Parallel Jacobi Decoding for Fast Autoregressive Image Generation
Pith reviewed 2026-06-28 02:03 UTC · model grok-4.3
The pith
Parallel Jacobi Decoding expands draft tokens into 2D space to accelerate autoregressive image generation 4.8x-6.4x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
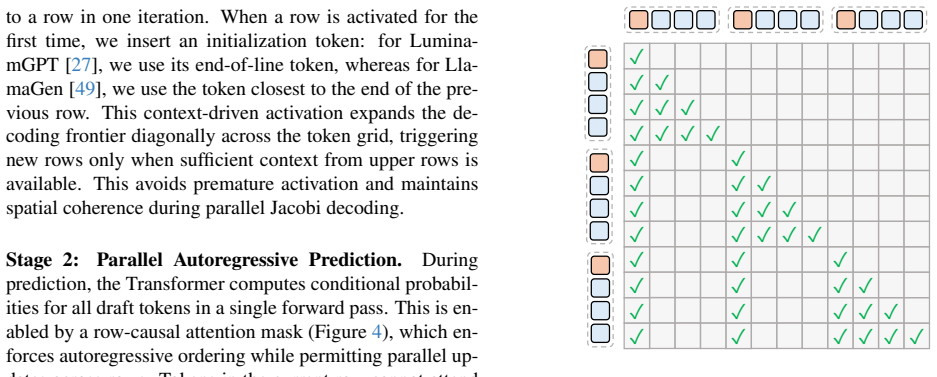
The authors introduce Parallel Jacobi Decoding (PJD), a training-free method that grows draft tokens across the two-dimensional spatial grid of an image rather than along a single sequence. This spatial expansion, combined with a modified attention mask, enables simultaneous refinement of multiple positions and reduces the convergence problems that appear in standard Jacobi decoding of images.
What carries the argument
Parallel Jacobi Decoding (PJD), which performs spatially parallel refinement of draft tokens in the 2D image domain together with an adjusted attention mask to control error propagation.
If this is right
- Inference latency drops by factors between 4.8x and 6.4x on existing autoregressive image models.
- No retraining is required, so the method can be applied directly to already-trained models.
- Generation quality remains competitive with the original sequential decoding.
- The approach works across multiple datasets and model architectures tested in the experiments.
Where Pith is reading between the lines
- The same spatial-parallel idea could be tested on other grid-structured generation tasks such as video frames or 3D voxel data.
- If local correlations prove weaker at very high resolutions, the acceleration factor may shrink unless the mask schedule is further tuned.
- Combining PJD with existing speculative decoding techniques might yield still larger speedups.
Load-bearing premise
Images contain strong local spatial correlations that support efficient parallel token refinement without large error spread once the attention mask is adjusted.
What would settle it
Measure whether generation quality collapses on image datasets deliberately constructed to lack local spatial correlations, such as scattered random patterns or highly abstract non-natural scenes.
Figures












read the original abstract
Autoregressive (AR) models have demonstrated remarkable performance in generating high-fidelity images. However, their inherently sequential next-token prediction leads to significantly slower inference. Recent studies have introduced Jacobi-style decoding to accelerate autoregressive image generation. Extending the draft sequence initially improves efficiency, yet the acceleration quickly saturates as error propagation in the one-dimensional sequence hinders convergence. Observing that images exhibit strong local spatial correlations, we propose Parallel Jacobi Decoding (PJD), a training-free decoding approach that expands draft tokens in the two-dimensional spatial domain to enable efficient spatially parallel refinement. PJD adjusts the attention mask to mitigate error accumulation and improve convergence stability. Extensive experiments on diverse datasets show that PJD achieves 4.8x-6.4x acceleration across multiple autoregressive image generation models while maintaining competitive generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Parallel Jacobi Decoding (PJD) is a training-free decoding method for autoregressive image generation models. It expands draft tokens in the 2D spatial domain (rather than 1D) to exploit local spatial correlations in images, adjusts the attention mask to mitigate error accumulation, and thereby achieves 4.8x–6.4x acceleration while retaining competitive generation quality on diverse datasets.
Significance. If the central empirical claim holds, the work would offer a practical, training-free route to faster inference for existing AR image generators by converting sequential decoding into spatially parallel refinement; the absence of free parameters and the focus on a decoding-only change are positive features.
major comments (1)
- [Abstract] Abstract and method description: the attention-mask adjustment that is asserted to 'mitigate error accumulation' is never given an explicit construction rule (e.g., which future positions remain visible, whether raster-order causality is preserved, or how the 2-D neighborhood is masked). Because this mask is the mechanism that is supposed to prevent the error-propagation saturation observed in prior 1-D Jacobi decoding, the 4.8x–6.4x speedup claim cannot be verified from the given text.
minor comments (1)
- The abstract states that 'extensive experiments … demonstrate the claimed speed-ups and quality retention' yet supplies no numerical metrics, baselines, or error bars; these must be added for the empirical claim to be inspectable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern regarding the lack of an explicit construction rule for the attention-mask adjustment is valid and will be addressed through revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the attention-mask adjustment that is asserted to 'mitigate error accumulation' is never given an explicit construction rule (e.g., which future positions remain visible, whether raster-order causality is preserved, or how the 2-D neighborhood is masked). Because this mask is the mechanism that is supposed to prevent the error-propagation saturation observed in prior 1-D Jacobi decoding, the 4.8x–6.4x speedup claim cannot be verified from the given text.
Authors: We agree that the current manuscript provides only a high-level description of the attention-mask adjustment and does not supply an explicit construction rule. This omission prevents full verification of the mechanism. In the revised manuscript we will add a dedicated subsection that states the precise mask construction: which future positions remain visible to each draft token, confirmation that raster-order causality is strictly preserved outside the 2-D neighborhood, and the exact rule used to mask the 2-D spatial neighborhood. These additions will make the error-mitigation strategy reproducible and will directly support the reported speed-up claims. revision: yes
Circularity Check
No circularity; training-free method rests on empirical observation and experimental validation
full rationale
The paper frames PJD as a training-free decoding change driven by the observation of local spatial correlations in images, with draft expansion in 2D and an attention-mask adjustment. No equations, fitted parameters, or self-citations are shown that reduce the reported 4.8x-6.4x acceleration or convergence claim to a quantity defined by the method's own inputs. The acceleration is presented as an empirical outcome measured across models and datasets, keeping the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Images exhibit strong local spatial correlations
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
-
[2]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Ja- son D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decod- ing heads.arXiv preprint arXiv:2401.10774, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[3]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean- Baptiste Lespiau, Laurent Sifre, and John Jumper. Acceler- ating large language model decoding with speculative sam- pling.arXiv preprint arXiv:2302.01318, 2023. 2, 3
Pith/arXiv arXiv 2023
-
[4]
Pixelsnail: An improved autoregressive generative model
Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, and Pieter Abbeel. Pixelsnail: An improved autoregressive generative model. InICML, 2018. 2
2018
-
[5]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
-
[6]
Ethan Chern, Jiadi Su, Yan Ma, and Pengfei Liu. Anole: An open, autoregressive, native large multimodal mod- els for interleaved image-text generation.arXiv preprint arXiv:2407.06135, 2024. 1, 3
arXiv 2024
-
[7]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InCVPR,
-
[8]
Sicheng Feng, Kaiwen Tuo, Song Wang, Lingdong Kong, Jianke Zhu, and Huan Wang. Rewardmap: Tackling sparse rewards in fine-grained visual reasoning via multi-stage rein- forcement learning.arXiv preprint arXiv:2510.02240, 2025. 4
arXiv 2025
-
[9]
Sicheng Feng, Song Wang, Shuyi Ouyang, Lingdong Kong, Zikai Song, Jianke Zhu, Huan Wang, and Xinchao Wang. Can mllms guide me home? a benchmark study on fine- grained visual reasoning from transit maps.arXiv preprint arXiv:2505.18675, 2025. 4
arXiv 2025
-
[10]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 1
Pith/arXiv arXiv 2024
-
[11]
Yefei He, Feng Chen, Yuanyu He, Shaoxuan He, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipar: Accelerating au- toregressive image generation through spatial locality.arXiv preprint arXiv:2412.04062, 2024. 3, 4
arXiv 2024
-
[12]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InNeurIPS, 2017. 6
2017
-
[13]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 1
2020
-
[14]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Os- tendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. InCVPR, 2023. 1
2023
-
[15]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capabil- ity in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025. 4
Pith/arXiv arXiv 2025
-
[16]
Lantern: Accelerating visual autoregressive models with relaxed speculative decoding
Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sungyub Kim, and Eunho Yang. Lantern: Accelerating visual autoregressive models with relaxed speculative decoding. InICLR, 2025. 2, 3
2025
-
[17]
Siyong Jian and Huan Wang. Ssd: Spatial-semantic head de- coupling for efficient autoregressive image generation.arXiv preprint arXiv:2510.18716, 2025. 3
arXiv 2025
-
[18]
Pixelcnn models with auxiliary variables for natural image modeling
Alexander Kolesnikov and Christoph H Lampert. Pixelcnn models with auxiliary variables for natural image modeling. InICML, 2017. 2
2017
-
[19]
Cllms: Consistency large language models
Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, and Hao Zhang. Cllms: Consistency large language models. InICML,
-
[20]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In ICML, 2023. 2, 3, 5
2023
-
[21]
Haopeng Li, Jinyue Yang, Guoqi Li, and Huan Wang. Au- toregressive image generation with randomized parallel de- coding.arXiv preprint arXiv:2503.10568, 2025. 3
arXiv 2025
-
[22]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. InNeurIPS, 2024. 3
2024
-
[23]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature un- certainty.arXiv preprint arXiv:2401.15077, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[24]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 2, 5, 1
2014
-
[25]
Evaluating text-to-visual generation with image-to-text gen- eration
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text gen- eration. InECCV, 2024. 1
2024
-
[26]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 1
Pith/arXiv arXiv 2024
-
[27]
Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yi Xin, Xinyue Li, Qi Qin, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-mgpt: Illuminate flexible photorealistic text- to-image generation with multimodal generative pretraining. arXiv preprint arXiv:2408.02657, 2024. 1, 2, 3, 5, 7
arXiv 2024
-
[28]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024. 3
Pith/arXiv arXiv 2024
-
[29]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. 2022. 2
2022
-
[30]
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high- resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023. 2
Pith/arXiv arXiv 2023
-
[31]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019. 5
2019
-
[32]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 1
2023
-
[33]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 6
2021
-
[34]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InICML, 2021. 2
2021
-
[35]
Hierarchical text-conditional image gen- eration with clip latents.arXiv preprint arXiv:2204.06125,
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gen- eration with clip latents.arXiv preprint arXiv:2204.06125,
-
[36]
Gener- ating diverse high-fidelity images with vq-vae-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Gener- ating diverse high-fidelity images with vq-vae-2. InNeurIPS,
-
[37]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 1
2022
-
[38]
Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022. 2
Pith/arXiv arXiv 2022
-
[39]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InNeurIPS, 2016. 6
2016
-
[40]
Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik P Kingma. Pixelcnn++: Improving the pixelcnn with dis- cretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517, 2017. 2
Pith/arXiv arXiv 2017
-
[41]
Accelerating transformer inference for translation via parallel decoding
Andrea Santilli, Silvio Severino, Emilian Postolache, Valentino Maiorca, Michele Mancusi, Riccardo Marin, and Emanuele Rodola. Accelerating transformer inference for translation via parallel decoding. InACL, 2023. 2, 3
2023
-
[42]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InECCV, 2024. 2
2024
-
[43]
Grouped speculative decoding for autoregressive im- age generation
Junhyuk So, Juncheol Shin, Hyunho Kook, and Eunhyeok Park. Grouped speculative decoding for autoregressive im- age generation. InICCV, 2025. 2, 3, 4, 6, 7, 1
2025
-
[44]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1
Pith/arXiv arXiv 2010
-
[45]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 1
Pith/arXiv arXiv 2011
-
[46]
Accelerating feedforward computation via parallel nonlinear equation solving
Yang Song, Chenlin Meng, Renjie Liao, and Stefano Ermon. Accelerating feedforward computation via parallel nonlinear equation solving. InICML, 2021. 3
2021
-
[47]
Consistency models.arXiv e-prints, 2023
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.arXiv e-prints, 2023. 2
2023
-
[48]
Block- wise parallel decoding for deep autoregressive models
Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Block- wise parallel decoding for deep autoregressive models. 2018. 2
2018
-
[49]
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 1, 2, 3, 5
Pith/arXiv arXiv 2024
-
[50]
Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 1, 3
Pith/arXiv arXiv 2024
-
[51]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1
Pith/arXiv arXiv 2023
-
[52]
Accelerating auto- regressive text-to-image generation with training-free specu- lative jacobi decoding
Yao Teng, Han Shi, Xian Liu, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, and Xihui Liu. Accelerating auto- regressive text-to-image generation with training-free specu- lative jacobi decoding. InICLR, 2025. 2, 3, 4, 5, 6, 7, 1
2025
-
[53]
Conditional image gen- eration with pixelcnn decoders
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image gen- eration with pixelcnn decoders. InNeurIPS, 2016. 2
2016
-
[54]
Pixel recurrent neural networks
Aron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. InICML,
-
[55]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InNeurIPS, 2017. 2, 3
2017
-
[56]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. 2017. 2
2017
-
[57]
Parallelized autoregressive visual generation
Yuqing Wang, Shuhuai Ren, Zhijie Lin, Yujin Han, Haoyuan Guo, Zhenheng Yang, Difan Zou, Jiashi Feng, and Xihui Liu. Parallelized autoregressive visual generation. InCVPR,
-
[58]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
-
[59]
Lumina-mgpt 2.0: Stand- alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025
Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Ren- rui Zhang, Le Zhuo, et al. Lumina-mgpt 2.0: Stand- alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025. 3
arXiv 2025
-
[60]
Imagere- ward: Learning and evaluating human preferences for text- to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation. InNeurIPS, 2023. 1
2023
-
[61]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1
Pith/arXiv arXiv 2025
-
[62]
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gun- jan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yin- fei Yang, Burcu Karagol Ayan, et al. Scaling autoregres- sive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2022. 2, 3, 5, 1
Pith/arXiv arXiv 2022
-
[63]
H2o: Heavy-hitter ora- cle for efficient generative inference of large language mod- els
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark Barrett, et al. H2o: Heavy-hitter ora- cle for efficient generative inference of large language mod- els. InNeurIPS, 2023. 3
2023
-
[64]
Zhuoyang Zhang, Luke J Huang, Chengyue Wu, Shang Yang, Kelly Peng, Yao Lu, and Song Han. Locality-aware parallel decoding for efficient autoregressive image genera- tion.arXiv preprint arXiv:2507.01957, 2025. 3 Parallel Jacobi Decoding for Fast Autoregressive Image Generation Supplementary Material A. Additional Quantitative Results Additional Metrics.We ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.