Crafting Your Evolving Dreams: Concept-Incremental Versatile Customization
Pith reviewed 2026-06-28 06:41 UTC · model grok-4.3
The pith
A diffusion model can incrementally learn new personalized concepts without forgetting earlier ones or neglecting details in multi-concept images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
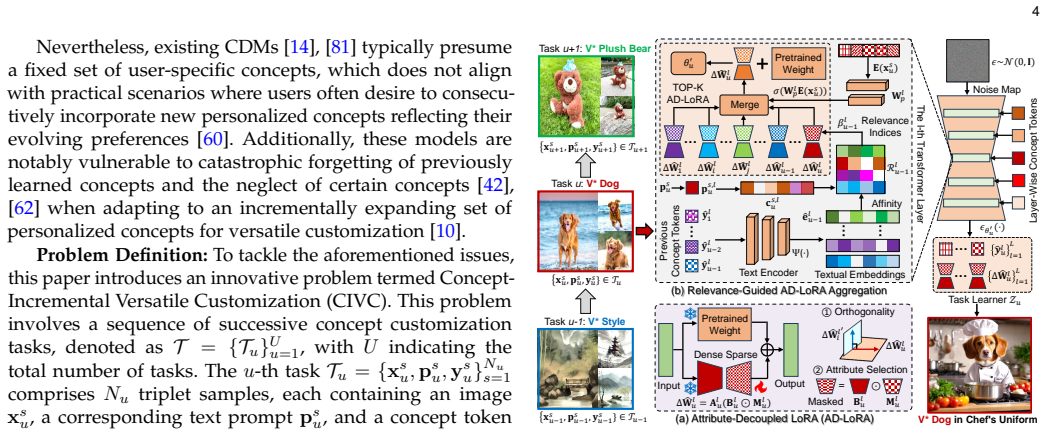
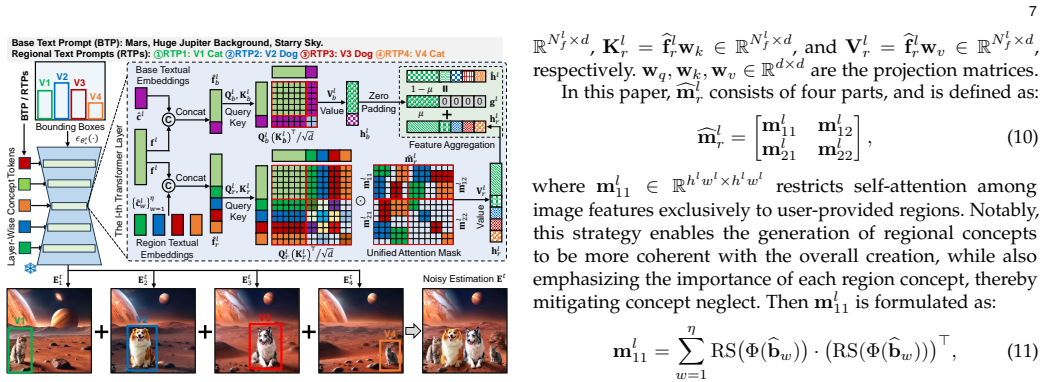
The central claim is that an attribute-decoupled LoRA module together with relevance-guided aggregation preserves concept-specific attributes of each incremental task while exploiting beneficial inter-task correlations, and that a controllable regional context synthesis strategy produces multi-concept images with semantic independence between user-defined regions and smooth boundary transitions, thereby solving both catastrophic forgetting and concept neglect in continual customization of diffusion models.
What carries the argument
Attribute-decoupled LoRA (AD-LoRA) module, which separates concept attributes so that each task's unique features remain isolated while still permitting controlled aggregation across tasks.
If this is right
- New customization tasks can be added without requiring full retraining or post-hoc fixes that degrade prior performance.
- Multi-concept images maintain region-specific semantics and avoid attribute mixing at boundaries.
- Inter-task relevance can be used to improve learning speed or quality of later tasks without harming earlier ones.
- The model supports versatile user conditions for region placement during composition.
Where Pith is reading between the lines
- The same modular separation of attributes could be tested on other parameter-efficient fine-tuning methods beyond LoRA.
- If the approach scales, personal image generators might support lifelong user collections measured in dozens of concepts rather than a handful.
- The regional synthesis component might generalize to video or 3D generation where temporal or spatial independence is also required.
Load-bearing premise
Decoupling attributes inside the LoRA updates will keep each concept's identity intact even when later tasks are learned and their parameters are aggregated.
What would settle it
Train CCDM sequentially on five unrelated concepts, then measure whether images of the first concept retain the same identity, detail fidelity, and prompt adherence as the single-task baseline.
Figures












read the original abstract
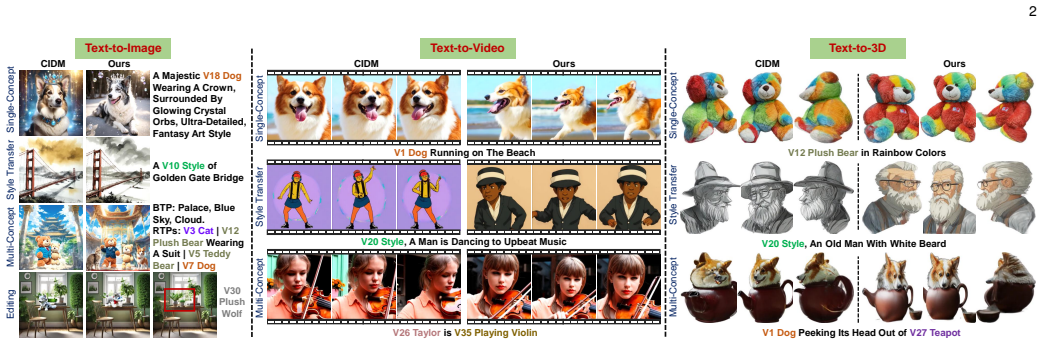
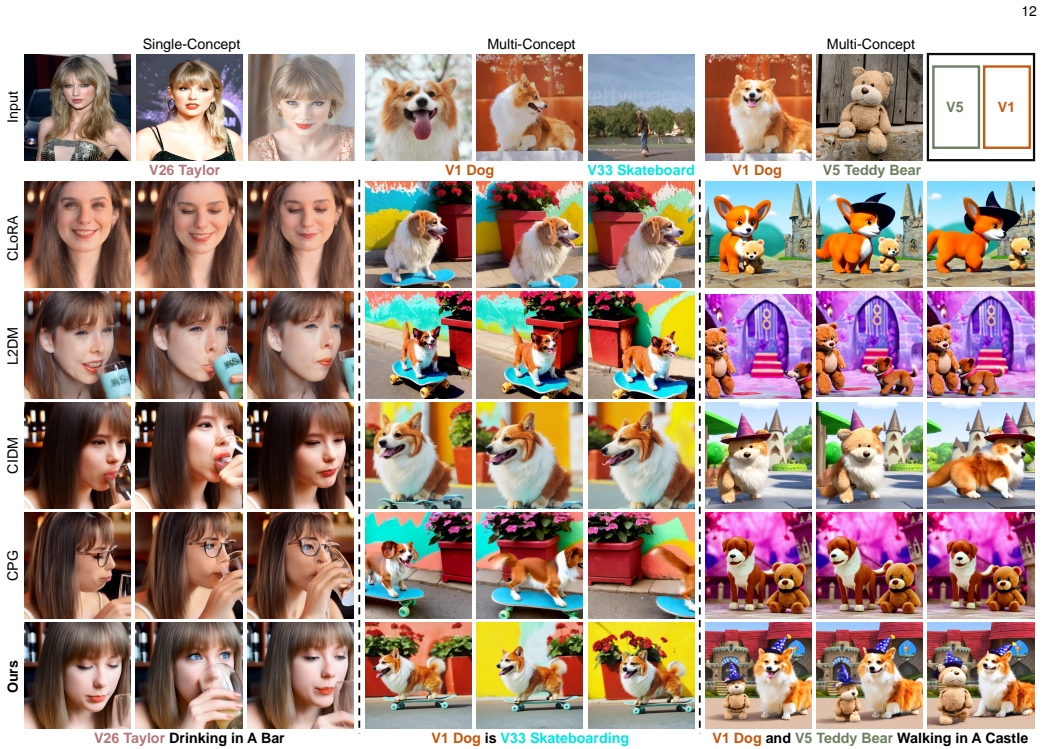
Custom diffusion models (CDMs) have garnered significant interest owing to their remarkable capacity for generating personalized concepts. However, the majority of CDMs unrealistically presume that the user's collection of personalized concepts is static and incapable of incremental growth over time. Furthermore, they exhibit significant catastrophic forgetting and concept neglect of previously learned concepts when incrementally learning a sequence of new ones. To resolve the above challenges, we develop a novel Continually Customizable Diffusion Model (CCDM), enabling users to perform concept-incremental versatile customization. Specifically, we design an attribute-decoupled LoRA (AD-LoRA) module and a relevance-guided AD-LoRA aggregation strategy to mitigate catastrophic forgetting. They can preserve concept-specific attributes of each task and leverage beneficial inter-task correlations to enhance the continual learning of new customization tasks. Additionally, to address the challenge of concept neglect, we propose a controllable regional context synthesis strategy that performs multi-concept composition in alignment with user-provided conditions. This strategy enhances the overall consistency in multi-concept synthesis by guaranteeing semantic independence between user-defined regions and their smooth boundary transitions. Experiments show our CCDM exhibits significant improvements over baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Continually Customizable Diffusion Model (CCDM) for concept-incremental versatile customization of diffusion models. It introduces an attribute-decoupled LoRA (AD-LoRA) module paired with a relevance-guided AD-LoRA aggregation strategy to mitigate catastrophic forgetting by preserving task-specific attributes while exploiting inter-task correlations, and a controllable regional context synthesis strategy to prevent concept neglect during multi-concept composition. The central claim is that these components together enable incremental learning of new personalized concepts without the forgetting and neglect observed in prior custom diffusion models, with experiments purportedly demonstrating significant improvements over baselines.
Significance. If the empirical results hold under rigorous evaluation, the work would be significant for continual and lifelong learning in generative models, as it targets practical limitations in evolving user-driven personalization. The introduction of named modules (AD-LoRA, relevance-guided aggregation, controllable regional synthesis) that aim to decouple attributes and enforce regional independence represents a targeted architectural response to known issues in incremental fine-tuning of diffusion models.
major comments (2)
- [Abstract] Abstract: the assertion that 'Experiments show our CCDM exhibits significant improvements over baseline methods' supplies no quantitative metrics, dataset names/sizes, baseline descriptions, or ablation results. This absence makes it impossible to determine whether the data support the central claim that AD-LoRA plus relevance-guided aggregation solves catastrophic forgetting without introducing new interference.
- [Abstract] The weakest assumption—that the attribute-decoupled LoRA module together with relevance-guided aggregation will preserve concept-specific attributes without requiring post-hoc adjustments—is presented without any derivation or control experiment showing that the relevance scores reduce to quantities independent of fitted parameters from prior tasks.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. We address each major comment below and will revise the abstract to provide greater specificity and clarity while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments show our CCDM exhibits significant improvements over baseline methods' supplies no quantitative metrics, dataset names/sizes, baseline descriptions, or ablation results. This absence makes it impossible to determine whether the data support the central claim that AD-LoRA plus relevance-guided aggregation solves catastrophic forgetting without introducing new interference.
Authors: We agree that the abstract would be strengthened by including concrete details. In the revised manuscript we will expand the abstract to report key quantitative metrics (e.g., forgetting reduction percentages and multi-concept composition scores), the datasets used (including number of concepts and images per task), the specific baseline methods compared, and references to the ablation studies that isolate the contribution of AD-LoRA and relevance-guided aggregation. These elements already appear in Sections 4 and 5; moving concise versions into the abstract will directly address the concern about supporting the central claim. revision: yes
-
Referee: [Abstract] The weakest assumption—that the attribute-decoupled LoRA module together with relevance-guided aggregation will preserve concept-specific attributes without requiring post-hoc adjustments—is presented without any derivation or control experiment showing that the relevance scores reduce to quantities independent of fitted parameters from prior tasks.
Authors: The derivation of relevance scores and their claimed independence from prior-task parameters is provided in Section 3.2, where the attribute-decoupling formulation and the aggregation formula are shown to operate on per-task attribute embeddings. Nevertheless, we acknowledge that the abstract itself does not reference this derivation or any supporting control. We will revise the abstract to briefly note the independence property and will add a short control experiment (new panel in an existing ablation figure) that explicitly verifies relevance scores remain stable when prior-task parameters are frozen. This addition will be included in the next version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces named modules (AD-LoRA, relevance-guided aggregation, controllable regional context synthesis) as design choices to address forgetting and neglect, then reports empirical improvements over baselines. No equations, parameter fits, or self-citation chains are shown that reduce any claimed prediction or uniqueness result to the inputs by construction. The central claims rest on the proposed architecture and experimental outcomes rather than definitional equivalence or fitted-input renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA-style adaptations can be applied to diffusion models for concept customization
invented entities (3)
-
Attribute-decoupled LoRA (AD-LoRA) module
no independent evidence
-
relevance-guided AD-LoRA aggregation strategy
no independent evidence
-
controllable regional context synthesis strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Il2m: Class incremental learning with dual memory,
E. Belouadah and A. Popescu, “Il2m: Class incremental learning with dual memory,” inICCV, 2019, pp. 583–592
2019
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulalet al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Align your latents: High-resolution video synthesis with latent diffusion models,
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis, “Align your latents: High-resolution video synthesis with latent diffusion models,” inCVPR, June 2023, pp. 22 563–22 575
2023
-
[4]
Attend- and-excite: Attention-based semantic guidance for text-to-image diffusion models,
H. Chefer, Y. Alaluf, Y. Vinker, L. Wolf, and D. Cohen-Or, “Attend- and-excite: Attention-based semantic guidance for text-to-image diffusion models,”ACM Transactions on Graphics, vol. 42, no. 4, jul 2023
2023
-
[5]
Disenstudio: Customized multi-subject text-to-video generation with disentangled spatial control,
H. Chen, X. Wang, Y. Zhang, Y. Zhou, Z. Zhang, S. Tang, and W. Zhu, “Disenstudio: Customized multi-subject text-to-video generation with disentangled spatial control,” inACM MM, 2024
2024
-
[6]
Any- door: Zero-shot object-level image customization,
X. Chen, L. Huang, Y. Liu, Y. Shen, D. Zhao, and H. Zhao, “Any- door: Zero-shot object-level image customization,”arxiv preprint arxiv:2307.09481, 2023
-
[7]
Dynasyn: Multi-subject personal- ization enabling dynamic action synthesis,
Y. Choi, C. Park, and S. J. Baek, “Dynasyn: Multi-subject personal- ization enabling dynamic action synthesis,”AAAI, vol. 39, no. 3, pp. 2564–2572, Apr. 2025
2025
-
[8]
Be your- self: Bounded attention for multi-subject text-to-image generation,
O. Dahary, O. Patashnik, K. Aberman, and D. Cohen-Or, “Be your- self: Bounded attention for multi-subject text-to-image generation,” inECCV, 2024, pp. 432–448
2024
-
[9]
No one left behind: Real-world federated class-incremental learning,
J. Dong, H. Li, Y. Cong, G. Sun, Y. Zhang, and L. Van Gool, “No one left behind: Real-world federated class-incremental learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 4, pp. 2054–2070, 2024
2054
-
[10]
How to continually adapt text-to-image diffusion models for flexible customization?
J. Dong, W. Liang, H. Li, D. Zhang, M. Cao, H. Ding, S. Khan, and F. S. Khan, “How to continually adapt text-to-image diffusion models for flexible customization?” inNeurIPS, vol. 37, 2024, pp. 130 057–130 083
2024
-
[11]
Federated class-incremental learning,
J. Dong, L. Wang, Z. Fang, G. Sun, S. Xu, X. Wang, and Q. Zhu, “Federated class-incremental learning,” inCVPR, June 2022, pp. 10 164–10 173
2022
-
[12]
Dytox: Transformers for continual learning with dynamic token expansion,
A. Douillard, A. Ramé, G. Couairon, and M. Cord, “Dytox: Transformers for continual learning with dynamic token expansion,” inCVPR, June 2022, pp. 9285–9295
2022
-
[13]
Scaling rectified flow transformers for high-resolution image synthesis,
P . Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini et al., “Scaling rectified flow transformers for high-resolution image synthesis,” inICML, 2024
2024
-
[14]
An image is worth one word: Personalizing text-to-image generation using textual inversion,
R. Gal, Y. Alaluf, Y. Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-or, “An image is worth one word: Personalizing text-to-image generation using textual inversion,” inICLR, 2023
2023
-
[15]
Phasemax: Convex phase retrieval via basis pursuit,
T. Goldstein and C. Studer, “Phasemax: Convex phase retrieval via basis pursuit,”IEEE Transactions on Information Theory, vol. 64, no. 4, pp. 2675–2689, 2018
2018
-
[16]
Vector quantized diffusion model for text-to-image synthesis,
S. Gu, D. Chen, J. Bao, F. Wen, B. Zhang, D. Chen, L. Yuan, and B. Guo, “Vector quantized diffusion model for text-to-image synthesis,” inCVPR, June 2022, pp. 10 696–10 706
2022
-
[17]
Mix- of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models,
Y. Gu, X. Wang, J. Z. Wu, Y. Shi, C. Yunpeng, Z. Fanet al., “Mix- of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models,” inNeurIPS, 2023
2023
-
[18]
Conceptguard: Continual personalized text- to-image generation with forgetting and confusion mitigation,
Z. Guo and T. Jin, “Conceptguard: Continual personalized text- to-image generation with forgetting and confusion mitigation,” in CVPR, June 2025, pp. 2945–2954
2025
-
[19]
Svdiff: Compact parameter space for diffusion fine-tuning,
L. Han, Y. Li, H. Zhang, P . Milanfar, D. Metaxas, and F. Yang, “Svdiff: Compact parameter space for diffusion fine-tuning,” in ICCV, 2023, pp. 7289–7300
2023
-
[20]
Cameractrl: Enabling camera control for video diffusion models,
H. He, Y. Xu, Y. Guo, G. Wetzstein, B. Dai, H. Li, and C. Yang, “Cameractrl: Enabling camera control for video diffusion models,” inICLR, 2025
2025
-
[21]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text,
R. Henschel, L. Khachatryan, H. Poghosyan, D. Hayrapetyanet al., “Streamingt2v: Consistent, dynamic, and extendable long video generation from text,” inCVPR, June 2025, pp. 2568–2577
2025
-
[22]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” in NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[23]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P . Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inICLR, 2022
2022
-
[24]
Turbo3d: Ultra-fast text-to-3d generation,
H. Hu, T. Yin, F. Luan, Y. Hu, H. Tan, Z. Xu, S. Bi, S. Tulsiani, and K. Zhang, “Turbo3d: Ultra-fast text-to-3d generation,” inCVPR, June 2025, pp. 23 668–23 678
2025
-
[25]
Storyagent: Customized storytelling video generation via multi- agent collaboration,
P . Hu, J. Jiang, J. Chen, M. Han, S. Liao, X. Chang, and X. Liang, “Storyagent: Customized storytelling video generation via multi- agent collaboration,”arXiv preprint arXiv:2411.04925, 2024
-
[26]
Videomage: Multi-subject and motion customization of text-to-video diffusion models,
C.-P . Huang, Y.-S. Wu, H.-K. Chung, K.-P . Chang, F.-E. Yang, and Y.- C. F. Wang, “Videomage: Multi-subject and motion customization of text-to-video diffusion models,” inCVPR, June 2025, pp. 17 603– 17 612
2025
-
[27]
Unicanvas: Affordance- aware unified real image editing via customized text-to-image generation,
J. Jin, Y. Shen, X. Zhao, Z. Fu, and J. Yang, “Unicanvas: Affordance- aware unified real image editing via customized text-to-image generation,”International Journal of Computer Vision, vol. 133, pp. 3456–3480, 01 2025
2025
-
[28]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” inNeurIPS, 2022
2022
-
[29]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitzet al., “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[30]
Multi-concept customization of text-to-image diffusion,
N. Kumari, B. Zhang, R. Zhang, E. Shechtman, and J.-Y. Zhu, “Multi-concept customization of text-to-image diffusion,” inCVPR, 2023
2023
-
[31]
B. F. Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
2024
-
[32]
Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,” inICML, 2022, pp. 12 888–12 900
2022
-
[33]
Tuning-free image customization with image and text guidance,
P . Li, Q. Nie, Y. Chen, X. Jiang, K. Wu, Y. Lin, Y. Liu, J. Peng, C. Wang, and F. Zheng, “Tuning-free image customization with image and text guidance,” inECCV, 2024, pp. 233–250
2024
-
[34]
Motrans: Customized motion transfer with text-driven video diffusion models,
X. Li, X. Jia, Q. Wang, H. Diao, mengmeng Ge, P . Li, Y. He, and H. Lu, “Motrans: Customized motion transfer with text-driven video diffusion models,” inACM MM, 2024
2024
-
[35]
Gligen: Open-set grounded text-to-image generation,
Y. Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y. J. Lee, “Gligen: Open-set grounded text-to-image generation,” inCVPR, June 2023, pp. 22 511–22 521
2023
-
[36]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 40, no. 12, pp. 2935–2947, 2017
2017
-
[37]
Magic3d: High-resolution text-to-3d content creation,
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zenget al., “Magic3d: High-resolution text-to-3d content creation,” inCVPR, June 2023, pp. 300–309
2023
-
[38]
Mu- seummaker: Continual style customization without catastrophic forgetting,
C. Liu, G. Sun, W. Liang, J. Dong, C. Qin, and Y. Cong, “Mu- seummaker: Continual style customization without catastrophic forgetting,”IEEE Transactions on Image Processing, vol. 34, pp. 2499– 2512, 2025
2025
-
[39]
Make-your-3d: Fast and consistent subject-driven 3d content generation,
F. Liu, H. Wang, W. Chen, H. Sun, and Y. Duan, “Make-your-3d: Fast and consistent subject-driven 3d content generation,” inECCV, 2024, pp. 389–406
2024
-
[40]
Dora: weight-decomposed low-rank adaptation,
S.-Y. Liu, C.-Y. Wang, H. Yin, P . Molchanov, Y.-C. F. Wang, K.-T. Cheng, and M.-H. Chen, “Dora: weight-decomposed low-rank adaptation,” inICML, 2024
2024
-
[41]
C-CLIP: Multimodal continual learning for vision-language model,
W. Liu, F. Zhu, L. Wei, and Q. Tian, “C-CLIP: Multimodal continual learning for vision-language model,” inICLR, 2025
2025
-
[42]
Customizable image synthesis with multiple subjects,
Z. Liu, Y. Zhang, Y. Shen, K. Zheng, K. Zhu, R. Feng, Y. Liuet al., “Customizable image synthesis with multiple subjects,” inNeurIPS, 2023. 17
2023
-
[43]
Coarse-to-fine latent diffusion for pose-guided person image synthesis,
Y. Lu, M. Zhang, A. J. Ma, X. Xie, and J. Lai, “Coarse-to-fine latent diffusion for pose-guided person image synthesis,” inCVPR, June 2024, pp. 6420–6429
2024
-
[44]
Progressive rendering distillation: Adapting stable diffusion for instant text- to-mesh generation without 3d data,
Z. Ma, X. Liang, R. Wu, X. Zhu, Z. Lei, and L. Zhang, “Progressive rendering distillation: Adapting stable diffusion for instant text- to-mesh generation without 3d data,” inCVPR, June 2025, pp. 11 036–11 050
2025
-
[45]
Representational continuity for unsupervised continual learning,
D. Madaan, J. Yoon, Y. Li, Y. Liu, and S. J. Hwang, “Representational continuity for unsupervised continual learning,” inICLR, 2022
2022
-
[46]
Lt3sd: Latent trees for 3d scene diffusion,
Q. Meng, L. Li, M. Nießner, and A. Dai, “Lt3sd: Latent trees for 3d scene diffusion,” inCVPR, June 2025, pp. 650–660
2025
-
[47]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models,
C. Mou, X. Wang, L. Xie, Y. Wu, J. Zhang, Z. Qi, Y. Shan, and X. Qie, “T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models,” inAAAI, 2024
2024
-
[48]
Dream- matcher: Appearance matching self-attention for semantically- consistent text-to-image personalization,
J. Nam, H. Kim, D. Lee, S. Jin, S. Kim, and S. Chang, “Dream- matcher: Appearance matching self-attention for semantically- consistent text-to-image personalization,” inCVPR, June 2024, pp. 8100–8110
2024
-
[49]
Shapewords: Guiding text-to-image synthesis with 3d shape-aware prompts,
D. Petrov, P . Goyal, D. Shivashok, Y. Tao, M. Averkiou, and E. Kalogerakis, “Shapewords: Guiding text-to-image synthesis with 3d shape-aware prompts,” inCVPR, June 2025, pp. 13 305–13 314
2025
-
[50]
SDXL: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach, “SDXL: Improving latent diffusion models for high-resolution image synthesis,” inICLR, 2024
2024
-
[51]
Dreamfusion: Text-to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text-to-3d using 2d diffusion,” inICLR, 2023
2023
-
[52]
Apply hierarchical-chain-of-generation to complex attributes text-to-3d generation,
Y. Qin, Z. Xu, and Y. Liu, “Apply hierarchical-chain-of-generation to complex attributes text-to-3d generation,” inCVPR, June 2025, pp. 18 521–18 530
2025
-
[53]
Dream- booth3d: Subject-driven text-to-3d generation,
A. Raj, S. Kaza, B. Poole, M. Niemeyer, N. Ruizet al., “Dream- booth3d: Subject-driven text-to-3d generation,” inICCV, October 2023, pp. 2349–2359
2023
-
[54]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P . Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hier- archical text-conditional image generation with clip latents,”arxiv preprint arxiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, 2022, pp. 10 684–10 695
2022
-
[56]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,
N. Ruiz, Y. Li, V . Jampani, Y. Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” inCVPR, 2023
2023
-
[57]
Hyperdreambooth: Hypernet- works for fast personalization of text-to-image models,
N. Ruiz, Y. Li, V . Jampani, W. Wei, T. Hou, Y. Pritch, N. Wadhwa, M. Rubinstein, and K. Aberman, “Hyperdreambooth: Hypernet- works for fast personalization of text-to-image models,” inCVPR, June 2024, pp. 6527–6536
2024
-
[58]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Dentonet al., “Photorealistic text-to-image diffusion models with deep language understanding,” inNeurIPS, 2022
2022
-
[59]
Fast high-resolution image synthesis with latent adversarial diffusion distillation,
A. Sauer, F. Boesel, T. Dockhorn, A. Blattmann, P . Esser, and R. Rom- bach, “Fast high-resolution image synthesis with latent adversarial diffusion distillation,” inSIGGRAPH Asia 2024 Conference Papers, 2024
2024
-
[60]
Continual diffusion: Continual customization of text-to-image diffusion with c-lora,
J. S. Smith, Y.-C. Hsu, L. Zhang, T. Hua, Z. Kira, Y. Shen, and H. Jin, “Continual diffusion: Continual customization of text-to-image diffusion with c-lora,”Transactions on Machine Learning Research, 2024
2024
-
[61]
Multidreamer3d: Multi-concept 3d customization with concept-aware diffusion guidance,
W. Song, S. Chang, and J. Yoo, “Multidreamer3d: Multi-concept 3d customization with concept-aware diffusion guidance,”arXiv preprint arXiv:2501.13449, 2025
-
[62]
Create your world: Lifelong text-to-image diffusion,
G. Sun, W. Liang, J. Dong, J. Li, Z. Ding, and Y. Cong, “Create your world: Lifelong text-to-image diffusion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6454– 6470, 2024
2024
-
[63]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation,
J. Tang, Z. Chen, X. Chenet al., “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” inECCV. Springer, 2024
2024
-
[64]
Falcon: Fairness learning via contrastive attention approach to continual semantic scene understanding,
T.-D. Truong, U. Prabhu, B. Raj, J. Cothren, and K. Luu, “Falcon: Fairness learning via contrastive attention approach to continual semantic scene understanding,” inCVPR, June 2025, pp. 15 065– 15 075
2025
-
[65]
Anti-dreambooth: Protecting users from personalized text-to-image synthesis,
T. Van Le, H. Phung, T. H. Nguyen, Q. Dao, N. N. Tran, and A. Tran, “Anti-dreambooth: Protecting users from personalized text-to-image synthesis,” inICCV, 2023, pp. 2116–2127
2023
-
[66]
Dualreal: Adaptive joint training for lossless identity-motion fusion in video customization,
W. Wang, M. Huang, Y. Tu, and Z. Mao, “Dualreal: Adaptive joint training for lossless identity-motion fusion in video customization,” inICCV, October 2025
2025
-
[67]
MS-diffusion: Multi-subject zero-shot image personalization with layout guid- ance,
X. Wang, S. Fu, Q. Huang, W. He, and H. Jiang, “MS-diffusion: Multi-subject zero-shot image personalization with layout guid- ance,” inICLR, 2025
2025
-
[68]
Lavie: High-quality video generation with cascaded latent diffusion models,
Y. Wang, X. Chen, X. Ma, S. Zhouet al., “Lavie: High-quality video generation with cascaded latent diffusion models,”International Journal of Computer Vision, 2025
2025
-
[69]
Sigstyle: Signature style transfer via personalized text-to-image models,
Y. Wang, T. Bai, X. Xie, Z. Yi, Y. Wang, and R. Ma, “Sigstyle: Signature style transfer via personalized text-to-image models,” AAAI, vol. 39, no. 8, pp. 8051–8059, Apr. 2025
2025
-
[70]
Dual- prompt: Complementary prompting for rehearsal-free continual learning,
Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhanget al., “Dual- prompt: Complementary prompting for rehearsal-free continual learning,” inECCV, 2022, p. 631–648
2022
-
[71]
Dream video: Composing your dream videos with customized subject and motion,
Y. Wei, S. Zhang, Z. Qing, H. Yuan, Z. Liu, Y. Liu, Y. Zhang, J. Zhou, and H. Shan, “Dream video: Composing your dream videos with customized subject and motion,” inCVPR, 2024, pp. 6537–6549
2024
-
[72]
Ouroboros3d: Image-to-3d generation via 3d-aware recursive diffusion,
H. Wen, Z. Huang, Y. Wang, X. Chen, and L. Sheng, “Ouroboros3d: Image-to-3d generation via 3d-aware recursive diffusion,” inCVPR, 2025, pp. 21 631–21 641
2025
-
[73]
Synthetic data is an elegant gift for continual vision-language models,
B. Wu, W. Shi, J. Wang, and M. Ye, “Synthetic data is an elegant gift for continual vision-language models,” inCVPR, June 2025, pp. 2813–2823
2025
-
[74]
Core: Context-regularized text embedding learning for text-to-image personalization,
F. Wu, Y. Pang, J. Zhang, L. Pang, J. Yin, B. Zhao, Q. Li, and X. Mao, “Core: Context-regularized text embedding learning for text-to-image personalization,” inAAAI, 2025, pp. 8377–8385
2025
-
[75]
Motionbooth: Motion-aware customized text-to-video generation,
J. Wu, X. Li, Y. Zeng, J. Zhang, Q. Zhou, Y. Li, Y. Tong, and K. Chen, “Motionbooth: Motion-aware customized text-to-video generation,” inNeurIPS, 2024
2024
-
[76]
Improved video vae for latent video diffusion model,
P . Wu, K. Zhu, Y. Liu, L. Zhao, W. Zhai, Y. Cao, and Z.-J. Zha, “Improved video vae for latent video diffusion model,” inCVPR, June 2025, pp. 18 124–18 133
2025
-
[77]
T. Wu, Y. Zhang, X. Wang, X. Zhouet al., “Customcrafter: Cus- tomized video generation with preserving motion and concept composition abilities,”arXiv preprint arXiv:2408.13239, 2024
-
[78]
Mixture of loRA experts,
X. Wu, S. Huang, and F. Wei, “Mixture of loRA experts,” inICLR, 2024
2024
-
[79]
Sana: Efficient high-resolution image synthesis with linear diffusion transformer,
E. Xie, J. Chen, J. Chen, H. Cai, H. Tang, Y. Lin, Z. Zhanget al., “Sana: Efficient high-resolution image synthesis with linear diffusion transformer,” inICLR, 2024
2024
-
[80]
Dreamvton: Customizing 3d virtual try-on with personalized diffusion models,
Z. Xie, H. Dong, Y. Gao, Z. Ma, and X. Liang, “Dreamvton: Customizing 3d virtual try-on with personalized diffusion models,” inACM MM, 2024, p. 10784–10793
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.