ProSPy: A Profiling-Driven SQL-Python Agentic Framework for Enterprise Text-to-SQL
Pith reviewed 2026-06-28 01:54 UTC · model grok-4.3
The pith
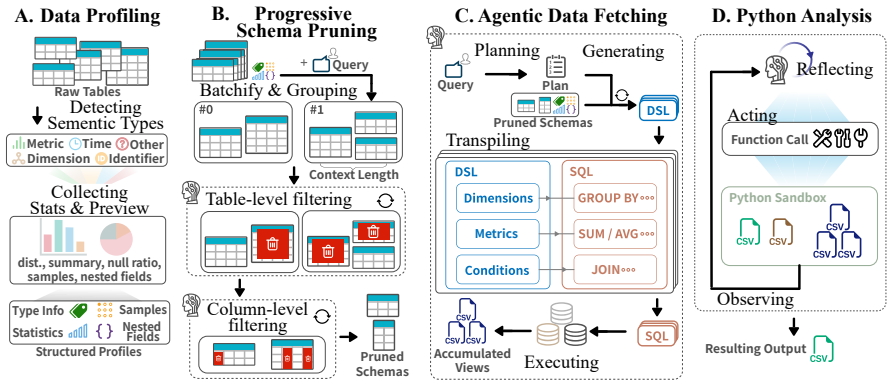
ProSPy structures Text-to-SQL reasoning into four stages that combine automatic profiling, schema pruning, dialect-agnostic SQL, and Python analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProSPy structures the reasoning process into four stages: it first extracts fine-grained data evidence through automatic profiling, progressively prunes large schemas into task-relevant contexts, fetches intermediate views through a dialect-agnostic SQL interface, and finally performs flexible downstream analysis with Python. This design combines the efficiency of SQL over large databases with the flexibility of Python-based analysis, while reducing reliance on unreliable metadata and improving robustness across SQL dialects.
What carries the argument
The four-stage profiling-driven SQL-Python agentic framework that extracts evidence, prunes schemas, generates views via SQL, and completes analysis in Python.
If this is right
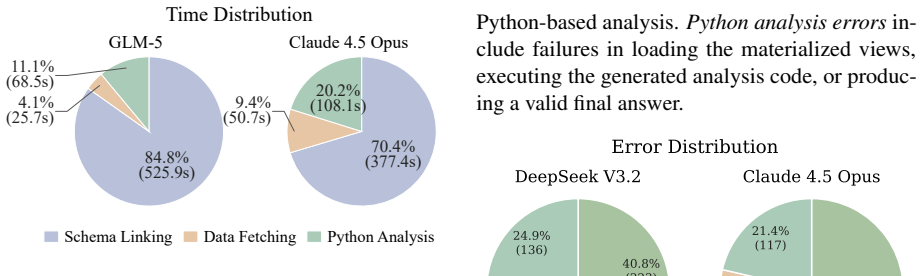
- Outperforms strong baselines on Spider 2.0-Lite and Spider 2.0-Snow with both open-source and proprietary models.
- Achieves execution accuracies of 60.15 percent and 60.51 percent with Claude-4.5-Opus without majority voting.
- Remains robust to SQL dialect variations.
- Delivers a favorable trade-off between schema recall and precision.
Where Pith is reading between the lines
- The same profiling-plus-pruning pattern could be tested on non-relational or streaming data sources where schema information is even less stable.
- The Python analysis stage opens the possibility of embedding statistical or machine-learning steps directly after SQL retrieval without separate pipelines.
- Lower reliance on metadata documentation could make the approach useful for legacy enterprise systems that lack up-to-date schema descriptions.
Load-bearing premise
Automatic profiling reliably extracts the needed fine-grained data evidence and progressive pruning keeps all task-relevant information without critical omissions in heterogeneous enterprise schemas.
What would settle it
A test case on a heterogeneous enterprise database where the profiling step misses key data patterns or pruning drops a required column, producing an incorrect final result that a single correct SQL query would have avoided.
Figures










read the original abstract
Large language models have substantially advanced Text-to-SQL systems, yet applying them to enterprise-scale databases remains challenging. Real-world databases often contain large and heterogeneous schemas, incomplete metadata, dialect-specific SQL syntax, and complex analytical questions that are difficult to solve with a single SQL query. To address these challenges, we propose ProSPy, a Profiling-driven SQL--Python agentic framework for enterprise-scale Text-to-SQL. ProSPy structures the reasoning process into four stages: it first extracts fine-grained data evidence through automatic profiling, progressively prunes large schemas into task-relevant contexts, fetches intermediate views through a dialect-agnostic SQL interface, and finally performs flexible downstream analysis with Python. This design combines the efficiency of SQL over large databases with the flexibility of Python-based analysis, while reducing reliance on unreliable metadata and improving robustness across SQL dialects. Experiments on Spider 2.0-Lite and Spider 2.0-Snow show that ProSPy consistently outperforms strong baselines with both open-source and proprietary models, achieving execution accuracies of 60.15% and 60.51% with Claude-4.5-Opus, without majority voting. Further analysis shows that ProSPy is robust to SQL dialect variations and achieves a favorable trade-off between schema recall and precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProSPy, a profiling-driven SQL-Python agentic framework for enterprise Text-to-SQL. It structures reasoning into four stages—automatic profiling to extract fine-grained data evidence, progressive schema pruning into task-relevant contexts, dialect-agnostic SQL for intermediate views, and Python for downstream analysis—targeting challenges of large heterogeneous schemas, incomplete metadata, and dialect variation. Experiments on Spider 2.0-Lite and Spider 2.0-Snow report execution accuracies of 60.15% and 60.51% with Claude-4.5-Opus (no majority voting), outperforming baselines, with additional analysis on dialect robustness and schema recall/precision trade-offs.
Significance. If the empirical results hold, the work offers a practical pipeline that combines SQL efficiency on large data with Python flexibility for complex analysis, while explicitly reducing metadata dependence. Credit is due for the ablation-style analysis and cross-dialect results that directly test the pipeline components, as well as the direct baseline comparisons on Spider 2.0 variants.
major comments (1)
- [§4] §4 (Experiments) and associated tables: the reported execution accuracies rest on the assumption that automatic profiling and progressive pruning preserve task-relevant information without critical omissions; while ablations and cross-dialect results are supplied, a quantitative breakdown of omission-induced failures on heterogeneous schemas would strengthen the load-bearing claim.
minor comments (2)
- [Abstract] Abstract: the four-stage description is clear but could explicitly note the Spider 2.0 variants used for each accuracy figure.
- [§3] Notation for schema pruning thresholds or profiling granularity is introduced without a dedicated definition table or equation reference.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the reported execution accuracies rest on the assumption that automatic profiling and progressive pruning preserve task-relevant information without critical omissions; while ablations and cross-dialect results are supplied, a quantitative breakdown of omission-induced failures on heterogeneous schemas would strengthen the load-bearing claim.
Authors: We agree that explicitly quantifying the proportion of failures attributable to information loss during automatic profiling or progressive pruning would provide stronger support for the claim that these stages preserve task-relevant information on heterogeneous schemas. Our existing schema recall/precision analysis and component ablations already demonstrate the overall effectiveness and trade-offs, but they do not isolate omission-induced errors. In the revised manuscript we will add a targeted error analysis subsection that samples failure cases from Spider 2.0-Lite and Spider 2.0-Snow, manually categorizes them by root cause (profiling omission, pruning omission, SQL generation, Python analysis, or other), and reports the percentages. This will directly address the referee's request without altering the reported accuracies. revision: yes
Circularity Check
No circularity: empirical framework with reported accuracies
full rationale
The paper describes a four-stage agentic pipeline (profiling, pruning, dialect-agnostic SQL views, Python analysis) and reports execution accuracies (60.15% and 60.51% on Spider 2.0 variants) as direct experimental outcomes from comparisons to baselines. No equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central claims rest on empirical measurements rather than any derivation chain that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Text-to-sql as dual-state reasoning: Integrating adaptive context and progressive generation.arXiv preprint arXiv:2511.21402. Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin SU, ZHAOQING SUO, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluat...
arXiv 2025
-
[2]
This is a multi-round iterative process; in each round, you only need to exclude the most obviously irrelevant tables
-
[3]
The input includes complete field information (profiling); please refer to field information to judge table relevance
-
[4]
If any field in a table is related to the question, that table must be retained
-
[5]
In subsequent rounds, you will receive a more streamlined schema and can further exclude less relevant tables
-
[6]
This stage only excludes tables, not fields (field exclusion is done in the next stage) Please analyze according to the following conservative exclusion strategy: -------------------------------------- Exclude Obviously Irrelevant Tables -------------------------------------- Based on question semantics and field information, only exclude tables that meet...
-
[7]
The table's core business domain clearly does not match the question's topic (e.g., the question is about user behavior, but the table only stores system logs)
-
[8]
The table's time range is completely incompatible with the question's time requirements (e.g., the question requires 2024 data, but the table only contains data before 2022)
2024
-
[9]
ALL fields of the table are irrelevant to the question (please carefully check field profiling information)
-
[10]
The table is NOT an intermediate table or dimension table that other related tables must JOIN through
-
[11]
who knows whom
The table does NOT contain data related to any entity, concept, or synonym mentioned in the question Exclusion principle: As long as a table may have a direct, indirect, or potential association with the question, firmly retain it. Figure 5: Prompt used for the first-pass table pruning stage (Part 1/2). 15 Prompt for Schema Pruning First Pass (Part 2/2) S...
-
[13]
Table names must exactly match those provided in the input, including case and path
-
[14]
Do not exclude any tables that may be indirectly related through JOINs, subqueries, or complex logic
-
[15]
If no tables can be safely excluded, return an empty array
-
[18]
When the question involves multi-entity comparisons, relationship chain queries, or complex aggregations, be extremely conservative and tend to retain more tables
-
[19]
Only exclude the most obviously irrelevant tables in each round; leave uncertain ones for subsequent rounds
-
[20]
16 Prompt for Schema Pruning Fields (Part 1/2) You are a rigorous database query expert, skilled at identifying data fields that are irrelevant to natural language questions
**The number of excluded_tables must be less than the total number of input tables**; excluding all tables is not allowed Figure 5: Prompt used for the first-pass table pruning stage (Part 2/2). 16 Prompt for Schema Pruning Fields (Part 1/2) You are a rigorous database query expert, skilled at identifying data fields that are irrelevant to natural languag...
-
[21]
This is a multi-round iterative process; in each round, you only need to exclude the most obviously irrelevant fields
-
[22]
Tables have already been filtered in the first stage; this stage only excludes fields
-
[23]
In subsequent rounds, you will receive a more streamlined schema and can further exclude less relevant fields
-
[24]
latest",
Please carefully refer to field profiling information (data type, value range, examples, etc.) to judge field relevance Please analyze according to the following conservative exclusion strategy: -------------------------------------- Exclude Obviously Irrelevant Fields (Processed by Category) -------------------------------------- Based on question semant...
2023
-
[25]
Exclusions must be based on clear, indisputable reasons; any uncertainty should result in retention
-
[26]
Field names must exactly match those provided in the input, including case and path
-
[27]
If no fields can be safely excluded, return an empty array
-
[28]
Only return JSON, without any prefix, suffix, or Markdown formatting
-
[29]
Conservative is the first principle: false retention is more acceptable than false exclusion
-
[30]
When the question involves multi-entity comparisons, relationship chain queries, or complex aggregations, be extremely conservative and tend to retain more fields
-
[31]
table names
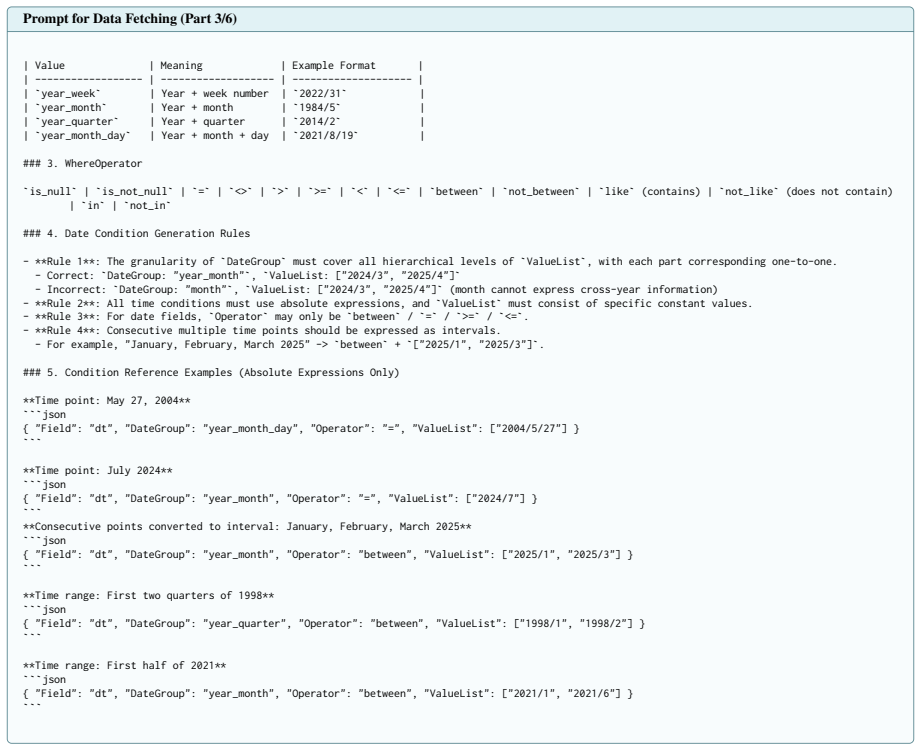
Only exclude the most obviously irrelevant fields in each round; leave uncertain ones for subsequent rounds Figure 6: Prompt used for the field pruning stage (Part 2/2). 18 Prompt for Data Fetching (Part 1/6) You are a data scientist and SQL expert proficient in data analysis. Based on the user's question and table schema information, you can generate mul...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.