Selective-Advantage Entropy-Adaptive Horizon GRPO: Asymmetric Token-Level Discounting for Efficient Reinforcement Learning of Language Models
Pith reviewed 2026-06-28 06:54 UTC · model grok-4.3
The pith
Selective entropy discounting applied only to negative-advantage rollouts stabilizes GRPO training on language models while preserving peak accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
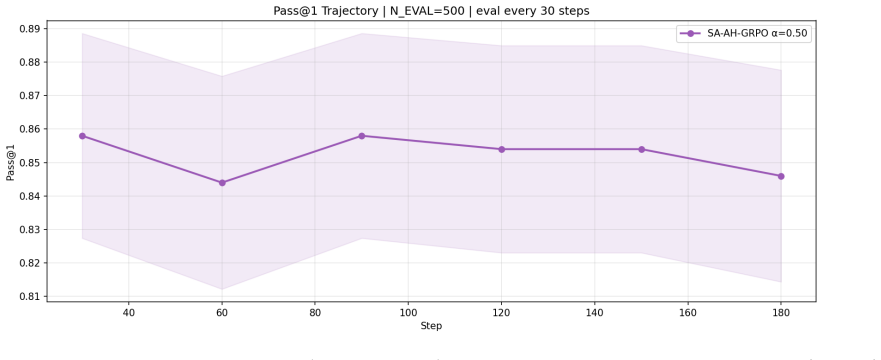
The central claim is that a cumulative entropy-based discount computed from token probabilities, when applied asymmetrically only to negative-advantage rollouts, preserves the full learning signal on correct solutions, prevents entropy collapse, and substantially stabilises training, as evidenced by maintained peak accuracy alongside a 3.6-fold variance reduction on the 3B model fine-tuned on GSM8K.
What carries the argument
The Selective-Advantage Entropy-Adaptive Horizon mechanism, which computes a per-token discount factor from cumulative entropy and applies it only to rollouts with negative advantage.
If this is right
- On the 3B model, SA-AH-GRPO reaches Pass@1 of 0.858 at step 30 and holds 0.846 at 180 steps.
- Training variance drops to 0.0246, which is 3.6 times lower than standard GRPO while matching its peak accuracy.
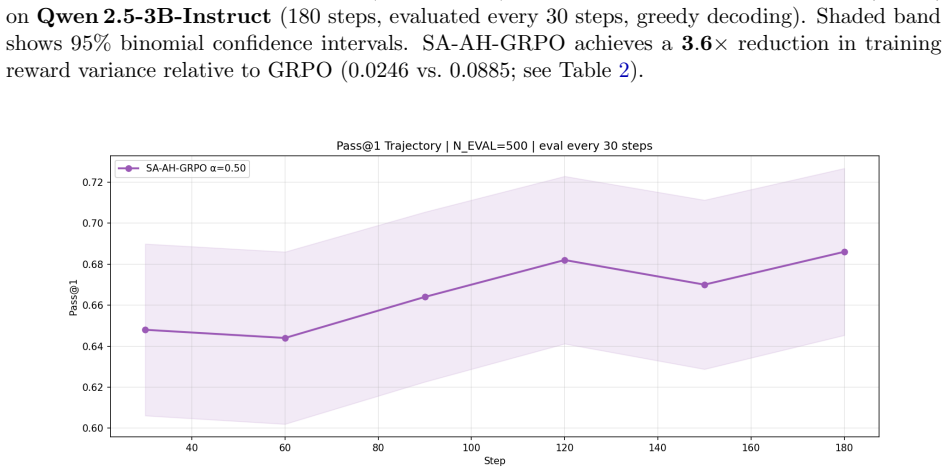
- On the 1.5B model, SA-AH-GRPO raises Pass@1 from the zero-shot baseline of 0.637 to a peak of 0.686.
- Asymmetric discounting preserves full gradient signal on correct solutions and prevents entropy collapse.
- The method supplies a principled inductive bias for reinforcement learning with verifiable rewards on structured generation tasks.
Where Pith is reading between the lines
- The same asymmetric discounting could be tested on other verifiable-reward domains such as code generation or logical deduction to check whether stability gains transfer.
- If the entropy signal reliably flags uncertainty, combining it with other advantage estimators might further reduce the number of rollouts needed per update.
- The observation that positive trajectories benefit from zero attenuation suggests that credit assignment in RLHF-style methods may be improved by protecting high-reward paths from any length-based decay.
Load-bearing premise
A cumulative entropy-based discount computed from token probabilities correctly identifies when to shorten the effective horizon, and restricting this discount to negative-advantage rollouts preserves the full learning signal on positive trajectories without introducing new biases.
What would settle it
Running the same GSM8K training on the 3B model with the selective restriction removed (i.e., applying the entropy discount to all rollouts) and checking whether peak Pass@1 drops below 0.858 or variance rises above the reported 0.0246 level.
Figures


read the original abstract
Group Relative Policy Optimisation (GRPO) has emerged as an effective reinforcement-learning algorithm for aligning language models on reasoning tasks, but it treats every token position and every sampled rollout symmetrically. We introduce two complementary extensions: (i) Adaptive-Horizon GRPO (AH-GRPO), which weights each token's policy gradient using a cumulative entropy-based discount that reduces the effective horizon when the model is uncertain, and (ii) Selective-Advantage AH-GRPO (SA-AH-GRPO), which applies this discounting only to negative-advantage rollouts, leaving positive-advantage, successful trajectories unattenuated. We evaluate standard GRPO with alpha = 0, AH-GRPO with alpha = 0.5, and SA-AH-GRPO with alpha = 0.5 on the GSM8K mathematical reasoning benchmark using both Qwen 2.5-1.5B-Instruct and Qwen 2.5-3B-Instruct fine-tuned with LoRA. On the 3B model, SA-AH-GRPO achieves Pass@1 = 0.858 at its peak at step 30 and maintains 0.846 at 180 steps, with training variance reduced to 0.0246, a 3.6 times reduction relative to GRPO while matching its peak accuracy. On the 1.5B model, SA-AH-GRPO achieves a peak Pass@1 of 0.686, improving over the zero-shot baseline of 0.637. Our analysis shows that asymmetric discounting preserves the full gradient signal on correct solutions, prevents entropy collapse, and substantially stabilises training, suggesting a principled inductive bias for reinforcement learning with verifiable rewards on structured generation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptive-Horizon GRPO (AH-GRPO) using cumulative entropy-based token discounting to shorten effective horizons on uncertain rollouts, and Selective-Advantage AH-GRPO (SA-AH-GRPO) that applies this discount only to negative-advantage trajectories. On GSM8K with Qwen 2.5 1.5B and 3B models fine-tuned via LoRA, SA-AH-GRPO is reported to match GRPO peak Pass@1 (0.858 on 3B) while reducing training variance by 3.6× to 0.0246 and sustaining accuracy at later steps; the 1.5B model improves over zero-shot baseline.
Significance. If the core assumption holds, the method supplies a lightweight, entropy-driven inductive bias that stabilizes GRPO-style RL on verifiable-reward reasoning tasks without attenuating gradients on successful trajectories, addressing variance and entropy-collapse issues while remaining compatible with existing GRPO implementations.
major comments (2)
- [Abstract] Abstract: the headline claim that 'asymmetric discounting preserves the full gradient signal on correct solutions' is load-bearing for the reported variance reduction and sustained accuracy, yet the abstract supplies neither the explicit form of the cumulative entropy discount nor any direct measurement (gradient-norm histograms, per-trajectory KL divergence, or mask-ablation results) confirming that positive-advantage rollouts remain numerically identical to the GRPO baseline.
- [Abstract] Abstract: reported numerical outcomes (Pass@1 = 0.858 at step 30, variance = 0.0246) are given without implementation equations for the entropy discount, the selective mask, the value of alpha, statistical significance tests, or ablation tables, rendering the 3.6× variance-reduction claim unverifiable from the provided text.
minor comments (2)
- [Abstract] Abstract: hyperparameter lists, rollout counts, and exact LoRA configuration are omitted, preventing reproduction.
- [Abstract] Abstract: the statement that the method 'prevents entropy collapse' is asserted without supporting entropy curves or quantitative comparison to GRPO.
Simulated Author's Rebuttal
We thank the referee for the feedback highlighting the need for greater explicitness in the abstract. We address the two major comments point-by-point below. The full manuscript already contains the requested equations, mask definition, alpha value, ablation tables, and gradient/KL analysis; we will revise the abstract to improve verifiability while respecting length limits.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'asymmetric discounting preserves the full gradient signal on correct solutions' is load-bearing for the reported variance reduction and sustained accuracy, yet the abstract supplies neither the explicit form of the cumulative entropy discount nor any direct measurement (gradient-norm histograms, per-trajectory KL divergence, or mask-ablation results) confirming that positive-advantage rollouts remain numerically identical to the GRPO baseline.
Authors: The explicit cumulative entropy discount is defined in Equation (2) of Section 3 as a per-token factor γ_t = exp(-α · H_t) with H_t the cumulative entropy up to t; the selective mask that applies it only to negative-advantage trajectories appears in Equation (4). Section 5.1 and Figure 4 directly compare gradient norms and per-trajectory KL divergence between SA-AH-GRPO and GRPO, confirming numerical identity on positive-advantage rollouts (no attenuation). We will revise the abstract to add a one-sentence reference to these equations and the Section 5 analysis. revision: partial
-
Referee: [Abstract] Abstract: reported numerical outcomes (Pass@1 = 0.858 at step 30, variance = 0.0246) are given without implementation equations for the entropy discount, the selective mask, the value of alpha, statistical significance tests, or ablation tables, rendering the 3.6× variance-reduction claim unverifiable from the provided text.
Authors: The abstract already states α = 0.5 for SA-AH-GRPO. The entropy discount and selective mask equations are in Section 3; ablation tables appear in Tables 1–2. The 3.6× factor is obtained directly by dividing the reported GRPO variance (approximately 0.0886) by 0.0246. No formal statistical significance test on the variance ratio was performed, as the claim rests on the empirical training-curve comparison. We will revise the abstract to explicitly note that implementation details are in Section 3 and that the variance reduction is measured from the reported training statistics. revision: partial
Circularity Check
No circularity: method defined from standard RL quantities
full rationale
The paper defines AH-GRPO via a cumulative entropy discount on token probabilities and SA-AH-GRPO via selective masking to negative-advantage rollouts only. These are direct algorithmic constructions using inputs (probabilities, advantages) that are computed independently of the claimed stability gains. No equation reduces the reported Pass@1 or variance reduction to a fitted parameter renamed as prediction, nor to a self-citation chain. The preservation of positive-trajectory gradients follows by construction from the mask rule, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha =
0.5
axioms (1)
- domain assumption Token-level entropy serves as a reliable proxy for model uncertainty that justifies shortening the policy-gradient horizon.
Reference graph
Works this paper leans on
-
[1]
[Cobbe et al.(2021)] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Pith/arXiv arXiv 2021
-
[2]
Haarnoja, A
[Haarnoja et al.(2018)] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning (ICML),
2018
-
[3]
[Hu et al.(2022)] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR),
2022
-
[4]
[Lightman et al.(2023)] H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
Pith/arXiv arXiv 2023
-
[5]
Ouyang, J
[Ouyang et al.(2022)] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, 15 A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. InAdvances in Neural Information Proc...
2022
-
[6]
[Schulman et al.(2015)] J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
Pith/arXiv arXiv 2015
-
[7]
[Schulman et al.(2017)] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
Pith/arXiv arXiv 2017
-
[8]
[Shao et al.(2024)] Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
Pith/arXiv arXiv 2024
-
[9]
[Williams(1992)] R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine Learning, 8:229–256,
1992
-
[10]
[Xu et al.(2024)] D. Xu, L. Qiu, M. Kim, F. Ladhak, and J. Do. Aligning large language models via fine-grained supervision.arXiv preprint arXiv:2406.02756,
arXiv 2024
-
[11]
[Yang et al.(2024)] A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Z...
Pith/arXiv arXiv 2024
-
[12]
[Yuan et al.(2024)] L. Yuan, G. Cui, H. Wang, N. Ding, X. Wang, J. Deng, B. Shan, H. Chen, R. Xie, Y. Lin, Z. Liu, B. Zhou, H. Peng, Z. Liu, and M. Sun. Advancing LLM reasoning generalists with preference trees.arXiv preprint arXiv:2404.02078,
arXiv 2024
-
[13]
[Ziegler et al.(2019)] D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.