Can Crowdsourcing Survive the LLM Era? A Community Survey on Human Data Collection
Pith reviewed 2026-06-28 06:14 UTC · model grok-4.3
The pith
A survey of 155 NLP researchers finds 44 percent have observed LLM-generated responses in crowdsourced data, with awareness high but mitigation steps insufficient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Survey responses show that the research community is aware of LLM use in crowdsourced free-text collection and is taking some measures, but existing efforts remain insufficient to fully address the problem; the authors therefore derive a set of considerations to guide future data collection.
What carries the argument
The community survey instrument that collected self-reported experiences, detection methods, and opinions on LLM contamination from 155 NLP researchers.
If this is right
- Detection will continue to rely mainly on textual style and speed signals until stronger methods are adopted.
- Data quality concerns will persist in any project that collects free-text responses without additional safeguards.
- Future crowdsourcing protocols should incorporate the considerations derived in the paper to reduce contamination risk.
- Half of practitioners still lack clear guidance on precautions, indicating a need for shared best practices.
Where Pith is reading between the lines
- If the survey pattern holds, datasets collected without verification steps may contain growing fractions of model-generated text that affect downstream model training and evaluation.
- The same detection challenges could appear in other domains that rely on human text input, such as user studies or annotation for non-NLP tasks.
- One testable extension would be to apply automated style or timing classifiers to existing public crowdsourced datasets and compare results against the survey's reported prevalence.
Load-bearing premise
The 155 respondents accurately represent the broader NLP research community and can reliably detect and self-report instances of LLM usage in crowdsourced data.
What would settle it
A follow-up experiment that plants known LLM-generated answers into real crowdsourcing tasks and measures whether researchers using the reported detection strategies (style patterns and completion times) identify them at the rates stated in the survey.
Figures

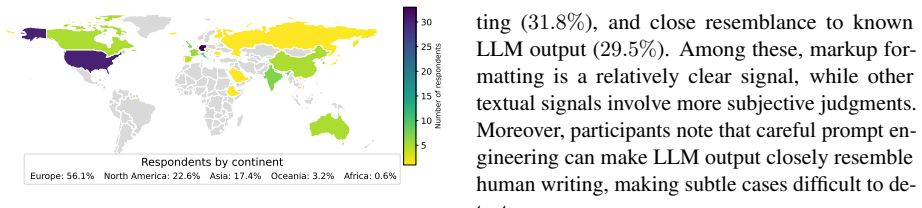
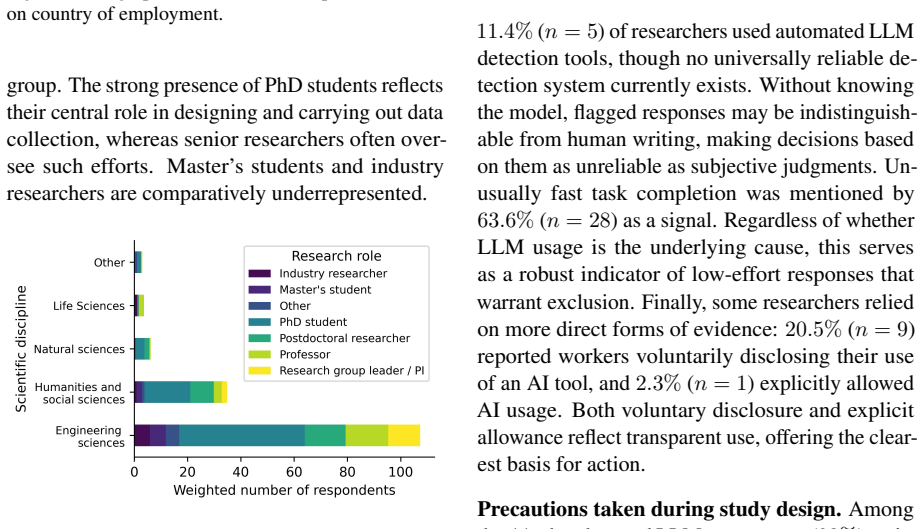
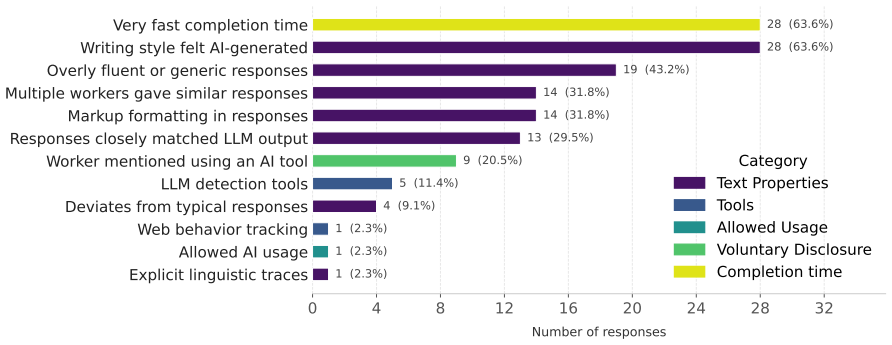
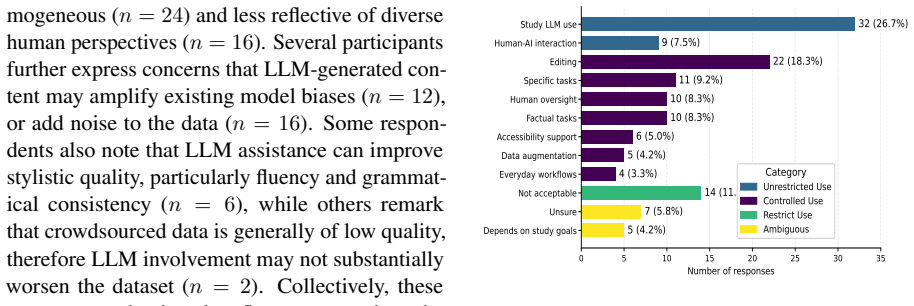

read the original abstract
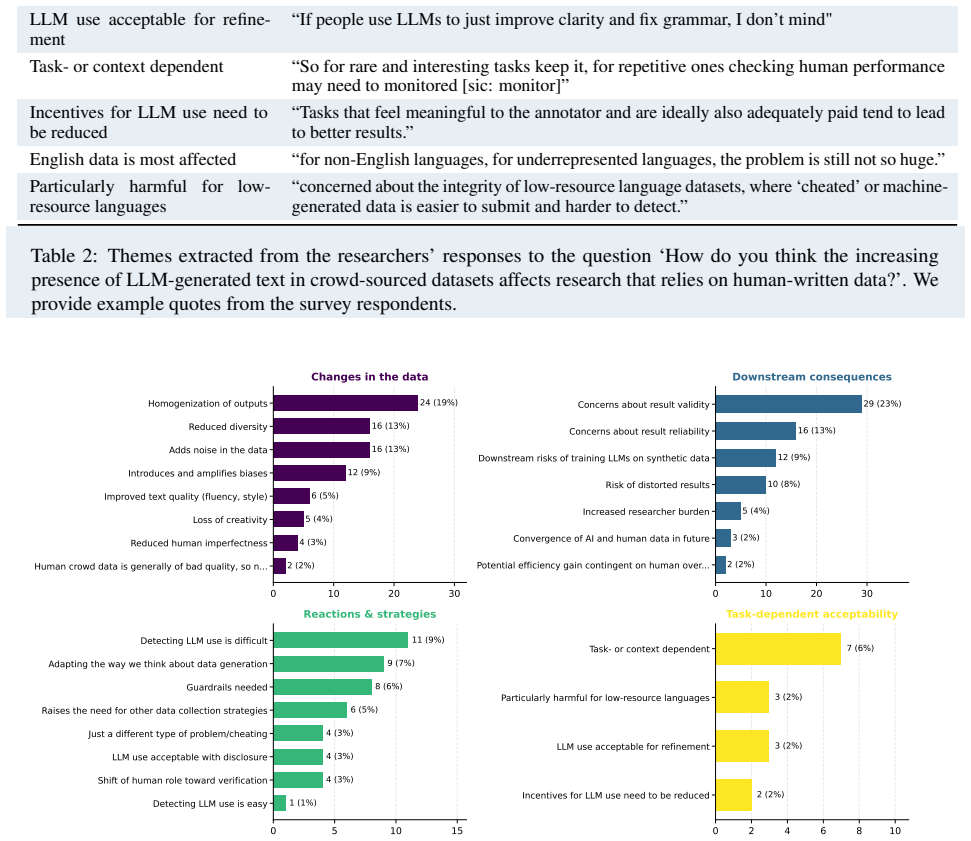
The widespread use of Large Language Models (LLMs) as writing tools challenges the validity of crowdsourced data, as crowdworkers may outsource tasks to models. To better understand how this is addressed, we surveyed 155 researchers in NLP and related disciplines about their experiences and opinions on collecting free-text responses via crowdsourcing. This paper provides an overview of practitioners' challenges, mitigation strategies, and the foreseen implications on data quality. 44% of respondents reported observing LLM usage in their crowdsourced data. While 93% of them had anticipated this, half were unsure what precautions to take. The most prevalent detection strategies are distinctive textual style patterns and unusually fast completion times. Overall, survey responses show that the research community is aware of the problem and taking measures, but existing efforts remain insufficient to fully address it. Finally, we derive a set of considerations to guide future crowdsourced free-text data collection in the era of LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a survey of 155 NLP and related researchers on experiences with LLM usage in crowdsourced free-text data collection. It states that 44% observed such usage (with 93% having anticipated it), half were unsure about precautions, common detection methods are textual style and completion time, and concludes that while the community shows awareness and is taking measures, these efforts remain insufficient; the paper derives considerations to guide future crowdsourced data collection.
Significance. If the survey sample is representative and self-reports are reliable, the work offers a timely snapshot of community practices and gaps around LLM contamination in human data, which could help shape standards for data quality in NLP. The derived considerations provide a concrete starting point for practitioners.
major comments (3)
- [Abstract / Survey description] The abstract and survey description supply no information on recruitment method, distribution channels, response rate, or respondent demographics (e.g., experience level, subfield). Without these, the claim that 'the research community is aware... but existing efforts remain insufficient' cannot be extrapolated from the 155 responses, as self-selection bias toward LLM-concerned researchers is a plausible confound.
- [Results on detection strategies] The 44% observation rate and the 'insufficient' assessment rest on unvalidated self-reports of LLM detection. The paper notes reliance on 'distinctive textual style patterns and unusually fast completion times,' yet provides no evidence or discussion of the known high error rates of these heuristics against current LLMs, nor any objective validation (e.g., via controlled tests or expert annotation).
- [Discussion / Conclusion] The central conclusion that efforts are 'insufficient' is not operationalized. No criteria are given for what would count as sufficient mitigation, nor is there quantification of the 'measures' respondents report taking, making the insufficiency judgment difficult to evaluate or falsify.
minor comments (2)
- [Methods] Clarify the exact survey instrument (full question list) and any pre-testing or piloting performed.
- [Discussion] Add a limitations subsection that explicitly addresses potential biases in self-reported LLM usage.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important aspects of survey methodology and interpretation. We address each point below and will revise the manuscript accordingly to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract / Survey description] The abstract and survey description supply no information on recruitment method, distribution channels, response rate, or respondent demographics (e.g., experience level, subfield). Without these, the claim that 'the research community is aware... but existing efforts remain insufficient' cannot be extrapolated from the 155 responses, as self-selection bias toward LLM-concerned researchers is a plausible confound.
Authors: We agree that methodological details are necessary to evaluate potential biases. The manuscript's Survey Design section describes recruitment through NLP mailing lists, Twitter, and personal networks, but we will expand it with exact response rate (tracked via survey platform), full demographic breakdowns (e.g., experience levels and subfields), and an explicit limitations subsection on self-selection. These additions will allow readers to assess generalizability without altering the core claims. revision: yes
-
Referee: [Results on detection strategies] The 44% observation rate and the 'insufficient' assessment rest on unvalidated self-reports of LLM detection. The paper notes reliance on 'distinctive textual style patterns and unusually fast completion times,' yet provides no evidence or discussion of the known high error rates of these heuristics against current LLMs, nor any objective validation (e.g., via controlled tests or expert annotation).
Authors: The survey intentionally captures practitioners' reported detection practices rather than providing objective validation of those methods. We will add a dedicated paragraph in the Discussion section reviewing literature on the limitations and error rates of style- and time-based heuristics for LLM detection. This contextualizes the findings while preserving the survey's focus on community experiences; we do not claim the 44% rate is objectively verified. revision: yes
-
Referee: [Discussion / Conclusion] The central conclusion that efforts are 'insufficient' is not operationalized. No criteria are given for what would count as sufficient mitigation, nor is there quantification of the 'measures' respondents report taking, making the insufficiency judgment difficult to evaluate or falsify.
Authors: We will revise the Conclusion to operationalize 'insufficient' by tying it directly to specific results: the 50% of respondents unsure about precautions and the heavy reliance on basic heuristics (with percentages for each strategy reported). We will also add a table or breakdown quantifying the measures taken. This makes the assessment more transparent and directly linked to the data. revision: yes
Circularity Check
No circularity: direct survey reporting with no derivations or self-referential claims
full rationale
The paper is a community survey that tabulates and summarizes responses from 155 NLP researchers on LLM usage in crowdsourcing. All central claims (e.g., 44% observed LLM usage, awareness but insufficient mitigation) are direct aggregates of the collected data. No equations, fitted parameters, predictions, uniqueness theorems, or self-citations are used to derive results; the survey itself constitutes the evidence base. This matches the default case of a self-contained empirical report with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Survey respondents can accurately detect and report LLM usage in crowdsourced data.
Reference graph
Works this paper leans on
-
[1]
and Gordon, Andrew and Rothschild, David and West, Robert , title =
Veselovsky, Veniamin and Horta Ribeiro, Manoel and Cozzolino, Philip J. and Gordon, Andrew and Rothschild, David and West, Robert , title =. 2025 , issue_date =. doi:10.1145/3685527 , journal =
-
[2]
Sociological Methods & Research , volume =
Zhang, Simone and Xu, Janet and Alvero, AJ , title =. Sociological Methods & Research , volume =. 2025 , doi =
2025
-
[3]
2023 , eprint=
Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks , author=. 2023 , eprint=
2023
-
[4]
Westwood , title =
Sean J. Westwood , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =
2025
-
[5]
Can Unconfident LLM Annotations Be Used for Confident Conclusions?
Gligoric, Kristina and Zrnic, Tijana and Lee, Cinoo and Candes, Emmanuel and Jurafsky, Dan. Can Unconfident LLM Annotations Be Used for Confident Conclusions?. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v...
-
[6]
Holzmeister, Felix and Johannesson, Magnus and Camerer, Colin F. and Chen, Yiling and Ho, Teck-Hua and Hoogeveen, Suzanne and Huber, Juergen and Imai, Noriko and Imai, Taisuke and Jin, Lawrence and Kirchler, Michael and Ly, Alexander and Mandl, Benjamin and Manfredi, Dylan and Nave, Gideon and Nosek, Brian A. and Pfeiffer, Thomas and Sarafoglou, Alexandra...
2025
-
[7]
The Parrot Dilemma: Human-Labeled vs
M ller, Anders Giovanni and Pera, Arianna and Dalsgaard, Jacob and Aiello, Luca. The Parrot Dilemma: Human-Labeled vs. LLM -augmented Data in Classification Tasks. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.eacl-short.17
-
[8]
AI and Ethics , volume =
Kieslich, Kimon and Diakopoulos, Nicholas and Helberger, Natali , title =. AI and Ethics , volume =. 2025 , doi =
2025
-
[9]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Zhong, Ruiqi and Zhang, Peter and Li, Steve and Ahn, Jinwoo and Klein, Dan and Steinhardt, Jacob , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[10]
Experimental Narratives: A Comparison of Human Crowdsourced Storytelling and
Begu. Experimental Narratives: A Comparison of Human Crowdsourced Storytelling and. Humanities and Social Sciences Communications , volume =. 2024 , doi =
2024
-
[11]
Crowdsourcing and language studies: The new generation of linguistic data
Munro, Robert and Bethard, Steven and Kuperman, Victor and Lai, Vicky Tzuyin and Melnick, Robin and Potts, Christopher and Schnoebelen, Tyler and Tily, Harry. Crowdsourcing and language studies: The new generation of linguistic data. Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with A mazon ' s Mechanical Turk. 2010
2010
-
[12]
Suhr, Alane and Vania, Clara and Nangia, Nikita and Sap, Maarten and Yatskar, Mark and Bowman, Samuel R. and Artzi, Yoav. Crowdsourcing Beyond Annotation: Case Studies in Benchmark Data Collection. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts. 2021. doi:10.18653/v1/2021.emnlp-tutorials.1
-
[13]
Wazny, Kerri , year = 2017, month = dec, journal =. ". doi:10.7189/jogh.07.020601 , langid =
-
[14]
and See, Linda and Savic, Dragan and Zhang, Tuqiao and Chen, Qiuwen and Assumpção, Thaine H
Zheng, Feifei and Tao, Ruoling and Maier, Holger R. and See, Linda and Savic, Dragan and Zhang, Tuqiao and Chen, Qiuwen and Assumpção, Thaine H. and Yang, Pan and Heidari, Bardia and Rieckermann, Jörg and Minsker, Barbara and Bi, Weiwei and Cai, Ximing and Solomatine, Dimitri and Popescu, Ioana , title =. Reviews of Geophysics , volume =. doi:https://doi....
-
[15]
and Kulkarni, Chinmay and Lasecki, Walter S
Bigham, Jeffrey P. and Kulkarni, Chinmay and Lasecki, Walter S. , title =. Proceedings of the 2017. 2017 , isbn =. doi:10.1145/3027063.3027098 , pages =
-
[16]
and Angeli, Gabor and Potts, Christopher and Manning, Christopher D
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D. A large annotated corpus for learning natural language inference. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1075
-
[17]
Crowdsourcing and Validating Event-focused Emotion Corpora for G erman and E nglish
Troiano, Enrica and Pad \'o , Sebastian and Klinger, Roman. Crowdsourcing and Validating Event-focused Emotion Corpora for G erman and E nglish. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1391
-
[18]
and Ng, Andrew and Potts, Christopher
Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
2013
-
[19]
Proceedings of the National Academy of Sciences , volume =
Alex Reinhart and Ben Markey and Michael Laudenbach and Kachatad Pantusen and Ronald Yurko and Gordon Weinberg and David West Brown , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =
2025
-
[20]
and Lopez-Lopez, Ezequiel and Hechtlinger, Shahar and Rahwan, Zoe and Aeschbach, Samuel and Bakker, Michiel A
Burton, Jason W. and Lopez-Lopez, Ezequiel and Hechtlinger, Shahar and Rahwan, Zoe and Aeschbach, Samuel and Bakker, Michiel A. and Becker, Joshua A. and Berditchevskaia, Aleks and Berger, Julian and Brinkmann, Levin and Flek, Lucie and Herzog, Stefan M. and Huang, Saffron and Kapoor, Sayash and Narayanan, Arvind and Nussberger, Anne-Marie and Yasseri, Ta...
-
[21]
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , year = 2024, month = jul, journal =
2024
-
[22]
Kamruzzaman, Mahammed and Shovon, Md. and Kim, Gene. Investigating Subtler Biases in LLM s: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.530
-
[23]
Khasentino, J., Belyaeva, A., Liu, X., Yang, Z., Furlotte, N
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , title =. 2023 , publisher =. doi:10.1145/3571730 , journal =
-
[24]
Dealing with Controversy: An Emotion and Coping Strategy Corpus Based on Role Playing
Troiano, Enrica and Labat, Sofie and Stranisci, Marco Antonio and Damiano, Rossana and Patti, Viviana and Klinger, Roman. Dealing with Controversy: An Emotion and Coping Strategy Corpus Based on Role Playing. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.89
-
[25]
Does Writing with Language Models Reduce Content Diversity? , booktitle =
Padmakumar, Vishakh and He, He , editor =. Does Writing with Language Models Reduce Content Diversity? , booktitle =
-
[26]
Can Large Language Models Help Augment
Trott, Sean , year = 2024, month = sep, journal =. Can Large Language Models Help Augment. doi:10.3758/s13428-024-02337-z , langid =
-
[27]
2026 , eprint=
Epistemic Diversity and Knowledge Collapse in Large Language Models , author=. 2026 , eprint=
2026
-
[28]
Marwa Abdulhai and Isadora White and Yanming Wan and Ibrahim Qureshi and Joel Leibo and Max Kleiman-Weiner and Natasha Jaques , year=. How. 2603.18161 , archivePrefix=
-
[29]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao ...
-
[30]
and Aroyehun, Segun , keywords =
Zanotto, Sergio E. and Aroyehun, Segun , keywords =. Human Variability vs. Machine Consistency: A Linguistic Analysis of Texts Generated by Humans and Large Language Models , journal =. 2024 , copyright =. doi:10.48550/ARXIV.2412.03025 , url =
-
[31]
Akinwande, Mayowa and Adeliyi, Oluwaseyi and Yussuph, Toyyibat , year=. Decoding. International Journal on Cybernetics & Informatics , publisher=. doi:10.5121/ijci.2024.130408 , number=
-
[32]
A Comparison of Human‐Written Versus
Yildiz Durak, Hatice and Eğin, Figen and Onan, Aytuğ , year =. A Comparison of Human‐Written Versus. European Journal of Education , publisher =. doi:10.1111/ejed.70014 , number =
-
[33]
Contrasting Linguistic Patterns in Human and
Muñoz-Ortiz, Alberto and Gómez-Rodríguez, Carlos and Vilares, David , year =. Contrasting Linguistic Patterns in Human and. Artificial Intelligence Review , publisher =. doi:10.1007/s10462-024-10903-2 , number =
-
[34]
Zamaraeva, Olga and Flickinger, Dan and Bond, Francis and G \'o mez-Rodr \'i guez, Carlos. Comparing LLM -generated and human-authored news text using formal syntactic theory. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.443
-
[35]
2024 , volume=
Andrew Gray , journal=. 2024 , volume=
2024
-
[36]
Kobak, Dmitry and González-Márquez, Rita and Horvát, Emőke-Ágnes and Lause, Jan , year =. Delving into. Science Advances , publisher =. doi:10.1126/sciadv.adt3813 , number =
-
[37]
Xuandong Zhao and Sam Gunn and Miranda Christ and Jaiden Fairoze and Andres Fabrega and Nicholas Carlini and Sanjam Garg and Sanghyun Hong and Milad Nasr and Florian Tram. 2025 , url =. doi:10.1109/SP61157.2025.00178 , timestamp =
-
[38]
2025 , volume=
Chinnappa Guggilla and Budhaditya Roy and Trupti Chavan and Abdul Rahman and Edward Bowen , journal=. 2025 , volume=
2025
-
[39]
Xiang, Lingyun and Li, Nian and Liu, Yuling and Hu, Jiayong , year = 2026, journal =
2026
-
[40]
Proceedings of the 15th International Learning Analytics and Knowledge Conference , pages =
Pan, Hongchen and Araujo Oliveira, Eduardo and Ferreira Mello, Rafael , year =. Exploring Human-AI Collaboration in Educational Contexts: Insights from Writing Analytics and Authorship Attribution , url =. doi:10.1145/3706468.3706536 , booktitle =
-
[41]
Wang, Yuxia and Shelmanov, Artem and Mansurov, Jonibek and Tsvigun, Akim and Habash, Nizar and Aji, Alham Fikri and Artemova, Ekaterina and Xie, Zhuohan and Su, Jinyan and Xing, Rui and Gurevych, Iryna and Nakov, Preslav , year = 2025, month = feb, publisher =
2025
-
[42]
Lee, Mina and Liang, Percy and Yang, Qian , title =. 2022 , isbn =. doi:10.1145/3491102.3502030 , booktitle =
-
[43]
Hamed, Ahmed Abdeen and Wu, Xindong , year = 2024, month = jul, journal =. Detection of. doi:10.1038/s41598-024-66784-6 , copyright =
-
[44]
A Survey on LLM -Generated Text Detection: Necessity, Methods, and Future Directions
Wu, Junchao and Yang, Shu and Zhan, Runzhe and Yuan, Yulin and Chao, Lidia Sam and Wong, Derek Fai. A Survey on LLM -Generated Text Detection: Necessity, Methods, and Future Directions. Computational Linguistics. 2025. doi:10.1162/coli_a_00549
-
[45]
Automatic Authorship Analysis in Human- AI Collaborative Writing
Richburg, Aquia and Bao, Calvin and Carpuat, Marine. Automatic Authorship Analysis in Human- AI Collaborative Writing. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[46]
HAC o-Det: A Study Towards Fine-Grained Machine-Generated Text Detection under Human- AI Coauthoring
Su, Zhixiong and Wang, Yichen and Wan, Herun and Zhang, Zhaohan and Luo, Minnan. HAC o-Det: A Study Towards Fine-Grained Machine-Generated Text Detection under Human- AI Coauthoring. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1069
-
[47]
Behavior Research Methods , volume =
The Effectiveness of Warning Statements in Reducing Careless Responding in Crowdsourced Online Surveys , author =. Behavior Research Methods , volume =
-
[48]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =
von Ahn, Luis and Dabbish, Laura , title =. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =. 2004 , isbn =. doi:10.1145/985692.985733 , abstract =
-
[49]
Ipeirotis , title =
Panagiotis G. Ipeirotis , title =. XRDS: Crossroads, The. 2010 , publisher =
2010
-
[50]
Cheap and Fast -- But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks
Snow, Rion and O ' Connor, Brendan and Jurafsky, Daniel and Ng, Andrew. Cheap and Fast -- But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. 2008
2008
-
[51]
SQuAD: 100, 000+ Questions for Machine Comprehension of Text , booktitle =
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[52]
Creating Speech and Language Data With A mazon ' s M echanical T urk
Callison-Burch, Chris and Dredze, Mark. Creating Speech and Language Data With A mazon ' s M echanical T urk. Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with A mazon ' s Mechanical Turk. 2010
2010
-
[53]
and Crowe, Michael and Weiss, Brandon and
Miller, Joshua D. and Crowe, Michael and Weiss, Brandon and. Using Online, Crowdsourcing Platforms for Data Collection in Personality Disorder Research:. Personality disorders , volume =. doi:10.1037/per0000191 , copyright =
-
[54]
Beyond the Turk: Alternative platforms for crowdsourcing behavioral research , journal =
Eyal Peer and Laura Brandimarte and Sonam Samat and Alessandro Acquisti , keywords =. Beyond the Turk: Alternative platforms for crowdsourcing behavioral research , journal =. 2017 , issn =. doi:https://doi.org/10.1016/j.jesp.2017.01.006 , url =
-
[55]
Raykar and Shipeng Yu and Linda H
Vikas C. Raykar and Shipeng Yu and Linda H. Zhao and Gerardo Hermosillo Valadez and Charles Florin and Luca Bogoni and Linda Moy , title =. Journal of Machine Learning Research , volume =
-
[56]
Proceedings of the 2013 Conference of the North
Dirk Hovy and Taylor Berg-Kirkpatrick and Ashish Vaswani and Eduard Hovy , title =. Proceedings of the 2013 Conference of the North. 2013 , publisher =
2013
-
[57]
, year = 2011, month = jan, journal =
Buhrmester, Michael and Kwang, Tracy and Gosling, Samuel D. , year = 2011, month = jan, journal =. Amazon's. doi:10.1177/1745691610393980 , langid =
-
[58]
Nickerson and Michael Bernstein and Elizabeth Gerber and Aaron Shaw and John Zimmerman and Matthew Lease and John Horton , title =
Aniket Kittur and Jeffrey V. Nickerson and Michael Bernstein and Elizabeth Gerber and Aaron Shaw and John Zimmerman and Matthew Lease and John Horton , title =. Proceedings of the 2013. 2013 , publisher =
2013
-
[59]
Bretonnel Cohen , title =
Karen Fort and Gilles Adda and K. Bretonnel Cohen , title =. Computational Linguistics , volume =. 2011 , publisher =
2011
-
[60]
Six Silberman , title =
Lilly Irani and M. Six Silberman , title =. Proceedings of the. 2013 , publisher =
2013
-
[61]
Gray and Siddharth Suri , title =
Mary L. Gray and Siddharth Suri , title =
-
[62]
Proceedings of the Eleventh
Djellel Difallah and Elena Filatova and Panagiotis Ipeirotis , title =. Proceedings of the Eleventh. 2018 , publisher =
2018
-
[63]
Mining Crowdsourcing Problems from Discussion Forums of Workers
Nouri, Zahra and Wachsmuth, Henning and Engels, Gregor. Mining Crowdsourcing Problems from Discussion Forums of Workers. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.551
-
[64]
Wireless Communications and Mobile Computing , volume =
Li, Yunhui and Chang, Liang and Li, Long and Bao, Xuguang and Gu, Tianlong , title =. Wireless Communications and Mobile Computing , volume =. doi:https://doi.org/10.1155/2021/8745897 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1155/2021/8745897 , year =
-
[65]
Graduate Student Journal of Psychology , year =
OConnell, Daniel and Bautista, Ashley and Johnson, Clint and Venta, Amanda , title =. Graduate Student Journal of Psychology , year =. doi:10.52214/gsjp.v25i1.14129 , url =
-
[66]
Douglas, Benjamin D. and Ewell, Patrick J. and Brauer, Markus , date =. Data Quality in Online Human-Subjects Research:. doi:10.1371/journal.pone.0279720 , url =
-
[67]
Beyond the
Peer, Eyal and Brandimarte, Laura and Samat, Sonam and Acquisti, Alessandro , year = 2017, journal =. Beyond the
2017
-
[68]
Beyond Fair Pay: Ethical Implications of NLP Crowdsourcing
Shmueli, Boaz and Fell, Jan and Ray, Soumya and Ku, Lun-Wei. Beyond Fair Pay: Ethical Implications of NLP Crowdsourcing. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.295
-
[69]
Machine-Generated Text , author =
Comparative Linguistic Analysis Framework of Human-Written vs. Machine-Generated Text , author =. Connection Science , volume =. https://doi.org/10.1080/09540091.2025.2507183 , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.