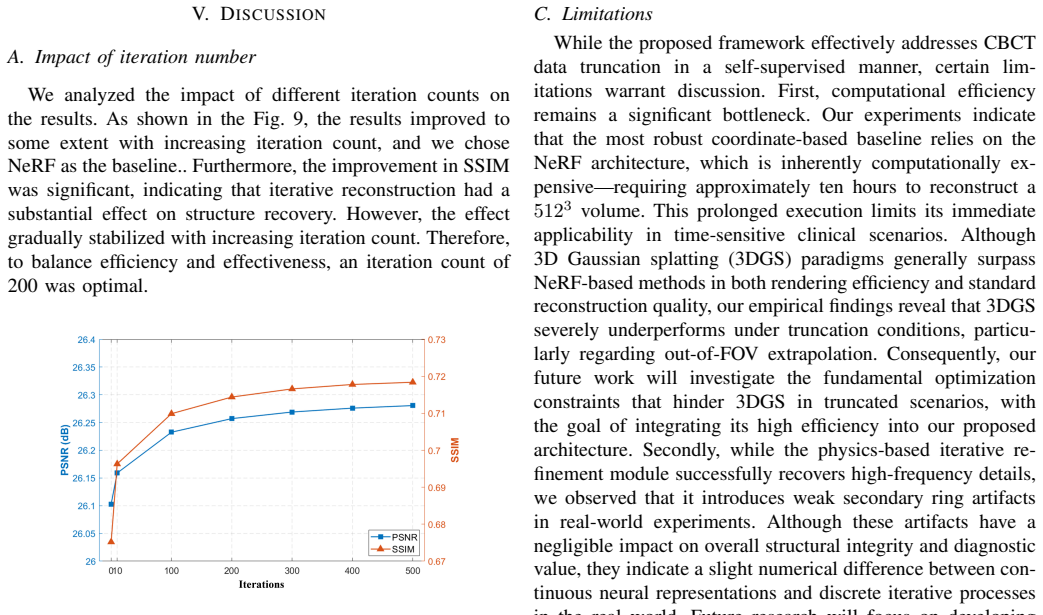
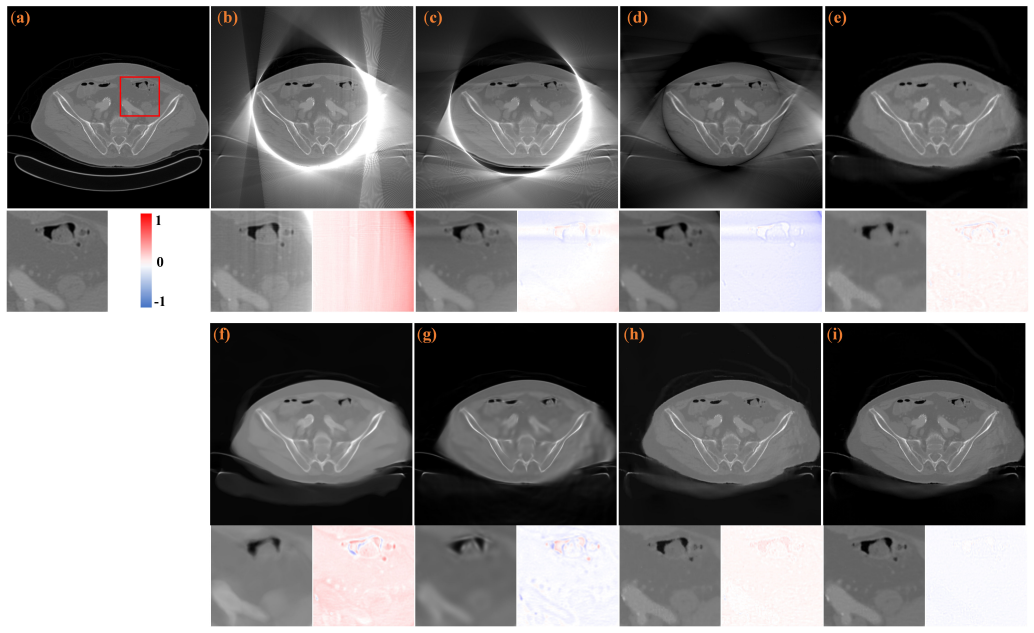
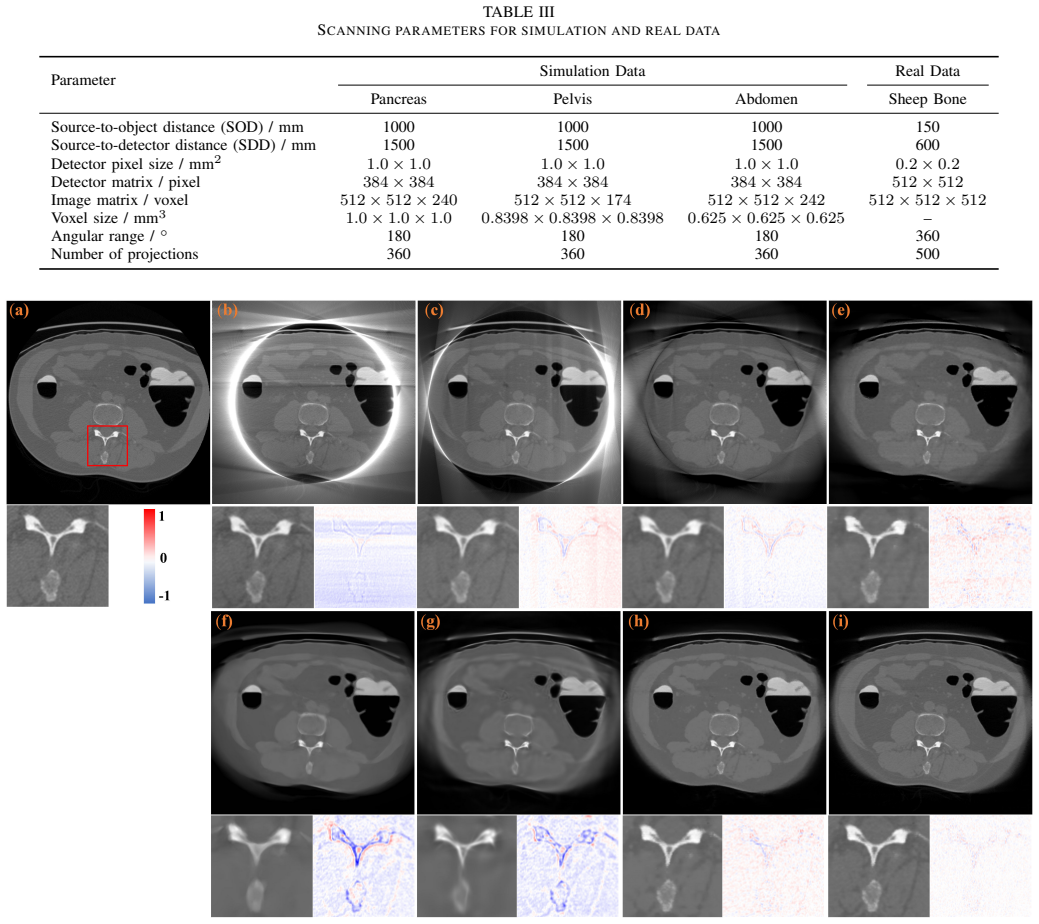
Texture-preserving implicit neural representation for Cone beam CT truncated reconstruction
Pith reviewed 2026-06-28 02:16 UTC · model grok-4.3
The pith
A coordinate network first extrapolates truncated CBCT data without ring artifacts, then a physics-based iterative module re-injects high-frequency textures from the original projections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
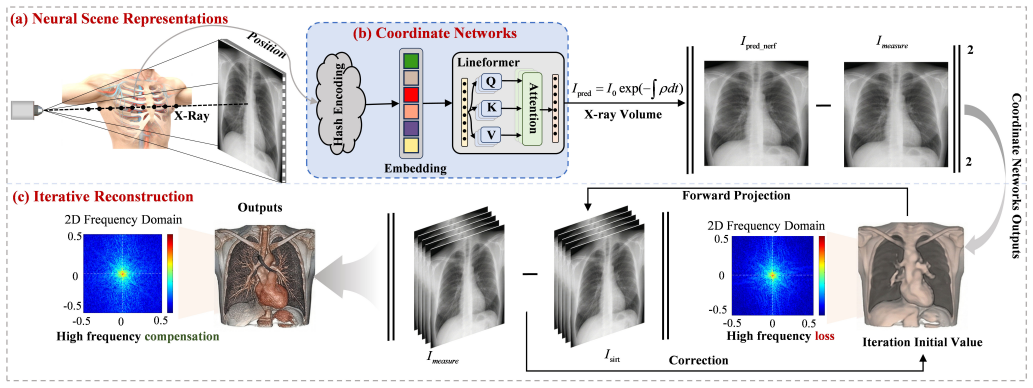
The central claim is that an implicit neural representation, trained only on truncated projections, produces an artifact-free extrapolated volume that serves as an optimal initialization; a subsequent physics-based iterative module then re-extracts and restores high-frequency structural information directly from the same projections, yielding a final volume that combines neural extrapolation with iterative texture fidelity.
What carries the argument
The implicit neural scene representation (a coordinate network that maps spatial coordinates to radiodensity) whose output initializes the physics-based iterative refinement module that injects projection-derived high-frequency information.
If this is right
- Truncation-induced ring artifacts are eliminated because the coordinate network bypasses conventional filtering and backprojection.
- Continuous three-dimensional extrapolation beyond the measured field of view becomes possible without additional data.
- High-frequency clinical textures are restored by direct projection supervision in the refinement stage.
- Training requires no paired full-volume ground truth, only the available truncated projections.
Where Pith is reading between the lines
- The same two-stage pattern could be tested on other incomplete-data tomography problems such as limited-angle or sparse-view reconstruction.
- If the neural initialization consistently outperforms conventional starts, detector size requirements in CBCT systems might be reduced in practice.
- A natural next measurement would be to quantify how much the iterative stage improves specific texture metrics on clinical head or dental datasets.
Load-bearing premise
The neural coordinate network must generate an artifact-free extrapolated volume that functions as an optimal starting point so the iterative module can recover textures without introducing new artifacts or needing extra supervision.
What would settle it
A controlled test on a physical phantom containing known high-frequency patterns where the final hybrid reconstruction shows lower texture fidelity or new artifacts compared with a standard iterative reconstruction started from filtered back-projection would falsify the claim that the neural initialization is optimal.
Figures

read the original abstract
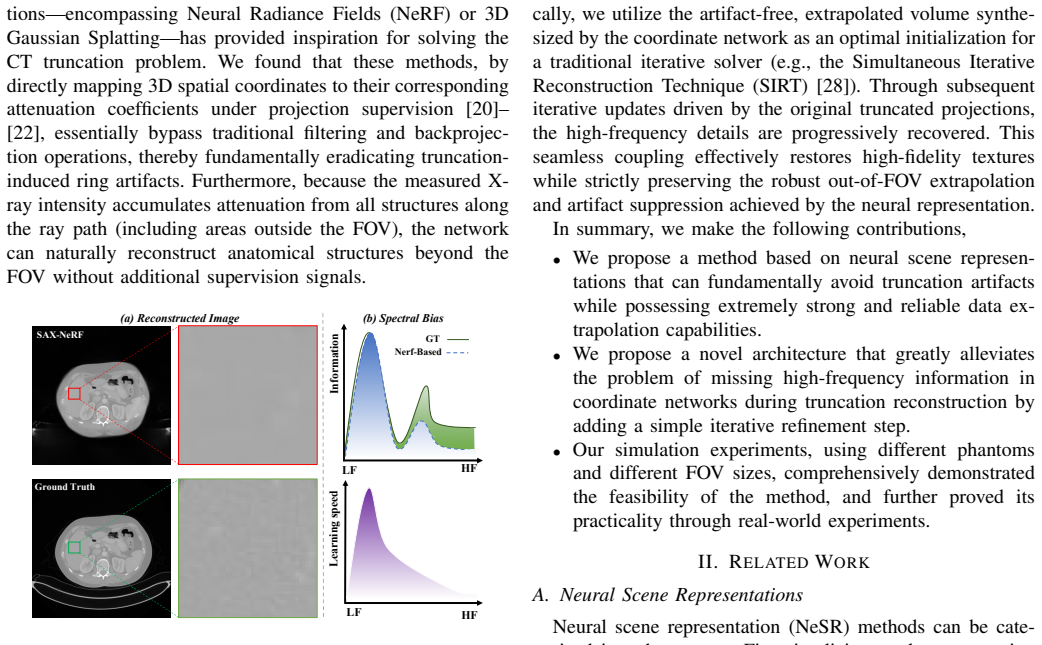
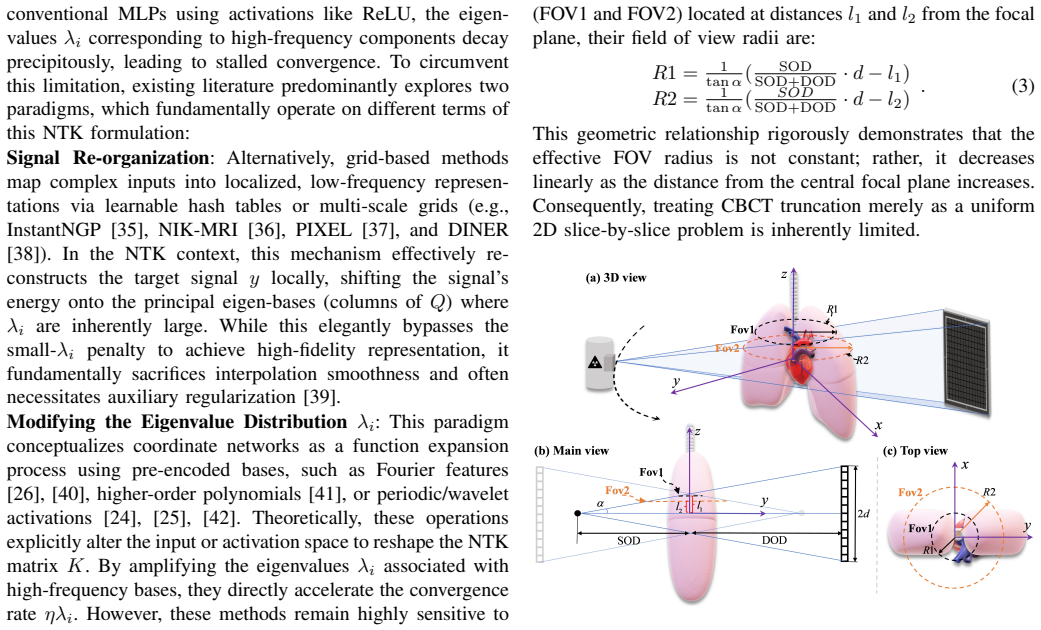
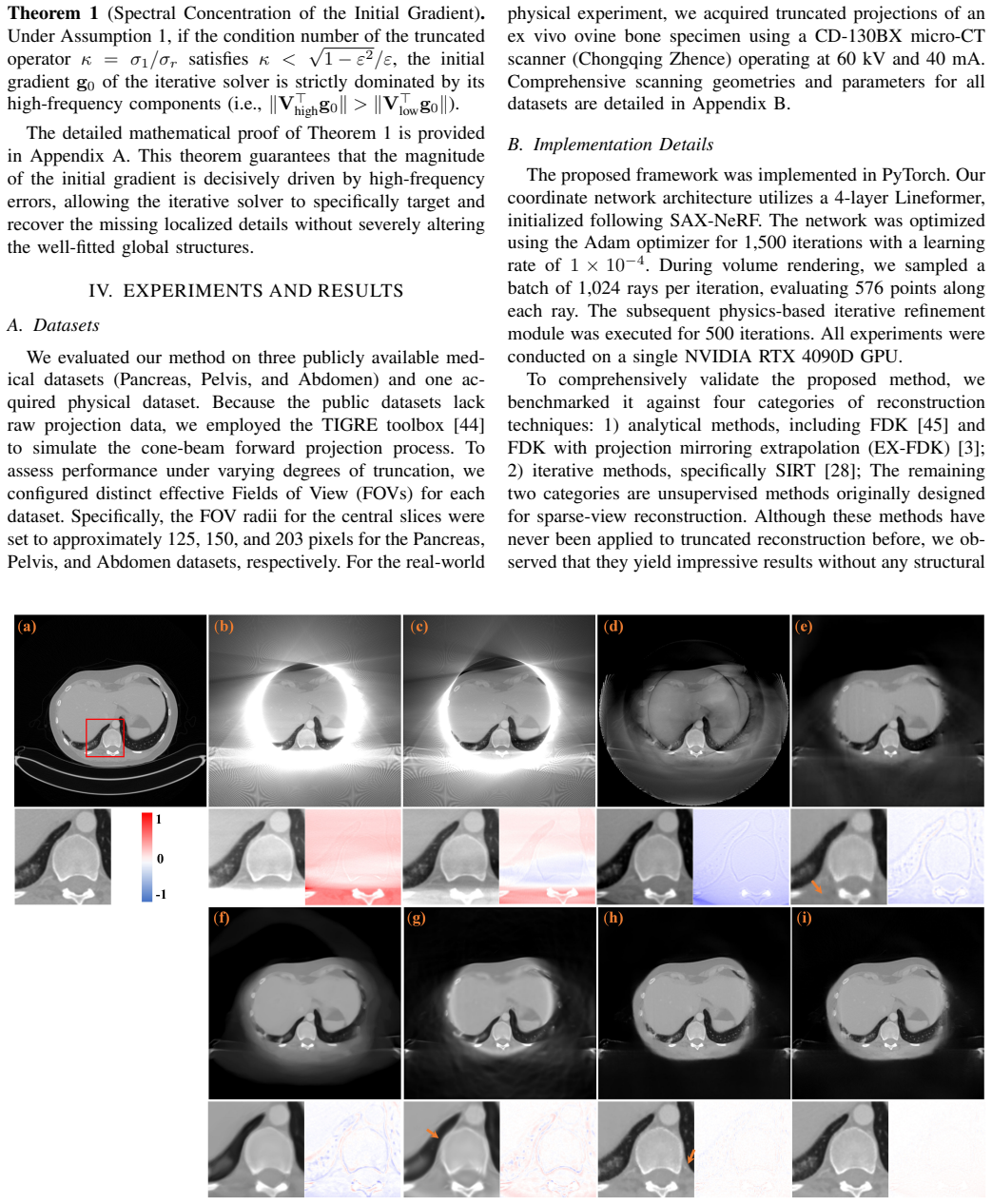
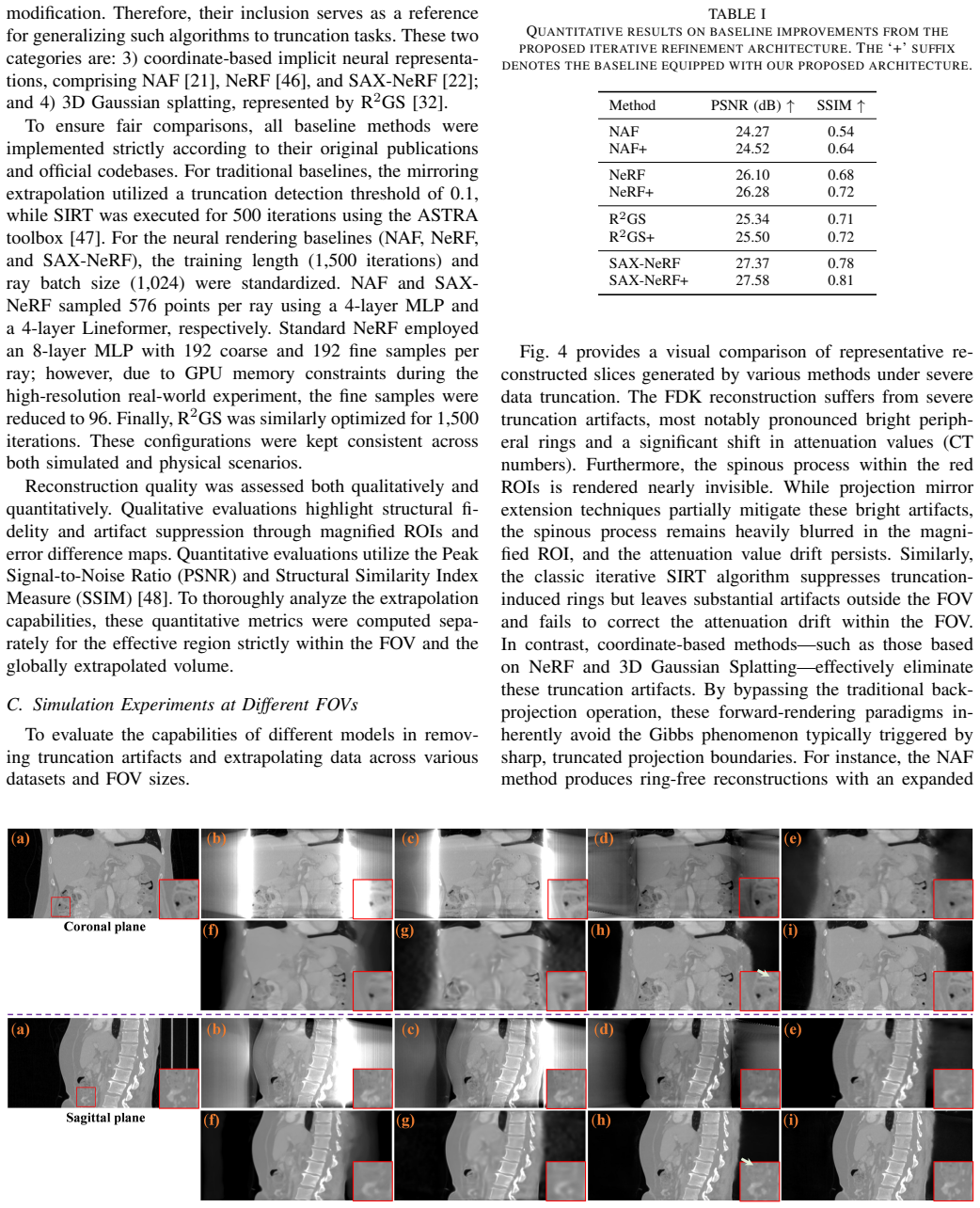
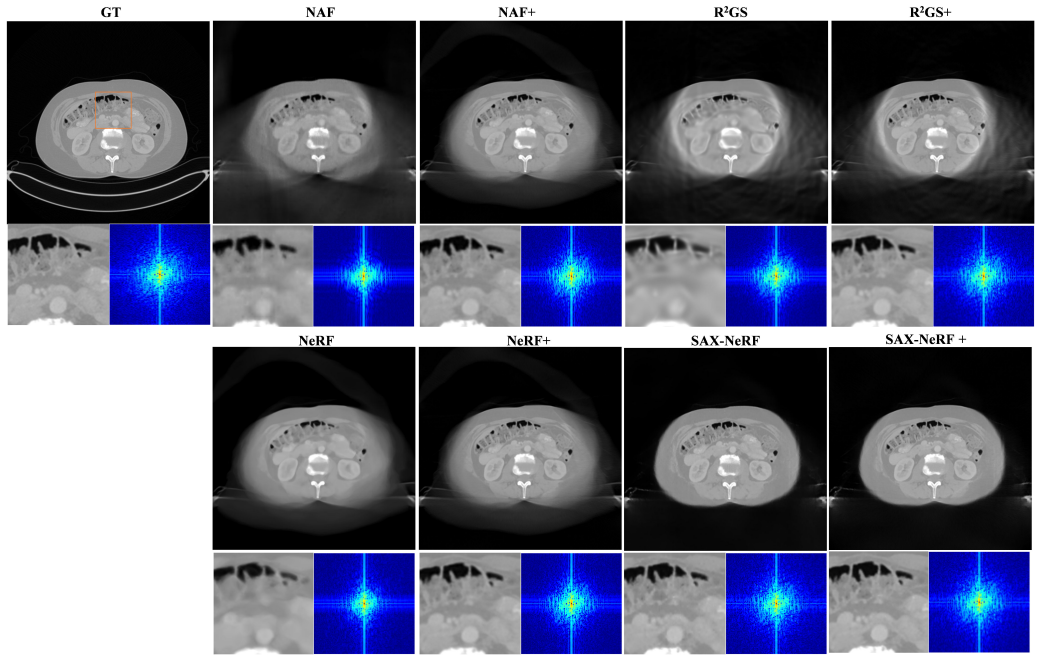
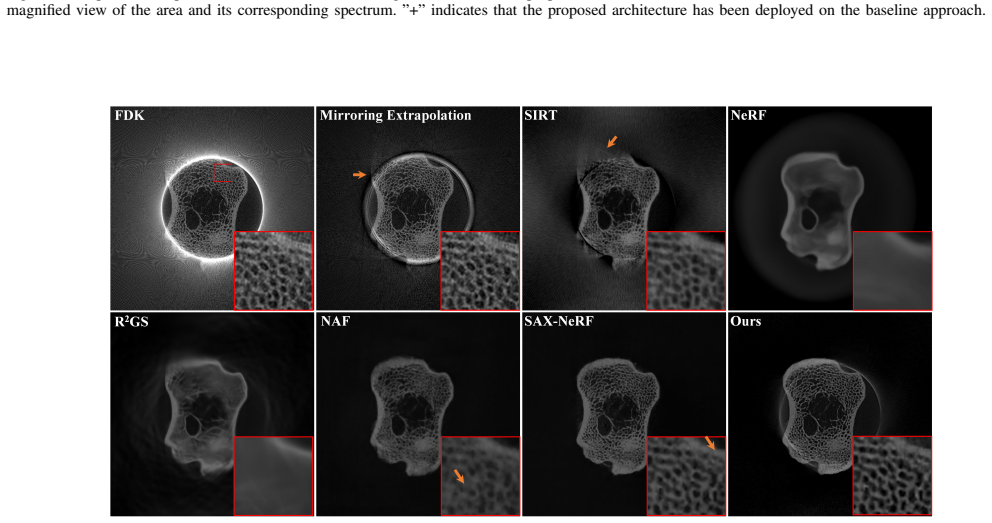
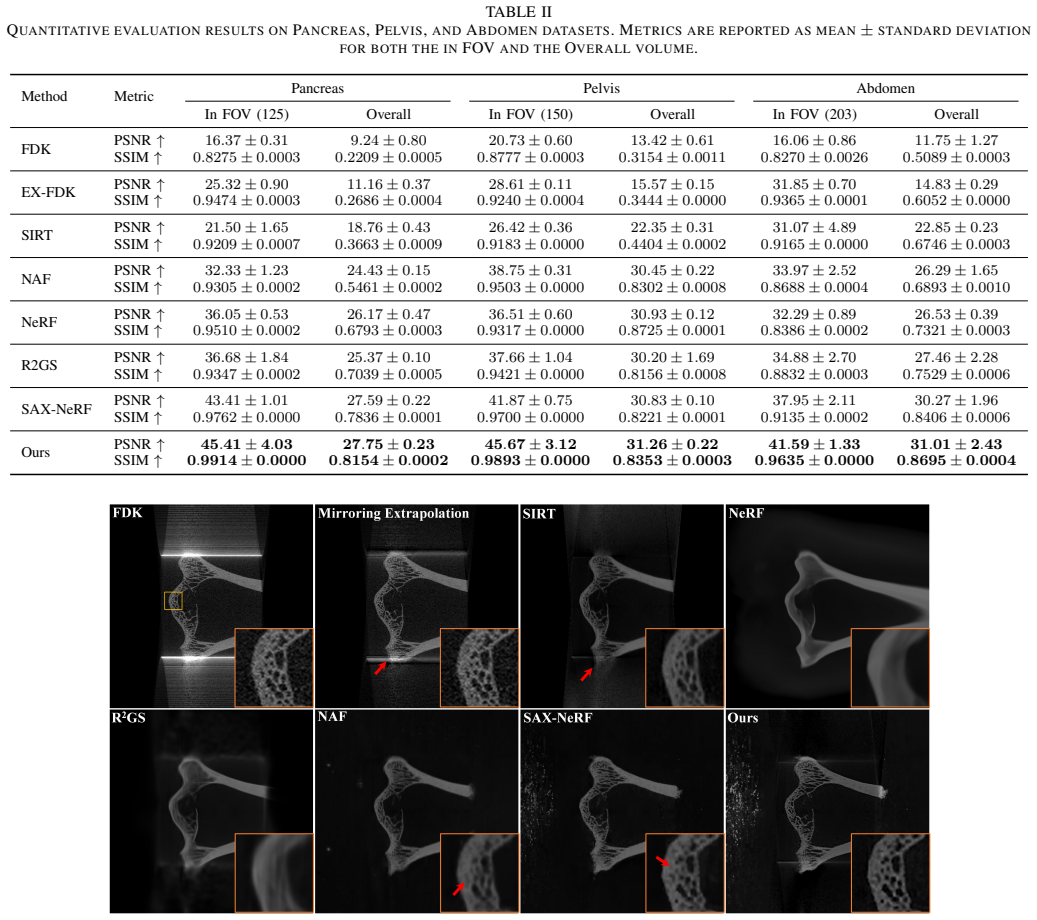
Cone-beam computed tomography (CBCT) frequently suffers from data truncation, which introduces severe artifacts and limits the effective field of view (FOV). Existing deep learning methods for truncated cone-beam computed tomography (CBCT) reconstruction suffer from serious limitations, including a strict reliance on supervised ground truth and a failure to account for continuous 3D spatial truncation variations. To address these challenges, we introduce a self-supervised 3D reconstruction framework based on neural scene representations. By directly mapping spatial coordinates to radiodensity under projection supervision, our approach inherently bypasses traditional filtering and backprojection operations, thereby fundamentally eliminating truncation-induced ring artifacts while enabling robust continuous 3D data extrapolation. However, coordinate networks are susceptible to an inherent spectral bias, which leads to a severe loss of clinically vital high-frequency textures. To resolve this bottleneck, we further incorporate a physics-based iterative refinement module into the neural scene representation architecture. Leveraging the artifact-free, extrapolated volume from the coordinate network as an optimal initialization, this module progressively re-extracts and injects high-frequency structural information from the original projections back into the volume. Extensive experiments on both simulated and real-world datasets demonstrate that our method successfully unifies the exceptional artifact suppression and extrapolation capabilities of neural networks with the high-fidelity detail preservation of iterative algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised framework for truncated CBCT reconstruction that uses a coordinate network (implicit neural representation) to map 3D spatial coordinates directly to radiodensity values under projection supervision. This is claimed to eliminate truncation-induced ring artifacts and enable continuous 3D extrapolation without traditional filtering or backprojection. A physics-based iterative refinement module is then added, taking the network's artifact-free extrapolated volume as initialization to progressively recover and inject high-frequency structural details from the original projections while avoiding new artifacts. Experiments on simulated and real datasets are asserted to demonstrate unification of neural artifact suppression with iterative detail preservation.
Significance. If the central claims hold with supporting evidence, the work would address an important practical limitation in CBCT imaging by providing a self-supervised alternative that avoids the need for ground-truth volumes and handles variable truncation. The combination of coordinate networks for low-frequency extrapolation with iterative refinement for texture recovery is a plausible direction, and the self-supervised projection loss is a methodological strength that could reduce reliance on paired training data.
major comments (2)
- [Abstract] Abstract: The unification claim rests on the assertion that the coordinate network produces an 'artifact-free extrapolated volume' that serves as an 'optimal initialization' allowing the iterative module to 'progressively re-extract and inject high-frequency structural information' without introducing new artifacts. No derivation, stability analysis, or ablation is described to show why standard iterative schemes (known to re-amplify truncation rings when emphasizing high frequencies) remain stable under this initialization or how the self-supervised loss alone enforces the required frequency separation.
- [Abstract] Abstract: The manuscript asserts successful performance on simulated and real-world datasets but provides no quantitative metrics (e.g., PSNR, SSIM, artifact indices), no ablation studies on the iterative module, and no comparison against baselines, making it impossible to evaluate whether the texture-preservation or artifact-suppression claims hold.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline planned revisions to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The unification claim rests on the assertion that the coordinate network produces an 'artifact-free extrapolated volume' that serves as an 'optimal initialization' allowing the iterative module to 'progressively re-extract and inject high-frequency structural information' without introducing new artifacts. No derivation, stability analysis, or ablation is described to show why standard iterative schemes (known to re-amplify truncation rings when emphasizing high frequencies) remain stable under this initialization or how the self-supervised loss alone enforces the required frequency separation.
Authors: We agree that the abstract is concise and omits explicit theoretical details on frequency separation and stability. The manuscript describes the coordinate network's spectral bias and the role of the physics-based iterative module, but does not provide a dedicated derivation or stability analysis. We will add a new subsection in the methods with a mathematical derivation of how the self-supervised projection loss promotes frequency separation, a stability analysis of the iterative refinement initialized by the neural representation, and an ablation study quantifying the effect of this initialization on ring artifact re-amplification. revision: yes
-
Referee: [Abstract] Abstract: The manuscript asserts successful performance on simulated and real-world datasets but provides no quantitative metrics (e.g., PSNR, SSIM, artifact indices), no ablation studies on the iterative module, and no comparison against baselines, making it impossible to evaluate whether the texture-preservation or artifact-suppression claims hold.
Authors: The current manuscript version does not include specific quantitative metrics, ablations on the iterative module, or baseline comparisons in the abstract or results sections. We will revise the abstract to summarize key quantitative outcomes and expand the experiments section to include PSNR, SSIM, and artifact index values, dedicated ablations isolating the iterative module, and comparisons against baselines such as FDK and other reconstruction methods on both simulated and real datasets. revision: yes
Circularity Check
No significant circularity; derivation relies on external measured projections
full rationale
The paper's core chain maps coordinates to density under direct projection supervision from measured data, then feeds the resulting volume into a physics-based iterative module that re-extracts high frequencies from the same original projections. No equation or procedure is shown that defines a target quantity in terms of itself or renames a fitted parameter as a prediction; the artifact-free claim follows from bypassing filtering/backprojection rather than from any self-referential construction. No self-citation is invoked as load-bearing justification, and the supervision source remains external to the model's outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Region of interest reconstruction from truncated data in circular cone- beam ct,
L. Yu, Y . Zou, E. Y . Sidky, C. A. Pelizzari, P. Munro, and X. Pan, “Region of interest reconstruction from truncated data in circular cone- beam ct,”IEEE transactions on medical imaging, vol. 25, no. 7, pp. 869–881, 2006
2006
-
[2]
3d roi image reconstruction from truncated computed tomography,
A. Sen, D. Labate, B. Bodmann, R. Azencott, and E. France, “3d roi image reconstruction from truncated computed tomography,”IEEE Trans Med Imaging, vol. 11, no. 9, pp. 1–19, 2012
2012
-
[3]
Efficient correction for ct image artifacts caused by objects extending outside the scan field of view,
B. Ohnesorge, T. Flohr, K. Schwarz, J. Heiken, and K. Bae, “Efficient correction for ct image artifacts caused by objects extending outside the scan field of view,”Medical physics, vol. 27, no. 1, pp. 39–46, 2000
2000
-
[4]
The obese emergency patient: imaging challenges and solutions,
M. J. Modica, K. M. Kanal, and M. L. Gunn, “The obese emergency patient: imaging challenges and solutions,”Radiographics, vol. 31, no. 3, pp. 811–823, 2011
2011
-
[5]
A novel reconstruction algorithm to extend the ct scan field-of-view,
J. Hsieh, E. Chao, J. Thibault, B. Grekowicz, A. Horst, S. McOlash, and T. Myers, “A novel reconstruction algorithm to extend the ct scan field-of-view,”Medical physics, vol. 31, no. 9, pp. 2385–2391, 2004
2004
-
[6]
Reconstruction from truncated projections in ct using adaptive detruncation,
K. Sourbelle, M. Kachelrieß, and W. A. Kalender, “Reconstruction from truncated projections in ct using adaptive detruncation,”European radiology, vol. 15, no. 5, pp. 1008–1014, 2005
2005
-
[7]
Towards clinical application of a laplace operator-based region of interest reconstruction algorithm in c-arm ct,
Y . Xia, H. Hofmann, F. Dennerlein, K. Mueller, C. Schwemmer, S. Bauer, G. Chintalapani, P. Chinnadurai, J. Hornegger, and A. Maier, “Towards clinical application of a laplace operator-based region of interest reconstruction algorithm in c-arm ct,”IEEE Transactions on Medical Imaging, vol. 33, no. 3, pp. 593–606, 2013
2013
-
[8]
Cone-beam reconstruction using the backprojection of locally filtered projections,
J. D. Pack, F. Noo, and R. Clackdoyle, “Cone-beam reconstruction using the backprojection of locally filtered projections,”IEEE Transactions on Medical Imaging, vol. 24, no. 1, pp. 70–85, 2005
2005
-
[9]
Compressed sensing based interior tomography,
H. Yu and G. Wang, “Compressed sensing based interior tomography,” Physics in medicine & biology, vol. 54, no. 9, pp. 2791–2805, 2009
2009
-
[10]
High-order total variation minimization for interior tomography,
J. Yang, H. Yu, M. Jiang, and G. Wang, “High-order total variation minimization for interior tomography,”Inverse problems, vol. 26, no. 3, p. 035013, 2010
2010
-
[11]
Statistical interior tomography,
Q. Xu, X. Mou, G. Wang, J. Sieren, E. A. Hoffman, and H. Yu, “Statistical interior tomography,”IEEE transactions on medical imaging, vol. 30, no. 5, pp. 1116–1128, 2011
2011
-
[12]
Data extrapolation from learned prior images for truncation correction in computed tomography,
Y . Huang, A. Preuhs, M. Manhart, G. Lauritsch, and A. Maier, “Data extrapolation from learned prior images for truncation correction in computed tomography,”IEEE Transactions on Medical Imaging, vol. 40, no. 11, pp. 3042–3053, 2021
2021
-
[13]
One network to solve all rois: Deep learning ct for any roi using differentiated backprojection,
Y . Han and J. C. Ye, “One network to solve all rois: Deep learning ct for any roi using differentiated backprojection,”Medical physics, vol. 46, no. 12, pp. e855–e872, 2019
2019
-
[14]
Ct field of view exten- sion using combined channels extension and deep learning methods,
´E. Fourni ´e, M. Baer-Beck, and K. Stierstorfer, “Ct field of view exten- sion using combined channels extension and deep learning methods,” Proc. MIDL, pp. 1–4, 2019
2019
-
[15]
Diffusion- based generative image outpainting for recovery of fov-truncated ct images,
M. E. Liman, D. Rueckert, F. J. Fintelmann, and P. M ¨uller, “Diffusion- based generative image outpainting for recovery of fov-truncated ct images,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 14–23
2024
-
[16]
Learning to reconstruct computed tomography images directly from sinogram data under a variety of data acquisition conditions,
Y . Li, K. Li, C. Zhang, J. Montoya, and G.-H. Chen, “Learning to reconstruct computed tomography images directly from sinogram data under a variety of data acquisition conditions,”IEEE transactions on medical imaging, vol. 38, no. 10, pp. 2469–2481, 2019
2019
-
[17]
Field of view extension in computed tomography using deep learning prior,
Y . Huang, L. Gao, A. Preuhs, and A. Maier, “Field of view extension in computed tomography using deep learning prior,” inBildverarbeitung f¨ur die Medizin 2020: Algorithmen–Systeme–Anwendungen. Proceedings des Workshops vom 15. bis 17. M ¨arz 2020 in Berlin. Springer, 2020, pp. 186–191
2020
-
[18]
Promising generative adversarial network based sinogram inpainting method for ultra-limited-angle computed tomography imaging,
Z. Li, A. Cai, L. Wang, W. Zhang, C. Tang, L. Li, N. Liang, and B. Yan, “Promising generative adversarial network based sinogram inpainting method for ultra-limited-angle computed tomography imaging,”Sensors, vol. 19, no. 18, p. 3941, 2019
2019
-
[19]
The robustness of deep networks: A geometrical perspective,
A. Fawzi, S.-M. Moosavi-Dezfooli, and P. Frossard, “The robustness of deep networks: A geometrical perspective,”IEEE Signal Processing Magazine, vol. 34, no. 6, pp. 50–62, 2017
2017
-
[20]
Intratomo: self-supervised learning-based tomography via sinogram synthesis and prediction,
G. Zang, R. Idoughi, R. Li, P. Wonka, and W. Heidrich, “Intratomo: self-supervised learning-based tomography via sinogram synthesis and prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1960–1970
2021
-
[21]
Naf: neural attenuation fields for sparse- view cbct reconstruction,
R. Zha, Y . Zhang, and H. Li, “Naf: neural attenuation fields for sparse- view cbct reconstruction,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2022, pp. 442–452
2022
-
[22]
Structure-aware sparse-view x-ray 3d reconstruction,
Y . Cai, J. Wang, A. Yuille, Z. Zhou, and A. Wang, “Structure-aware sparse-view x-ray 3d reconstruction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 11 174–11 183
2024
-
[23]
A structured dictionary perspective on implicit neural representations,
G. Y ¨uce, G. Ortiz-Jim ´enez, B. Besbinar, and P. Frossard, “A structured dictionary perspective on implicit neural representations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2022, pp. 19 228–19 238
2022
-
[24]
Implicit neural representations with periodic activation functions,
V . Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” Advances in neural information processing systems, vol. 33, pp. 7462– 7473, 2020
2020
-
[25]
Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps,
S. Ramasinghe and S. Lucey, “Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 142–158
2022
-
[26]
Fourier features let networks learn high frequency functions in low dimensional domains,
M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, and R. Ng, “Fourier features let networks learn high frequency functions in low dimensional domains,” Advances in neural information processing systems, vol. 33, pp. 7537– 7547, 2020
2020
-
[27]
Batch normalization alleviates the spectral bias in coordinate networks,
Z. Cai, H. Zhu, Q. Shen, X. Wang, and X. Cao, “Batch normalization alleviates the spectral bias in coordinate networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 25 160–25 171
2024
-
[28]
Iterative methods for the three-dimensional reconstruction of an object from projections,
P. Gilbert, “Iterative methods for the three-dimensional reconstruction of an object from projections,”Journal of theoretical biology, vol. 36, no. 1, pp. 105–117, 1972
1972
-
[29]
Mednerf: Medical neural radiance fields for reconstructing 3d-aware ct-projections from a single x-ray,
A. Corona-Figueroa, J. Frawley, S. Bond-Taylor, S. Bethapudi, H. P. Shum, and C. G. Willcocks, “Mednerf: Medical neural radiance fields for reconstructing 3d-aware ct-projections from a single x-ray,” in2022 44th annual international conference of the IEEE engineering in medicine & Biology society (EMBC). IEEE, 2022, pp. 3843–3848
2022
-
[30]
Neat: Neural adaptive tomography,
D. R ¨uckert, Y . Wang, R. Li, R. Idoughi, and W. Heidrich, “Neat: Neural adaptive tomography,”ACM Transactions on Graphics (TOG), vol. 41, no. 4, pp. 1–13, 2022
2022
-
[31]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakiset al., “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[32]
R 2-gaussian: Rectifying radiative gaussian splatting for tomographic reconstruction,
R. Zha, T. J. Lin, Y . Cai, J. Cao, Y . Zhang, and H. Li, “R 2-gaussian: Rectifying radiative gaussian splatting for tomographic reconstruction,” Advances in Neural Information Processing Systems, vol. 37, pp. 44 907–44 934, 2024
2024
-
[33]
Gr- gaussian: Graph-based radiative gaussian splatting for sparse-view ct reconstruction,
Y . Yuluo, Y . Ma, K. Shen, T. Jin, W. Liao, Y . Ma, and F. Wang, “Gr- gaussian: Graph-based radiative gaussian splatting for sparse-view ct reconstruction,”arXiv preprint arXiv:2508.02408, 2025
arXiv 2025
-
[34]
On the spectral bias of neural networks,
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y . Bengio, and A. Courville, “On the spectral bias of neural networks,” inInternational conference on machine learning. PMLR, 2019, pp. 5301–5310
2019
-
[35]
Instant neural graphics primitives with a multiresolution hash encoding,
T. M ¨uller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,”ACM transactions on graphics (TOG), vol. 41, no. 4, pp. 1–15, 2022
2022
-
[36]
Neural implicit k-space for binning-free non-cartesian cardiac mr imaging,
W. Huang, H. B. Li, J. Pan, G. Cruz, D. Rueckert, and K. Hammernik, “Neural implicit k-space for binning-free non-cartesian cardiac mr imaging,” inInternational Conference on Information Processing in Medical Imaging. Springer, 2023, pp. 548–560
2023
-
[37]
Pixel: Physics- informed cell representations for fast and accurate pde solvers,
N. Kang, B. Lee, Y . Hong, S.-B. Yun, and E. Park, “Pixel: Physics- informed cell representations for fast and accurate pde solvers,” in Proceedings of the AAAI conference on artificial intelligence, vol. 37, no. 7, 2023, pp. 8186–8194
2023
-
[38]
Disorder-invariant implicit neural representation,
H. Zhu, S. Xie, Z. Liu, F. Liu, Q. Zhang, Y . Zhou, Y . Lin, Z. Ma, and X. Cao, “Disorder-invariant implicit neural representation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5463–5478, 2024
2024
-
[39]
Rhino: Regularizing the hash-based implicit neural representation,
H. Zhu, F. Liu, Q. Zhang, Z. Ma, and X. Cao, “Rhino: Regularizing the hash-based implicit neural representation,”Science China Information Sciences, vol. 69, no. 1, p. 112101, 2026
2026
-
[40]
Pins: Progressive im- plicit networks for multi-scale neural representations,
Z. Landgraf, A. S. Hornung, and R. S. Cabral, “Pins: Progressive im- plicit networks for multi-scale neural representations,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 11 969–11 984
2022
-
[41]
Polynomial implicit neural repre- sentations for large diverse datasets,
R. Singh, A. Shukla, and P. Turaga, “Polynomial implicit neural repre- sentations for large diverse datasets,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2041–2051
2023
-
[42]
Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions,
Z. Liu, H. Zhu, Q. Zhang, J. Fu, W. Deng, Z. Ma, Y . Guo, and X. Cao, “Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2713–2722
2024
-
[43]
Towards the spec- tral bias alleviation by normalizations in coordinate networks,
Z. Cai, H. Zhu, Q. Shen, X. Wang, and X. Cao, “Towards the spec- tral bias alleviation by normalizations in coordinate networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. Fig. 11. Visual evaluation results for the pelvis dataset (FOV: approx. 150 pixels, 80th axial slice). The red box delineates the ROI; the bottom-left corner ...
2026
-
[44]
Tigre: a matlab- gpu toolbox for cbct image reconstruction,
A. Biguri, M. Dosanjh, S. Hancock, and M. Soleimani, “Tigre: a matlab- gpu toolbox for cbct image reconstruction,”Biomedical Physics & Engineering Express, vol. 2, no. 5, p. 055010, 2016
2016
-
[45]
Practical cone-beam algorithm,
L. A. Feldkamp, L. C. Davis, and J. W. Kress, “Practical cone-beam algorithm,”Journal of the Optical Society of America A, vol. 1, no. 6, pp. 612–619, 1984
1984
-
[46]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[47]
Fast and flexible x-ray tomography using the astra toolbox,
W. Van Aarle, W. J. Palenstijn, J. Cant, E. Janssens, F. Bleichrodt, A. Dabravolski, J. De Beenhouwer, K. Joost Batenburg, and J. Sijbers, “Fast and flexible x-ray tomography using the astra toolbox,”Optics express, vol. 24, no. 22, pp. 25 129–25 147, 2016
2016
-
[48]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004. VII. APPENDIX VIII. PROOF OFTHEOREM1 Proof.Using the SVD decomposition, the transpose of the truncated forward projection matrix isA ⊤ T =VΣU ⊤. The i...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.