Bridge the Last-Mile Gap to Semantic Analytics: Compiling Natural-Language Queries into Semantic Operator Pipelines
Pith reviewed 2026-06-28 04:01 UTC · model grok-4.3
The pith
NL2Pipe compiles natural-language questions into executable semantic operator pipelines via three-phase compilation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
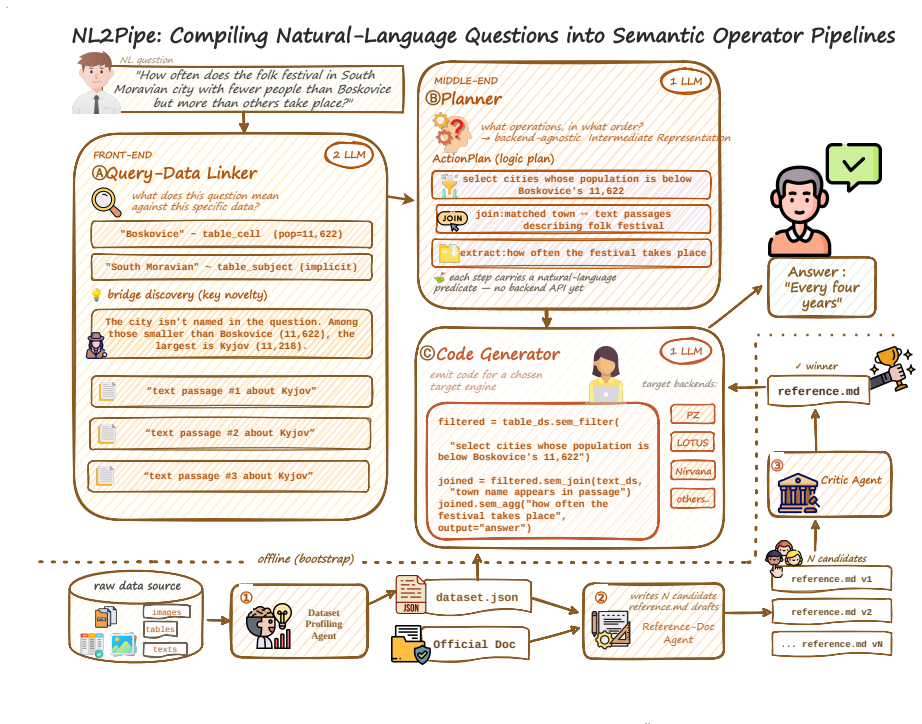
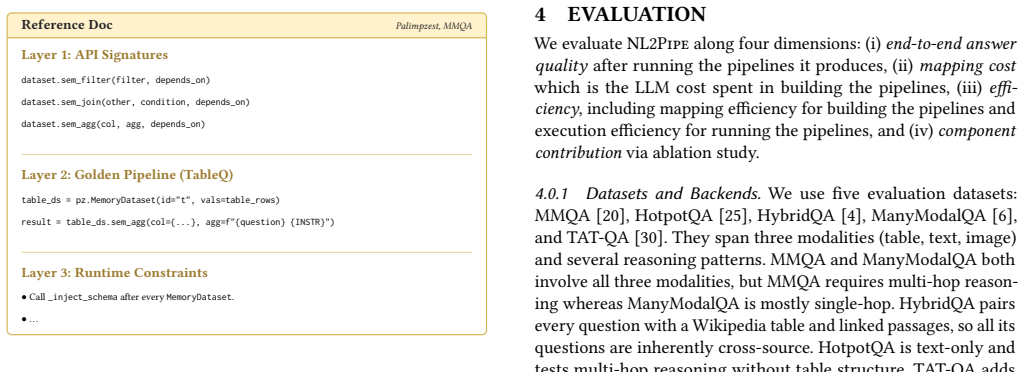
NL2Pipe treats the translation from natural language to semantic pipelines as a three-phase compilation: a Query-Data Linker grounds entities and finds implicit bridges across sources, a Semantic Planner builds a backend-agnostic sequence of operators with natural-language predicates, and a Code Generator produces executable code using an auto-generated backend reference document. This separation lets one planning process support multiple backends while handling heterogeneous data without manual intervention.
What carries the argument
The three-phase compiler consisting of Query-Data Linker, Semantic Planner, and Code Generator, where the linker grounds entities and discovers bridge entities to connect data sources.
If this is right
- Non-expert users and automated workflows can issue natural-language questions over heterogeneous data without manually designing pipelines.
- The same planning logic supports multiple semantic operator backends by isolating backend details to the code generation phase.
- Complex cross-source queries achieve higher accuracy than manual or baseline approaches while keeping cost bounded.
- Queries and data can vary at runtime because the compiler adapts the pipeline automatically rather than requiring static manual design.
Where Pith is reading between the lines
- The linker step may become the main bottleneck when data sources lack clear entity overlaps or when implicit bridges are ambiguous.
- Extending the planner to include cost or latency estimates during planning could further optimize the generated pipelines.
- The approach could apply to additional data modalities such as video or audio if the linker and operator set are expanded accordingly.
Load-bearing premise
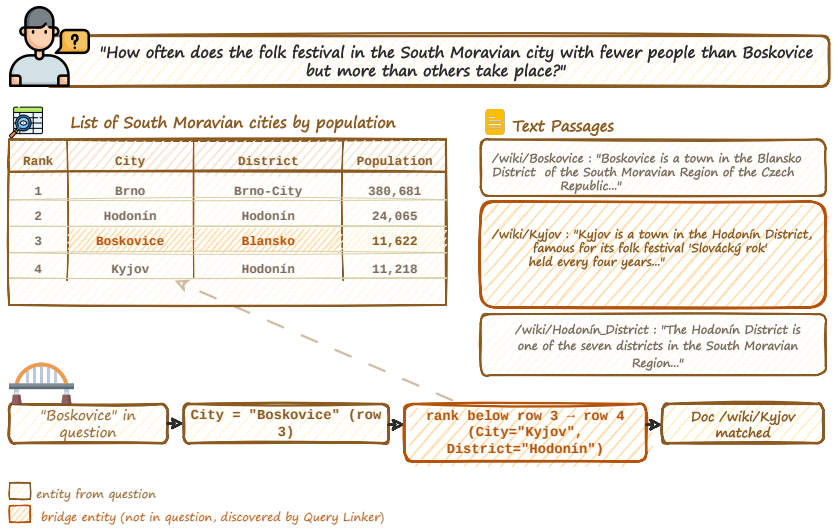
The Query-Data Linker can reliably ground question entities against heterogeneous data sources and discover implicit bridge entities that connect tables, text, and images without requiring backend-specific knowledge during planning.
What would settle it
A test set of natural-language questions over tables, text, and images where the linker fails to identify the required bridge entities, causing the planner to produce invalid or incomplete pipelines.
Figures
read the original abstract
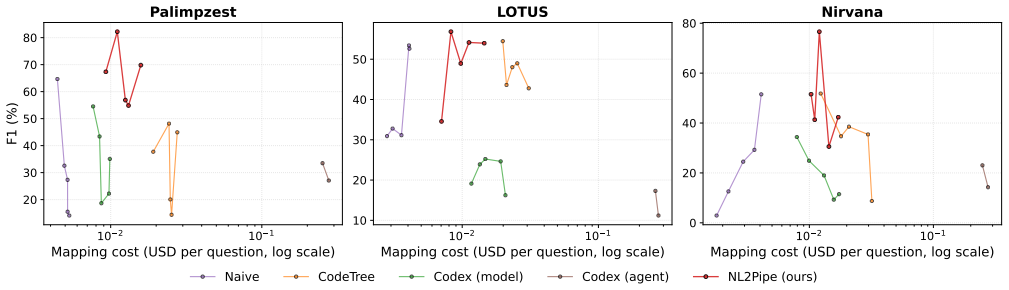
Automated AI workflows increasingly rely on natural-language reasoning over heterogeneous data, but lack a practical way to execute it through optimized semantic data systems. Recent semantic operator systems, such as Palimpzest and LOTUS, expose declarative operators for filtering, joining, mapping, and aggregating over tables, text, and images using natural-language predicates. However, these systems require users to manually choose operators, order them, write predicates, and adapt the pipeline to backend-specific APIs. This is difficult for non-experts, brittle across backends, and infeasible for automated workflows where queries and data vary at runtime. We present NL2Pipe, a middleware system that compiles natural-language questions into executable semantic operator pipelines, treating this as a three-phase compilation problem. First, a Query-Data Linker grounds question entities against the actual data and discovers implicit bridge entities needed to connect tables, text, and images. Second, a Semantic Planner produces a backend-agnostic action plan of semantic operators and natural-language predicates. Third, a Code Generator translates the plan into executable code for a target backend using an auto-generated reference document capturing operator signatures, example pipelines, and backend constraints. This separates data-aware reasoning from backend-specific code generation, letting the same planning logic support multiple backends. Evaluation shows NL2Pipe substantially outperforms baselines on complex cross-source workloads (e.g., up to 60% higher F1) while maintaining bounded cost and competitive latency. This demonstrates that automatic compilation from natural language to semantic operator pipelines is both practical and effective for bringing semantic analytics to non-expert users and automated AI workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NL2Pipe, a middleware system that compiles natural-language questions into executable semantic operator pipelines for heterogeneous data sources including tables, text, and images. The system is structured as a three-phase compilation process: (1) Query-Data Linker that grounds question entities and discovers implicit bridge entities, (2) Semantic Planner that generates a backend-agnostic action plan of semantic operators and predicates, and (3) Code Generator that translates the plan into backend-specific executable code using an auto-generated reference document. The evaluation claims that NL2Pipe substantially outperforms baselines on complex cross-source workloads, achieving up to 60% higher F1 scores while maintaining bounded cost and competitive latency.
Significance. If the results hold, this work would be significant in bridging the gap between natural language reasoning and optimized semantic data systems. By automating the selection and ordering of operators and adapting to different backends, it makes semantic analytics practical for non-experts and automated workflows, potentially increasing the adoption of systems like Palimpzest and LOTUS.
major comments (2)
- Abstract: The central performance claim of up to 60% higher F1 on complex cross-source workloads is presented without details on the specific workloads, baselines used, or error analysis. This prevents verification of whether the data supports the claim, particularly given that the Query-Data Linker is described as backend-agnostic but its reliability in grounding entities and discovering bridges is not independently evaluated.
- Abstract: The Query-Data Linker is identified as the first and critical phase, yet no mechanism, algorithm, or evaluation is provided for how it grounds entities against heterogeneous data sources or discovers implicit bridge entities without requiring backend-specific knowledge. This is load-bearing for attributing the F1 gains to the architecture rather than to the linker's success on the evaluated workloads.
minor comments (1)
- The abstract mentions 'bounded cost' but does not specify what cost metric is used or how it is bounded.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the two major points below. We agree that the abstract would benefit from additional context and will revise accordingly while pointing to the detailed descriptions already present in the body of the manuscript.
read point-by-point responses
-
Referee: [—] Abstract: The central performance claim of up to 60% higher F1 on complex cross-source workloads is presented without details on the specific workloads, baselines used, or error analysis. This prevents verification of whether the data supports the claim, particularly given that the Query-Data Linker is described as backend-agnostic but its reliability in grounding entities and discovering bridges is not independently evaluated.
Authors: The abstract is necessarily concise, but the full manuscript provides the requested details in Section 5. Workloads are the heterogeneous cross-source QA tasks (tables+text+images) defined in 5.1; baselines include direct LLM prompting, hand-crafted pipelines, and NL-to-pipeline systems in 5.2; F1 results and error analysis appear in 5.3–5.4. The linker is backend-agnostic because it operates solely on a unified schema and embeddings. We will revise the abstract to include a brief reference to the evaluation setup and add an isolated precision/recall evaluation of the linker. revision: yes
-
Referee: [—] Abstract: The Query-Data Linker is identified as the first and critical phase, yet no mechanism, algorithm, or evaluation is provided for how it grounds entities against heterogeneous data sources or discovers implicit bridge entities without requiring backend-specific knowledge. This is load-bearing for attributing the F1 gains to the architecture rather than to the linker's success on the evaluated workloads.
Authors: Section 3.1 of the manuscript describes the Query-Data Linker in detail: entity grounding uses embedding-based similarity against a backend-agnostic metadata index, while implicit bridge discovery employs LLM reasoning over candidate connections derived from the same index. No backend APIs are invoked. The end-to-end evaluation in Section 5 incorporates linker performance, but we agree a standalone ablation would strengthen attribution. We will add pseudocode for the algorithm and a dedicated linker-accuracy subsection in the revision. revision: yes
Circularity Check
No circularity: system design with external empirical evaluation
full rationale
The paper presents NL2Pipe as a three-phase middleware system (Query-Data Linker, Semantic Planner, Code Generator) for compiling NL queries to semantic operator pipelines. No equations, fitted parameters, or first-principles derivations appear; performance claims (up to 60% higher F1) rest on external benchmark comparisons rather than any reduction to self-defined inputs or self-citations. The Query-Data Linker is described as a component whose reliability is evaluated empirically, not derived by construction from the planner or generator. This is a standard systems paper whose central claims are falsifiable against independent workloads and baselines, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gonzalez, Carlos Guestrin, and Matei Zaharia
Asim Biswal, Liana Patel, Siddarth Jha, Amog Kamsetty, Shu Liu, Joseph E. Gonzalez, Carlos Guestrin, and Matei Zaharia. 2024. Text2SQL is Not Enough: Unifying AI and Databases with TAG.arXiv preprint arXiv:2408.14717(2024)
arXiv 2024
-
[2]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. 2023. Au- tonomous Chemical Research with Large Language Models.Nature624 (2023), 570–578
2023
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374(2021)
Pith/arXiv arXiv 2021
-
[4]
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. 2020. HybridQA: A Dataset of Multi-Hop Question Answer- ing over Tabular and Textual Data. InFindings of EMNLP
2020
-
[5]
Hanjun Dai, Bethany Yixin Wang, Xingchen Wan, Bo Dai, Sherry Yang, Azade Nova, Pengcheng Yin, Phitchaya Mangpo Phothilimthana, Charles Sutton, and Dale Schuurmans. 2024. UQE: A Query Engine for Unstructured Databases. arXiv:2407.09522 [cs.DB] https://arxiv.org/abs/2407.09522
arXiv 2024
-
[6]
Darryl Hannan, Akshay Jain, and Mohit Bansal. 2020. ManyModalQA: Modality Disambiguation and QA over Diverse Inputs. InAAAI
2020
-
[7]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al
-
[8]
MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. InICLR
-
[9]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6769–6781
2020
-
[10]
Vishwajeet Kumar, Yash Gupta, Saneem Chemmengath, Jaydeep Sen, Soumen Chakrabarti, Samarth Bharadwaj, and Feifei Pan. 2023. Multi-Row, Multi-Span Distant Supervision For Table+Text Question Answering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 8080– 8094
2023
-
[11]
Jiale Lao, Andreas Zimmerer, Olga Ovcharenko, Tianji Cong, Matthew Russo, Gerardo Vitagliano, Michael Cochez, Fatma Özcan, Gautam Gupta, Thibaud Hottelier, H. V. Jagadish, Kris Kissel, Sebastian Schelter, Andreas Kipf, and Im- manuel Trummer. 2025. SemBench: A Benchmark for Semantic Query Processing Engines.arXiv preprint arXiv:2511.01716(2025)
arXiv 2025
-
[12]
Jierui Li, Hung Le, Yingbo Zhou, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. 2025. CodeTree: Agent-guided Tree Search for Code Generation with Large Language Models. InNAACL
2025
-
[13]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. 2025. Palimpzest: Optimizing AI-Powered Analytics with Declarative Query Processing. InProc. CIDR
2025
-
[14]
Shicheng Liu, Jialiang Xu, Wesley Tjangnaka, Sina Semnani, Chen Yu, and Monica Lam. 2024. SUQL: Conversational Search over Structured and Unstructured Data with Large Language Models. InFindings of NAACL
2024
-
[15]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS.Proc. VLDB Endow.18, 11 (2025), 4171–4184
2025
-
[16]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. InNeurIPS
2023
-
[17]
Matthew Russo, Sivaprasad Sudhir, Gerardo Vitagliano, Chunwei Liu, Tim Kraska, Samuel Madden, and Michael Cafarella. 2026. Abacus: A Cost-Based Optimizer for Semantic Operator Systems.Proc. VLDB Endow.19, 5 (2026), 1060–1073
2026
-
[18]
Parameswaran, and Eugene Wu
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9
2025
-
[19]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2024. HuggingGPT: Solving AI Tasks with ChatGPT and Its Friends in Hugging Face. InNeurIPS
2024
-
[20]
Ji Sun, Guoliang Li, Peiyao Zhou, Yihui Ma, Jingzhe Xu, and Yuan Li. 2025. AgenticData: An Agentic Data Analytics System for Heterogeneous Data.arXiv preprint arXiv:2508.05002(2025)
arXiv 2025
-
[21]
Alon Talmor, Ori Yoran, Amnon Catav, Dan Lahav, Yizhong Wang, Akari Asai, Gabriel Ilharco, Hannaneh Hajishirzi, and Jonathan Berant. 2021. MultiModalQA: Complex Question Answering over Text, Tables, and Images. InICLR
2021
-
[22]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[23]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 10014–10037
-
[24]
Matthias Urban and Carsten Binnig. 2024. Demonstrating CAESURA: Language Models as Multi-Modal Query Planners. InCompanion of the 2024 International Conference on Management of Data (SIGMOD)
2024
-
[25]
Jiayi Wang and Jianhua Feng. 2025. Unify: An Unstructured Data Analytics System. InProc. ICDE
2025
-
[26]
Wenhan Xiong, Xiang Lorraine Li, Srinivasan Iyer, Jingfei Du, Patrick Lewis, William Yang Wang, Yashar Mehdad, Wen-tau Yih, Sebastian Riedel, Douwe Kiela, and Barlas Oğuz. 2021. Answering Complex Open-Domain Questions with Multi- Hop Dense Retrieval. InInternational Conference on Learning Representations (ICLR)
2021
-
[27]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering. InEMNLP
2018
-
[28]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InICLR
2023
-
[29]
Le Zhang, Yihong Wu, Fengran Mo, Jian-Yun Nie, and Aishwarya Agrawal
-
[30]
MoqaGPT: Zero-Shot Multi-modal Open-domain Question Answering with Large Language Model.arXiv preprint arXiv:2310.13265(2023)
arXiv 2023
-
[31]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InNeurIPS Datasets and Benchmarks Track
2023
-
[32]
Yongwei Zhou, Junwei Bao, Chaoqun Duan, Youzheng Wu, Xiaodong He, and Tiejun Zhao. 2022. UniRPG: Unified Discrete Reasoning over Table and Text as Program Generation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 7494–7507. https...
2022
-
[33]
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. TAT-QA: A Question An- swering Benchmark on a Hybrid of Tabular and Textual Content in Finance. In ACL
2021
-
[34]
Junhao Zhu, Lu Chen, Xiangyu Ke, Ziquan Fang, Tianyi Li, Yunjun Gao, and Christian S. Jensen. 2025. Beyond Relational: Semantic-Aware Multi-Modal Analytics with LLM-Native Query Optimization.arXiv preprint arXiv:2511.19830 (2025). 13
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.