GNStor: Design of GPU-Native High-Performance Remote All-Flash Array
Pith reviewed 2026-06-28 03:21 UTC · model grok-4.3
The pith
GNStor lets GPUs access remote all-flash arrays directly without CPU involvement to reach 3.2 times higher I/O throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
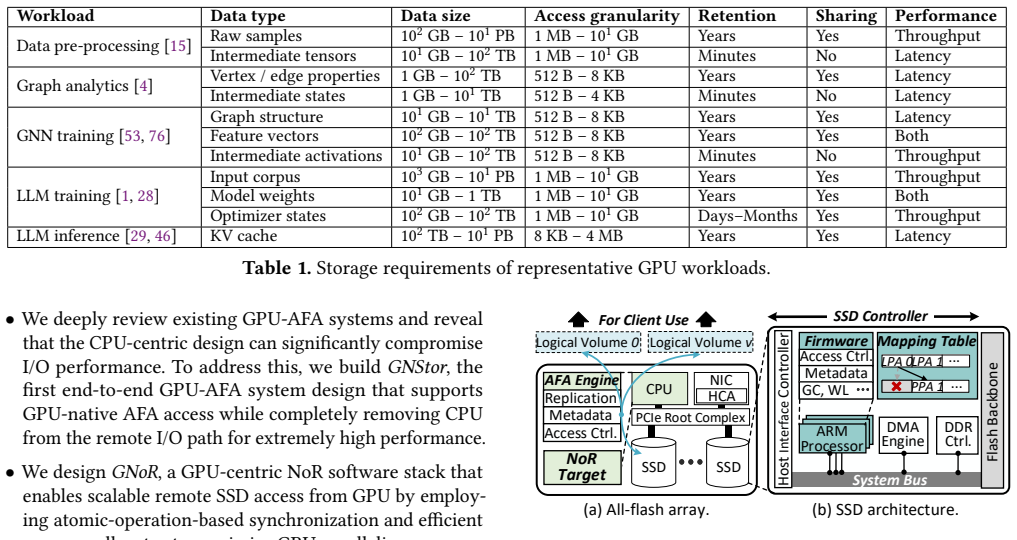
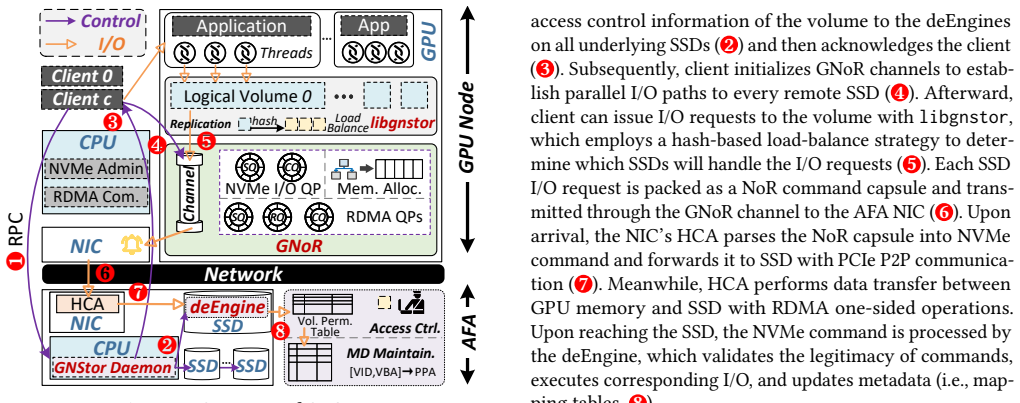
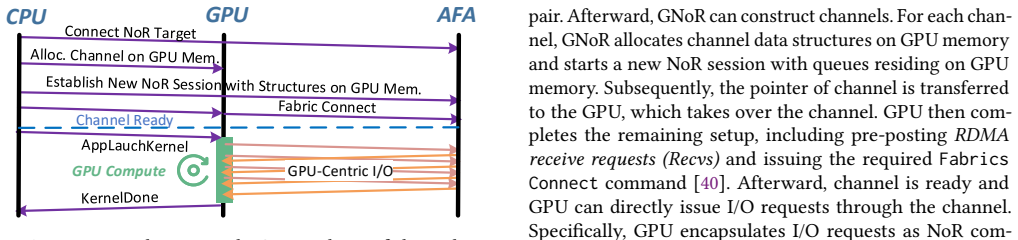
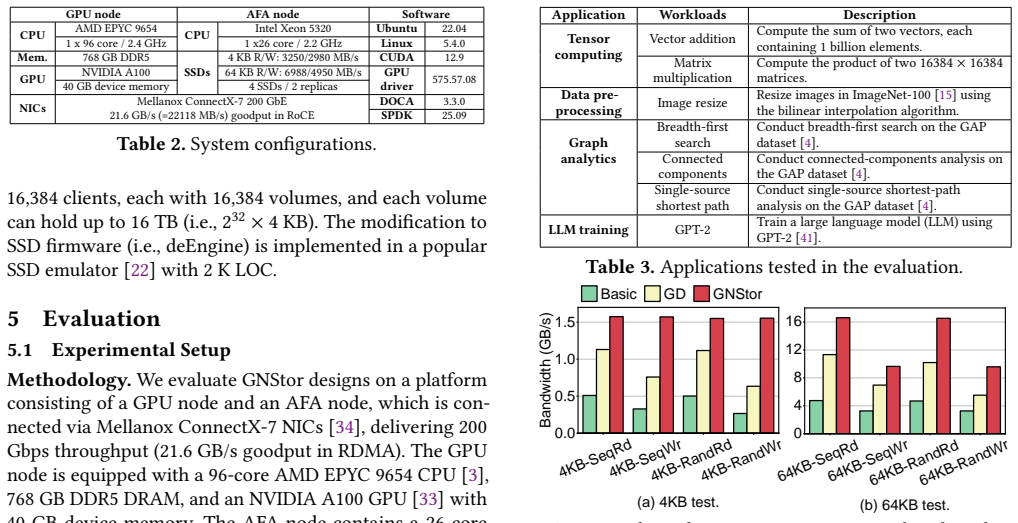
GNStor is a GPU-native remote AFA system built around GNoR, a GPU-centric NVMe over RDMA stack that lets GPUs issue I/O requests directly using atomic operations and the SIMT execution model, and deEngine, which decomposes AFA tasks such as access control and metadata persistence into each SSD firmware. This produces a complete CPU-bypass path while preserving AFA semantics, yielding 3.2 times higher I/O throughput and 31.1 percent shorter application execution times than prior AFA systems.
What carries the argument
GNoR, the GPU-centric NVMe over RDMA stack that orchestrates I/O with atomic operations under the SIMT model, together with deEngine, the decentralized AFA engine placed inside SSD firmware.
If this is right
- GPU applications gain direct use of remote AFA bandwidth without CPU orchestration costs.
- I/O throughput rises by a measured factor of 3.2 compared with current CPU-centric AFA designs.
- End-to-end application run times fall by 31.1 percent under the same workloads.
- AFA-level guarantees remain available even though the CPU is removed from the I/O path.
Where Pith is reading between the lines
- The same CPU-bypass pattern could be tested on other accelerators that currently route storage through a host CPU.
- Clusters built around many GPUs might reduce their total CPU count if storage management moves entirely into the devices.
- Further AFA features could be pushed into SSD firmware to test whether additional performance headroom appears.
Load-bearing premise
Essential AFA functions such as access control and metadata persistence can be decomposed and placed inside SSD firmware while keeping correctness and low overhead in a direct GPU-to-SSD path.
What would settle it
A measurement showing that access-control logic moved into SSD firmware either allows unauthorized access or adds latency that cancels the reported throughput gains would disprove the central claim.
Figures








read the original abstract
GPU has become the leading computing device for a wide range of data-intensive applications, which tightly collaborates with remote all-flash array (AFA) to accommodate ever-expanding datasets, facilitate multi-client data sharing, and guarantee fault tolerance. Although GPU is the center of computation, all I/O processes in existing GPU-AFA systems are still CPU-centric. CPU orchestrates remote I/O requests and executes a centralized AFA engine to take charge of AFA-level functionalities (e.g., access control and metadata persistence). This design disparity suffers from substantial CPU-GPU interaction overhead and I/O traffic amplification, compromising end-to-end I/O performance. In this work, we present \emph{GNStor}, a GPU-native AFA system that enables GPU to directly access remote AFA without CPU intervention in the I/O path, thereby fully exploiting the performance of AFA. Specifically, GNStor first proposes a GPU-centric NVMe over RDMA (NoR) software stack (named \emph{GNoR}), paving a fast path for GPUs to directly initiate NoR I/O requests to SSDs within remote AFA. GNoR employs an atomic-operation-based I/O orchestration design and follows the single-instruction-multiple-thread (SIMT) execution model of GPU, fully exploiting the massive parallelism of GPU architectures. To facilitate essential AFA functionalities in a CPU-bypass I/O path, GNStor further designs \emph{deEngine}, a decentralized AFA engine that seamlessly decomposes and integrates AFA-level tasks into each SSD firmware, thereby achieving efficient AFA access at low cost. Evaluation results show that GNStor achieves 3.2$\times$ higher I/O throughput and reduces application execution time by 31.1\%, compared to state-of-the-art AFA systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GNStor, a GPU-native remote all-flash array (AFA) design that enables direct GPU-initiated I/O to remote SSDs without CPU intervention in the data path. It introduces GNoR, a GPU-centric NVMe over RDMA software stack using atomic operations and SIMT execution, and deEngine, a decentralized AFA engine that decomposes tasks such as access control and metadata persistence into per-SSD firmware. The central claim is that this CPU-bypass architecture delivers 3.2× higher I/O throughput and reduces application execution time by 31.1% versus state-of-the-art AFA systems.
Significance. If the performance numbers and correctness of the decentralized engine hold under realistic multi-client workloads, the work would represent a meaningful shift from CPU-orchestrated to GPU-direct remote storage for data-intensive GPU applications, potentially reducing interaction overhead and traffic amplification in GPU-AFA co-designs.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The specific claims of 3.2× throughput improvement and 31.1% execution-time reduction are stated without any description of experimental setup, baselines, workloads, hardware configuration, or error bars. This absence makes the central performance result unverifiable from the provided text and is load-bearing for the paper's contribution.
- [deEngine design] deEngine design (architecture section): The claim that essential AFA functionalities including access control and metadata persistence can be fully decomposed and integrated into individual SSD firmware while preserving correctness in a CPU-bypass path lacks a concrete mechanism for cross-device atomicity, policy replication, or power-loss persistence. If these cannot be handled without races or hidden CPU fallbacks, the reported throughput gains are at risk.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point by point below and outline the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The specific claims of 3.2× throughput improvement and 31.1% execution-time reduction are stated without any description of experimental setup, baselines, workloads, hardware configuration, or error bars. This absence makes the central performance result unverifiable from the provided text and is load-bearing for the paper's contribution.
Authors: We agree that the abstract would benefit from a brief mention of the experimental context to improve immediate verifiability of the central claims. The full evaluation section provides details on the hardware platform (GPU and remote AFA configuration), baselines (state-of-the-art CPU-centric AFA systems), workloads, and reports results with error bars from repeated runs. In the revised version we will expand the abstract with a concise experimental overview and ensure the evaluation section opens with an explicit setup subsection. revision: yes
-
Referee: [deEngine design] deEngine design (architecture section): The claim that essential AFA functionalities including access control and metadata persistence can be fully decomposed and integrated into individual SSD firmware while preserving correctness in a CPU-bypass path lacks a concrete mechanism for cross-device atomicity, policy replication, or power-loss persistence. If these cannot be handled without races or hidden CPU fallbacks, the reported throughput gains are at risk.
Authors: We acknowledge that the current architecture description would be strengthened by additional concrete mechanisms. The deEngine design relies on per-SSD firmware extensions coordinated via GPU-initiated RDMA atomics, but explicit details on cross-device atomicity (e.g., distributed locking), policy replication, and power-loss persistence (e.g., journaling) are not fully elaborated. We will add a dedicated subsection in the revised architecture section that specifies these mechanisms, discusses potential race conditions, and clarifies that no hidden CPU fallbacks are used in the data path. revision: yes
Circularity Check
No circularity: systems design with external evaluation
full rationale
The paper presents an architectural design (GNoR stack and deEngine decomposition) and reports measured throughput gains from implementation and benchmarking. No equations, fitted parameters, or predictions appear; performance claims rest on described hardware/software changes evaluated against external baselines rather than any self-referential reduction or self-citation chain. The central claim is therefore independent of its own inputs.
Axiom & Free-Parameter Ledger
invented entities (2)
-
GNoR
no independent evidence
-
deEngine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
Jinwoo Ahn, Donggyu Park, Chang-Gyu Lee, Donghyun Min, Junghee Lee, Sungyong Park, Qian Chen, and Youngjae Kim. Key-ssd: Access- control drive to protect files from ransomware attacks.arXiv preprint arXiv:1904.05012, 2019
Pith/arXiv arXiv 1904
-
[3]
Epyc™9654.https://www .amd.com/en/products/processors/ server/epyc/4th-generation-9004-and-8004-series/amd-epyc- 9654.html
AMD. Epyc™9654.https://www .amd.com/en/products/processors/ server/epyc/4th-generation-9004-and-8004-series/amd-epyc- 9654.html
-
[4]
The gap bench- mark suite, 2017
Scott Beamer, Krste Asanović, and David Patterson. The gap bench- mark suite, 2017
2017
-
[5]
Spin: Seamless operating system integration of peer-to-peer dma be- tween ssds and gpus.ACM Transactions on Computer Systems (TOCS), 36(2):1–26, 2019
Shai Bergman, Tanya Brokhman, Tzachi Cohen, and Mark Silberstein. Spin: Seamless operating system integration of peer-to-peer dma be- tween ssds and gpus.ACM Transactions on Computer Systems (TOCS), 36(2):1–26, 2019
2019
-
[6]
O’Reilly Media, Inc
John Bloomer.Power programming with RPC. " O’Reilly Media, Inc. ", 1992
1992
-
[7]
Recom- mender systems: An overview.Ai Magazine, 32(3):13–18, 2011
Robin Burke, Alexander Felfernig, and Mehmet H Göker. Recom- mender systems: An overview.Ai Magazine, 32(3):13–18, 2011
2011
-
[8]
Nvme over fabrics user space initiator library.https: //github.com/bytedance/libnvmf, 2024
Bytedance. Nvme over fabrics user space initiator library.https: //github.com/bytedance/libnvmf, 2024
2024
-
[9]
Efficient distributed memory management with rdma and caching
Qingchao Cai, Wentian Guo, Hao Zhang, Divyakant Agrawal, Gang Chen, Beng Chin Ooi, Kian-Lee Tan, Yong Meng Teo, and Sheng Wang. Efficient distributed memory management with rdma and caching. Proceedings of the VLDB Endowment, 11(11):1604–1617, 2018
2018
-
[10]
Hyq: Hybrid i/o queue architecture for nvme over fabrics to enable high- performance hardware offloading
Yiquan Chen, Jinlong Chen, Yijing Wang, Yi Chen, Zhen Jin, Jiexiong Xu, Guoju Fang, Wenhai Lin, Chengkun Wei, and Wenzhi Chen. Hyq: Hybrid i/o queue architecture for nvme over fabrics to enable high- performance hardware offloading. In2023 IEEE/ACM 23rd International Symposium on Cluster, Cloud and Internet Computing (CCGrid), pages 13–24. IEEE, 2023
2023
-
[11]
A lightweight, gpu-based software raid system
Matthew L Curry, H Lee Ward, Anthony Skjellum, and Ron Brightwell. A lightweight, gpu-based software raid system. In2010 39th Interna- tional Conference on Parallel Processing, pages 565–572. IEEE, 2010
2010
-
[12]
Fire-flyer file system.https://github .com/deepseek-ai/3fs, 2026
DeepSeek. Fire-flyer file system.https://github .com/deepseek-ai/3fs, 2026
2026
-
[13]
Powerstore 500t storage array.https:// www.delltechnologies.com/asset/en-ca/products/storage/technical- support/dell-powerstore-gen2-spec-sheet.pdf, 2023
DELL. Powerstore 500t storage array.https:// www.delltechnologies.com/asset/en-ca/products/storage/technical- support/dell-powerstore-gen2-spec-sheet.pdf, 2023
2023
-
[14]
A survey of llm datasets: From autoregressive model to ai chatbot.Journal of Computer Science and Technology, 39(3):542–566, 2024
Fei Du, Xin-Jian Ma, Jing-Ru Yang, Yi Liu, Chao-Ran Luo, Xue-Bin Wang, Hai-Ou Jiang, and Xiang Jing. A survey of llm datasets: From autoregressive model to ai chatbot.Journal of Computer Science and Technology, 39(3):542–566, 2024
2024
-
[15]
Imagenet-100.https://huggingface .co/datasets/clane9/ imagenet-100
Hugging Face. Imagenet-100.https://huggingface .co/datasets/clane9/ imagenet-100
-
[16]
The recovery manager of the system r database manager.ACM Computing Surveys (CSUR), 13(2):223–242, 1981
Jim Gray, Paul McJones, Mike Blasgen, Bruce Lindsay, Raymond Lorie, Tom Price, Franco Putzolu, and Irving Traiger. The recovery manager of the system r database manager.ACM Computing Surveys (CSUR), 13(2):223–242, 1981
1981
-
[17]
A novel approach to real-time bilinear interpolation
Kim T Gribbon and Donald G Bailey. A novel approach to real-time bilinear interpolation. InProceedings. DELTA 2004. Second IEEE in- ternational workshop on electronic design, test and applications, pages 126–131. IEEE, 2004
2004
-
[18]
Intel®xeon®gold 5320 processor.https://www .intel.com/ content/www/us/en/products/sku/215285/intel-xeon-gold-5320- processor-39m-cache-2-20-ghz/specifications.html
Intel. Intel®xeon®gold 5320 processor.https://www .intel.com/ content/www/us/en/products/sku/215285/intel-xeon-gold-5320- processor-39m-cache-2-20-ghz/specifications.html
-
[19]
Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web
David Karger, Eric Lehman, Tom Leighton, Rina Panigrahy, Matthew Levine, and Daniel Lewin. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. InProceedings of the twenty-ninth annual ACM symposium on Theory of computing, pages 654–663, 1997
1997
-
[20]
On the use of gpus in realizing cost-effective distributed raid
Aleksandr Khasymski, M Mustafa Rafique, Ali R Butt, Sudharshan S Vazhkudai, and Dimitrios S Nikolopoulos. On the use of gpus in realizing cost-effective distributed raid. In2012 IEEE 20th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, pages 469–478. IEEE, 2012
2012
-
[21]
{D2FS}:{Device-Driven} filesystem garbage collection
Juwon Kim, Seungjae Lee, Joontaek Oh, Dongkun Shin, and Youjip Won. {D2FS}:{Device-Driven} filesystem garbage collection. In23rd USENIX Conference on File and Storage Technologies (FAST 25), pages 337–353, 2025
2025
-
[22]
{NVMeVirt}: A versatile software- defined virtual {NVMe} device
Sang-Hoon Kim, Jaehoon Shim, Euidong Lee, Seongyeop Jeong, Ilkueon Kang, and Jin-Soo Kim. {NVMeVirt}: A versatile software- defined virtual {NVMe} device. In21st USENIX Conference on File and Storage Technologies (FAST 23), pages 379–394, 2023
2023
-
[23]
Fessd: A fast encrypted ssd employing on-chip access-control memory.IEEE Computer Architecture Letters, 16(2):115–118, 2017
Junghee Lee, Kalidas Ganesh, Hyuk-Jun Lee, and Youngjae Kim. Fessd: A fast encrypted ssd employing on-chip access-control memory.IEEE Computer Architecture Letters, 16(2):115–118, 2017
2017
-
[24]
Gpu snapshot: check- point offloading for gpu-dense systems
Kyushick Lee, Michael B Sullivan, Siva Kumar Sastry Hari, Timothy Tsai, Stephen W Keckler, and Mattan Erez. Gpu snapshot: check- point offloading for gpu-dense systems. InProceedings of the ACM International Conference on Supercomputing, pages 171–183, 2019
2019
-
[25]
{RubbleDB}:{CPU-Efficient} replica- tion with {NVMe-oF}
Haoyu Li, Sheng Jiang, Chen Chen, Ashwini Raina, Xingyu Zhu, Changxu Luo, and Asaf Cidon. {RubbleDB}:{CPU-Efficient} replica- tion with {NVMe-oF}. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 689–703, 2023
2023
-
[26]
Man- aging scalable direct storage accesses for gpus with gofs
Shaobo Li, Yirui Eric Zhou, Yuqi Xue, Yuan Xu, and Jian Huang. Man- aging scalable direct storage accesses for gpus with gofs. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 979–995, 2025
2025
-
[27]
Cognitive {SSD}: A deep learning engine for{In-Storage} data retrieval
Shengwen Liang, Ying Wang, Youyou Lu, Zhe Yang, Huawei Li, and Xiaowei Li. Cognitive {SSD}: A deep learning engine for{In-Storage} data retrieval. In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 395–410, 2019
2019
-
[28]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[29]
Lmcache: An efficient kv cache layer for enterprise-scale llm inference
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al. Lmcache: An efficient kv cache layer for enterprise-scale llm inference. 13 arXiv preprint arXiv:2510.09665, 2025
arXiv 2025
-
[30]
Smar- tio: Zero-overhead device sharing through pcie networking.ACM Transactions on Computer Systems (TOCS), 38(1-2):1–78, 2021
Jonas Markussen, Lars Bjørlykke Kristiansen, Pål Halvorsen, Halvor Kielland-Gyrud, Håkon Kvale Stensland, and Carsten Griwodz. Smar- tio: Zero-overhead device sharing through pcie networking.ACM Transactions on Computer Systems (TOCS), 38(1-2):1–78, 2021
2021
-
[31]
Springer Science & Business Media, 2010
Rino Micheloni, Luca Crippa, and Alessia Marelli.Inside NAND flash memories. Springer Science & Business Media, 2010
2010
-
[32]
A lightweight infrastructure for graph analytics
Donald Nguyen, Andrew Lenharth, and Keshav Pingali. A lightweight infrastructure for graph analytics. InProceedings of the twenty-fourth ACM symposium on operating systems principles, pages 456–471, 2013
2013
-
[33]
A100 tensor core gpu.https://www .nvidia.com/en-us/data- center/a100/
NVIDIA. A100 tensor core gpu.https://www .nvidia.com/en-us/data- center/a100/
-
[34]
Connectx-7.https://www .nvidia.com/content/dam/en- zz/Solutions/networking/ethernet-adapters/connectx-7-datasheet- Final.pdf, 2021
NVIDIA. Connectx-7.https://www .nvidia.com/content/dam/en- zz/Solutions/networking/ethernet-adapters/connectx-7-datasheet- Final.pdf, 2021
2021
-
[35]
NVIDIA. Advancing memory and storage architectures for next-gen ai workloads.https://files .futurememorystorage.com/proceedings/2025/ 20250807_OPSW-301-1_Mailthody-2025-08-07-15.14.33.pdf, 2025
2025
-
[36]
Cuda toolkit.https://developer .nvidia.com/cuda/toolkit, 2025
NVIDIA. Cuda toolkit.https://developer .nvidia.com/cuda/toolkit, 2025
2025
-
[37]
Doca software framework.https://developer .nvidia.com/ networking/doca, 2025
NVIDIA. Doca software framework.https://developer .nvidia.com/ networking/doca, 2025
2025
-
[38]
Gpudirect.https://developer.nvidia.com/gpudirect, 2026
NVIDIA. Gpudirect.https://developer.nvidia.com/gpudirect, 2026
2026
-
[39]
Nvm command set specification.https://nvmexpress .org/ specification/nvm-command-set-specification/, 2025
NVMe. Nvm command set specification.https://nvmexpress .org/ specification/nvm-command-set-specification/, 2025
2025
-
[40]
Nvm express base specification 2.3.https://nvmexpress .org/ specification/nvm-express-base-specification/, 2025
NVMe. Nvm express base specification 2.3.https://nvmexpress .org/ specification/nvm-express-base-specification/, 2025
2025
-
[41]
Gpt-2.https://github.com/openai/gpt-2
OpenAI. Gpt-2.https://github.com/openai/gpt-2
-
[42]
Cuckoo hashing.Journal of Algorithms, 51(2):122–144, 2004
Rasmus Pagh and Flemming Friche Rodler. Cuckoo hashing.Journal of Algorithms, 51(2):122–144, 2004
2004
-
[43]
Multi-gpu graph analytics
Yuechao Pan, Yangzihao Wang, Yuduo Wu, Carl Yang, and John D Owens. Multi-gpu graph analytics. In2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 479–490. IEEE, 2017
2017
-
[44]
Optimizing memory-mapped {I/O} for fast storage devices
Anastasios Papagiannis, Giorgos Xanthakis, Giorgos Saloustros, Mano- lis Marazakis, and Angelos Bilas. Optimizing memory-mapped {I/O} for fast storage devices. In2020 USENIX Annual Technical Conference (USENIX ATC 20), pages 813–827, 2020
2020
-
[45]
Energy-aware gpu-raid scheduling for reducing energy consumption in cloud storage sys- tems
Mehdi Pirahandeh and Deok-Hwan Kim. Energy-aware gpu-raid scheduling for reducing energy consumption in cloud storage sys- tems. InComputer Science and its Applications: Ubiquitous Information Technologies, pages 705–711. Springer, 2015
2015
-
[46]
Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX conference on file and storage technologies (FAST 25), pages 155–170, 2025
2025
-
[47]
{GeminiFS}: A com- panion file system for {GPUs }
Shi Qiu, Weinan Liu, Yifan Hu, Jianqin Yan, Zhirong Shen, Xin Yao, Renhai Chen, Gong Zhang, and Yiming Zhang. {GeminiFS}: A com- panion file system for {GPUs }. In23rd USENIX Conference on File and Storage Technologies (FAST 25), pages 221–236, 2025
2025
-
[48]
Gpu-initiated on-demand high-throughput storage access in the bam system architecture
Zaid Qureshi, Vikram Sharma Mailthody, Isaac Gelado, Seungwon Min, Amna Masood, Jeongmin Park, Jinjun Xiong, Chris J Newburn, Dmitri Vainbrand, I-Hsin Chung, et al. Gpu-initiated on-demand high-throughput storage access in the bam system architecture. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Language...
2023
-
[49]
Recommender systems.Communica- tions of the ACM, 40(3):56–58, 1997
Paul Resnick and Hal R Varian. Recommender systems.Communica- tions of the ACM, 40(3):56–58, 1997
1997
-
[50]
Samsung. Power loss protection (plp) protect your data against sudden power loss.https://download .semiconductor.samsung.com/resources/ others/Samsung_SSD_845DC_05_Power_loss_protection_PLP.pdf, 2014
2014
-
[51]
980pro nvme ssd.https://www .samsung.com/us/ computing/memory-storage/solid-state-drives/980-pro-pcie-4-0- nvme-ssd-1tb-mz-v8p1t0b-am/, 2020
Samsung. 980pro nvme ssd.https://www .samsung.com/us/ computing/memory-storage/solid-state-drives/980-pro-pcie-4-0- nvme-ssd-1tb-mz-v8p1t0b-am/, 2020
2020
-
[52]
Samsung pm1743.https://semiconductor .samsung.com/ ssd/enterprise-ssd/pm1743/, 2023
Samsung. Samsung pm1743.https://semiconductor .samsung.com/ ssd/enterprise-ssd/pm1743/, 2023
2023
-
[53]
Distributed graph neural network training: A survey.ACM Computing Surveys, 56(8):1–39, 2024
Yingxia Shao, Hongzheng Li, Xizhi Gu, Hongbo Yin, Yawen Li, Xupeng Miao, Wentao Zhang, Bin Cui, and Lei Chen. Distributed graph neural network training: A survey.ACM Computing Surveys, 56(8):1–39, 2024
2024
-
[54]
Cam: Asyn- chronous gpu-initiated, cpu-managed ssd management for batching storage access
Ziyu Song, Jie Zhang, Jie Sun, Mo Sun, Zihan Yang, Zheng Zhang, Xuzheng Chen, Fei Wu, Huajin Tang, and Zeke Wang. Cam: Asyn- chronous gpu-initiated, cpu-managed ssd management for batching storage access. In2025 IEEE 41st International Conference on Data Engineering (ICDE), pages 2309–2322. IEEE, 2025
2025
-
[55]
Storage performance development kit.https://spdk.io, 2025
SPDK. Storage performance development kit.https://spdk.io, 2025
2025
-
[56]
Selective buddy allocation for scheduling parallel jobs on clusters
Vijay Subramani, Rajkumar Kettimuthu, Srividya Srinivasan, Jeanette Johnston, and P Sadayappan. Selective buddy allocation for scheduling parallel jobs on clusters. InProceedings. IEEE International Conference on Cluster Computing, pages 107–116. IEEE, 2002
2002
-
[57]
Scalio: Scaling up {DPU-based } {JBOF} key-value store with {NVMe-oF} target offload
Xun Sun, Mingxing Zhang, Yingdi Shan, Kang Chen, Jinlei Jiang, and Yongwei Wu. Scalio: Scaling up {DPU-based } {JBOF} key-value store with {NVMe-oF} target offload. In19th USENIX Symposium on Op- erating Systems Design and Implementation (OSDI 25), pages 449–464, 2025
2025
-
[58]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[59]
T-lease: A trusted lease primitive for distributed systems
Bohdan Trach, Rasha Faqeh, Oleksii Oleksenko, Wojciech Ozga, Pramod Bhatotia, and Christof Fetzer. T-lease: A trusted lease primitive for distributed systems. InProceedings of the 11th ACM Symposium on Cloud Computing, pages 387–400, 2020
2020
-
[60]
The land- scape of gpu-centric communication.arXiv preprint arXiv:2409.09874, 2024
Didem Unat, Ilyas Turimbetov, Mohammed Kefah Taha Issa, Doğan Sağbili, Flavio Vella, Daniele De Sensi, and Ismayil Ismayilov. The land- scape of gpu-centric communication.arXiv preprint arXiv:2409.09874, 2024
Pith/arXiv arXiv 2024
-
[61]
Lock-free linked lists using compare-and-swap
John D Valois. Lock-free linked lists using compare-and-swap. In Proceedings of the fourteenth annual ACM symposium on Principles of distributed computing, pages 214–222, 1995
1995
-
[62]
{FineMem}: Breaking the allocation overhead vs
Xiaoyang Wang, Yongkun Li, Kan Wu, Wenzhe Zhu, Yuqi Li, and Yin- long Xu. {FineMem}: Breaking the allocation overhead vs. memory waste dilemma in {Fine-Grained} disaggregated memory manage- ment. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 57–74, 2025
2025
-
[63]
Gunrock: Gpu graph analytics.ACM Transactions on Parallel Computing (TOPC), 4(1):1–49, 2017
Yangzihao Wang, Yuechao Pan, Andrew Davidson, Yuduo Wu, Carl Yang, Leyuan Wang, Muhammad Osama, Chenshan Yuan, Weitang Liu, Andy T Riffel, et al. Gunrock: Gpu graph analytics.ACM Transactions on Parallel Computing (TOPC), 4(1):1–49, 2017
2017
-
[64]
Merlin hugectr: Gpu-accelerated recommender system training and inference
Zehuan Wang, Yingcan Wei, Minseok Lee, Matthias Langer, Fan Yu, Jie Liu, Shijie Liu, Daniel G Abel, Xu Guo, Jianbing Dong, et al. Merlin hugectr: Gpu-accelerated recommender system training and inference. InProceedings of the 16th ACM Conference on Recommender Systems, pages 534–537, 2022
2022
-
[65]
Crush: Controlled, scalable, decentralized placement of replicated data
Sage A Weil, Scott A Brandt, Ethan L Miller, and Carlos Maltzahn. Crush: Controlled, scalable, decentralized placement of replicated data. InProceedings of the 2006 ACM/IEEE conference on Supercomputing, pages 122–es, 2006
2006
-
[66]
Eliminating storage management over- head of deduplication over ssd arrays through a hardware/software co-design
Yuhong Wen, Xiaogang Zhao, You Zhou, Tong Zhang, Shangjun Yang, Changsheng Xie, and Fei Wu. Eliminating storage management over- head of deduplication over ssd arrays through a hardware/software co-design. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 320–335, 2024
2024
-
[67]
{D2FQ}:{Device-Direct}fair queueing for{NVMe} {SSDs}
Jiwon Woo, Minwoo Ahn, Gyusun Lee, and Jinkyu Jeong. {D2FQ}:{Device-Direct}fair queueing for{NVMe} {SSDs}. In19th 14 GNStor Arxiv, June 2026, Online USENIX Conference on File and Storage Technologies (FAST 21), pages 403–415, 2021
2026
-
[68]
Understanding and exploiting the full potential of ssd address remapping.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 41(11):5112–5125, 2022
Qiulin Wu, You Zhou, Fei Wu, Hong Jiang, Jian Zhou, and Changsheng Xie. Understanding and exploiting the full potential of ssd address remapping.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 41(11):5112–5125, 2022
2022
-
[69]
Kintex™ultrascale+™fpgas.https://www .amd.com/ en/products/adaptive-socs-and-fpgas/fpga/kintex-ultrascale- plus.html
XILINX. Kintex™ultrascale+™fpgas.https://www .amd.com/ en/products/adaptive-socs-and-fpgas/fpga/kintex-ultrascale- plus.html
-
[70]
Perfor- mance characterization of smartnic nvme-over-fabrics target offload- ing
Jiexiong Xu, Yue Qiu, Yiquan Chen, Yijing Wang, Wenhai Lin, Yiquan Lin, Shushu Zhao, Yuqi Liu, Ying Wang, and Wenzhi Chen. Perfor- mance characterization of smartnic nvme-over-fabrics target offload- ing. InProceedings of the 17th ACM International Systems and Storage Conference, pages 14–24, 2024
2024
-
[71]
On-demand and parallel checkpoint/restore for gpu applications
Yanning Yang, Dong Du, Haitao Song, and Yubin Xia. On-demand and parallel checkpoint/restore for gpu applications. InProceedings of the 2024 ACM Symposium on Cloud Computing, pages 415–433, 2024
2024
-
[72]
{𝜆-IO}: A unified {IO} stack for computational storage
Zhe Yang, Youyou Lu, Xiaojian Liao, Youmin Chen, Junru Li, Siyu He, and Jiwu Shu. {𝜆-IO}: A unified {IO} stack for computational storage. In21st USENIX Conference on File and Storage Technologies (FAST 23), pages 347–362, 2023
2023
-
[73]
ScalaAFA: Constructing User-Space All-Flash array engine with holistic designs
Shushu Yi, Xiurui Pan, Qiao Li, Qiang Li, Chenxi Wang, Bo Mao, Myoungsoo Jung, and Jie Zhang. ScalaAFA: Constructing User-Space All-Flash array engine with holistic designs. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 141–156, Santa Clara, CA, July 2024. USENIX Association
2024
-
[74]
{GPU } {Checkpoint/Restore} made fast and lightweight
Shaoxun Zeng, Tingxu Ren, Jiwu Shu, and Youyou Lu. {GPU } {Checkpoint/Restore} made fast and lightweight. In 24th USENIX Conference on File and Storage Technologies (FAST 26), pages 239–254, 2026
2026
-
[75]
Nvmmu: A non-volatile memory management unit for heterogeneous gpu-ssd architectures
Jie Zhang, David Donofrio, John Shalf, Mahmut T Kandemir, and Myoungsoo Jung. Nvmmu: A non-volatile memory management unit for heterogeneous gpu-ssd architectures. In2015 International Conference on Parallel Architecture and Compilation (PACT), pages 13–24. IEEE, 2015
2015
-
[76]
Bytegnn: efficient graph neural network training at large scale.Pro- ceedings of the VLDB Endowment, 15(6):1228–1242, 2022
Chenguang Zheng, Hongzhi Chen, Yuxuan Cheng, Zhezheng Song, Yifan Wu, Changji Li, James Cheng, Hao Yang, and Shuai Zhang. Bytegnn: efficient graph neural network training at large scale.Pro- ceedings of the VLDB Endowment, 15(6):1228–1242, 2022
2022
-
[77]
{Remap-SSD}: Safely and efficiently exploiting {SSD} address remapping to eliminate duplicate writes
You Zhou, Qiulin Wu, Fei Wu, Hong Jiang, Jian Zhou, and Changsheng Xie. {Remap-SSD}: Safely and efficiently exploiting {SSD} address remapping to eliminate duplicate writes. In19th USENIX Conference on File and Storage Technologies (FAST 21), pages 187–202, 2021
2021
-
[78]
Toolqa: A dataset for llm question answering with external tools.Ad- vances in Neural Information Processing Systems, 36:50117–50143, 2023
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. Toolqa: A dataset for llm question answering with external tools.Ad- vances in Neural Information Processing Systems, 36:50117–50143, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.