ReSAGE-PAR: Representational Similarity Assessment for Generative Expansion in Pedestrian Attribute Recognition
Pith reviewed 2026-06-28 02:21 UTC · model grok-4.3
The pith
ReSAGE-PAR expands pedestrian attribute datasets by adapting diffusion models and converting vision-language scores into reliable pseudo-labels via Bayesian classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReSAGE-PAR adapts pre-trained diffusion models to PAR resolutions with a LoRA-based image-to-image method, extracts vision-language alignment scores using a comprehensive prompting strategy of label-consistent and inconsistent complements, and applies a Bayesian classifier to convert the scores into binary pseudo-labels that verify attributes and prevent generative hallucinations.
What carries the argument
The ReSAGE-PAR generate-score-autolabel pipeline, which relies on vision-language alignment scores from mixed prompting and the Bayesian classifier to turn those scores into verified binary pseudo-labels.
If this is right
- Integration into PAR training produces gains of up to 8.7 percent on standard backbones.
- State-of-the-art PAR frameworks reach new performance levels when the expanded data is added.
- The approach remains architecture-agnostic and scales dataset size while preserving spatial priors.
- Attribute verification succeeds across generated images without introducing hallucinations.
Where Pith is reading between the lines
- The same verification loop could be tested on attribute recognition tasks outside surveillance, such as clothing or medical imaging.
- If the Bayesian step proves robust, similar score-to-label pipelines might reduce reliance on manual annotation in other generative data-augmentation settings.
- Evaluating the method on additional low-resolution surveillance datasets would test whether the domain adaptation generalizes beyond the reported backbones.
Load-bearing premise
Vision-language alignment scores obtained from the prompting strategy can be converted by the Bayesian classifier into reliable binary pseudo-labels that accurately verify attributes and prevent generative hallucinations.
What would settle it
Running PAR training on the expanded dataset and checking whether accuracy gains disappear or reverse when the Bayesian pseudo-labels are replaced by human verification of the same generated images.
Figures


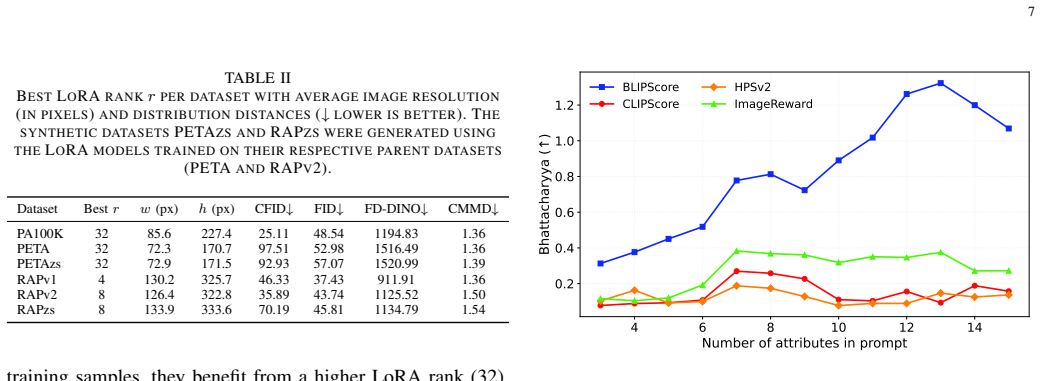


read the original abstract
To address the limited diversity and data scarcity in Pedestrian Attribute Recognition (PAR), we explore image synthesis using diffusion models guided by attribute-based prompts. While this enables the controlled generation of pedestrian images, it faces two critical challenges: (i) the domain gap between high-quality pre-training data and low-resolution, non-standard surveillance crops, and (ii) the need for reliable attribute verification to prevent generative hallucinations. In this paper, we introduce a robust generate-score-autolabel pipeline called ReSAGE-PAR (REpresentational Similarity Assessment for Generative Expansion in PAR) that bridges this domain gap and enables scalable, high-fidelity dataset expansion. First, we adapt pre-trained diffusion models to native PAR resolutions using a tailored LoRA-based Image-to-Image approach. Second, we extract vision-language alignment scores between the generated images and their conditioning prompts, utilizing a comprehensive prompting strategy that includes label-consistent and inconsistent complements. Finally, we formulate a Bayesian classifier that converts these continuous scores into reliable binary pseudo-labels. Extensive evaluations demonstrate the effectiveness of ReSAGE-PAR in preserving spatial priors and verifying attributes. When integrated into PAR training, ReSAGE-PAR consistently yields significant improvements-achieving gains of up to 8.7% on standard backbones and pushing state-of-the-art frameworks to new performance levels. This proves its value as an architecture-agnostic solution for scalable PAR enhancement. The complete codebase for ReSAGE-PAR is publicly available at http://www-vpu.eps.uam.es/publications/ReSAGE-PAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ReSAGE-PAR, a generate-score-autolabel pipeline for expanding Pedestrian Attribute Recognition (PAR) datasets via diffusion models. It adapts pre-trained diffusion models to PAR resolutions with a LoRA-based image-to-image approach, extracts vision-language alignment scores using label-consistent and inconsistent prompting, and applies a Bayesian classifier to produce binary pseudo-labels from these scores. The central claim is that this pipeline bridges the domain gap, prevents generative hallucinations, preserves spatial priors, and when the resulting data is integrated into PAR training yields consistent gains of up to 8.7% on standard backbones while advancing state-of-the-art frameworks; the codebase is released publicly.
Significance. If the pseudo-labels are shown to be accurate and the performance gains are reproducible with proper controls, the work could provide a practical, architecture-agnostic route to scalable dataset expansion for data-scarce surveillance tasks such as PAR. The public code release is a clear strength supporting reproducibility.
major comments (2)
- [Bayesian classifier and pseudo-label verification] The headline performance claims (up to 8.7% gains and SOTA improvements) rest on the assumption that the Bayesian classifier converts VL alignment scores into accurate binary pseudo-labels. No quantitative validation of pseudo-label quality—such as precision, recall, or agreement rate against ground-truth attributes on held-out labeled data—is reported in the experimental section, leaving open the possibility that domain-gap or CLIP-induced mislabeling injects noise rather than signal.
- [Experimental evaluation] The experimental results section asserts 'extensive evaluations' and specific numerical gains but supplies no details on the number of generated images, exact PAR datasets and metrics, baseline implementations, number of runs, error bars, or ablation isolating the contribution of the pseudo-labeling step versus the LoRA adaptation alone.
minor comments (2)
- [Abstract] The abstract would be strengthened by briefly naming the PAR datasets and evaluation metrics used to obtain the reported gains.
- [Method] Notation for the alignment scores and the precise form of the Bayesian classifier (prior, likelihood model) should be defined explicitly with equations in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of pseudo-label quality and more complete experimental details. We address each major comment below and will incorporate the requested information and analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Bayesian classifier and pseudo-label verification] The headline performance claims (up to 8.7% gains and SOTA improvements) rest on the assumption that the Bayesian classifier converts VL alignment scores into accurate binary pseudo-labels. No quantitative validation of pseudo-label quality—such as precision, recall, or agreement rate against ground-truth attributes on held-out labeled data—is reported in the experimental section, leaving open the possibility that domain-gap or CLIP-induced mislabeling injects noise rather than signal.
Authors: We agree that direct quantitative validation of the pseudo-labels is essential to support the performance claims. The current manuscript does not report precision, recall, or agreement rates against ground-truth on held-out data. In the revision we will add a dedicated subsection (or appendix) that evaluates pseudo-label accuracy on held-out labeled PAR data, reporting precision, recall, F1, and agreement rates for the Bayesian classifier output. This will directly address concerns about noise versus signal. revision: yes
-
Referee: [Experimental evaluation] The experimental results section asserts 'extensive evaluations' and specific numerical gains but supplies no details on the number of generated images, exact PAR datasets and metrics, baseline implementations, number of runs, error bars, or ablation isolating the contribution of the pseudo-labeling step versus the LoRA adaptation alone.
Authors: We acknowledge the lack of these specifics in the current text. The revised manuscript will expand the experimental section to explicitly state: (i) the exact number of generated images per dataset, (ii) the precise PAR datasets, splits, and metrics used, (iii) baseline implementation details (including any public code references), (iv) the number of runs and error bars (standard deviation across seeds), and (v) a new ablation isolating the pseudo-labeling step from LoRA adaptation alone. These additions will make the evaluation fully reproducible and transparent. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on external benchmarks
full rationale
The paper presents a generate-score-autolabel pipeline (LoRA adaptation of diffusion models, VL alignment scoring via consistent/inconsistent prompts, Bayesian classifier for pseudo-labels) and reports accuracy gains when the resulting data is added to PAR training. No equations, fitted parameters, or self-citations are shown that reduce the reported 8.7% gains or SOTA improvements to quantities defined by the method itself. The central claims rest on external pre-trained models (diffusion, CLIP) and standard PAR benchmarks, which are independent of the paper's fitted values. This is the normal case of a self-contained empirical method paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language alignment scores can be reliably mapped to binary attribute labels via Bayesian classification
Reference graph
Works this paper leans on
-
[1]
Human attribute recognition—a comprehensive survey,
E. Yaghoubi, F. Khezeli, D. Borza, S. A. Kumar, J. Neves, and H. Proenc ¸a, “Human attribute recognition—a comprehensive survey,” Appl. Sci., vol. 10, no. 16, p. 5608, 2020
2020
-
[2]
Pedestrian attribute recogni- tion at far distance,
Y . Deng, P. Luo, C. C. Loy, and X. Tang, “Pedestrian attribute recogni- tion at far distance,” inProc. ACM Int. Conf. Multimedia (ACM MM), 2014, pp. 789–792
2014
-
[3]
A richly annotated dataset for pedestrian attribute recognition,
D. Li, Z. Zhang, X. Chen, H. Ling, and K. Huang, “A richly annotated dataset for pedestrian attribute recognition,”arXiv:1603.07054, 2016
Pith/arXiv arXiv 2016
-
[4]
A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios,
D. Li, Z. Zhang, X. Chen, and K. Huang, “A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios,”IEEE Trans. Image Process., vol. 28, no. 4, pp. 1575–1590, 2019
2019
-
[5]
HydraPlus-Net: Attentive deep features for pedestrian analysis,
X. Liu, H. Zhao, M. Tian, L. Sheng, J. Shao, S. Yi, J. Yan, and X. Wang, “HydraPlus-Net: Attentive deep features for pedestrian analysis,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 350–359
2017
-
[6]
J. Jia, H. Huang, X. Chen, and K. Huang, “Rethinking of pedestrian attribute recognition: A reliable evaluation under zero-shot pedestrian identity setting,”arXiv:2107.03576, 2021
arXiv 2021
-
[7]
Joint discriminative and generative learning for person re-identification,
Z. Zheng, X. Yang, Z. Yu, L. Zheng, Y . Yang, and J. Kautz, “Joint discriminative and generative learning for person re-identification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 2138–2147
2019
-
[8]
Image- image domain adaptation with preserved self-similarity and domain- dissimilarity for person re-identification,
W. Deng, L. Zheng, Q. Ye, G. Kang, Y . Yang, and J. Jiao, “Image- image domain adaptation with preserved self-similarity and domain- dissimilarity for person re-identification,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 994–1003
2018
-
[9]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” inAdv. Neural Inform. Process. Syst. (NeurIPS), vol. 34, 2021, pp. 8780–8794
2021
-
[10]
Effective data augmentation with diffusion models,
B. Trabuccoet al., “Effective data augmentation with diffusion models,” arXiv:2302.07944, 2023
arXiv 2023
-
[11]
LAION-5b: An open large-scale dataset for training next genera- tion image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “LAION-5b: An open large-scale dataset for training next genera- tion image-text models,” inProc. Adv. Neural Inform. Process. Syst. (NeurIPS) Datasets Benchmarks Track, 2022
2022
-
[12]
CLIPScore: A reference-free evaluation metric for image captioning,
J. Hessel, A. Holtzman, M. Forbes, R. L. Bras, and Y . Choi, “CLIPScore: A reference-free evaluation metric for image captioning,” inProceedings of the Conference on Empirical Methods in Natural Language Process- ing (EMNLP), 2021
2021
-
[13]
Enhancing zero- shot pedestrian attribute recognition with synthetic data generation: A comparative study with image-to-image diffusion models,
P. Ayuso-Albizu, J. C. SanMiguel, and P. Carballeira, “Enhancing zero- shot pedestrian attribute recognition with synthetic data generation: A comparative study with image-to-image diffusion models,” inProc. IEEE Int. Conf. Adv. Visual Signal-Based Syst. (AVSS), 2025, pp. 1– 6
2025
-
[14]
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inProceedings of the International Conference on Machine Learning (ICML), 2022, pp. 12 888–12 900
2022
-
[15]
ImageReward: Learning and evaluating human preferences for text-to- image generation,
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong, “ImageReward: Learning and evaluating human preferences for text-to- image generation,”Adv. Neural Inform. Process. Syst. (NeurIPS), vol. 36, pp. 15 903–15 935, 2023
2023
-
[16]
X. Wu, Y . Hao, K. Sun, Y . Chen, F. Zhu, R. Zhao, and H. Li, “Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis,”arXiv:2306.09341, 2023
Pith/arXiv arXiv 2023
-
[17]
VQAScore: Evaluating text-to-visual generation with image-to-text generation,
Z. Lin, S. Yu, K.-H. Lee, P. Verga, R. Doddapaneni, P. K. A. Vasu, F. Faghri, K. Knight, J. E. Gonzalez, D. Pathak, and D. Ramanan, “VQAScore: Evaluating text-to-visual generation with image-to-text generation,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2024. 12
2024
-
[18]
Davidsonian scene graph: Improving reliability in fine-grained evaluation,
J. Cho, Y . Yu, T. Vang, and M. Bansal, “Davidsonian scene graph: Improving reliability in fine-grained evaluation,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
2024
-
[19]
AutoAugment: Learning augmentation strategies from data,
E. D. Cubuket al., “AutoAugment: Learning augmentation strategies from data,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 113–123
2019
-
[20]
RandAugment: Practical automated data augmentation with a reduced search space,
——, “RandAugment: Practical automated data augmentation with a reduced search space,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2020, pp. 702–703
2020
-
[21]
TrivialAugment: Tuning-free yet state-of-the-art data augmentation,
S. M ¨ulleret al., “TrivialAugment: Tuning-free yet state-of-the-art data augmentation,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 774–782
2021
-
[22]
Improved regularization of convolutional neural networks with cutout,
T. DeVries and G. W. Taylor, “Improved regularization of convolutional neural networks with cutout,”arXiv:1708.04552, 2017
Pith/arXiv arXiv 2017
-
[23]
Random erasing data augmentation,
Z. Zhong, L. Zheng, G. Kang, S. Li, and Y . Yang, “Random erasing data augmentation,” inProc. AAAI Conf. Artif. Intell. (AAAI), vol. 34, no. 7, 2020, pp. 13 001–13 008
2020
-
[24]
mixup: Beyond empirical risk minimization,
H. Zhanget al., “mixup: Beyond empirical risk minimization,” arXiv:1710.09412, 2017
Pith/arXiv arXiv 2017
-
[25]
CutMix: Regularization strategy to train strong classifiers with localizable features,
S. Yunet al., “CutMix: Regularization strategy to train strong classifiers with localizable features,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2019, pp. 6023–6032
2019
-
[26]
Towards unified text-based person retrieval: A large- scale multi-attribute and language search benchmark,
S. Yanget al., “Towards unified text-based person retrieval: A large- scale multi-attribute and language search benchmark,” inProc. ACM Int. Conf. Multimedia (ACM MM), 2023, pp. 4492–4501
2023
-
[27]
A data-centric approach to pedes- trian attribute recognition: Synthetic augmentation via prompt-driven diffusion models,
A. Alonso, S. A. Chaudhry, J. C. SanMiguel, ´A. Garc ´ıa-Mart´ın, P. Ayuso-Albizu, and P. Carballeira, “A data-centric approach to pedes- trian attribute recognition: Synthetic augmentation via prompt-driven diffusion models,” inProc. IEEE Int. Conf. Adv. Visual Signal-Based Syst. (AVSS), 2025, pp. 1–6
2025
-
[28]
Synthesizing efficient data with diffusion models for person re-identification pre-training,
L. Niuet al., “Synthesizing efficient data with diffusion models for person re-identification pre-training,”Mach. Learn., vol. 114, no. 3, pp. 1–25, 2025
2025
-
[29]
Pose-dive: Pose-diversified augmentation with diffusion model for person re-identification,
M. Kimet al., “Pose-dive: Pose-diversified augmentation with diffusion model for person re-identification,”arXiv:2406.16042, 2024
Pith/arXiv arXiv 2024
-
[30]
T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan, “T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,” inProc. AAAI Conf. Artif. Intell. (AAAI), vol. 38, no. 5, 2024, pp. 4296–4304
2024
-
[31]
Composer: Creative and controllable image synthesis with composable conditions,
L. Huang, D. Chen, Y . Liu, Y . Shen, D. Zhao, and J. Zhou, “Composer: Creative and controllable image synthesis with composable conditions,” arXiv:2302.09778, 2023
arXiv 2023
-
[32]
Gligen: Open-set grounded text-to-image generation,
Y . Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y . J. Lee, “Gligen: Open-set grounded text-to-image generation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 22 511–22 521
2023
-
[33]
Prompt-to-prompt image editing with cross attention control,
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-prompt image editing with cross attention control,”arXiv:2208.01626, 2022
Pith/arXiv arXiv 2022
-
[34]
Attend-and- excite: Attention-based semantic guidance for text-to-image diffusion models,
H. Chefer, Y . Alaluf, Y . Vinker, L. Wolf, and D. Cohen-Or, “Attend-and- excite: Attention-based semantic guidance for text-to-image diffusion models,”ACM Trans. Graph., vol. 42, no. 4, pp. 1–10, 2023
2023
-
[35]
Optimizing prompts for text-to- image generation,
Y . Hao, Z. Chi, L. Dong, and F. Wei, “Optimizing prompts for text-to- image generation,”Adv. Neural Inform. Process. Syst. (NeurIPS), vol. 36, pp. 66 923–66 939, 2023
2023
-
[36]
Parameter- efficient fine-tuning for large models: A comprehensive survey,
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter- efficient fine-tuning for large models: A comprehensive survey,” arXiv:2403.14608, 2024
Pith/arXiv arXiv 2024
-
[37]
Autolabeling 3d objects with differentiable rendering of SDF shape priors,
S. Zakharov, W. Kehl, A. Bhargava, and A. Gaidon, “Autolabeling 3d objects with differentiable rendering of SDF shape priors,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 12 224–12 233
2020
-
[38]
VESPA: Towards un- supervised open-world pointcloud labeling for autonomous driving,
L. Tempfli, E. Rivera, and M. Lienkamp, “VESPA: Towards un- supervised open-world pointcloud labeling for autonomous driving,” arXiv:2507.20397, 2025
arXiv 2025
-
[39]
What are effective labels for augmented data? improving calibration and robustness with autolabel,
Y . Qin, X. Wang, B. Lakshminarayanan, E. H. Chi, and A. Beutel, “What are effective labels for augmented data? improving calibration and robustness with autolabel,” inProc. IEEE Conf. Secure Trustworthy Mach. Learn. (SaTML), 2023, pp. 365–376
2023
-
[40]
ShareGPT4V: Improving large multi-modal models with better captions,
L. Chen, J. Li, X. Dong, P. Zhang, C. He, J. Wang, F. Zhao, and D. Lin, “ShareGPT4V: Improving large multi-modal models with better captions,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2024
2024
-
[41]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inAdv. Neural Inform. Process. Syst. (NeurIPS), 2024
2024
-
[42]
Difflm: Controllable synthetic data generation via diffusion language models,
Y . Zhou, X. Wang, Y . Niu, Y . Shen, L. Tang, F. Chen, B. He, L. Sun, and L. Wen, “Difflm: Controllable synthetic data generation via diffusion language models,” inProc. Findings Assoc. Comput. Linguist. (ACL), 2025, pp. 20 638–20 658
2025
-
[43]
Self-improving diffusion models with synthetic data,
S. Alemohammad, A. I. Humayun, S. Agarwal, J. Collomosse, and R. Baraniuk, “Self-improving diffusion models with synthetic data,” arXiv:2408.16333, 2024
arXiv 2024
-
[44]
Autoeval done right: Using synthetic data for model evaluation,
P. Boyeau, A. N. Angelopoulos, N. Yosef, J. Malik, and M. I. Jordan, “Autoeval done right: Using synthetic data for model evaluation,” arXiv:2403.07008, 2024
Pith/arXiv arXiv 2024
-
[45]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 10 674–10 685
2022
-
[46]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[47]
Diffusers: State-of-the-art diffusion models,
P. von Platen, S. Patil, A. Lozhkov, P. Cuenca, N. Lambert, K. Rasul, M. Daware, and T. Wolf, “Diffusers: State-of-the-art diffusion models,” https://github.com/huggingface/diffusers, 2022
2022
-
[48]
Pedestrian attribute recognition via CLIP-based prompt vision-language fusion,
X. Wang, J. Jin, C. Li, J. Tang, C. Zhang, and W. Wang, “Pedestrian attribute recognition via CLIP-based prompt vision-language fusion,” IEEE Trans. Circuits Syst. Video Technol., 2024
2024
-
[49]
Sequen- cepar: Understanding pedestrian attributes via a sequence generation paradigm,
J. Jin, X. Wang, Y . Lin, C. Li, L. Huang, A. Zheng, and J. Tang, “Sequen- cepar: Understanding pedestrian attributes via a sequence generation paradigm,”Pattern Recognit., vol. 112, p. 112356, 2025
2025
-
[50]
GANs trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “GANs trained by a two time-scale update rule converge to a local nash equilibrium,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[51]
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models,
G. Stein, J. C. Cresswell, R. Hosseinzadeh, Y . Sui, B. L. Ross, V . Villecroze, Z. Liu, A. L. Caterini, J. E. T. Taylor, and G. Loaiza- Ganem, “Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023
2023
-
[52]
Rethinking FID: Towards a better evaluation metric for image generation,
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar, “Rethinking FID: Towards a better evaluation metric for image generation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 9307–9315
2024
-
[53]
Conditional frechet inception distance,
M. Soloveitchik, T. Diskin, E. Morin, and A. Wiesel, “Conditional frechet inception distance,”arXiv:2103.11521, 2022
arXiv 2022
-
[54]
AugMix: A simple data processing method to improve robustness and uncertainty,
D. Hendryckset al., “AugMix: A simple data processing method to improve robustness and uncertainty,”arXiv:1912.02781, 2019. Pablo Ayuso-Albizureceived the B.S. degree in Computer Engineering in 2021, and the M.S. de- gree in Deep Learning for Audio and Video Sig- nal Processing in 2022, both from the Universidad Aut´onoma de Madrid (UAM), Madrid, Spain. I...
arXiv 1912
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.