CHASE: Adversarial Red-Blue Teaming for Improving LLM Safety using Reinforcement Learning
Pith reviewed 2026-06-28 02:30 UTC · model grok-4.3
The pith
CHASE trains an attacker and defender in a closed RL loop to cut LLM vulnerability to prompt-rewriting attacks by 43 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
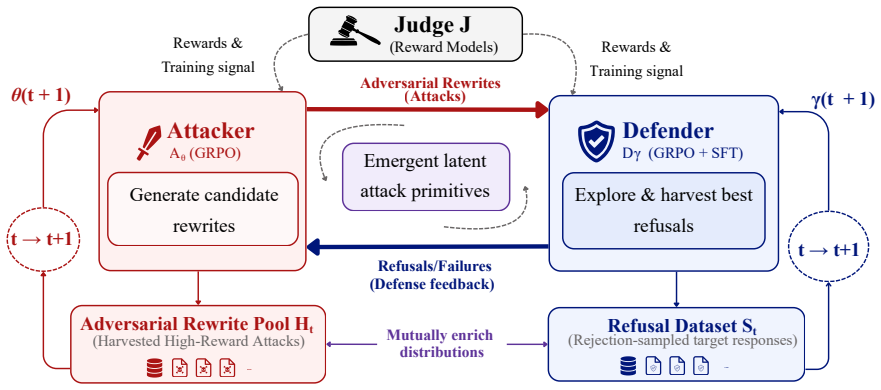
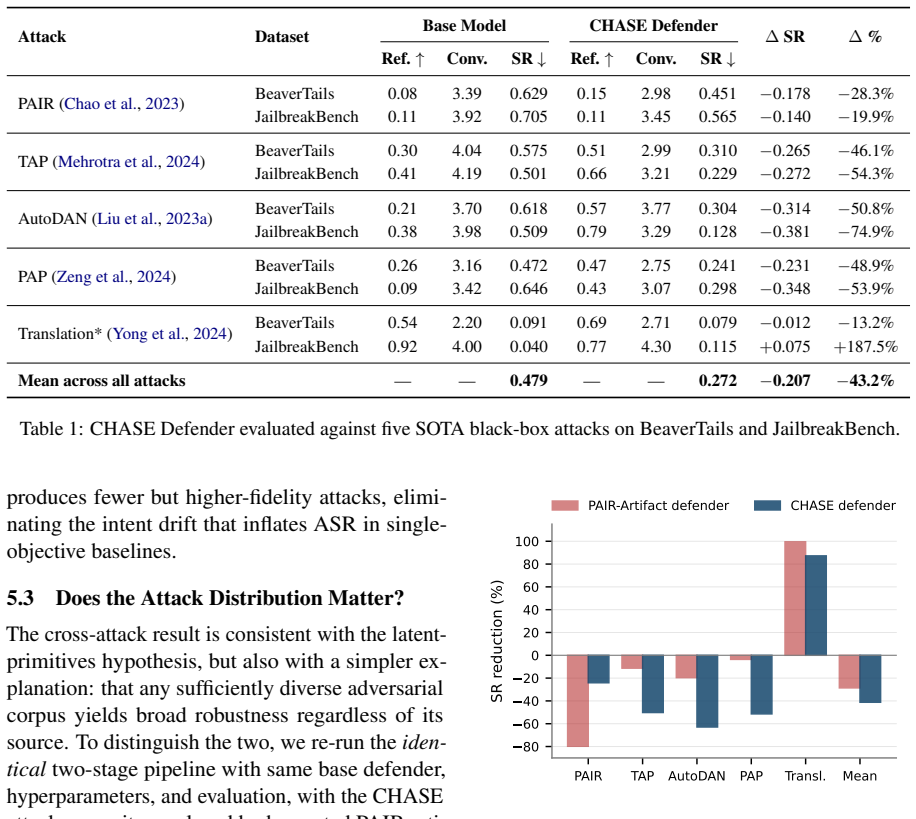
CHASE shows that a closed-loop red-blue teaming setup, with the attacker optimized via Group Relative Policy Optimization under a multiplicative reward for bypass effectiveness and intent fidelity, followed by a two-stage GRPO plus rejection-sampled SFT pipeline for the defender balanced with benign data, produces models whose mean StrongREJECT score drops 43.2 percent on BeaverTails and JailbreakBench when tested against five held-out attack families while recording zero false refusals on benign prompts.
What carries the argument
The closed-loop co-evolution in which the attacker and defender iteratively generate and defend against prompt rewrites using GRPO, with the multiplicative reward jointly enforcing attack success and intent preservation.
If this is right
- Template-free RL exploration recovers latent attack primitives that transfer across mechanistically distinct families.
- Safety improvements achieved through this process do not increase false refusals when benign prompts are included in the defender update.
- The method produces hardening that holds on two separate benchmarks against held-out attacks without post-hoc selection.
- Generalization occurs beyond the narrow distributions typical of prior adversarial training approaches.
Where Pith is reading between the lines
- The same co-evolutionary loop could be applied to other alignment targets such as reducing over-refusal or improving factuality.
- Scaling the attacker to larger models might expose whether the recovered primitives remain effective at frontier scale.
- Explicit inclusion of intent fidelity in the attack reward appears necessary to avoid generating unrealistic or off-distribution attacks.
Load-bearing premise
The distribution of adversarial rewrites harvested from the attacker during training allows the defender to generalize to attack families whose mechanisms were not encountered in the training loop.
What would settle it
Retraining a model with CHASE and then testing it on a fresh set of prompt-rewriting attacks drawn from a family outside the five evaluated families, with no measurable drop in StrongREJECT score relative to the undefended baseline.
Figures




read the original abstract
Despite advances in safety alignment, prompt-rewriting attacks such as persona modulation, fictional framing and persuasion-based reformulation, can bypass safety filters even on frontier models. Existing defenses either rely on non-scalable human curation or white-box optimisation that overfits to specific model internals, leaving aligned models brittle against the very class of adaptive black-box adversaries they will face in deployment. To address this gap, we introduce CHASE (Co-evolutionary Hardening through Adversarial Safety-Escalation), a closed-loop red-blue teaming framework in which a black-box attacker and a safety-aligned defender co-evolve. The attacker is trained via Group Relative Policy Optimization (GRPO) under a multiplicative reward that jointly enforces bypass effectiveness and intent fidelity, while the defender is hardened on the harvested adversarial rewrites through a two-stage GRPO + rejection-sampled SFT pipeline balanced with benign data. Evaluated on BeaverTails and JailbreakBench against five held-out attack families (PAIR, TAP, AutoDAN, PAP, Translation), CHASE cuts mean StrongREJECT score by 43.2\% with 0\% false-refusal on benign prompts. Beyond the headline result, CHASE shows that template-free RL exploration recovers latent attack primitives that transfer across mechanistically distinct attack families, suggesting a path toward LLM safety hardening that generalises beyond the narrow distributions achieved thus far in adversarial training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CHASE, a closed-loop red-blue teaming framework in which a black-box attacker is trained via GRPO under a multiplicative reward enforcing bypass effectiveness and intent fidelity, while the defender is hardened via a two-stage GRPO + rejection-sampled SFT pipeline on the resulting adversarial rewrites. Evaluated on BeaverTails and JailbreakBench against five held-out attack families (PAIR, TAP, AutoDAN, PAP, Translation), the method is claimed to reduce mean StrongREJECT score by 43.2% while maintaining 0% false-refusal on benign prompts, with the broader claim that template-free RL recovers transferable attack primitives.
Significance. If the generalization result holds after addressing statistical and ablation gaps, the work would demonstrate a scalable, black-box co-evolutionary alternative to human-curated or white-box defenses, with the closed-loop GRPO attacker-defender setup offering a concrete path toward safety hardening that transfers across mechanistically distinct families. The emphasis on multiplicative rewards and two-stage defender training provides a reproducible recipe worth testing in follow-on work.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the headline claim of a 43.2% reduction in mean StrongREJECT score supplies no information on statistical significance, variance across runs, number of seeds, or exact baseline implementations, preventing assessment of whether the held-out improvement supports the generalization claim.
- [Method / Experiments] Method and Experiments sections: no ablation is reported that isolates co-evolution effects (multiplicative-reward GRPO attacker + two-stage defender) from standard adversarial training, which is load-bearing for the claim that harvested rewrites capture transferable primitives rather than defender-specific artifacts.
- [Experiments] Experiments section: details on data exclusion rules, how the five held-out families were chosen to ensure mechanistic distinctness from training rewrites, and any distribution-shift metrics between training and test attacks are absent, leaving open the possibility that reported gains reflect correlation with the defender's evolving refusal surface.
minor comments (2)
- [Method] Notation for the multiplicative reward and the two-stage pipeline could be formalized with an equation or pseudocode block to improve reproducibility.
- [Evaluation] Figure or table presenting per-family StrongREJECT scores (rather than only the mean) would clarify whether the 43.2% aggregate is driven by a subset of families.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the statistical reporting, experimental ablations, and methodological transparency.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the headline claim of a 43.2% reduction in mean StrongREJECT score supplies no information on statistical significance, variance across runs, number of seeds, or exact baseline implementations, preventing assessment of whether the held-out improvement supports the generalization claim.
Authors: We agree that additional statistical details are necessary to support the generalization claim. In the revised manuscript we will expand the Evaluation section to report the number of random seeds, per-run variance or standard deviations of StrongREJECT scores, and appropriate statistical tests or confidence intervals for the 43.2% reduction. We will also document the precise baseline implementations and hyper-parameters used for comparison. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: no ablation is reported that isolates co-evolution effects (multiplicative-reward GRPO attacker + two-stage defender) from standard adversarial training, which is load-bearing for the claim that harvested rewrites capture transferable primitives rather than defender-specific artifacts.
Authors: We acknowledge the absence of these isolating ablations. The revised manuscript will include new ablation experiments that compare the full CHASE co-evolutionary pipeline (multiplicative-reward GRPO attacker plus two-stage defender) against standard adversarial training baselines that use a fixed attacker or non-multiplicative rewards. These results will clarify whether the observed transferability stems from the closed-loop dynamics rather than defender-specific artifacts. revision: yes
-
Referee: [Experiments] Experiments section: details on data exclusion rules, how the five held-out families were chosen to ensure mechanistic distinctness from training rewrites, and any distribution-shift metrics between training and test attacks are absent, leaving open the possibility that reported gains reflect correlation with the defender's evolving refusal surface.
Authors: We will revise the Experiments section to supply the missing details: explicit data exclusion rules, the selection rationale for the five held-out families (emphasizing their mechanistic differences from the training rewrite distribution), and quantitative distribution-shift metrics (e.g., embedding-based similarity or attack-success distribution divergence) between training and test attacks. These additions will help rule out spurious correlation with the defender's refusal surface. revision: yes
Circularity Check
No circularity: empirical gains on held-out families rest on external evaluation, not definitional reduction.
full rationale
The paper reports an empirical result (43.2% reduction in StrongREJECT on five held-out attack families after closed-loop GRPO training) without any equations, fitted parameters, or self-citations that would make the reported improvement equivalent to its training inputs by construction. The evaluation protocol explicitly separates training rewrites from the test families (PAIR, TAP, AutoDAN, PAP, Translation), and no load-bearing premise reduces to a self-citation chain or an ansatz smuggled from prior author work. The multiplicative reward and two-stage pipeline are described as training procedures whose outputs are then measured externally; nothing in the provided text equates the measured generalization to the training distribution itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zheng-Xin Yong and Cristina Menghini and Stephen H. Bach , title =. arXiv preprint arXiv:2310.02446 , year =
-
[2]
arXiv preprint arXiv:2505.19056 , year =
Harethah Abu Shairah and Hasan Abed Al Kader Hammoud and Bernard Ghanem and George Turkiyyah , title =. arXiv preprint arXiv:2505.19056 , year =
-
[3]
Proceedings of ACL , year =
Zixuan Chen and Weikai Lu and Xin Lin and Ziqian Zeng , title =. Proceedings of ACL , year =
-
[4]
arXiv preprint arXiv:2405.15624 , year =
Hao Sun and Mihaela van der Schaar , title =. arXiv preprint arXiv:2405.15624 , year =
-
[5]
arXiv preprint arXiv:2402.10260 , year =
Alexandra Souly and Qingyuan Lu and Dillon Bowen and Tu Trinh and Elvis Hsieh and Sana Pandey and Pieter Abbeel and Justin Svegliato and Scott Emmons and Olivia Watkins and Sam Toyer , title =. arXiv preprint arXiv:2402.10260 , year =
-
[6]
arXiv preprint arXiv:1707.06347 , year =
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. arXiv preprint arXiv:1707.06347 , year =
-
[7]
Pappas and Eric Wong , title =
Patrick Chao and Alexander Robey and Edgar Dobriban and Hamed Hassani and George J. Pappas and Eric Wong , title =. arXiv preprint arXiv:2310.08419 , year =
-
[8]
Proceedings of ACM CCS , year =
Xinyue Shen and Zeyuan Chen and Michael Backes and Yun Shen and Yang Zhang , title =. Proceedings of ACM CCS , year =
-
[9]
2023 , journal =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , journal =
2023
-
[10]
Long Ouyang and Jeff Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul Christiano and Jan Leike and Ryan Lowe , title =. arXiv...
-
[11]
2024 , journal =
Adversarial attacks on large language models , author =. 2024 , journal =
2024
-
[12]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y.K. Li and Y. Wu and Daya Guo , title =. arXiv preprint arXiv:2402.03300 , year =
-
[13]
arXiv preprint arXiv:2310.15140 , year =
Sicheng Zhu and Ruiyi Zhang and Bang An and Gang Wu and Joe Barrow and Zichao Wang and Furong Huang and Ani Nenkova and Tong Sun , title =. arXiv preprint arXiv:2310.15140 , year =
-
[14]
arXiv preprint arXiv:2209.07858 , year =
Deep Ganguli and Liane Lovitt and Jackson Kernion and Amanda Askell and Yuntao Bai and Saurav Kadavath and Ben Mann and Ethan Perez and Nicholas Schiefer and Kamal Ndousse and Andy Jones and Sam Bowman and Anna Chen and Tom Conerly and Nova DasSarma and Dawn Drain and Nelson Elhage and Sheer El-Showk and Stanislav Fort and Zac Hatfield-Dodds and Tom Henig...
-
[15]
Proceedings of the First Workshop on LLM Security (LLMSEC) , year =
Mohsen Sorkhpour and Abbas Yazdinejad and Ali Dehghantanha , title =. Proceedings of the First Workshop on LLM Security (LLMSEC) , year =
-
[16]
arXiv preprint arXiv:2503.01333 , year =
Xu Liang , title =. arXiv preprint arXiv:2503.01333 , year =
-
[17]
arXiv preprint arXiv:2310.06474 , year =
Yue Deng and Wenxuan Zhang and Sinno Jialin Pan and Lidong Bing , title =. arXiv preprint arXiv:2310.06474 , year =
-
[18]
Manning and Chelsea Finn , title =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Findings of the Association for Computational Linguistics , year =
Tharindu Kumarage and Ninareh Mehrabi and Anil Ramakrishna and Xinyan Zhao and Richard Zemel and Kai-Wei Chang and Aram Galstyan and Rahul Gupta and Charith Peris , title =. Findings of the Association for Computational Linguistics , year =
-
[20]
2023 , journal =
Adversarial Markov Games: On Adaptive Decision-Based Attacks and Defenses , author =. 2023 , journal =
2023
-
[21]
arXiv preprint arXiv:2310.04451 , year=
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , author=. arXiv preprint arXiv:2310.04451 , year=
-
[22]
arXiv preprint arXiv:2512.07059 , year=
Replicating TEMPEST at Scale: Multi-Turn Adversarial Attacks Against Trillion-Parameter Frontier Models , author=. arXiv preprint arXiv:2512.07059 , year=
-
[23]
arXiv preprint arXiv:2509.19839 , year=
LatentGuard: Controllable Latent Steering for Robust Refusal of Attacks and Reliable Response Generation , author=. arXiv preprint arXiv:2509.19839 , year=
-
[24]
arXiv preprint arXiv:2401.06373 , year =
Yi Zeng and Hongpeng Lin and Jingwen Zhang and Diyi Yang and Ruoxi Jia and Weiyan Shi , title =. arXiv preprint arXiv:2401.06373 , year =
-
[25]
2024 , journal =
Open sesame! universal black-box jailbreaking of large language models , author =. 2024 , journal =
2024
-
[26]
arXiv preprint arXiv:2307.04657 , year =
Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Chi Zhang and Ruiyang Sun and Yizhou Wang and Yaodong Yang , title =. arXiv preprint arXiv:2307.04657 , year =
-
[27]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Zhang, Mingchuan and Li, Y. K. and Wu, Yu and Guo, Daya , journal =. 2024 , url =
2024
-
[28]
arXiv preprint arXiv:2508.18255 , year =
Hermes 4 Technical Report , author =. arXiv preprint arXiv:2508.18255 , year =
-
[29]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and others , journal =. The. 2024 , url =
2024
-
[30]
Pappas and Florian Tramer and Hamed Hassani and Eric Wong , title =
Patrick Chao and Edoardo Debenedetti and Alexander Robey and Maksym Andriushchenko and Francesco Croce and Vikash Sehwag and Edgar Dobriban and Nicolas Flammarion and George J. Pappas and Florian Tramer and Hamed Hassani and Eric Wong , title =. arXiv preprint arXiv:2404.01318 , year =
-
[31]
2024 , journal =
MART: Improving LLM Safety with Multi-round Automatic Red-Teaming , author =. 2024 , journal =
2024
-
[32]
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. arXiv preprint arXiv:2106.09685 , year =
-
[33]
2023 , journal =
Stanford alpaca: An instruction-following llama model , author =. 2023 , journal =
2023
-
[34]
Transformer Circuits Thread , year =
Nelson Elhage and Tristan Hume and Catherine Olsson and Nicholas Schiefer and Tom Henighan and Shauna Kravec and Zac Hatfield-Dodds and Robert Lasenby and Dawn Drain and Carol Chen and Roger Gross and Sam McCandlish and Jared Kaplan and Dario Amodei and Martin Wattenberg and Christopher Olah , title =. Transformer Circuits Thread , year =
-
[35]
arXiv preprint arXiv:2307.02483 , year =
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , title =. arXiv preprint arXiv:2307.02483 , year =
-
[36]
Efficient Adversarial Training in
Sophie Xhonneux and Alessandro Sordoni and Stephan G. Efficient Adversarial Training in. arXiv preprint arXiv:2405.15589 , year =
- [37]
-
[38]
arXiv preprint arXiv:2204.05862 , year =
Yuntao Bai and Andy Jones and Kamal Ndousse and Amanda Askell and Anna Chen and Nova DasSarma and Dawn Drain and Stanislav Fort and Deep Ganguli and Tom Henighan and Nicholas Joseph and Saurav Kadavath and Jackson Kernion and Tom Conerly and Sheer El-Showk and Nelson Elhage and Zac Hatfield-Dodds and Danny Hernandez and Tristan Hume and Scott Johnston and...
-
[39]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Yong Lin and Hangyu Lin and Wei Xiong and Shizhe Diao and Jianmeng Liu and Jipeng Zhang and Rui Pan and Haoxiang Wang and Wenbin Hu and Hanning Zhang and Hanze Dong and Renjie Pi and Han Zhao and Nan Jiang and Heng Ji and Yuan Yao and Tong Zhang , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2024
-
[40]
Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
Yifan Zhong and Chengdong Ma and Xiaoyuan Zhang and Ziran Yang and Haojun Chen and Qingfu Zhang and Siyuan Qi and Yaodong Yang , title =. Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
-
[41]
arXiv preprint arXiv:2310.12773 , year =
Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang , title =. arXiv preprint arXiv:2310.12773 , year =
-
[42]
2024 , journal =
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models , author =. 2024 , journal =
2024
-
[43]
Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
Andy Arditi and Oscar Obeso and Aaquib Syed and Daniel Paleka and Nina Panickssery and Wes Gurnee and Neel Nanda , title =. Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
-
[44]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Xiangyu Qi and Ashwinee Panda and Kaifeng Lyu and Xiao Ma and Subhrajit Roy and Ahmad Beirami and Prateek Mittal and Peter Henderson , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[45]
arXiv preprint arXiv:2405.20947 , year =
Justin Cui and Wei-Lin Chiang and Ion Stoica and Cho-Jui Hsieh , title =. arXiv preprint arXiv:2405.20947 , year =
-
[46]
arXiv preprint arXiv:2305.13860 , year =
Yi Liu and Gelei Deng and Zhengzi Xu and Yuekang Li and Yaowen Zheng and Ying Zhang and Lida Zhao and Tianwei Zhang and Kailong Wang and Yang Liu , title =. arXiv preprint arXiv:2305.13860 , year =
-
[47]
arXiv preprint arXiv:2311.03191 , year =
Xuan Li and Zhanke Zhou and Jianing Zhu and Jiangchao Yao and Tongliang Liu and Bo Han , title =. arXiv preprint arXiv:2311.03191 , year =
-
[48]
arXiv preprint arXiv:2311.03348 , year =
Rusheb Shah and Quentin Feuillade-Montixi and Soroush Pour and Arush Tagade and Stephen Casper and Javier Rando , title =. arXiv preprint arXiv:2311.03348 , year =
-
[49]
International Conference on Machine Learning (ICML) , year =
Mantas Mazeika and Long Phan and Xuwang Yin and Andy Zou and Zifan Wang and Norman Mu and Elham Sakhaee and Nathaniel Li and Steven Basart and Bo Li and David Forsyth and Dan Hendrycks , title =. International Conference on Machine Learning (ICML) , year =
-
[50]
ACM Conference on Computer and Communications Security (CCS) , year =
Xinyue Shen and Zeyuan Chen and Michael Backes and Yun Shen and Yang Zhang , title =. ACM Conference on Computer and Communications Security (CCS) , year =
-
[51]
arXiv preprint arXiv:2312.02119 , year =
Anay Mehrotra and Manolis Zampetakis and Paul Kassianik and Blaine Nelson and Hyrum Anderson and Yaron Singer and Amin Karbasi , title =. arXiv preprint arXiv:2312.02119 , year =
-
[52]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Maksym Andriushchenko and Francesco Croce and Nicolas Flammarion , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[53]
34th USENIX Security Symposium (USENIX Security) , year =
Mark Russinovich and Ahmed Salem and Ronen Eldan , title =. 34th USENIX Security Symposium (USENIX Security) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.