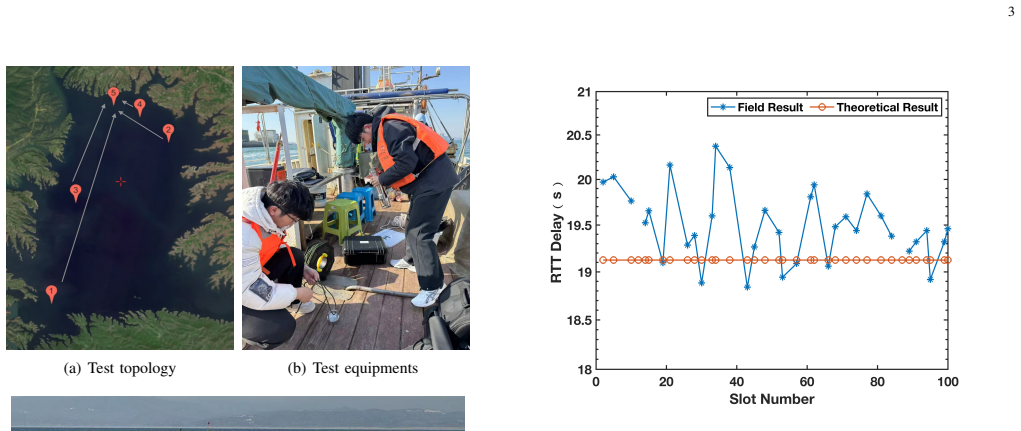
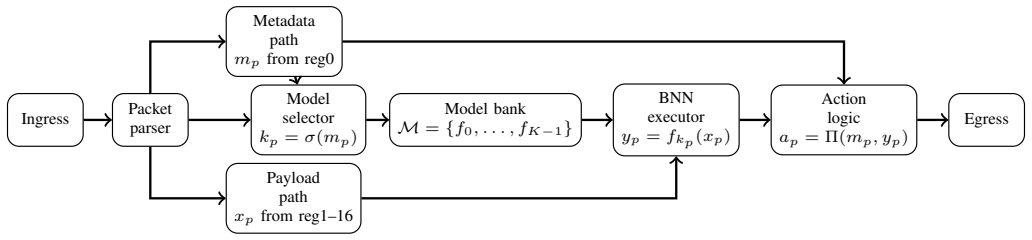
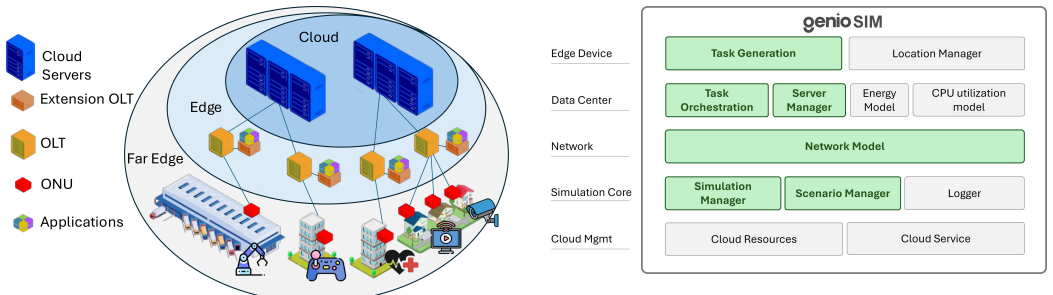
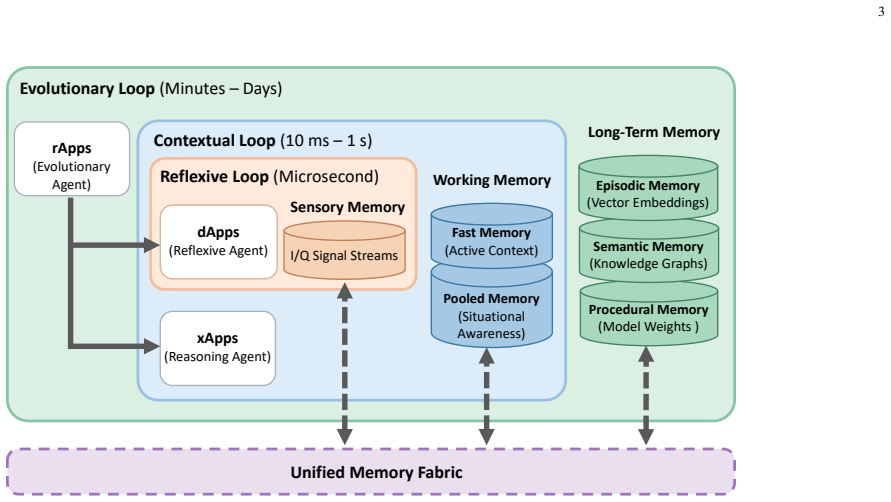
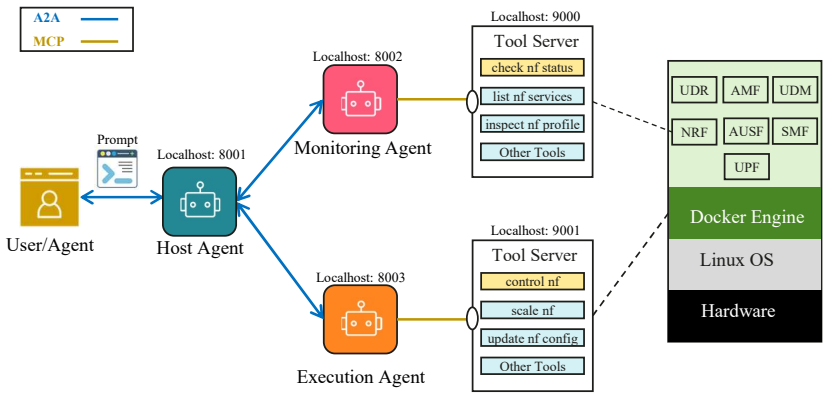
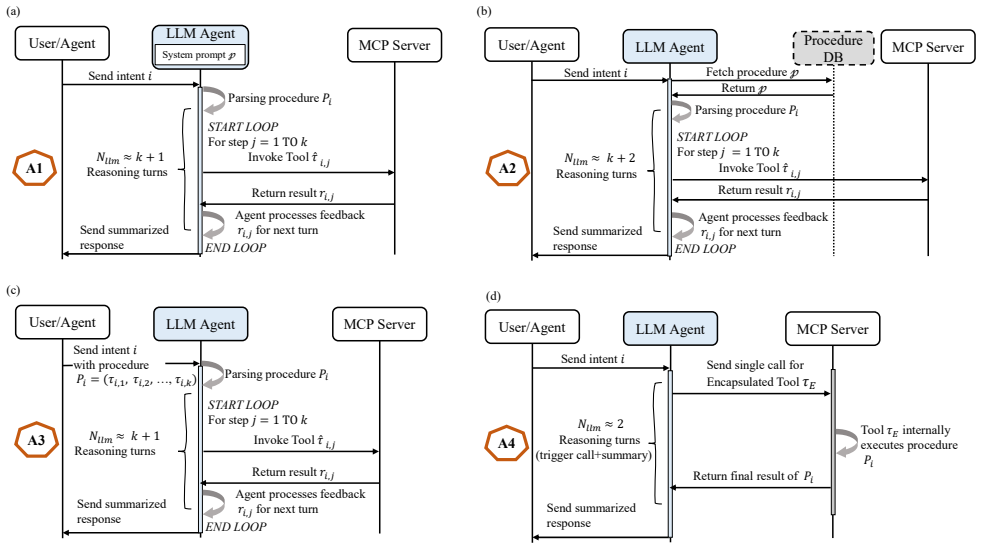
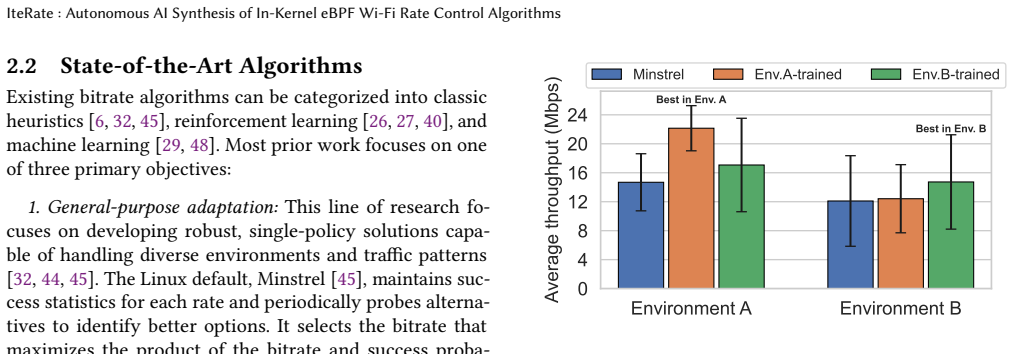
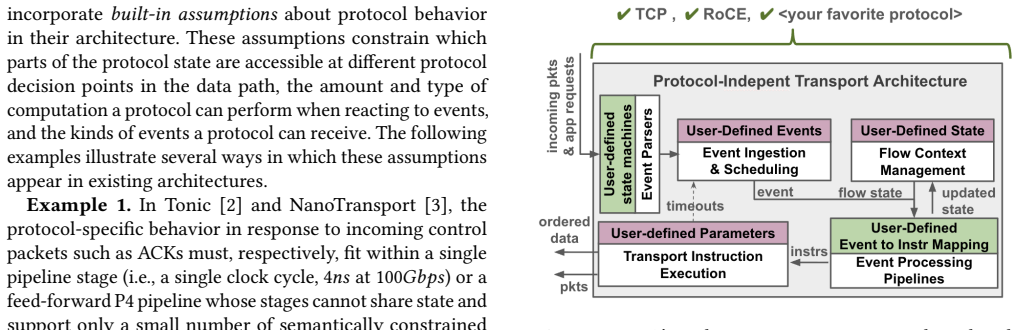
0
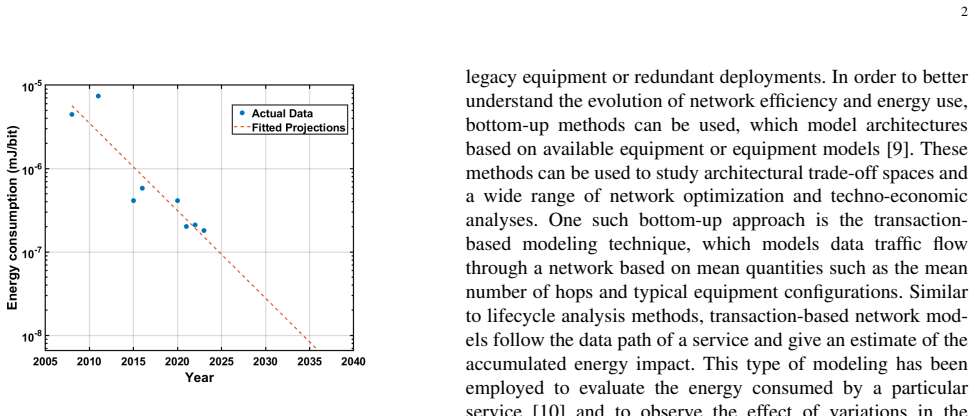
Processing energy dominates RAN consumption
Energy Consumption in Next Generation Radio Access Networks
Baseband processing location strongly affects efficiency in next-generation mobile networks.
 full image
full image
abstract click to expand
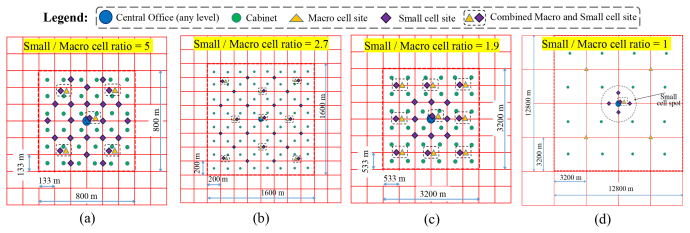
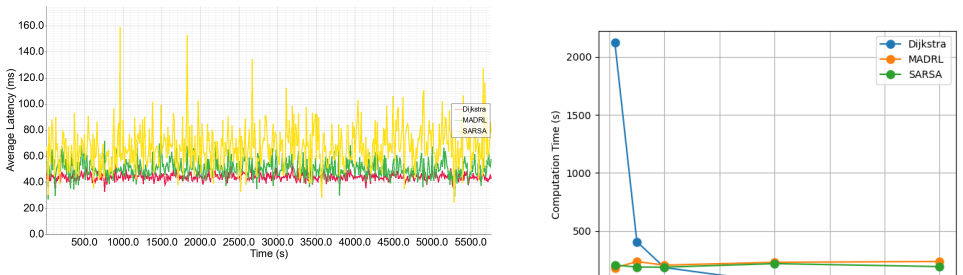
The radio access network (RAN) accounts for the largest share of energy consumption in mobile networks, making it essential to understand how and where this energy is used, particularly as future networks move toward higher levels of densification. Open radio access networks (O-RAN) have emerged as a promising approach to support this evolution through open interfaces that enable a multivendor environment, support for hierarchical intelligent controls, and simplified, cost-effective radio units that facilitate large-scale deployments. This paper examines the energy consumption in next-generation RAN architectures through transaction-based energy models. The model captures both processing and transmission energy components and evaluates how energy use varies with the placement of baseband processing (BBP) across network nodes and with different levels of network densification. Results indicate that processing energy dominates total consumption and that the location of BBP strongly influences overall energy efficiency. These insights can inform the design of future RAN deployments that balance flexibility, cost, and sustainability.