Optimizing the Cost-Quality Tradeoff of Agentic Theorem Provers in Lean
Pith reviewed 2026-06-28 05:59 UTC · model grok-4.3
The pith
An action routing agent reduces the cost of Lean theorem proving by 28.9% on a PutnamBench subset while preserving performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
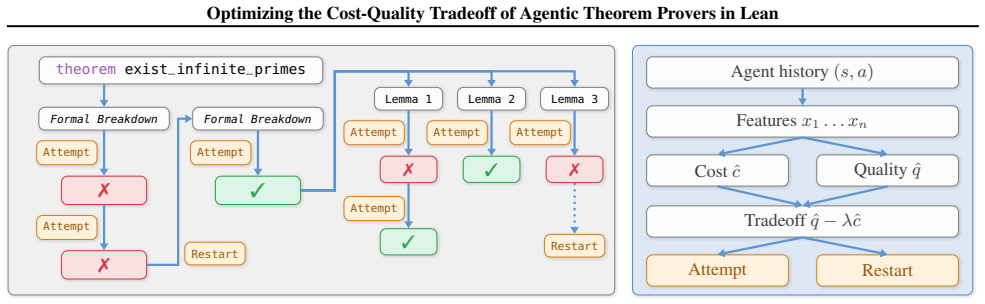
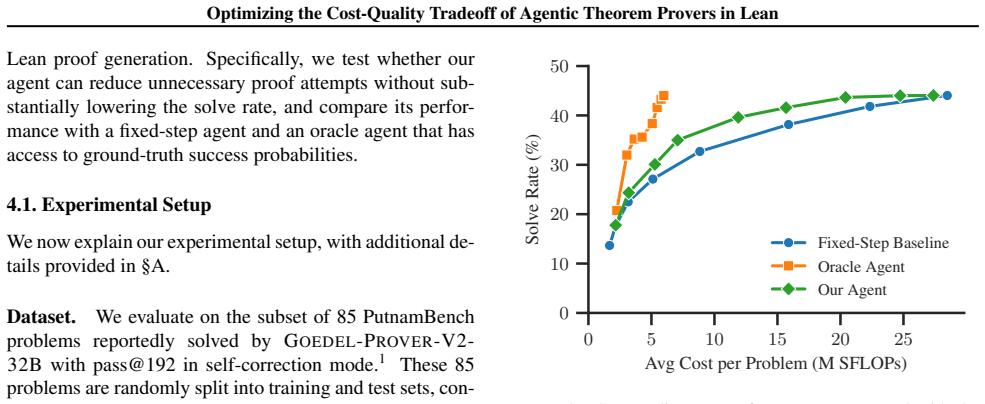
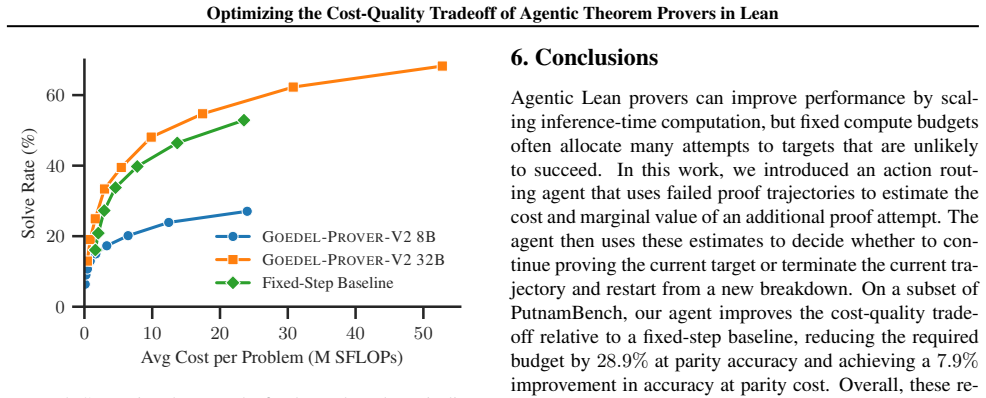
The paper claims that the action routing agent decreases the cost by 28.9% over a fixed-step baseline on average on a subset of PutnamBench, preserving performance, by having the control plane observe previous failed Lean attempts, estimate both the likelihood of success and the cost of another attempt, and decide whether to continue proving the current target or restart from a new breakdown.
What carries the argument
The action routing agent with a data plane that generates natural-language lemma decompositions, formalizes them in Lean, and samples proof attempts, paired with a control plane that uses failed trajectories to estimate success likelihood and next-attempt cost before routing to continue or restart.
If this is right
- Failed Lean trajectories contain usable signals for deciding when to stop or restart.
- Restarting from a new lemma breakdown can be cheaper overall than persisting on a failing target.
- Dynamic routing based on per-target estimates preserves proof success while lowering total compute compared with fixed-step search.
- The same separation of generation from routing decisions applies to any workflow that samples multiple proof attempts and receives compiler feedback.
Where Pith is reading between the lines
- Adding a similar control plane to other formal-reasoning agents could let them manage compute budgets across larger problem sets without hand-tuned step limits.
- The estimates from failed trajectories could themselves be improved by supervised training on past runs, potentially widening the cost gap further.
- This routing pattern might extend to interactive proving sessions where a human or another model supplies new decompositions on demand.
Load-bearing premise
The control plane can reliably estimate both the likelihood of success and the cost of another attempt from previous failed Lean trajectories.
What would settle it
On the same PutnamBench subset, replace the control plane estimates with a fixed policy that always continues for the same number of steps and check whether the 28.9% cost reduction disappears while success rate stays the same.
Figures

read the original abstract
Large language models (LLMs) are increasingly used in workflows for generating formal proofs in Lean. These workflows often decompose problems into smaller lemmas, sample many proof attempts, and use compiler feedback to guide search. However, they can be prohibitively expensive, often spending substantial compute on attempts that ultimately fail. In this work, we address this problem with an action routing agent that consists of a data plane and a control plane. The data plane generates natural-language lemma decompositions, formalizes them in Lean, and samples proof attempts for the resulting theorem and lemma targets. The control plane observes previous failed Lean attempts, estimates both the likelihood of success and the cost of another attempt, and decides whether to continue proving the current target or restart from a new breakdown. On a subset of PutnamBench, our agent decreases the cost by 28.9% over a fixed-step baseline on average, preserving performance while using substantially less compute. These results suggest that failed Lean trajectories provide actionable signals for cost-aware resource allocation in agentic theorem proving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an agentic theorem prover in Lean with a data plane that generates natural-language lemma decompositions, formalizes them, and samples proof attempts, paired with a control plane that observes failed Lean trajectories to estimate success likelihood and additional attempt cost before deciding to continue on the current target or restart with a new decomposition. It reports that this agent achieves a 28.9% average cost reduction relative to a fixed-step baseline on a PutnamBench subset while preserving performance.
Significance. If the control-plane estimates are shown to be accurate and the cost savings hold under rigorous controls, the work would demonstrate a practical method for cost-aware resource allocation in LLM-based formal proof search, potentially improving efficiency in agentic theorem proving by exploiting signals from failed trajectories.
major comments (1)
- [Abstract] Abstract: the control plane is described as estimating 'the likelihood of success and the cost of another attempt' from previous failed Lean trajectories, yet no algorithm, features, model, training data, or validation procedure for these estimates is supplied. This estimation mechanism is load-bearing for the headline 28.9% cost-reduction result, because the savings are attributed to the agent's decisions to continue versus restart.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the importance of the control-plane estimation mechanism. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the control plane is described as estimating 'the likelihood of success and the cost of another attempt' from previous failed Lean trajectories, yet no algorithm, features, model, training data, or validation procedure for these estimates is supplied. This estimation mechanism is load-bearing for the headline 28.9% cost-reduction result, because the savings are attributed to the agent's decisions to continue versus restart.
Authors: We agree that the manuscript does not supply the requested details on the estimation procedure. The abstract and high-level description mention that the control plane estimates success likelihood and additional cost from failed trajectories, but no algorithm, features, model, training data, or validation is provided. This is a substantive gap that affects interpretability of the 28.9% cost reduction. In the revised manuscript we will add a dedicated subsection (likely in Methods) that specifies the estimation algorithm (including whether it is a learned model or rule-based), the exact features extracted from Lean trajectories, the model or heuristic used, the training data and procedure, and any validation or accuracy results for the estimates. This addition will directly support the cost-saving claims. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper reports an empirical cost reduction result from an agentic system on a PutnamBench subset. No equations, fitted parameters, self-citations, or derivation steps are described that reduce a claimed prediction or result to its own inputs by construction. The control plane estimation is left unspecified, but this is a verification gap rather than a circular reduction. The result is presented as an experimental outcome against a fixed-step baseline and does not rely on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , month =
Grok 4 Model Card , author =. 2025 , month =
2025
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal and Lama Ahmad and Jason Ai and Sam Altman and Andy Applebaum and Edwin Arbus and Rahul K. Arora and Yu Bai and Bowen Baker and Haiming Bao and Boaz Barak and Ally Bennett and Tyler Bertao and Nivedita Brett and Eugene Brevdo and Greg Brockman and S. gpt-oss-120b. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.10925 , eprinttype =...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[3]
2025 , month =
GPT-5 System Card , author =. 2025 , month =
2025
-
[4]
2025 , month = may, url =
Anthropic , title =. 2025 , month = may, url =
2025
-
[5]
2025 , month = dec, url =
Gemini 3 Pro - Model Card , institution =. 2025 , month = dec, url =
2025
-
[6]
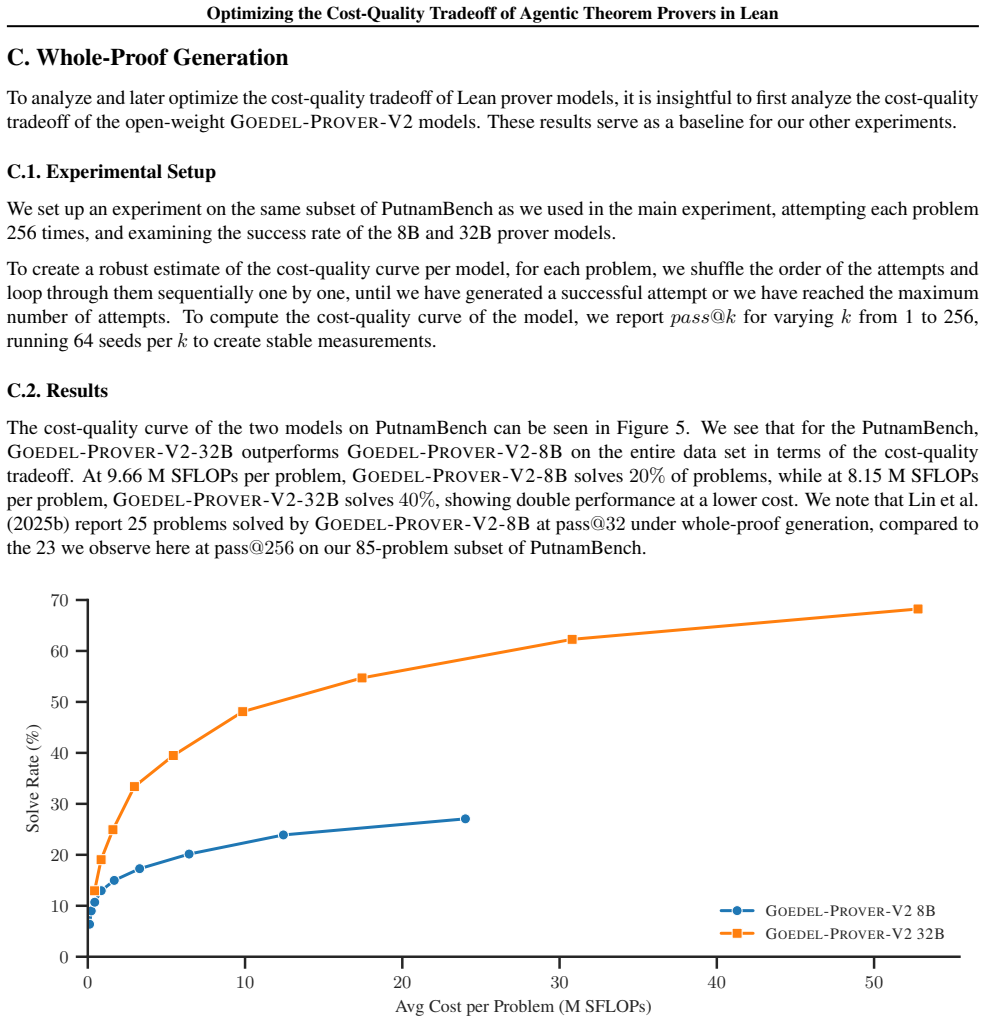
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Yong Lin and Shange Tang and Bohan Lyu and Ziran Yang and Jui. Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction , journal =. 2025 , url =. doi:10.48550/ARXIV.2508.03613 , eprinttype =. 2508.03613 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.03613 2025
-
[7]
arXiv preprint arXiv:2509.22819 , year=
Hilbert: Recursively Building Formal Proofs with Informal Reasoning , author=. arXiv preprint arXiv:2509.22819 , year=
-
[8]
Seed-Prover : Deep and broad reasoning for automated theorem proving
Luoxin Chen and Jinming Gu and Liankai Huang and Wenhao Huang and Zhicheng Jiang and Allan Jie and Xiaoran Jin and Xing Jin and Chenggang Li and Kaijing Ma and Cheng Ren and Jiawei Shen and Wenlei Shi and Tong Sun and He Sun and Jiahui Wang and Siran Wang and Zhihong Wang and Chenrui Wei and Shufa Wei and Yonghui Wu and Yuchen Wu and Yihang Xia and Huajia...
-
[9]
arXiv preprint arXiv:2109.00110 , year=
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics , author=. arXiv preprint arXiv:2109.00110 , year=
-
[10]
PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition , booktitle =
George Tsoukalas and Jasper Lee and John Jennings and Jimmy Xin and Michelle Ding and Michael Jennings and Amitayush Thakur and Swarat Chaudhuri , editor =. PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition , booktitle =. 2024 , url =
2024
-
[11]
, biburl =
Platt, John C. , biburl =. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods , username =. Advances in Large Margin Classifiers , citeseerurl =
-
[12]
arXiv preprint arXiv:2601.14027 , year=
Numina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics , author=. arXiv preprint arXiv:2601.14027 , year=
-
[13]
url: https://arxiv.org/abs/2507.15225
Yichi Zhou and Jianqiu Zhao and Yongxin Zhang and Bohan Wang and Siran Wang and Luoxin Chen and Jiahui Wang and Haowei Chen and Allan Jie and Xinbo Zhang and Haocheng Wang and Luong Quoc Trung and Rong Ye and Phan Nhat Hoang and Huishuai Zhang and Peng Sun and Hang Li , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.15225 , eprinttype =. ...
-
[14]
Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmark , year=
MathArena: Evaluating LLMs on Uncontaminated Math Competitions , author =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmark , year=
-
[15]
The Lean Theorem Prover (System Description)
de Moura, Leonardo and Kong, Soonho and Avigad, Jeremy and van Doorn, Floris and von Raumer, Jakob. The Lean Theorem Prover (System Description). Automated Deduction - CADE-25. 2015
2015
-
[16]
The Lean 4 Theorem Prover and Programming Language
Moura, Leonardo de and Ullrich, Sebastian. The Lean 4 Theorem Prover and Programming Language. Automated Deduction -- CADE 28. 2021
2021
-
[17]
The Lean mathematical library , journal =. 2019 , url =. 1910.09336 , timestamp =
arXiv 2019
-
[18]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. CoRR , volume =. 2017 , url =. 1706.03762 , timestamp =
Pith/arXiv arXiv 2017
-
[19]
Chi and Quoc Le and Denny Zhou , title =
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Ed H. Chi and Quoc Le and Denny Zhou , title =. CoRR , volume =. 2022 , url =. 2201.11903 , timestamp =
Pith/arXiv arXiv 2022
-
[20]
2024 , eprint=
OpenAI o1 System Card , author=. 2024 , eprint=
2024
-
[21]
2017 , eprint=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. 2017 , eprint=
2017
-
[22]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[23]
2020 , eprint=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. 2020 , eprint=
2020
-
[24]
2025 , url =
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning , author =. 2025 , url =
2025
-
[25]
2024 , eprint=
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data , author=. 2024 , eprint=
2024
-
[26]
Z. Z. Ren and Zhihong Shao and Junxiao Song and Huajian Xin and Haocheng Wang and Wanjia Zhao and Liyue Zhang and Zhe Fu and Qihao Zhu and Dejian Yang and Z. F. Wu and Zhibin Gou and Shirong Ma and Hongxuan Tang and Yuxuan Liu and Wenjun Gao and Daya Guo and Chong Ruan , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.21801 , eprinttype =....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21801 2025
-
[27]
Goedel-Prover : A frontier model for open-source automated theorem proving
Yong Lin and Shange Tang and Bohan Lyu and Jiayun Wu and Hongzhou Lin and Kaiyu Yang and Jia Li and Mengzhou Xia and Danqi Chen and Sanjeev Arora and Chi Jin , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.07640 , eprinttype =. 2502.07640 , timestamp =
-
[28]
Vechev , editor =
Jasper Dekoninck and Maximilian Baader and Martin T. Vechev , editor =. A Unified Approach to Routing and Cascading for LLMs , booktitle =. 2025 , url =
2025
-
[29]
The Eleventh International Conference on Learning Representations,
Stanislas Polu and Jesse Michael Han and Kunhao Zheng and Mantas Baksys and Igor Babuschkin and Ilya Sutskever , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[30]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. 2024 , eprint =
2024
-
[31]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[32]
2023 , eprint=
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics , author=. 2023 , eprint=
2023
-
[33]
ChatGPT (Nov 30 version) , year =
-
[34]
2026 , eprint=
A Minimal Agent for Automated Theorem Proving , author=. 2026 , eprint=
2026
-
[35]
2026 , eprint=
CSLib: The Lean Computer Science Library , author=. 2026 , eprint=
2026
-
[36]
2025 , eprint=
Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad , author=. 2025 , eprint=
2025
-
[37]
2025 , month =
Luong, Thang and Lockhart, Edward , title =. 2025 , month =
2025
-
[38]
2026 , month =
Luong, Thang and Mirrokni, Vahab , title =. 2026 , month =
2026
-
[39]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[40]
2026 , month=
GLM-5: From Vibe Coding to Agentic Engineering , author=. 2026 , month=
2026
-
[41]
2026 , month=
Qwen3.5: Towards Native Multimodal Agents , author=. 2026 , month=
2026
-
[42]
Wang, Lei and Ma, Chen and Feng, Xueyang and Zhang, Zeyu and Yang, Hao and Zhang, Jingsen and Chen, Zhiyuan and Tang, Jiakai and Chen, Xu and Lin, Yankai and Zhao, Wayne Xin and Wei, Zhewei and Wen, Jirong , year=. A survey on large language model based autonomous agents , volume=. Frontiers of Computer Science , publisher=. doi:10.1007/s11704-024-40231-1...
-
[43]
2024 , eprint=
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters , author=. 2024 , eprint=
2024
-
[44]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[45]
2023 , eprint=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. 2023 , eprint=
2023
-
[46]
2023 , eprint=
Teaching Large Language Models to Self-Debug , author=. 2023 , eprint=
2023
-
[47]
Jeremy Avigad and Leonardo de Moura and Soonho Kong and Sebastian Ullrich , title =
-
[48]
Wadler, Philip , title =. Commun. ACM , month = nov, pages =. 2015 , issue_date =. doi:10.1145/2699407 , abstract =
-
[49]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[50]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[51]
2023 , eprint=
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs , author=. 2023 , eprint=
2023
-
[52]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[53]
2024 , eprint=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. 2024 , eprint=
2024
-
[54]
Jiangjie Chen and Wenxiang Chen and Jiacheng Du and Jinyi Hu and Zhicheng Jiang and Allan Jie and Xiaoran Jin and Xing Jin and Chenggang Li and Wenlei Shi and Zhihong Wang and Mingxuan Wang and Chenrui Wei and Shufa Wei and Huajian Xin and Fan Yang and Weihao Gao and Zheng Yuan and Tianyang Zhan and Zeyu Zheng and Tianxi Zhou and Thomas Hanwen Zhu , title...
-
[55]
Olympiad-level formal mathematical reasoning with reinforcement learning
Hubert, Thomas and Mehta, Rishi and Sartran, Laurent and others , title =. Nature , year =. doi:10.1038/s41586-025-09833-y , url =
-
[56]
Leanstral: Open-Source foundation for trustworthy vibe-coding , year =
-
[57]
Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection , journal =
Guillem Ram. Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection , journal =. 2024 , url =. doi:10.48550/ARXIV.2405.02134 , eprinttype =. 2405.02134 , timestamp =
-
[58]
Transactions on Machine Learning Research , year=
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance , author=. Transactions on Machine Learning Research , year=
-
[59]
Learning to Route LLMs with Confidence Tokens , booktitle =
Yu. Learning to Route LLMs with Confidence Tokens , booktitle =. 2025 , url =
2025
-
[60]
Dujian Ding and Ankur Mallick and Chi Wang and Robert Sim and Subhabrata Mukherjee and Victor R. Hybrid. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[61]
Surya Narayanan Hari and Matt Thomson , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2308.11601 , eprinttype =. 2308.11601 , timestamp =
-
[62]
When Does Confidence-Based Cascade Deferral Suffice? , booktitle =
Wittawat Jitkrittum and Neha Gupta and Aditya Krishna Menon and Harikrishna Narasimhan and Ankit Singh Rawat and Sanjiv Kumar , editor =. When Does Confidence-Based Cascade Deferral Suffice? , booktitle =. 2023 , url =
2023
-
[63]
AutoMix: Automatically Mixing Language Models , booktitle =
Pranjal Aggarwal and Aman Madaan and Ankit Anand and Srividya Pranavi Potharaju and Swaroop Mishra and Pei Zhou and Aditya Gupta and Dheeraj Rajagopal and Karthik Kappaganthu and Yiming Yang and Shyam Upadhyay and Manaal Faruqui and Mausam , editor =. AutoMix: Automatically Mixing Language Models , booktitle =. 2024 , url =
2024
-
[64]
2023 , eprint=
Baldur: Whole-Proof Generation and Repair with Large Language Models , author=. 2023 , eprint=
2023
-
[65]
2025 , eprint=
Towards Understanding Distilled Reasoning Models: A Representational Approach , author=. 2025 , eprint=
2025
-
[66]
2023 , eprint=
Sparks of Artificial General Intelligence: Early experiments with GPT-4 , author=. 2023 , eprint=
2023
-
[67]
Difficulty-Aware Agentic Orchestration for Query-Specific Multi-Agent Workflows , booktitle =
Jinwei Su and Qizhen Lan and Yinghui Xia and Lifan Sun and Weiyou Tian and Tianyu Shi and Lewei He , editor =. Difficulty-Aware Agentic Orchestration for Query-Specific Multi-Agent Workflows , booktitle =. 2026 , url =. doi:10.1145/3774904.3792240 , timestamp =
-
[68]
arXiv preprint arXiv:2502.14815 , year=
Lingjiao Chen and Jared Quincy Davis and Boris Hanin and Peter Bailis and Matei Zaharia and James Zou and Ion Stoica , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.14815 , eprinttype =. 2502.14815 , timestamp =
-
[69]
MasRouter: Learning to Route LLMs for Multi-Agent Systems , booktitle =
Yanwei Yue and Guibin Zhang and Boyang Liu and Guancheng Wan and Kun Wang and Dawei Cheng and Yiyan Qi , editor =. MasRouter: Learning to Route LLMs for Multi-Agent Systems , booktitle =. 2025 , url =
2025
-
[70]
GPTSwarm: Language Agents as Optimizable Graphs , booktitle =
Mingchen Zhuge and Wenyi Wang and Louis Kirsch and Francesco Faccio and Dmitrii Khizbullin and J. GPTSwarm: Language Agents as Optimizable Graphs , booktitle =. 2024 , url =
2024
-
[71]
Ramchand Kumaresan , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.21231 , eprinttype =. 2602.21231 , timestamp =
-
[72]
2018 , eprint=
Scikit-learn: Machine Learning in Python , author=. 2018 , eprint=
2018
-
[73]
2026 , eprint=
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs , author=. 2026 , eprint=
2026
-
[74]
Jasper Dekoninck and Ivo Petrov and Kristian Minchev and Mislav Balunovic and Martin T. Vechev and Miroslav Marinov and Maria Drencheva and Lyuba Konova and Milen Shumanov and Kaloyan Tsvetkov and Nikolay Drenchev and Lazar Todorov and Kalina Nikolova and Nikolay Georgiev and Vanesa Kalinkova and Margulan Ismoldayev , title =. CoRR , volume =. 2025 , url ...
-
[75]
Jiedong Jiang and Wanyi He and Yuefeng Wang and Guoxiong Gao and Yongle Hu and Jingting Wang and Nailing Guan and Peihao Wu and Chunbo Dai and Liang Xiao and Bin Dong , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2511.02872 , eprinttype =. 2511.02872 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.