Edit-R2: Context-Aware Reinforcement Learning for Multi-Turn Image Editing
Pith reviewed 2026-06-29 05:08 UTC · model grok-4.3
The pith
Edit-R2 reconstructs session intent to enable reliable multi-turn image editing with reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
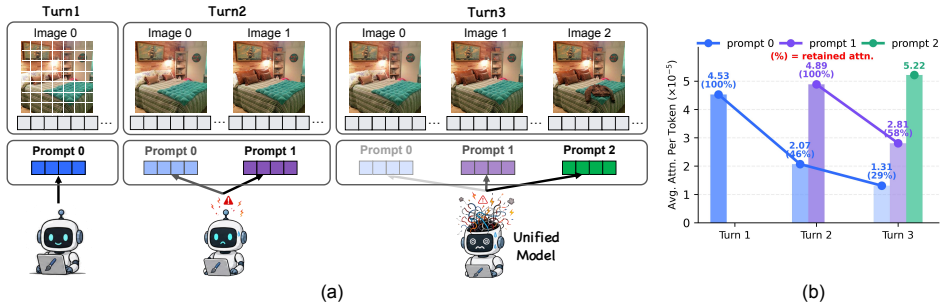
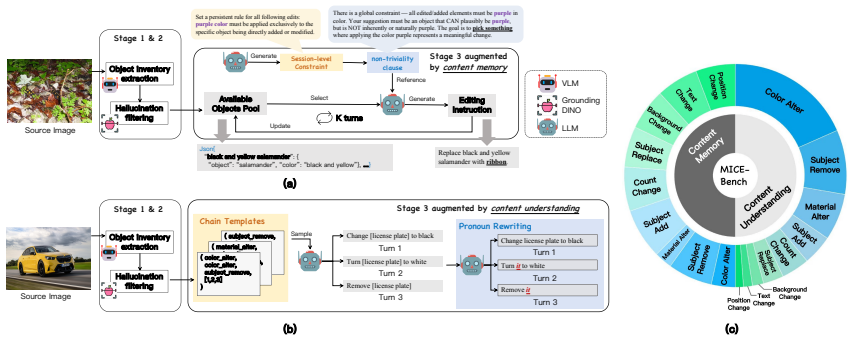
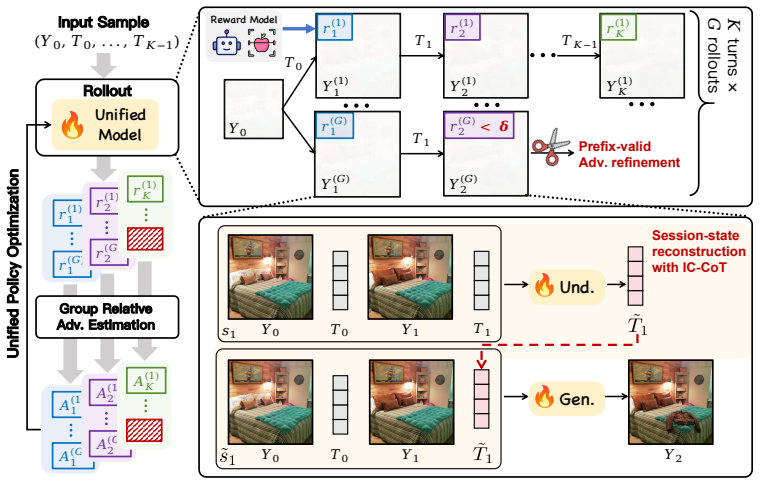
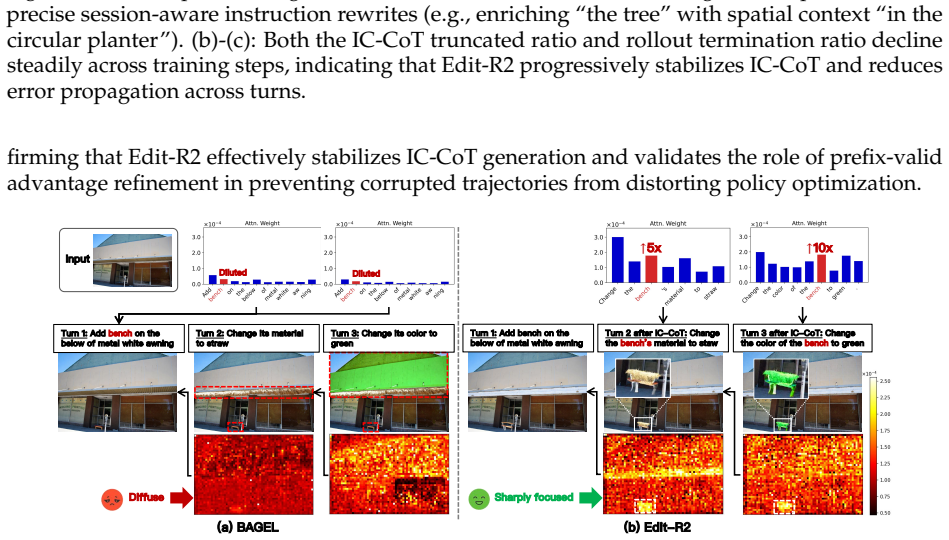
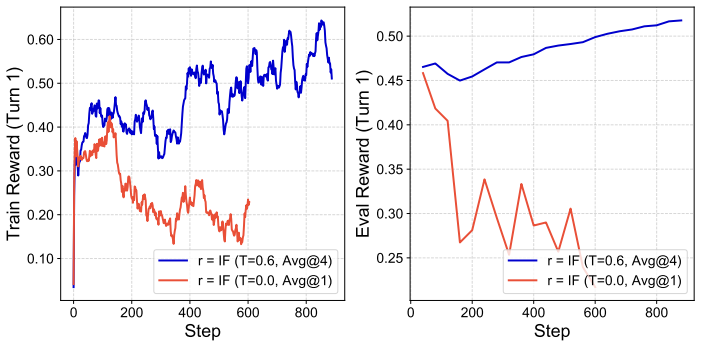
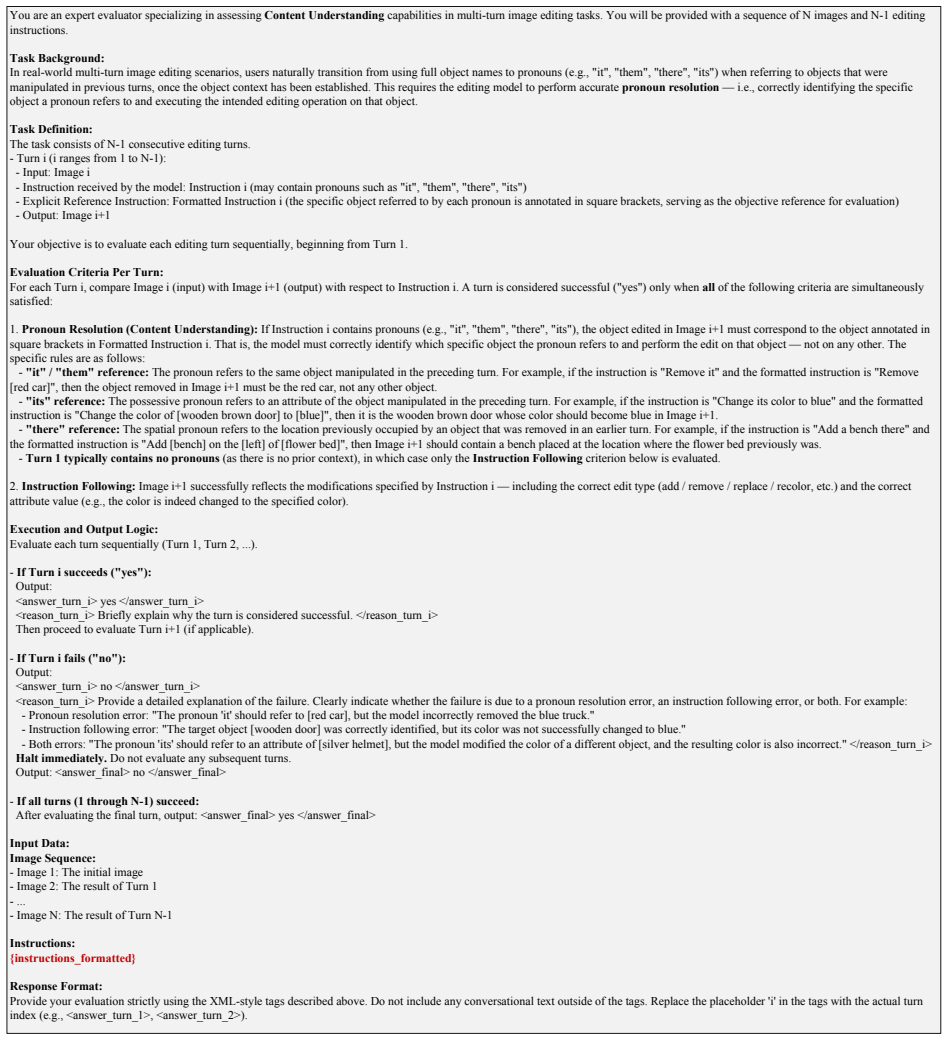
Edit-R2 reconstructs the operative session intent to consolidate scattered historical constraints into an explicit reasoning trace before each editing turn, and applies multi-turn RL over both reasoning and generation through a unified objective that jointly optimizes intent reconstruction in text space and flow-matching image generation in latent space, while using trajectory filtering to suppress corrupted rollouts.
What carries the argument
Operative session intent reconstruction that turns scattered constraints into an explicit reasoning trace, paired with a unified RL objective across discrete text and continuous image spaces plus trajectory filtering.
If this is right
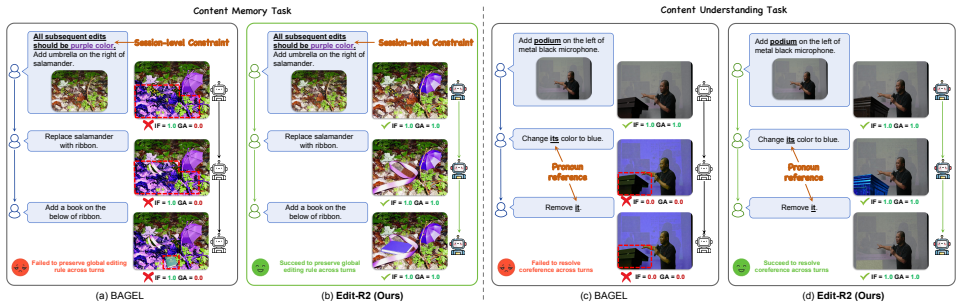
- Multi-turn editing models follow new instructions while preserving all accumulated session constraints.
- Earlier editing mistakes have less negative effect on later turns due to state contamination reduction.
- The method yields competitive results against strong baselines on instruction following, content consistency, and global awareness.
- Systematic evaluation becomes possible through the introduced MICE-Bench benchmark with automated metrics.
Where Pith is reading between the lines
- Similar intent reconstruction could apply to other sequential tasks involving history like conversational agents or iterative design tools.
- Future work might test if this approach scales to longer sessions or different modalities such as video.
- The trajectory filtering mechanism may generalize to other RL setups prone to error accumulation.
Load-bearing premise
Reconstructing the operative session intent consolidates scattered historical constraints into an explicit reasoning trace that prevents long-context dilution and state contamination.
What would settle it
If models trained with Edit-R2 show no gains in multi-turn performance metrics over standard fine-tuning on the MICE-Bench dataset, the central claim would not hold.
Figures






















read the original abstract
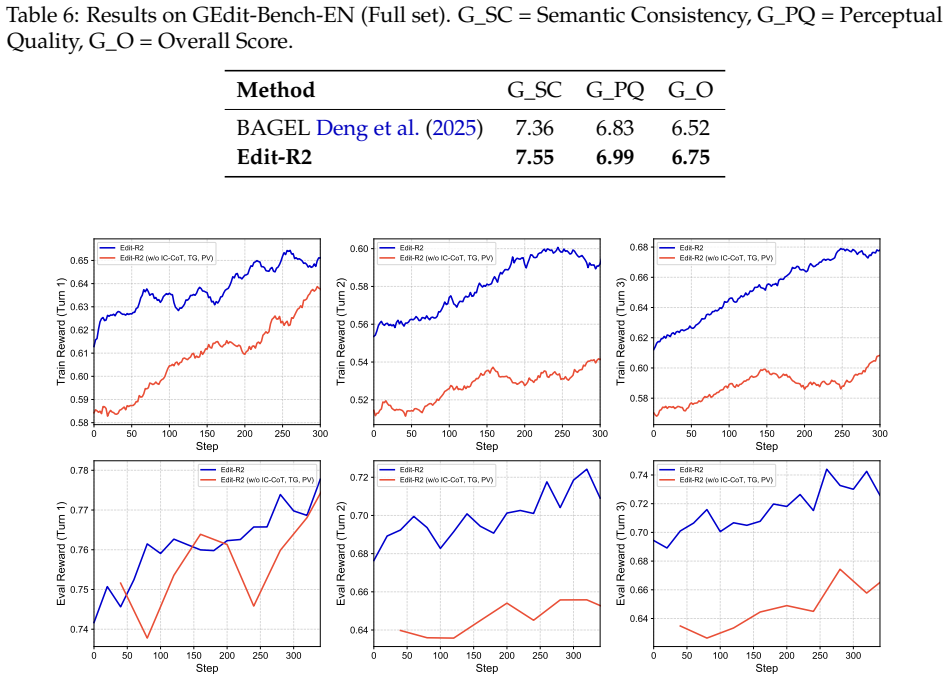
Text-guided image editing has advanced rapidly with diffusion models and unified multimodal foundation models. However, most existing methods remain confined to single-turn settings, overlooking the more realistic scenario of multi-turn in-context editing, where users iteratively refine an image through a sequence of instructions. In this setting, a model must follow each new instruction while preserving accumulated session-level constraints, challenged by two coupled failure modes: long-context dilution, where sparse textual constraints become difficult to recover from growing interleaved image-text histories, and state contamination, where earlier editing mistakes degrade subsequent generations. We introduce Edit-R2, a novel reinforcement learning post-training framework for unified multimodal models. Edit-R2 reconstructs the operative session intent, which effectively consolidates scattered historical constraints into an explicit reasoning trace before each editing turn. It further enables multi-turn RL over both reasoning and generation through a unified objective that jointly optimizes intent reconstruction generation in discrete text space and flow-matching image generation in continuous latent space, while a trajectory filtering mechanism suppresses corrupted rollouts to stabilize training under state contamination. To support systematic evaluation, we introduce MICE-Bench, a large-scale benchmark for multi-turn in-context editing with automated metrics for instruction following (IF), content consistency (CC), and global awareness (GA) over accumulated session constraints. Experiments show that Edit-R2 substantially improves multi-turn in-context editing and achieves competitive performance compared against strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Edit-R2, a reinforcement learning post-training framework for multi-turn in-context image editing with unified multimodal models. It reconstructs operative session intent to consolidate historical constraints into an explicit reasoning trace, applies a unified RL objective jointly optimizing discrete-text intent reconstruction and continuous-latent flow-matching image generation, incorporates trajectory filtering to suppress corrupted rollouts, and introduces the MICE-Bench benchmark with automated metrics for instruction following (IF), content consistency (CC), and global awareness (GA). Experiments are reported to show substantial improvements and competitive performance against strong baselines.
Significance. If the empirical claims hold, the work addresses a realistic and underexplored setting in text-guided image editing by mitigating long-context dilution and state contamination through intent reconstruction and filtering. The introduction of MICE-Bench provides a standardized evaluation resource, and the unified cross-modal RL objective represents a technically interesting direction for multimodal post-training. These elements could influence subsequent research on iterative multimodal agents if the gains are reproducible and the method generalizes.
major comments (2)
- [Abstract] Abstract: The central claim that Edit-R2 'substantially improves multi-turn in-context editing' is stated without any numerical results, error bars, ablation tables, or statistical tests. This absence prevents verification of the magnitude or reliability of the reported gains and is load-bearing for assessing whether the unified RL objective and trajectory filtering deliver the claimed benefits.
- [Method] Method description (unified objective): It is unclear from the high-level description whether the joint optimization over discrete text space and continuous latent space uses separate reward models or a single shared signal, and whether any component of the objective is fitted on data that overlaps with the MICE-Bench evaluation set. This directly affects the circularity concern for the performance claims.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., average IF or GA improvement) to support the 'substantially improves' statement.
- [Method] Notation for the unified RL objective and the trajectory filtering threshold should be defined explicitly with equations if they appear in the full text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and substantiation of claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Edit-R2 'substantially improves multi-turn in-context editing' is stated without any numerical results, error bars, ablation tables, or statistical tests. This absence prevents verification of the magnitude or reliability of the reported gains and is load-bearing for assessing whether the unified RL objective and trajectory filtering deliver the claimed benefits.
Authors: We agree that the abstract would be strengthened by including representative quantitative results. In the revised version we will add concise numerical highlights of the main gains (e.g., relative improvements on IF, CC, and GA) together with pointers to the corresponding tables and figures. Full error bars, ablation tables, and statistical tests remain in the experiments section; space constraints preclude their inclusion in the abstract itself. revision: yes
-
Referee: [Method] Method description (unified objective): It is unclear from the high-level description whether the joint optimization over discrete text space and continuous latent space uses separate reward models or a single shared signal, and whether any component of the objective is fitted on data that overlaps with the MICE-Bench evaluation set. This directly affects the circularity concern for the performance claims.
Authors: We will revise the method section to state explicitly that a single shared multimodal reward signal is used for both the discrete intent-reconstruction and continuous flow-matching objectives. We will also add a clear statement that the RL training trajectories are drawn from a held-out collection distinct from the MICE-Bench evaluation set, thereby removing any circularity concern. These additions address the high-level description without altering the underlying algorithm. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a post-training RL framework (intent reconstruction + unified objective over text reasoning and flow-matching generation + trajectory filtering) evaluated on a newly introduced benchmark MICE-Bench. No equations, derivations, or self-citations are shown that reduce any claimed prediction or result to a fitted input or prior self-result by construction. The central claims rest on experimental comparisons to external baselines rather than internal redefinitions or tautological steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
it,” “them,
Coreference resolution: replace vague pronouns (“it,” “them,” “its,” etc.) with the specific object names visible in the current imageY t
-
[2]
BAGEL w/ think
Global constraint injection: if any earlier turn specifies a persistent constraint (e.g., a color or material requirement for all subsequent edits), explicitly incorporate that constraint into the current instruction. Examples of QCoT are shown in Figure 14. Note that these questions are tailored to MICE-Bench, which differ from BAGEL’s original thinking ...
2026
-
[3]
Replace any vague pronouns (it, them, they, its, the one, etc.) with the specific object names visible in the image
-
[4]
Think briefly, under 100 words
If any earlier round specifies a persistent global constraint (e.g., 'Ensure all subsequent edits are yellow', 'Use leather material for all edits'), explicitly incorporate that constraint into the current instruction. Think briefly, under 100 words. Output ONLY the enhanced instruction. No explanation, no extra text. Figure 14: Illustration ofQ CoT. 29 Y...
-
[5]
Instruction Adherence: Image i+1 successfully reflects the modifications specified by Instruction i
-
[6]
objects added or modified in subsequent edits must be yellow
Global Constraint Compliance: If the first instruction establishes a global constraint that governs the entire editing session (e.g., "objects added or modified in subsequent edits must be yellow"), then Image i+1 must adhere to this constraint. The specific rules are as follows: - Scope of Application: Global constraint compliance is required only with r...
-
[7]
it", "them
Pronoun Resolution (Content Understanding): If Instruction i contains pronouns (e.g., "it", "them", "there", "its"), the object edited in Image i+1 must correspond to the object annotated in square brackets in Formatted Instruction i. That is, the model must correctly identify which specific object the pronoun refers to and perform the edit on that object...
-
[8]
The pronoun 'it' should refer to [red car], but the model incorrectly removed the blue truck
Instruction Following: Image i+1 successfully reflects the modifications specified by Instruction i — including the correct edit type (add / remove / replace / recolor, etc.) and the correct attribute value (e.g., the color is indeed changed to the specified color). Execution and Output Logic: Evaluate each turn sequentially (Turn 1, Turn 2, ...). - If Tu...
-
[9]
- Wool grey scarf and plastic black glasses remain unchanged, meeting the instruction
**Instruction Following:** - Background successfully changed to a red curtain, meeting the instruction. - Wool grey scarf and plastic black glasses remain unchanged, meeting the instruction
-
[10]
Here, the background was modified to a red curtain, which complies with the constraint
**Global Constraint Following:** - The global constraint specifies that red color can only be applied to directly added or modified objects. Here, the background was modified to a red curtain, which complies with the constraint. **Conclusion:** <answer_turn_1> yes </answer_turn_1> <reason_turn_1> Background successfully changed to a red curtain, wool grey...
-
[11]
**Instruction Following:** - The wool grey scarf has been successfully removed, meeting the instruction
-
[12]
**Global Constraint Following:** - The instruction is to remove an object, which does not involve adding or modifying objects; thus, the global constraint is irrelevant. **Conclusion:** <answer_turn_2> yes </answer_turn_2> <reason_turn_2> Wool grey scarf successfully removed, meeting the instruction; removal operation does not require considering the glob...
-
[13]
change the material to metal
**Instruction Following:** - The material of the glasses has been successfully changed from plastic to metal, meeting the instruction requirement of "change the material to metal."
-
[14]
directly modified object
**Global Constraint Following:** - The global constraint states that in all subsequent edits, red color can only be applied to directly added or modified objects. The object modified in this round is the glasses, whose material was changed to metal, making it a "directly modified object." According to the global constraint, this modified object should be ...
-
[15]
**Instruction Following:** - The material of the plastic black glasses has been successfully changed to red metal, meeting the instruction
-
[16]
Here, the glasses' material was changed to metal, and red color is applied only to the glasses themselves, complying with the constraint
**Global Constraint Following:** - The global constraint states that red color can only be applied to directly added or modified objects. Here, the glasses' material was changed to metal, and red color is applied only to the glasses themselves, complying with the constraint. **Conclusion:** <answer_turn_3> yes </answer_turn_3> <reason_turn_3> The material...
-
[18]
In Image 2, an orange flower has indeed been added to the left of the black plastic handle, meeting the instruction
**Instruction Following:** - The instruction requires adding a flower to the left of the black plastic handle. In Image 2, an orange flower has indeed been added to the left of the black plastic handle, meeting the instruction. **Conclusion:** <answer_turn_1> yes </answer_turn_1> <reason_turn_1> The instruction requires adding a flower to the left of the ...
-
[19]
According to the explicit reference instruction, the model needs to change the color of the flower
**Pronoun Resolution (Content Understanding):** - The pronoun "its" in the instruction refers to the object added in the previous round, i.e., the flower. According to the explicit reference instruction, the model needs to change the color of the flower. However, the model did not correctly understand that "its" refers to the newly added flower in the fir...
-
[20]
Therefore, the instruction is not correctly followed
**Instruction Following:** - Although the model changed a flower to orange, it operated on the wrong object (the original flower rather than the newly added one). Therefore, the instruction is not correctly followed. **Conclusion:** <answer_turn_2> no </answer_turn_2> <reason_turn_2> The model failed to correctly understand that "its" refers to the flower...
-
[21]
**Pronoun Resolution (Content Understanding):** - The instruction in this turn contains no pronouns, so pronoun resolution is not required
-
[22]
Observing Image 2, a yellow flower has indeed been added to the left of the plastic black handle
**Instruction Following:** - The instruction requires adding a flower to the left of the plastic black handle. Observing Image 2, a yellow flower has indeed been added to the left of the plastic black handle. **Conclusion:** <answer_turn_1> yes </answer_turn_1> <reason_turn_1> The instruction requires adding a flower to the left of the plastic black handl...
-
[23]
its" in this turn refers to the flower added in the previous round. The explicit reference instruction clearly refers to
**Pronoun Resolution (Content Understanding):** - The pronoun "its" in this turn refers to the flower added in the previous round. The explicit reference instruction clearly refers to "[flower]", i.e., the yellow flower added in the previous round. The model indeed changes the color of the flower to orange in Image 3, so pronoun resolution is correct
-
[24]
Observing Image 3, the flower's color has been successfully changed to orange
**Instruction Following:** - The instruction requires changing the color of the flower to orange. Observing Image 3, the flower's color has been successfully changed to orange. **Conclusion:** <answer_turn_2> yes </answer_turn_2> <reason_turn_2> The instruction requires changing the color of the flower to orange. Image 3 successfully changes the flower's ...
-
[25]
it" in this turn refers to the orange flower edited in the previous round. The explicit reference instruction clearly refers to
**Pronoun Resolution (Content Understanding):** - The pronoun "it" in this turn refers to the orange flower edited in the previous round. The explicit reference instruction clearly refers to "[orange flower]", i.e., the flower whose color was changed to orange in the previous round. The model indeed removes the orange flower in Image 4, so pronoun resolut...
-
[26]
Observing Image 4, the orange flower has been removed, meeting the instruction
**Instruction Following:** - The instruction requires removing the orange flower. Observing Image 4, the orange flower has been removed, meeting the instruction. **Conclusion:** <answer_turn_3> yes </answer_turn_3> <reason_turn_3> The instruction requires removing the orange flower. Image 4 successfully removes the orange flower, meeting the instruction. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.