transactions on Image Processing , year=
Self-calibrated clip for training-free open-vocabulary segmentation , author=. IEEE Transactions on Image Processing , year=
-
[27]
European Conference on Computer Vision , pages=
Proxyclip: Proxy attention improves clip for open-vocabulary segmentation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Advances in Neural Information Processing Systems , volume=
Frustratingly easy test-time adaptation of vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Efficient test-time adaptation of vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Label propagation for zero-shot classification with vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Realistic test-time adaptation of vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Dual prototype evolving for test-time generalization of vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
IEEE Transactions on Image Processing , year=
Task-to-instance prompt learning for vision-language models at test time , author=. IEEE Transactions on Image Processing , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
COSMIC: Clique-Oriented Semantic Multi-space Integration for Robust CLIP Test-Time Adaptation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
The pascal visual object classes challenge 2012 (voc2012) results (2012) , author=
2012
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
The role of context for object detection and semantic segmentation in the wild , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
International Journal of Computer Vision , volume=
Semantic understanding of scenes through the ade20k dataset , author=. International Journal of Computer Vision , volume=. 2019 , publisher=
2019
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Coco-stuff: Thing and stuff classes in context , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
The cityscapes dataset for semantic urban scene understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
SOTA: Self-adaptive Optimal Transport for Zero-Shot Classification with Multiple Foundation Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2009 , organization=
2009
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Sun database: Large-scale scene recognition from abbey to zoo , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2010 , organization=
2010
-
[45]
arXiv preprint arXiv:1306.5151 , year=
Fine-grained visual classification of aircraft , author=. arXiv preprint arXiv:1306.5151 , year=
-
[46]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[47]
Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
3d object representations for fine-grained categorization , author=. Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
-
[48]
European conference on computer vision , pages=
Food-101--mining discriminative components with random forests , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cats and dogs , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2012 , organization=
2012
-
[50]
2008 Sixth Indian conference on computer vision, graphics & image processing , pages=
Automated flower classification over a large number of classes , author=. 2008 Sixth Indian conference on computer vision, graphics & image processing , pages=. 2008 , organization=
2008
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop , pages=
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop , pages=. 2004 , organization=
2004
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Describing textures in the wild , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
arXiv preprint arXiv:1212.0402 , year=
Ucf101: A dataset of 101 human actions classes from videos in the wild , author=. arXiv preprint arXiv:1212.0402 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.