Contrastive Learning and Correlation Clustering for Sequences of Network Telescope Data
Pith reviewed 2026-06-28 07:40 UTC · model grok-4.3
The pith
A transformer trained by contrastive learning on network flow sequences produces higher similarities for sequences from the same source and supports correlation clustering that matches scanner labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
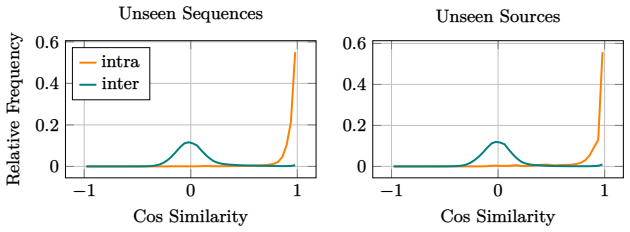
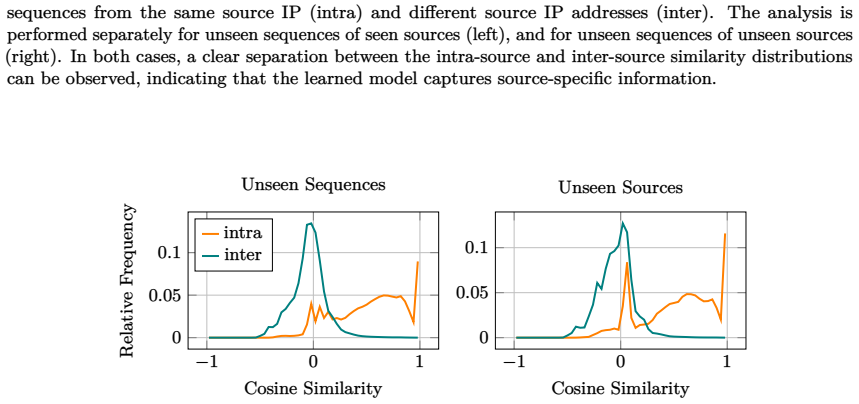
Learned similarities are higher on average for sequences originating from the same source than for sequences originating from different sources, and this property generalizes to unseen sequences of unseen sources. Moreover, correlation clustering yields clusters consistent with scanner labels.
What carries the argument
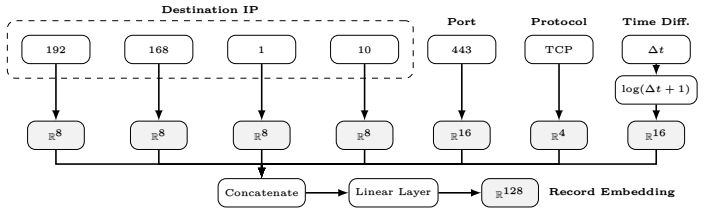
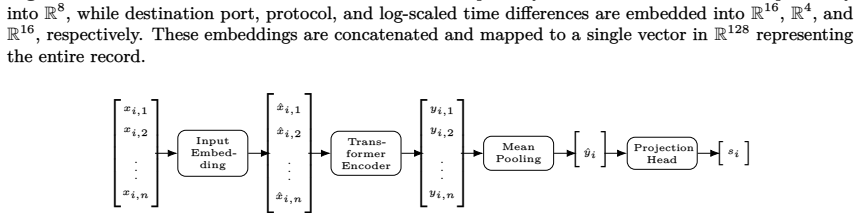
Transformer model that embeds minimally preprocessed sequences of network flow records and is trained with contrastive learning to produce pairwise similarities for subsequent correlation clustering.
If this is right
- The learned similarities can be used directly as input to correlation clustering without further supervision.
- The similarity property holds for sequences from sources absent from the training data.
- Clustering results remain consistent with external scanner labels even though no labels were used during training.
- The method operates on minimally preprocessed sequences and requires no pretraining step.
Where Pith is reading between the lines
- The same contrastive setup could be applied to other unlabeled sequence collections in network monitoring where source identity is known but semantic groupings are not.
- If the similarity signal is stable over time, the clusters could serve as a baseline for detecting changes in scanner behavior.
- Extending the input sequences to include additional flow attributes might tighten the clusters without changing the training procedure.
Load-bearing premise
The raw sequences contain enough inherent structure that contrastive pairs built only from source identity let the model recover semantically meaningful relationships.
What would settle it
On a held-out test set of sequences from sources never seen in training, the average similarity for same-source pairs is not higher than for different-source pairs, or the correlation clusters do not align with the scanner labels.
Figures
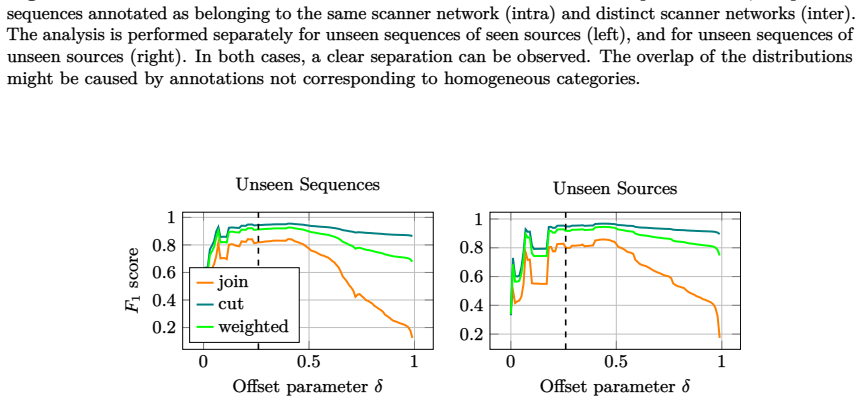
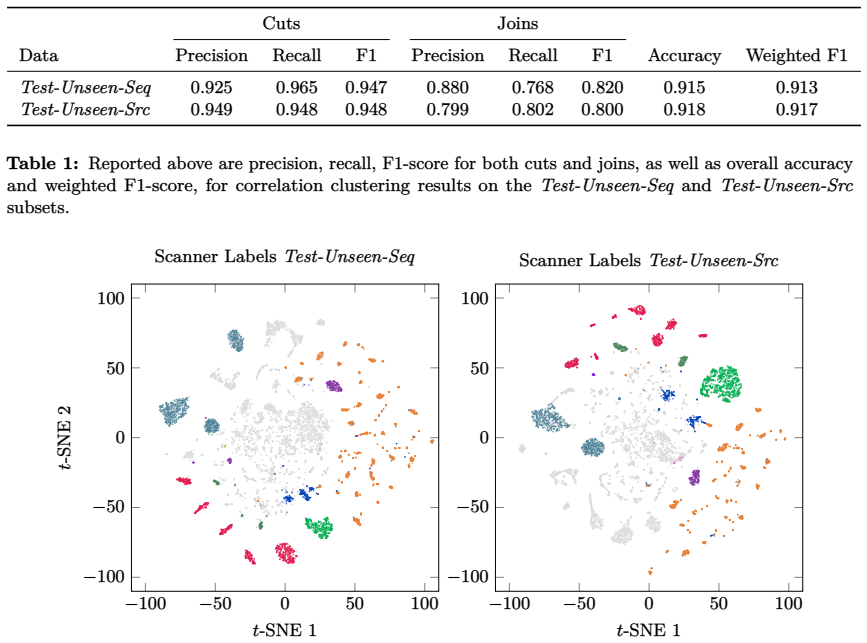
read the original abstract
Understanding activities of Internet scanners is challenging; it often requires identifying relationships between sources, a task for which semantic annotations are scarce. This work investigates whether semantically meaningful pairwise relationships between sequences of network flow records can be estimated by contrastive learning, without pretraining and without annotations. To this end, we propose a transformer model that embeds minimally preprocessed sequences of network flow records and train it using contrastive learning. With the similarities obtained from this model, we state a correlation clustering problem and solve it locally. Experimentally, we show: Learned similarities are higher on average for sequences originating from the same source than for sequences originating from different sources, and this property generalizes to unseen sequences of unseen sources. Moreover, correlation clustering yields clusters consistent with scanner labels. The complete source code of the algorithms and for reproducing the experiments is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a transformer-based model trained via contrastive learning on minimally preprocessed sequences of network flow records from network telescopes. Positive pairs are formed from sequences sharing the same source identity (without annotations or pretraining). The resulting similarities are used to formulate a correlation clustering problem that is solved locally. Experiments claim that learned similarities are higher for same-source pairs than different-source pairs, that this property generalizes to unseen sequences from unseen sources, and that the resulting clusters align with scanner labels. Complete source code is provided for reproduction.
Significance. If the generalization and clustering claims hold, the work offers a practical unsupervised method for discovering behavioral relationships among Internet scanners in a domain where semantic labels are scarce. The direct application of contrastive learning to raw telescope sequences and the public code release are strengths that support reproducibility and potential follow-on use.
minor comments (3)
- [§3] §3 (model and training): specify the exact construction of positive/negative pairs, batch size, temperature, and any data augmentation applied to sequences, as these choices directly affect whether the learned metric captures source semantics or artifacts.
- [§5] §5 (experiments): report the number of sources, total sequences, and the precise train/test split protocol used to demonstrate generalization to unseen sources; without these numbers the strength of the generalization claim is difficult to assess.
- [§4] §4 (clustering): clarify the precise objective function of the correlation clustering problem and the local solver employed, including any hyperparameters and how consistency with labels is quantified (e.g., adjusted Rand index or similar).
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its significance for unsupervised discovery of scanner relationships, and recommendation of minor revision. We appreciate the emphasis placed on reproducibility via the public code release.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper applies standard contrastive learning (positives defined by source identity) to embed network sequences and then solves a correlation clustering problem on the resulting similarities. The central claims concern generalization to unseen sequences of unseen sources and consistency of clusters with external scanner labels; these are empirical statements evaluated on held-out data rather than identities or fitted parameters renamed as predictions. No equation or step reduces the reported generalization or clustering result to the training construction by definition. The approach is verifiable via released code and does not rely on self-citation chains or imported uniqueness theorems for its load-bearing steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL: https://github.com/JannikPresberger/Contrastive Learning and Correlation Clustering for Sequences of Network Telescope Data
-
[2]
URL: https://www.caida.org/about/legal/aua/
-
[3]
URL: https://www.caida.org/catalog/datasets/request user info forms/telescope dataset request/
-
[4]
M. Antonakakis, T. April, M. Bailey, M. Bernhard, E. Bursztein, J. Cochran, Z. Durumeric, J. A. Halderman, L. Invernizzi, M. Kallitsis, D. Kumar, C. Lever, Z. Ma, J. Mason, D. Menscher, C. Seaman, N. Sullivan, K. Thomas, and Y. Zhou. Understanding the Mirai Botnet. In26th USENIX Security Symposium (USENIX), 2017. doi:10.5555/3241189.3241275
-
[5]
E. Balkanli, J. Alves, and A. N. Zincir-Heywood. Supervised Learning to detect DDoS Attacks. InSymposium on Computational Intelligence in Cyber Security (CICS), 2014. doi:10.1109/CICYBS.2014.7013367
-
[6]
E. Balkanli, N. Zincir-Heywood, and M. I. Heywood. Feature Selection for Robust Backscatter DDoS Detection. In40th Local Computer Networks Conference Workshops (LCNW), 2015. doi:10.1109/LCNW.2015.7365905
-
[7]
Sustainable Tools for Analysis and Research on Darknet Unsolicited Traffic, 2021
CAIDA. Sustainable Tools for Analysis and Research on Darknet Unsolicited Traffic, 2021. URL: https://www.caida.org/projects/stardust/
2021
-
[8]
R. J. G. B. Campello, D. Moulavi, A. Zimek, and J. Sander. Hierarchical density estimates for data clustering, visualization, and outlier detection.ACM Trans. Knowl. Discov. Data, 10(1), 2015. doi:10.1145/2733381
-
[9]
Censys Plattform
Censys. Censys Plattform. Website, 2017. URL: https://platform.censys.io/
2017
-
[10]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. InICML, 2020. URL: https://proceedings.mlr.press/v119/ chen20j/chen20j.pdf
2020
-
[11]
Chopra and M
S. Chopra and M. R. Rao. The partition problem.Mathematical Programming, 59(1):87–115,
-
[12]
doi:10.1007/BF01581239
-
[13]
Chowdhury, F
S. Chowdhury, F. Zhang, S. Zhang, H. Medal, M. Marufuzzaman, and L. Bian. Botnet detection using graph-based feature clustering.Journal of Big Data, 4:14, 2017. doi:10.1186/ s40537-017-0074-7
2017
-
[14]
D. Cohen, Y. Mirsky, M. Kamp, T. Martin, Y. Elovici, R. Puzis, and A. Shabtai. Dante: A framework for mining and monitoring darknet traffic. In25th European Symposium on Research in Computer Security (ESORICS), 2020. doi:10.1007/978-3-030-58951-6 5
-
[15]
M. Collins. Acknowledged Scanners, 2021. URL: https://gitlab.com/mcollins at isi/ acknowledged scanners.git
2021
-
[16]
A. Dainotti, A. King, K. Claffy, F. Papale, and A. Pescape. Analysis of a “/0” Stealth Scan From a Botnet.IEEE/ACM Transactions on Networking, 23(2):341–354, 2015. doi: 10.1109/tnet.2013.2297678
-
[17]
A. Dainotti, C. Squarcella, E. Aben, K. C. Claffy, M. Chiesa, M. Russo, and A. Pescap´ e. Analysis of Country-Wide Internet Outages Caused by Censorship.IEEE/ACM Transactions on Networking, 22(6):1964–1977, 2014. doi:10.1109/TNET.2013.2291244
-
[18]
J. A. Delgado-Soto, J. E. L´ opez de Vergara, I. Gonz´ alez, D. Perdices, and L. de Pedro. GPT on the wire: Towards realistic network traffic conversations generated with large language models.Comput. Netw., 265(C), 2025. doi:10.1016/j.comnet.2025.111308. 10
-
[19]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics,
2019
-
[20]
doi:10.18653/v1/N19-1423
-
[21]
L. Gioacchini, M. Mellia, L. Vassio, I. Drago, G. Milan, Z. B. Houidi, and D. Rossi. Cross- network embeddings transfer for traffic analysis.IEEE Transactions on Network and Service Management, 21(3):2686–2699, 2024. doi:10.1109/TNSM.2023.3329442
-
[22]
L. Gioacchini, L. Vassio, M. Mellia, I. Drago, Z. B. Houidi, and D. Rossi. Darkvec: automatic analysis of darknet traffic with word embeddings. InInternational Conference on Emerging Networking EXperiments and Technologies (CoNEXT), 2021. doi:10.1145/3485983.3494863
-
[23]
Gioacchini, L
L. Gioacchini, L. Vassio, M. Mellia, I. Drago, Z. B. Houidi, and D. Rossi. i-DarkVec: Incremental Embeddings for Darknet Traffic Analysis.ACM Trans. Internet Technol., 23(3),
-
[24]
R. Harang and P. Mell. Evasion-resistant network scan detection.Security Informatics, 4(4):1–10, 2015. doi:10.1186/s13388-015-0019-7
-
[25]
R. Hiesgen, M. Nawrocki, M. Barcellos, D. Kopp, O. Hohlfeld, E. Chan, R. Dobbins, C. Doerr, C. Rossow, D. R. Thomas, M. Jonker, R. Mok, X. Luo, J. Kristoff, T. C. Schmidt, M. W¨ ahlisch, and K. Claffy. The Age of DDoScovery: An Empirical Comparison of Industry and Academic DDoS Assessments. InInternet Measurement Conference (IMC), 2024. doi:10.1145/364654...
-
[26]
Strong supermartingales and limits of nonnegative martingales
K. Huang, L. Gioacchini, M. Mellia, and L. Vassio. Dynamic cluster analysis to detect and track novelty in network telescopes. InEuropean Symposium on Security and Privacy Workshops (EuroS & PW), 2024. doi:10.1109/EuroSPW61312.2024.00037
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/eurospw61312.2024.00037 2024
-
[27]
M. Jonker, A. King, J. Krupp, C. Rossow, A. Sperotto, and A. Dainotti. Millions of Targets under Attack: A Macroscopic Characterization of the DoS Ecosystem. InInternet Measurement Conference (IMC), 2017. doi:10.1145/3131365.3131383
-
[28]
J. Jung, V. Paxson, A. Berger, and H. Balakrishnan. Fast portscan detection using sequential hypothesis testing. InIEEE Symposium on Security and Privacy, 2004. doi:10.1109/SECPRI. 2004.1301325
-
[29]
M. Kallitsis, R. Prajapati, V. Honavar, D. Wu, and J. Yen. Detecting and Interpreting Changes in Scanning Behavior in Large Network Telescopes.IEEE Transactions on Information Forensics and Security, 17:3611–3625, 2022. doi:10.1109/tifs.2022.3211644
-
[30]
M. Keuper, E. Levinkov, N. Bonneel, G. Lavou´ e, T. Brox, and B. Andres. Efficient decomposi- tion of image and mesh graphs by lifted multicuts. InICCV, 2015. doi:10.1109/ICCV.2015.204
-
[31]
Koukoulis, I
I. Koukoulis, I. Syrigos, and T. Korakis. Self-supervised transformer-based contrastive learning for intrusion detection systems. InProceedings of the IFIP Networking 2025 Conference, Limassol, Cyprus, 2025. IFIP. URL: https://networking.ifip.org/2025/images/Net25 papers/ 1571127827.pdf
2025
-
[32]
Z. Li, S. Li, D. Fang, X. Chen, Z. Song, Z. Li, S. Lv, and L. Sun. PNetGPT: Proprietary Protocol Network Traffic Generation with Pre-trained Transformer. InInternational Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025. doi:10.1109/ICASSP49660.2025. 10890383. 11
-
[33]
A. M¨ annel, J. M¨ ucke, kc Claffy, M. Gao, R. K. P. Mok, M. Nawrocki, T. C. Schmidt, and M. W¨ ahlisch. Lessons Learned from Operating a Large Network Telescope. InProc. of ACM Special Interest Group on Data Communication (SIGCOMM), pages 826–841, New York, NY, USA, 2025. ACM. doi:10.1145/3718958.3754347
-
[34]
L. D. Manocchio, S. Layeghy, W. W. Lo, G. K. Kulatilleke, M. Sarhan, and M. Portmann. FlowTransformer: A transformer framework for flow-based network intrusion detection systems. Expert Syst. Appl., 241(C), 2024. doi:10.1016/j.eswa.2023.122564
-
[35]
P. Mell and R. Harang. Limitations to threshold random walk scan detection and mitigating enhancements. InConference on Communications and Network Security (CNS), 2013. doi: 10.1109/CNS.2013.6682723
-
[36]
X. Meng, C. Lin, Y. Wang, and Y. Zhang. NetGPT: Generative Pretrained Transformer for Network Traffic, 2025. URL: https://arxiv.org/abs/2304.09513, arXiv:2304.09513
arXiv 2025
-
[37]
Mikolov, I
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. InNeurIPS, 2013. URL: https://proceedings. neurips.cc/paper files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
2013
-
[38]
D. Moore, V. Paxson, S. Savage, C. Shannon, S. Staniford-Chen, and N. Weaver. Inside the Slammer Worm.IEEE Security & Privacy, 1(4):33–39, 2003. doi:10.1109/msecp.2003.1219056
-
[39]
Moore, G
D. Moore, G. M. Voelker, and S. Savage. Inferring Internet Denial-of-Service Activity. In USENIX Security Symposium, 2001
2001
-
[40]
M¨ ucke, M
J. M¨ ucke, M. Nawrocki, R. Hiesgen, P. Sattler, J. Zirngibl, G. Carle, J. Luxemburk, T. C. Schmidt, and M. W¨ ahlisch. Waiting for QUIC: Passive Measurements to Understand QUIC Deployments.Proceedings of the ACM on Networking (PACMNET), 3(CoNEXT4):41:1–41:26,
-
[41]
URL: https://doi.org/10.1145/3768988
-
[42]
G. Noblet, C. Lefebvre, P. Owezarski, and W. Ritchie. NetGlyph: Representation Learning to generate Network Traffic with Transformers. InInternational Conference on Network and Service Management (CNSM), 2024. doi:10.23919/CNSM62983.2024.10814626
-
[43]
Padmanabhan, A
R. Padmanabhan, A. Filast` o, M. Xynou, R. S. Raman, K. Middleton, M. Zhang, D. Madory, M. Roberts, and A. Dainotti. A Multi-Perspective View of Internet Censorship in Myanmar. InACM SIGCOMM Workshop on Free and Open Communications on the Internet (FOCI),
-
[44]
doi:10.1145/3473604.3474562
-
[45]
M. S. Pour, J. Khoury, and E. Bou-Harb. HoneyComb: A Darknet-Centric Proactive Deception Technique For Curating IoT Malware Forensic Artifacts. InIEEE/IFIP Network Operations and Management Symposium (NOMS), 2022. doi:10.1109/noms54207.2022.9789827
-
[46]
M. Ring, A. Dallmann, D. Landes, and A. Hotho. IP2Vec: Learning Similarities Between IP Addresses. InInternational Conference on Data Mining Workshops (ICDMW), 2017. doi:10.1109/ICDMW.2017.93
-
[47]
Shodan - the world’s first search engine for Internet-connected devices
Shodan. Shodan - the world’s first search engine for Internet-connected devices. Website. URL: https://www.shodan.io/
-
[48]
R. Sommese, K. Claffy, R. van Rijswijk-Deij, A. Chattopadhyay, A. Dainotti, A. Sperotto, and M. Jonker. Investigating the Impact of DDoS Attacks on DNS Infrastructure. InInternet Measurement Conference (IMC), 2022. doi:10.1145/3517745.3561458
-
[49]
van der Maaten and G
L. van der Maaten and G. Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008. URL: http://jmlr.org/papers/v9/vandermaaten08a.html. 12
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.