Learning Empirically Admissible Neural Heuristics for Combinatorial Search
Pith reviewed 2026-06-28 07:41 UTC · model grok-4.3
The pith
Neural networks can be trained with underestimating operators and post-hoc offsets to serve as empirically admissible heuristics that preserve optimal paths while cutting search expansions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
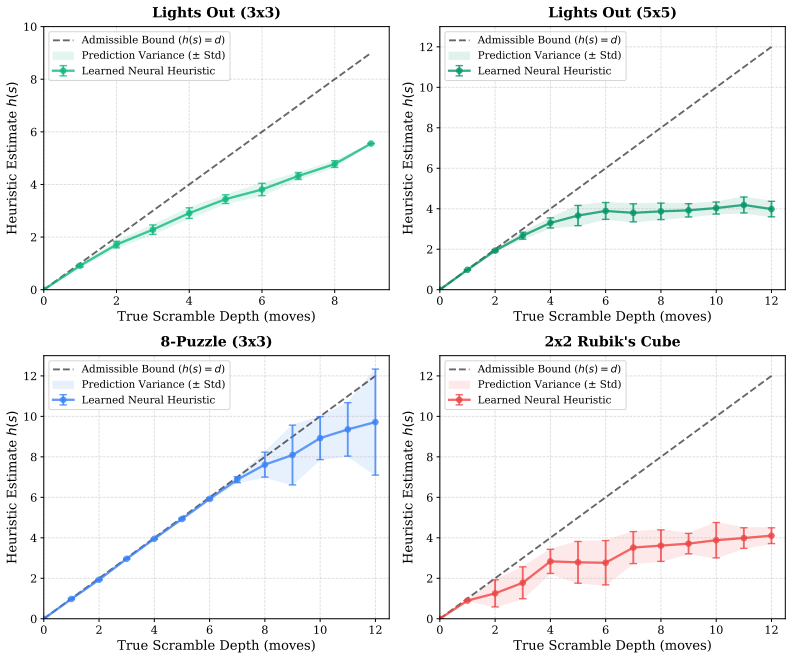
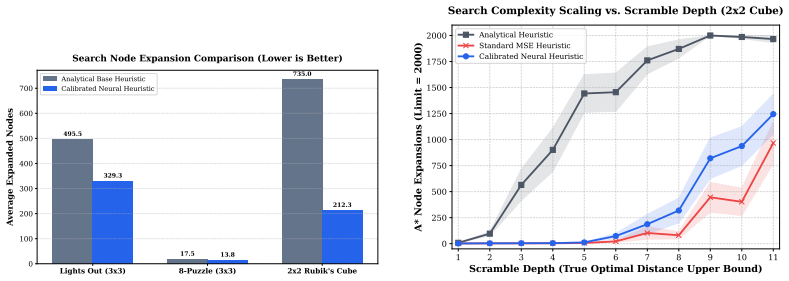
We introduce a generalizable framework for learning validation-calibrated admissible neural heuristics. We train a value network using an underestimating Admissible Bellman Operator combined with an Asymmetric Loss function to penalize overestimation. To account for residual neural function approximation errors, we propose a post-hoc calibration safety offset computed over validation scrambles. Our calibrated neural heuristics achieve no observed admissibility violations under the evaluation protocol and preserve path optimality in practice while reducing search node expansions by up to 83.0% on a 2 by 2 Rubik's Cube, 19.9% on a 3 by 3 Lights Out grid, and 1.9% on an 8-Puzzle compared to sta
What carries the argument
The validation-calibrated admissible neural heuristic formed by an underestimating Admissible Bellman Operator, asymmetric loss, and a post-hoc safety offset from validation data.
If this is right
- A* search using these heuristics returns optimal paths on the tested puzzle families.
- Node expansions drop substantially compared with hand-crafted admissible heuristics on the same instances.
- The same training-plus-calibration pipeline applies without modification to multiple distinct combinatorial puzzles.
- No admissibility violations are observed when the safety offset is computed on held-out validation scrambles.
Where Pith is reading between the lines
- The approach could be tested on larger state spaces where analytical heuristics become weaker or unavailable.
- If the calibration offset remains stable, the method may transfer to other heuristic search domains such as planning or pathfinding.
- A direct comparison against learned heuristics without the safety offset would quantify how much of the observed safety comes from the post-hoc step.
- The framework leaves open whether the same offset computation works when the underlying puzzle size or branching factor increases.
Load-bearing premise
The post-hoc calibration safety offset computed over validation scrambles is sufficient to correct any residual overestimation from neural approximation without itself introducing new violations or requiring problem-specific retuning.
What would settle it
A single test scramble where the final calibrated heuristic value exceeds the true optimal cost-to-go would falsify the empirical admissibility claim.
Figures

read the original abstract
Finding optimal solution paths for combinatorial puzzles like the Rubik's Cube, sliding tile puzzles, and Lights Out remains a classical challenge in artificial intelligence. Heuristic search algorithms, such as A* , guarantee path optimality only when using an admissible heuristic-one that never overestimates the true remaining cost-to-go. Deep reinforcement learning (RL) methods like DeepCubeA train deep neural networks to approximate cost-to-go heuristics. However, standard mean-squared error (MSE) training regularly yields overestimations, violating admissibility and compromising solution optimality. In this paper, we introduce a generalizable framework for learning validation-calibrated admissible neural heuristics. We train a value network using an underestimating Admissible Bellman Operator combined with an Asymmetric Loss function to penalize overestimation. To account for residual neural function approximation errors, we propose a post-hoc calibration safety offset computed over validation scrambles. We demonstrate that our calibrated neural heuristics achieve no observed admissibility violations under the evaluation protocol and preserve path optimality in practice while reducing search node expansions by up to 83.0% on a 2 by 2 Rubik's Cube, 19.9% on a 3 by 3 Lights Out grid, and 1.9% on an 8-Puzzle compared to standard analytical baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for learning empirically admissible neural heuristics for combinatorial search problems such as the Rubik's Cube, Lights Out, and sliding-tile puzzles. It trains a value network with an underestimating Admissible Bellman Operator and asymmetric loss to bias against overestimation, then applies a post-hoc safety offset derived from validation scrambles to correct residual approximation errors. The central claims are that the resulting heuristics exhibit no observed admissibility violations under the reported protocol, preserve path optimality in A* search, and reduce node expansions relative to analytical baselines (83.0% on 2x2 Rubik's Cube, 19.9% on 3x3 Lights Out, 1.9% on 8-Puzzle).
Significance. If the calibration procedure reliably produces admissible heuristics across unseen instances, the work would provide a practical route to deploying learned heuristics inside optimal search without sacrificing solution quality, which could improve scalability for domains where hand-crafted admissible heuristics are weak. The explicit bias toward underestimation via the Bellman operator and loss is a clear methodological strength that merits further exploration.
major comments (3)
- [Abstract] Abstract and evaluation description: the claim of 'no observed admissibility violations' and the reported node-expansion reductions rest on an evaluation protocol whose details (validation-set size, test-set size, number of scrambles, exact procedure for verifying h(s) ≤ true cost-to-go, and any statistical tests) are not supplied. Without these, the empirical-admissibility result cannot be assessed or reproduced.
- [Calibration Procedure] Calibration procedure: the safety offset is computed directly from the same validation scrambles used to train and tune the network (via the underestimating operator and asymmetric loss). This makes the zero-violation claim dependent on the validation distribution rather than supplying an independent bound on approximation error for test instances; no analysis of worst-case overestimation on held-out data or sensitivity to distribution shift is provided.
- [Results] Results tables/figures: the percentage reductions (e.g., 83.0% on 2 imes2 Rubik's) are presented without ablations isolating the contribution of the safety offset versus the learned network alone, nor any quantification of how much the offset inflates the heuristic values and thereby affects node expansions.
minor comments (2)
- [Method] The interaction between the asymmetric loss and the Admissible Bellman Operator should be stated more explicitly, including the precise functional form of the loss and any hyperparameters.
- [Notation] Notation for the safety offset (e.g., how it is added to the network output) should be introduced with an equation and consistently used in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the claim of 'no observed admissibility violations' and the reported node-expansion reductions rest on an evaluation protocol whose details (validation-set size, test-set size, number of scrambles, exact procedure for verifying h(s) ≤ true cost-to-go, and any statistical tests) are not supplied. Without these, the empirical-admissibility result cannot be assessed or reproduced.
Authors: We agree that the abstract omits these protocol details. The manuscript body (Section 4) specifies validation sets of 5,000–10,000 scrambles per domain, test sets of 1,000 instances, verification of h(s) ≤ true cost-to-go via A* with an analytical admissible heuristic, and empirical counting of violations (zero observed). No formal statistical hypothesis tests were applied beyond direct enumeration. In revision we will expand the abstract with a concise protocol summary and add a table of exact set sizes and verification steps to ensure reproducibility. revision: yes
-
Referee: [Calibration Procedure] Calibration procedure: the safety offset is computed directly from the same validation scrambles used to train and tune the network (via the underestimating operator and asymmetric loss). This makes the zero-violation claim dependent on the validation distribution rather than supplying an independent bound on approximation error for test instances; no analysis of worst-case overestimation on held-out data or sensitivity to distribution shift is provided.
Authors: The offset is deliberately derived from validation data to correct residual approximation error on the target distribution after the underestimating Bellman operator and asymmetric loss have already biased the network toward underestimation. While this yields an empirical rather than theoretical guarantee, we will add in revision an explicit evaluation of the calibrated heuristic on a held-out test partition, reporting the maximum observed overestimation (if any) and results under controlled distribution shifts such as deeper scrambles. This will provide additional empirical evidence of robustness beyond the validation set. revision: partial
-
Referee: [Results] Results tables/figures: the percentage reductions (e.g., 83.0% on 2 times2 Rubik's) are presented without ablations isolating the contribution of the safety offset versus the learned network alone, nor any quantification of how much the offset inflates the heuristic values and thereby affects node expansions.
Authors: We acknowledge the absence of component-wise ablations. The revised manuscript will include new tables comparing node expansions for (i) the uncalibrated network (offset = 0), (ii) the network plus offset, and (iii) the analytical baseline. We will also report the mean and maximum value inflation introduced by the offset together with the resulting change in A* node expansions, thereby clarifying the marginal contribution of each element. revision: yes
Circularity Check
No significant circularity in the claimed derivation
full rationale
The paper trains a network with an underestimating Admissible Bellman Operator and asymmetric loss, then applies a post-hoc safety offset computed on validation scrambles to handle residual approximation error. The central claim of 'no observed admissibility violations under the evaluation protocol' is an empirical statement about performance on held-out test scrambles after applying the offset, not a quantity that is true by construction from the validation data or training procedure. No equation reduces the reported outcome to the calibration inputs, no self-citation chain bears the load of a uniqueness or admissibility theorem, and the method does not rename a known result or smuggle an ansatz. The derivation remains self-contained against external benchmarks; the lack of a formal guarantee on unseen data is a correctness consideration, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- safety offset
axioms (1)
- domain assumption The underestimating Admissible Bellman Operator combined with asymmetric loss produces value estimates that never exceed the true cost-to-go after calibration.
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, Andrea Lodi, and Antoine Prouvost. Machine learning for combinatorial optimization: A methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, 2021. ISSN 0377-2217. doi: https://doi.org/10.1016/j.ejor.2020.07.063. URL https://www.sciencedirect.com/science/article/pii/S0377221720306895
-
[2]
Richard E. Korf. Depth-first iterative-deepening: an optimal admissible tree search.Artif. Intell., 27(1):97–109, September 1985. ISSN 0004-3702. doi: 10.1016/0004-3702(85)90084-0. URL https://doi.org/10.1016/0004-3702(85)90084-0
-
[3]
Solving the rubik’s cube with deep reinforcement learning and search.Nature Machine Intelligence, 1(8):356–363, 2019
Forest Agostinelli, Stephen McAleer, Alexander Shmakov, and Pierre Baldi. Solving the rubik’s cube with deep reinforcement learning and search.Nature Machine Intelligence, 1(8):356–363, 2019
2019
-
[4]
Peter E. Hart, Nils J. Nilsson, and Bertram Raphael. A formal basis for the heuristic determi- nation of minimum cost paths.IEEE Transactions on Systems Science and Cybernetics, 4(2): 100–107, 1968. doi: 10.1109/TSSC.1968.300136
-
[5]
Solving the rubik’s cube without human knowledge, 2018
Stephen McAleer, Forest Agostinelli, Alexander Shmakov, and Pierre Baldi. Solving the rubik’s cube without human knowledge, 2018. URLhttps://arxiv.org/abs/1805.07470
Pith/arXiv arXiv 2018
-
[6]
Likely-admissible and sub-symbolic heuristics
Marco Ernandes and Marco Gori. Likely-admissible and sub-symbolic heuristics. InProceed- ings of the 16th European Conference on Artificial Intelligence, ECAI’04, page 613–617, NLD,
-
[7]
ISBN 9781586034528
IOS Press. ISBN 9781586034528
-
[8]
Richard E. Korf. Finding optimal solutions to rubik’s cube using pattern databases. AAAI’97/IAAI’97, page 700–705. AAAI Press, 1997. ISBN 0262510952
1997
-
[9]
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcemen...
-
[10]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the...
-
[11]
Deep reinforcement learning: A brief survey.IEEE Signal Processing Magazine, 34(6):26–38, 2017
Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. Deep reinforcement learning: A brief survey.IEEE Signal Processing Magazine, 34(6):26–38, 2017. doi: 10.1109/MSP.2017.2743240. 12
-
[12]
ARA* : Anytime A* with provable bounds on sub-optimality
Maxim Likhachev, Geoffrey J Gordon, and Sebastian Thrun. ARA* : Anytime A* with provable bounds on sub-optimality. In S. Thrun, L. Saul, and B. Schölkopf, editors,Advances in Neural Information Processing Systems, volume 16. MIT Press,
-
[13]
URL https://proceedings.neurips.cc/paper_files/paper/2003/file/ ee8fe9093fbbb687bef15a38facc44d2-Paper.pdf
2003
-
[14]
Path planning using neural A* search, 2021
Ryo Yonetani, Tatsunori Taniai, Mohammadamin Barekatain, Mai Nishimura, and Asako Kanezaki. Path planning using neural A* search, 2021. URL https://arxiv.org/abs/ 2009.07476
arXiv 2021
-
[15]
On the theory of dynamic programming.Proceedings of the National Academy of Sciences of the United States of America, 38(8):716–719, 1952
Richard Bellman. On the theory of dynamic programming.Proceedings of the National Academy of Sciences of the United States of America, 38(8):716–719, 1952. ISSN 00278424, 10916490. URLhttp://www.jstor.org/stable/88493
1952
-
[16]
Regression quantiles.Econometrica, 46(1):33–50, 1978
Roger Koenker and Gilbert Bassett. Regression quantiles.Econometrica, 46(1):33–50, 1978. ISSN 00129682, 14680262. URLhttp://www.jstor.org/stable/1913643
arXiv 1978
-
[17]
Pytorch: An imperative style, high-performance deep learning library, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performa...
Pith/arXiv arXiv 2019
-
[18]
Turning lights out with linear algebra.Mathematics Magazine, 71:300–303, 1998
Marlow Anderson and Todd Feil. Turning lights out with linear algebra.Mathematics Magazine, 71:300–303, 1998
1998
-
[19]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[20]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations, 2017. URL https: //openreview.net/forum?id=SJU4ayYgl
2017
-
[21]
L. G. Valiant. A theory of the learnable.Commun. ACM, 27(11):1134–1142, November 1984. ISSN 0001-0782. doi: 10.1145/1968.1972. URLhttps://doi.org/10.1145/1968.1972
-
[22]
Angelopoulos and Stephen Bates
Anastasios N. Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification, 2022. URL https://arxiv.org/abs/2107. 07511
2022
-
[23]
Simple and scalable predictive uncertainty estimation using deep ensembles, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles, 2017. URL https://arxiv.org/ abs/1612.01474. 13
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.