Output Type Before Quality: A Standards-Derived XAI Admissibility Rubric for Autonomous-Driving Safety
Pith reviewed 2026-06-28 05:50 UTC · model grok-4.3
The pith
Causal XAI is required to meet evidence demands from autonomous-driving safety standards at three lifecycle stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
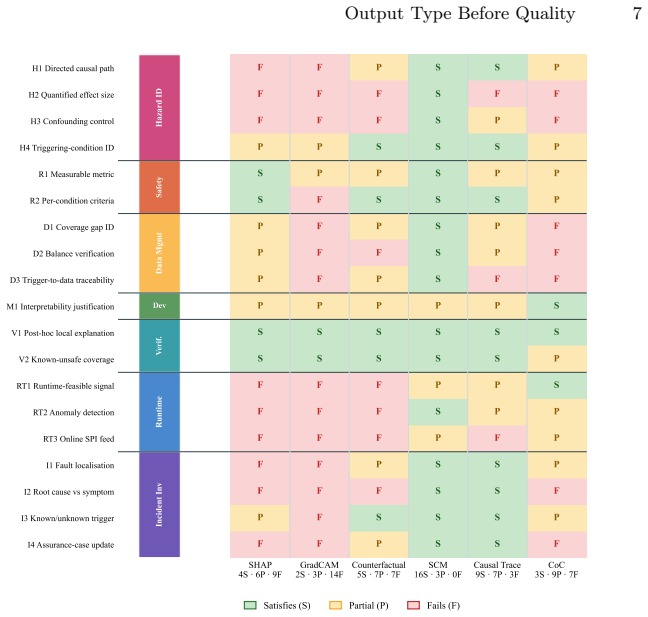
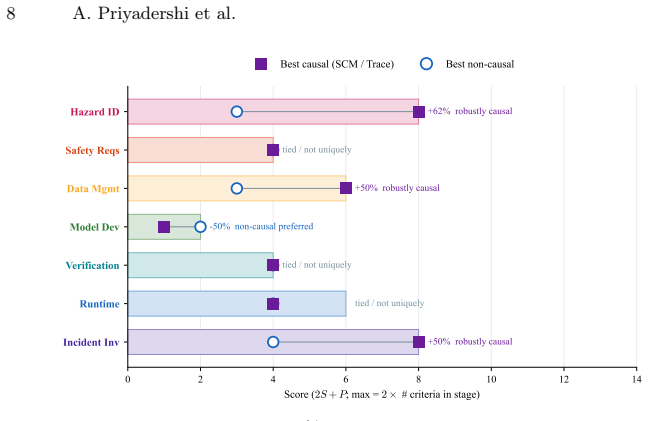
From the cited standards the authors extract 19 testable evidentiary criteria that assurance cases must satisfy with directed cause-and-effect chains, quantified interventional effects and named root-cause variables. Structural scoring of XAI method classes shows causal XAI is required to close the evidence-type gap at hazard identification (+62 percent), incident investigation (+50 percent) and data management (+50 percent). The verdict set remains stable for thresholds from 0 percent to 50 percent and survives a worst-case single-cell flip down to 25 percent. At the remaining four stages correlational or language-based methods are comparable or sufficient. The rubric addresses structural a
What carries the argument
The 19-criterion admissibility rubric that scores XAI method classes by whether their output types can supply the directed cause-and-effect evidence required by the standards at each lifecycle stage.
If this is right
- XAI method selection for ADS safety cases must be driven by the evidence demand of each lifecycle stage.
- Causal XAI is the only class that satisfies the rubric at hazard identification, incident investigation and data management.
- At the other four stages correlational or language-based methods remain admissible under the rubric.
- Even an admissible method still requires separate validation that its concrete outputs are factually correct.
- The stability of the verdict set down to a 25 percent threshold indicates the structural result is not fragile to small scoring changes.
Where Pith is reading between the lines
- The same standards-to-rubric approach could be reused for other regulated domains that require causal evidence in assurance cases.
- Developers might design stage-aware XAI pipelines that switch method class according to the current lifecycle stage.
- The open fidelity-validation challenge points to a need for new benchmarks that test whether a causal graph or trace names the actual root cause in driving data.
Load-bearing premise
The 19 criteria derived from the standards correctly capture the evidence types that XAI outputs must supply in autonomous-driving assurance cases.
What would settle it
Demonstration that a non-causal XAI method, such as SHAP, can be implemented to produce directed cause-and-effect chains that satisfy the hazard-identification criteria would falsify the structural scoring.
Figures

read the original abstract
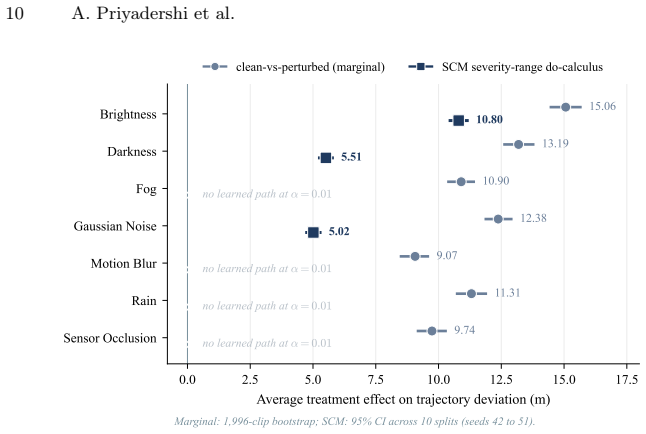
Safety standards for ML-based autonomous driving specify the kind of evidence an assurance case must contain (directed cause-and-effect chains, quantified interventional effects, named root-cause variables), yet the XAI literature is organised by output type and technique family (saliency maps, feature attribution, counterfactuals, causal graphs, language traces). SHAP, the most-recommended ADS XAI method, returns a ranked feature list that no implementation effort can convert into a directed chain (Fig.1). We name this mismatch the evidence-type gap. From AMLAS, ISO 26262, ISO21448, ISO/PAS 8800 we derive 19 testable evidentiary criteria across 7 lifecycle stages with representative clause-cited derivations and score six XAI method classes structurally. Causal XAI emerges as structurally required to satisfy the derived criteria at three stages: hazard identification (+62% rubric gap), incident investigation (+50%), and data management (+50%); the verdict set is stable across thresholds T in (0%, 50%]$ and survives a worst-case single-cell flip down to T = 25%. At the remaining four stages, correlational or language-based methods are comparable or sufficient. The rubric identifies structural admissibility (necessary but not sufficient for compliance): an admissible method's specific output content may still be wrong, and validating that fidelity (the edges a fitted SCM produces, the cause a trace names) is the open assurance challenge. A single-VLA proof of concept on 1,996 real-world driving clips (79,840 rows, ten splits) is consistent with each method's observed output type matching its rubric prediction. XAI method selection for ADS safety assurance should be driven by lifecycle-stage evidence demand, not by method popularity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives 19 evidentiary criteria from AMLAS, ISO 26262, ISO 21448 and ISO/PAS 8800 across seven lifecycle stages for autonomous-driving assurance cases. It structurally scores six XAI method classes (including SHAP, saliency, counterfactuals, causal graphs and language traces) on whether their output types can ever supply the required evidence (directed cause-and-effect chains, quantified interventional effects, named root-cause variables). Causal XAI is found structurally required at hazard identification (+62% gap), incident investigation (+50%) and data management (+50%), with verdicts stable for thresholds T in (0%,50%] and robust to single-cell flips down to T=25%. At the other four stages correlational or language methods suffice. A single-VLA proof-of-concept on 1,996 real-world clips (79,840 rows, ten splits) is reported as consistent with each method’s rubric-predicted output type. The rubric addresses structural admissibility only.
Significance. If the clause-cited derivations and structural scoring hold, the work supplies a standards-grounded, output-type-driven rubric for XAI selection in ADS safety cases rather than popularity-based choice. The explicit stability analysis across T thresholds and the 1,996-clip proof-of-concept (with ten splits) constitute reproducible empirical support for the internal consistency of the rubric. These elements strengthen the central claim that method selection must be driven by lifecycle-stage evidence demand.
major comments (1)
- [Abstract (criteria derivation and validation paragraph); § on 19 evidentiary criteria and method scoring] The central claim that causal XAI is structurally required at the three named stages rests on the accuracy of the 19 criteria extracted from the cited standards and on the structural scoring of the six method classes. The single-VLA proof-of-concept validates only that observed output types match the paper’s own rubric predictions; it does not independently test whether the criteria correctly encode the evidence types demanded by the standards or whether the scoring accurately reflects what each method class can supply even after post-processing. This mapping is load-bearing for the reported gaps (+62%, +50%, +50%) and for the stability result.
minor comments (1)
- [Abstract (Fig. 1 reference)] Figure 1 is referenced in the abstract but its caption and axis labels are not described in the provided text; ensure the figure explicitly shows why a ranked feature list cannot be converted into a directed chain.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and for recognizing the significance of the standards-derived rubric and the stability analysis. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract (criteria derivation and validation paragraph); § on 19 evidentiary criteria and method scoring] The central claim that causal XAI is structurally required at the three named stages rests on the accuracy of the 19 criteria extracted from the cited standards and on the structural scoring of the six method classes. The single-VLA proof-of-concept validates only that observed output types match the paper’s own rubric predictions; it does not independently test whether the criteria correctly encode the evidence types demanded by the standards or whether the scoring accurately reflects what each method class can supply even after post-processing. This mapping is load-bearing for the reported gaps (+62%, +50%, +50%) and for the stability result.
Authors: We agree that the single-VLA proof-of-concept (1,996 clips, ten splits) only demonstrates internal consistency: that each method class produces output types matching the rubric predictions. It does not constitute an independent empirical test of whether the 19 criteria faithfully encode the evidentiary demands of the cited standards clauses, nor does it validate the structural scoring against post-processed implementations. The criteria are derived via direct clause extraction from AMLAS, ISO 26262, ISO 21448 and ISO/PAS 8800, with representative derivations supplied in the manuscript so that readers may assess the mapping themselves. The structural scoring evaluates output-type capability (e.g., whether a ranked feature list can ever supply a directed cause-and-effect chain) rather than post-processing potential. We will revise the abstract and the criteria-derivation section to state explicitly the limited scope of the empirical component and to flag that independent validation of the criteria-to-standard mapping against real assurance cases remains an open task. This makes the load-bearing assumptions transparent without altering the reported gaps or stability results. revision: partial
Circularity Check
No significant circularity; derivation from external standards is independent
full rationale
The paper derives its 19 evidentiary criteria from external standards (AMLAS, ISO 26262, ISO 21448, ISO/PAS 8800) with clause-cited derivations, then applies structural scoring to XAI method classes based on their inherent output types (e.g., SHAP cannot produce directed chains). This chain does not reduce to self-definition, fitted inputs renamed as predictions, or self-citation load-bearing. The single-VLA proof-of-concept tests consistency with the rubric but does not substitute for external validation of the rubric itself. No equations or steps exhibit the enumerated circular patterns; the central claims rest on mappings to independent standards rather than internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The safety standards AMLAS, ISO 26262, ISO21448, ISO/PAS 8800 specify evidentiary requirements that can be translated into testable criteria for XAI output types.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2112.11561 (2024), revised 2024
Atakishiyev,S.,Salameh,M.,Yao,H.,Goebel,R.:Explainableartificialintelligence for autonomous driving: A comprehensive overview and field guide. arXiv preprint arXiv:2112.11561 (2024), revised 2024
-
[2]
Chickering, D.M.: Optimal structure identification with greedy search. J. Mach. Learn. Res.3, 507–554 (2002)
2002
-
[3]
arXiv preprint arXiv:2408.02379 (2024)
Fresz, B., Göbels, V.P., Omri, S., Brajovic, D., Aichele, A., Kutz, J., Neuhüttler, J., Huber, M.F.: The contribution of XAI for the safe development and certification of AI: An expert-based analysis. arXiv preprint arXiv:2408.02379 (2024)
- [4]
-
[5]
ISO: Road vehicles — functional safety (2018), iSO 26262:2018
2018
-
[6]
ISO: Road vehicles — safety of the intended functionality (2022), iSO 21448:2022
2022
-
[7]
ISO: Road vehicles — safety and artificial intelligence (2024), iSO/PAS 8800:2024
2024
-
[8]
arXiv preprint arXiv:2402.10086 (2024)
Kuznietsov, A., Gyevnar, B., Wang, C., Peters, S., Albrecht, S.V.: Explainable AI for safe and trustworthy autonomous driving: A systematic review. arXiv preprint arXiv:2402.10086 (2024)
-
[9]
In: Proc
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. In: Proc. NeurIPS (2017)
2017
-
[10]
https://huggingface.co/ datasets/nvidia/PhysicalAI-Autonomous-Vehicles (2025)
NVIDIA: PhysicalAI-Autonomous-Vehicles dataset. https://huggingface.co/ datasets/nvidia/PhysicalAI-Autonomous-Vehicles (2025)
2025
-
[11]
Pearl,J.:Causality:Models,Reasoning,andInference.CambridgeUniversityPress, 2nd edn. (2009)
2009
-
[12]
MIT Press (2017)
Peters, J., Janzing, D., Schölkopf, B.: Elements of Causal Inference. MIT Press (2017)
2017
-
[13]
In: Proc
Priyadershi, A., Frtunikj, J.: Lost in fog: Sensor perturbations expose reasoning fragility in driving VLAs. In: Proc. CVPR Workshops (SAIAD) (2026), to appear
2026
-
[14]
In: Proc
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- CAM: Visual explanations from deep networks via gradient-based localization. In: Proc. IEEE ICCV (2017)
2017
-
[15]
MIT Press, 2nd edn
Spirtes, P., Glymour, C., Scheines, R.: Causation, Prediction, and Search. MIT Press, 2nd edn. (2000)
2000
-
[16]
Harvard J
Wachter, S., Mittelstadt, B., Russell, C.: Counterfactual explanations without opening the black box. Harvard J. Law Technol.31(2) (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.