EviRank: Evidence-Based Confidence Estimation for LLM-Based Ranking
Pith reviewed 2026-06-28 04:03 UTC · model grok-4.3
The pith
EviRank extracts three complementary evidences from one LLM forward pass, aggregates them with opinion aggregation, and applies position-aware calibration to produce reliable position-specific confidence for rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
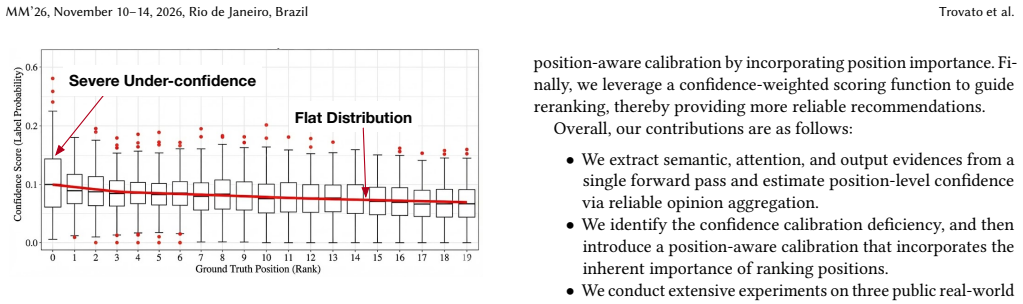
The central claim is that three complementary evidences can be pulled from a single forward pass, aggregated via reliable opinion aggregation, and refined by position-aware calibration to overcome both the global-score limitation and the uniform-low-value problem, thereby improving both recommendation quality and uncertainty quantification on ranking tasks.
What carries the argument
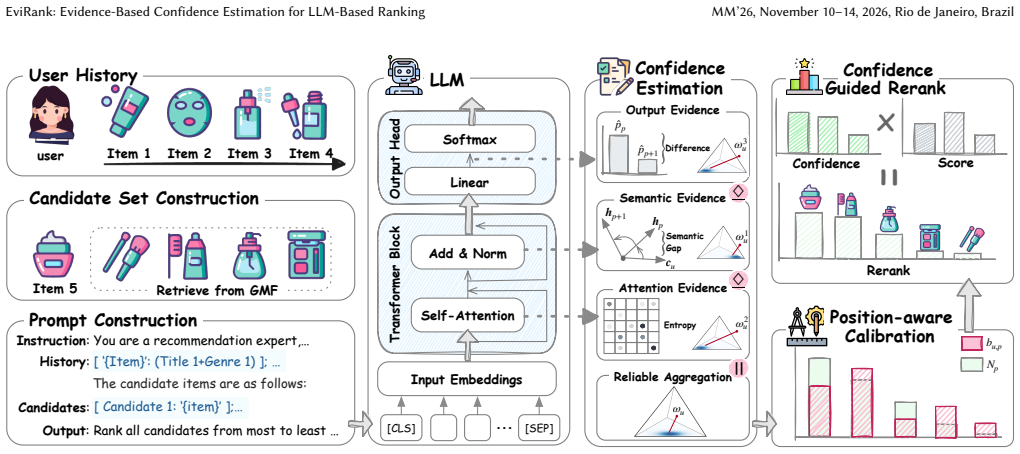
EviRank's evidence extraction and aggregation process, which pulls three complementary signals in one forward pass, combines them by reliable opinion aggregation, and corrects via position-aware calibration to yield usable per-position confidence scores.
If this is right
- Position-specific confidence scores identify unreliable spots inside a ranking list rather than returning only a single global value.
- The aggregated scores allow filtering or down-weighting of unreliable predictions before they affect users.
- Calibrated confidence directly guides the ranking optimization step to produce better lists.
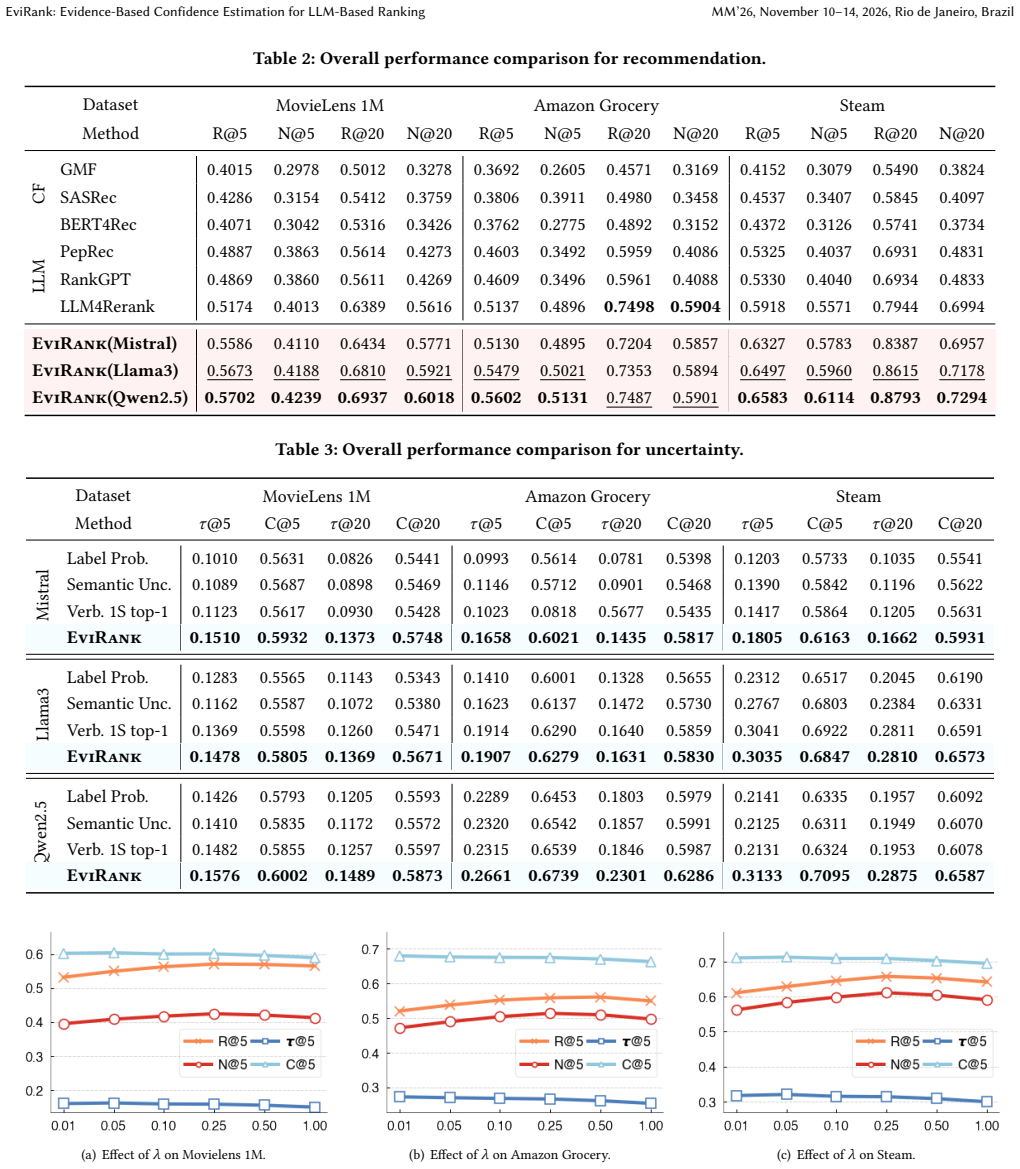
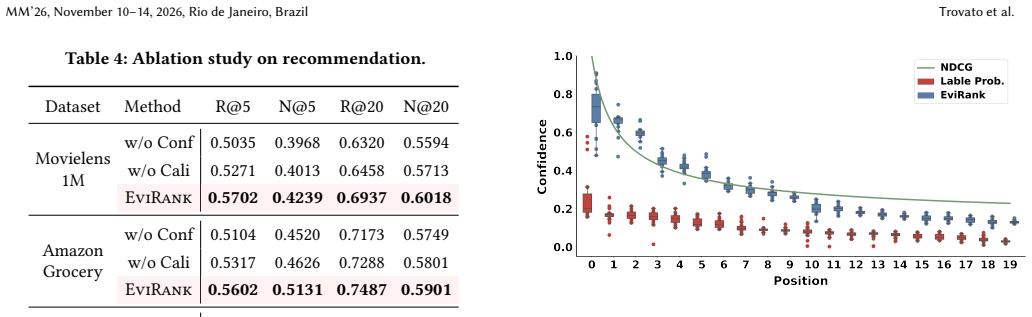
- The approach reaches state-of-the-art results on both recommendation and uncertainty quantification across the three evaluated datasets.
Where Pith is reading between the lines
- The single-pass evidence method could extend to other list-generation tasks where positional reliability matters, such as search result ordering.
- Position-aware calibration suggests that many ranking models carry systematic positional biases that can be corrected at inference time without retraining.
- If the aggregation proves stable, it may reduce the need for repeated sampling or multiple forward passes when estimating uncertainty in production recommenders.
Load-bearing premise
That three complementary evidences can be extracted from one forward pass and aggregated in a way that actually overcomes the global-score and uniform-low limitations while the position calibration adds value.
What would settle it
If side-by-side experiments on the three datasets show that EviRank produces no gains over baselines on recommendation accuracy or on uncertainty quantification metrics such as position-specific reliability, the central performance claim would be falsified.
Figures

read the original abstract
Large Language Models show promise for recommendation, but they raise reliability concerns due to limited domain coverage and inherent stochasticity. Existing uncertainty quantification methods persist two fundamental challenges: (1) the global confidence score designed for question answering fails to reveal which positions are unreliable in ranking list; (2) fine-grained confidence extracted from model internals exhibits uniformly low values across all positions, making it impossible to filter unreliable predictions. To tackle the challenges, we propose an evidence-based confidence estimation for LLM-based ranking (EviRank). We extract three complementary evidences from a single forward pass and aggregate them via reliable opinion aggregation. Furthermore, we recognize that ranking positions are inherently unequal, and introduce a position-aware calibration. Lastly, the calibrated confidence guides ranking optimization. Experiments on three datasets demonstrate that our method achieves state-of-the-art performance on both recommendation and uncertainty quantification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EviRank for evidence-based confidence estimation in LLM-based ranking. It extracts three complementary evidences from a single forward pass, aggregates them via reliable opinion aggregation, introduces position-aware calibration to address unequal ranking positions, and uses the calibrated confidence to guide ranking optimization. Experiments on three datasets are reported to achieve state-of-the-art performance on both recommendation and uncertainty quantification, addressing limitations of global confidence scores and uniformly low fine-grained confidences.
Significance. If the method and results hold, the work could meaningfully advance reliable LLM-based ranking by enabling position-specific uncertainty estimates without extra forward passes, with potential impact on recommendation systems and uncertainty quantification in generative models.
major comments (2)
- [Abstract] Abstract: the central claim of SOTA performance on recommendation and uncertainty quantification is asserted without any description of the three evidences, the aggregation procedure, the position-aware calibration formula, the datasets, baselines, or metrics, rendering it impossible to evaluate whether the experimental evidence supports the claim.
- [Abstract] Abstract: no equations, pseudocode, or method details are supplied for the evidence extraction, opinion aggregation, or calibration steps, preventing assessment of whether the approach avoids the uniform-low and global-score limitations it identifies or introduces circularity or fitted parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that it is currently too high-level and will revise it in the next version to include more details on the method components and experimental setup while maintaining conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of SOTA performance on recommendation and uncertainty quantification is asserted without any description of the three evidences, the aggregation procedure, the position-aware calibration formula, the datasets, baselines, or metrics, rendering it impossible to evaluate whether the experimental evidence supports the claim.
Authors: We agree that the abstract lacks these specifics. In the revised manuscript, we will expand the abstract to briefly describe the three complementary evidences extracted from a single forward pass, the reliable opinion aggregation procedure, the position-aware calibration, and to name the three datasets along with the key baselines and metrics supporting the SOTA claims on recommendation and uncertainty quantification. revision: yes
-
Referee: [Abstract] Abstract: no equations, pseudocode, or method details are supplied for the evidence extraction, opinion aggregation, or calibration steps, preventing assessment of whether the approach avoids the uniform-low and global-score limitations it identifies or introduces circularity or fitted parameters.
Authors: We acknowledge the absence of equations or pseudocode in the abstract, which is standard due to length limits. The full details, including how the approach uses position-aware calibration to avoid uniform-low and global-score issues without circularity or additional fitted parameters, are in Sections 3-4. We will revise the abstract to add a concise high-level description of these steps to better allow readers to assess the claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The supplied document contains only the abstract, which summarizes the EviRank approach at a conceptual level (extracting three evidences, opinion aggregation, position-aware calibration) without equations, formal definitions, or derivation steps. No load-bearing claims can be inspected for self-definitional reduction, fitted-input predictions, or self-citation chains, as required by the analysis rules. Absent any quotable technical content that reduces to its own inputs, the finding is no circularity (score 0). This outcome is expected when the paper text supplies no material for the circularity patterns to apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. 2024. Make your llm fully utilize the context.Advances in Neural Information Processing Systems37 (2024), 62160–62188
2024
-
[2]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM conference on recommender systems. 1007–1014
2023
-
[3]
Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to rank using gradient descent. InProceedings of the 22nd International Conference on Machine Learning(Bonn, Germany)(ICML ’05). Association for Computing Machinery, New York, NY, USA, 89–96. doi:10. 1145/1102351.1102363
arXiv 2005
-
[4]
Jingtong Gao, Bo Chen, Xiangyu Zhao, Weiwen Liu, Xiangyang Li, Yichao Wang, Wanyu Wang, Huifeng Guo, and Ruiming Tang. 2025. Llm4rerank: Llm-based auto-reranking framework for recommendations. InProceedings of the ACM on Web Conference 2025. 228–239
2025
-
[5]
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. 2023. Chat-rec: Towards interactive and explainable llms-augmented recommender system.arXiv preprint arXiv:2303.14524(2023)
arXiv 2023
-
[6]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
2022
-
[7]
Hamidreza Ghader and Christof Monz. 2017. What does Attention in Neural Machine Translation Pay Attention to?. InProceedings of the Eighth Interna- tional Joint Conference on Natural Language Processing (Volume 1: Long Papers), Greg Kondrak and Taro Watanabe (Eds.). Asian Federation of Natural Language Processing, Taipei, Taiwan, 30–39. https://aclantholo...
2017
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[9]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. InInternational conference on machine learning. PMLR, 1321–1330
2017
-
[10]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
2015
-
[11]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. InProceedings of the 26th international conference on world wide web. 173–182
2017
-
[12]
Zhankui He, Zhouhang Xie, Rahul Jha, Harald Steck, Dawen Liang, Yesu Feng, Bodhisattwa Prasad Majumder, Nathan Kallus, and Julian McAuley. 2023. Large language models as zero-shot conversational recommenders. InProceedings of the 32nd ACM international conference on information and knowledge management. 720–730
2023
-
[13]
Dan Hendrycks and Kevin Gimpel. 2017. A Baseline for Detecting Misclas- sified and Out-of-Distribution Examples in Neural Networks.Proceedings of International Conference on Learning Representations(2017)
2017
-
[14]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated gain-based evaluation of IR techniques.ACM Trans. Inf. Syst.20, 4 (Oct. 2002), 422–446. doi:10.1145/ 582415.582418
arXiv 2002
-
[15]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
Pith/arXiv arXiv 2023
-
[16]
2018.Subjective Logic: A formalism for reasoning under uncertainty
Audun Jsang. 2018.Subjective Logic: A formalism for reasoning under uncertainty. Springer Publishing Company, Incorporated
2018
-
[17]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[18]
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, and Chanyoung Park. 2024. Large language models meet collaborative filtering: An efficient all-round llm-based recommender system. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1395–1406
2024
-
[19]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. arXiv preprint arXiv:2302.09664(2023)
Pith/arXiv arXiv 2023
-
[20]
Wonbin Kweon, Sanghwan Jang, SeongKu Kang, and Hwanjo Yu. 2025. Uncer- tainty Quantification and Decomposition for LLM-based Recommendation. In Proceedings of the ACM on Web Conference 2025. 4889–4901
2025
-
[21]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al
-
[22]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
From generation to judgment: Opportunities and challenges of llm-as- a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2757–2791
2025
-
[23]
Mingming Li, Songlin Hu, Fuqing Zhu, and Qiannan Zhu. 2024. Few-shot learning for cold-start recommendation. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 7185–7195
2024
-
[24]
Xinyu Lin, Wenjie Wang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua
-
[25]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Bridging items and language: A transition paradigm for large language model-based recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1816–1826
-
[26]
Chen Ling, Xujiang Zhao, Wei Cheng, Yanchi Liu, Yiyou Sun, Xuchao Zhang, Mika Oishi, Takao Osaki, Katsushi Matsuda, Jie Ji, et al. 2024. Uncertainty de- composition and quantification for in-context learning of large language models. CoRR(2024)
2024
-
[27]
Varun Nathan, Ayush Kumar, and Digvijay Ingle. 2024. Can probing classifiers reveal the learning by contact center large language models?: No, it doesn’t!. InProceedings of the Fifth Workshop on Insights from Negative Results in NLP. 92–100
2024
-
[28]
Dina Nawara and Rasha Kashef. 2025. A comprehensive survey on LLM-powered recommender systems: from discriminative, generative to multi-modal paradigms. IEEE Access(2025)
2025
-
[29]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197
2019
-
[30]
John Platt et al. 1999. Probabilistic outputs for support vector machines and com- parisons to regularized likelihood methods.Advances in large margin classifiers 10, 3 (1999), 61–74
1999
-
[31]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[32]
InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09)
BPR: Bayesian personalized ranking from implicit feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09). AUAI Press, Arlington, Virginia, USA, 452–461
-
[33]
Aravind Sankar, Junting Wang, Adit Krishnan, and Hari Sundaram. 2021. Protocf: Prototypical collaborative filtering for few-shot recommendation. InProceedings of the 15th ACM Conference on Recommender Systems. 166–175
2021
-
[34]
Pranab Kumar Sen. 1968. Estimates of the Regression Coefficient Based on Kendall’s Tau.J. Amer. Statist. Assoc.63, 324 (1968), 1379–1389. http://www. jstor.org/stable/2285891
arXiv 1968
-
[35]
Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z Ren, and Anirudha Majumdar
-
[36]
Surveys(2025)
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.Comput. Surveys(2025)
2025
-
[37]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[38]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450. MM’26, November 10–14, 2026, Rio de Janeiro, Brazil Trovato et al
2026
-
[39]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT good at search? investigat- ing large language models as re-ranking agents.arXiv preprint arXiv:2304.09542 (2023)
arXiv 2023
-
[40]
Qwen Team et al. 2024. Qwen2 technical report.arXiv preprint arXiv:2407.10671 2, 3 (2024)
Pith/arXiv arXiv 2024
-
[41]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. 2023. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine- Tuned with Human Feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H...
-
[42]
Pencina, Ralph B
Hajime Uno, Tianxi Cai, Michael J. Pencina, Ralph B. D’Agostino, and L. J. Wei
-
[43]
On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data.Statistics in Medicine30, 10 (2011), 1105–
2011
-
[44]
arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/sim.4154 doi:10.1002/ sim.4154
-
[45]
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Li...
-
[46]
Yakun Yu, Shi-ang Qi, Baochun Li, and Di Niu. 2024. PepRec: Progressive enhance- ment of prompting for recommendation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 17941–17953
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.