LLM-Based Porting of Optimized C++ to CUDA Through Deoptimization and Reoptimization
Pith reviewed 2026-06-27 23:43 UTC · model grok-4.3
The pith
Deoptimizing C++ code by removing CPU optimizations before LLM translation to CUDA produces faster results in some kernels but slower results in others compared to direct translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
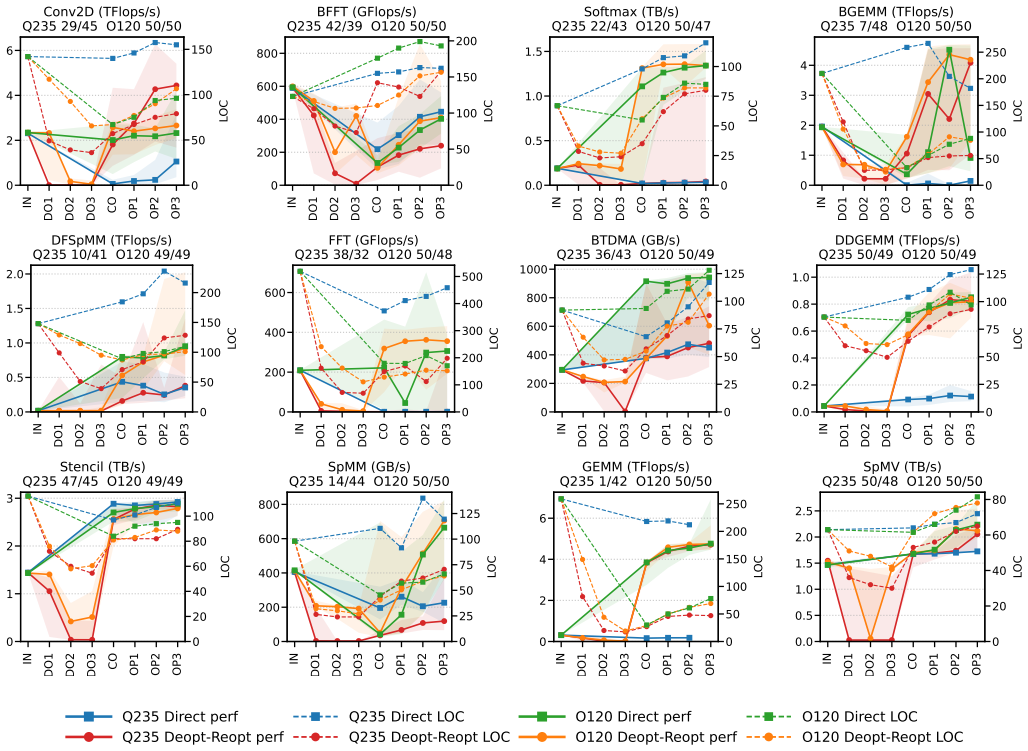
The Deopt-Reopt workflow first simplifies the input C++ code to strip CPU-specific optimizations and then retranslates and reoptimizes the result for CUDA using an LLM. Direct comparison against straightforward translation of the original code shows Deopt-Reopt significantly faster among successful single-shot trials in five of eighteen testable cases and slower in three, with the clearest advantage on kernels such as conv2d where CPU and GPU designs diverge. In iterative refinement the performance gap narrows for one model while the other retains large Deopt-Reopt advantages on several kernels; success rates also move in both directions. The authors therefore characterize the method as effe
What carries the argument
The Deopt-Reopt workflow, which removes CPU-oriented optimizations from C++ code before LLM-driven CUDA translation and reoptimization.
If this is right
- Deopt-Reopt yields faster successful executions than direct translation for some kernels but slower executions for others in single-shot settings.
- Iterative refinement reduces the performance gap between the two approaches for at least one of the tested models.
- Deopt-Reopt raises or lowers compilation success rates depending on the specific kernel.
- Equalizing the number of LLM calls does not produce a consistent advantage for Deopt-Reopt over direct translation.
- All reported speedups are measured only on trials that compile and execute, so overall workflow time may differ.
Where Pith is reading between the lines
- Teams porting HPC code might run quick tests of both strategies on a few kernels before committing to one workflow.
- Automated detection of CPU-GPU design mismatch could decide when to apply deoptimization without manual intervention.
- The same deopt-reopt idea could be tested on other LLM translation tasks such as moving between different GPU architectures.
- End-to-end timing that includes failed attempts would show whether the conditional runtime gains produce net workflow savings.
Load-bearing premise
That runtime comparisons restricted to successfully compiled and executed trials give a fair picture of the two strategies even when their overall success rates differ substantially.
What would settle it
An experiment that equalizes success rates between Direct and Deopt-Reopt across the same kernels and still observes no consistent performance difference would undermine the claim of conditional benefits.
Figures

read the original abstract
When porting high-performance computing (HPC) code from CPU to GPU, CPU-oriented optimizations may obstruct LLM-based CUDA translation. We design and evaluate a Deopt-Reopt workflow that first simplifies the input C++ code and then retranslates and reoptimizes it for CUDA, comparing it against direct translation (Direct) on twelve HPC kernels with two LLMs (gpt-oss-120b (O120) and qwen-3-235b-a22b-instruct-2507 (Q235)) in Single-shot (one pass) and Iterative (repeated refinement) settings. In Single-shot, among 18 testable cases Deopt-Reopt was significantly faster among successful trials (after BH-FDR correction) in five - most clearly for conv2d, where CPU- and GPU-oriented designs diverge - but Direct was faster in three, so removing CPU-specific optimizations is not universally beneficial. An exploratory Direct-3 control that equalizes the LLM-call count left Deopt-Reopt ahead in only four of nineteen testable cases, with Direct-3 ahead in four others. In Iterative, repeated generation and repair narrow the mode gap - markedly so for O120 - while Q235 retains large Deopt-Reopt advantages on conv2d, ddgemm, and bgemm. Deopt-Reopt's effect on feasibility is also mixed - sharply higher for some kernels Direct rarely compiles, lower for others. Because performance is conditioned on successful trials, the benefit is conditional rather than a guaranteed end-to-end gain. Overall, Deopt-Reopt is an effective but non-universal technique for LLM-based GPU porting, with gains that depend on the kernel, the model, the search budget, and the success rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates a Deopt-Reopt workflow for LLM-based porting of optimized C++ HPC code to CUDA. The workflow deoptimizes the input code to remove CPU-specific optimizations before translation and reoptimization, compared to direct translation (Direct). Experiments on twelve kernels with two LLMs (O120 and Q235) in single-shot and iterative settings show mixed results: Deopt-Reopt yields faster runtimes in 5 of 18 single-shot cases after BH-FDR correction, Direct in 3, with varying effects on compilation success. The conclusion is that Deopt-Reopt is effective but non-universal, with benefits depending on kernel, model, search budget, and success rate.
Significance. If the results hold, this work demonstrates that CPU-oriented optimizations can impede LLM CUDA translation and that a deoptimization step can provide gains in specific cases, such as conv2d where designs diverge. The use of statistical correction (BH-FDR) and an exploratory Direct-3 control for equalizing LLM calls strengthens the empirical comparison. It contributes to automated code porting research by emphasizing the conditional nature of performance benefits and the role of success rates in evaluating such techniques.
major comments (1)
- Abstract: The runtime comparisons supporting the effectiveness claim are conditioned on successful trials only. When success rates differ substantially between Direct and Deopt-Reopt (as the abstract notes for some kernels where Direct rarely compiles), this conditional analysis may overstate practical gains. The paper should either provide unconditional metrics (e.g., success-weighted performance) or more explicitly discuss how the mixed success rates affect the overall recommendation of the workflow.
minor comments (2)
- Abstract: The model names 'gpt-oss-120b (O120)' and 'qwen-3-235b-a22b-instruct-2507 (Q235)' would benefit from full citations or version details for reproducibility.
- Abstract: Kernel selection criteria and the exact deoptimization rules are not detailed in the abstract, limiting assessment of generalizability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to ensure that conditional performance results are not misinterpreted as unconditional gains. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: The runtime comparisons supporting the effectiveness claim are conditioned on successful trials only. When success rates differ substantially between Direct and Deopt-Reopt (as the abstract notes for some kernels where Direct rarely compiles), this conditional analysis may overstate practical gains. The paper should either provide unconditional metrics (e.g., success-weighted performance) or more explicitly discuss how the mixed success rates affect the overall recommendation of the workflow.
Authors: We agree that all runtime comparisons are conditioned on successful compilations and that differing success rates can affect practical interpretation. The abstract already states this limitation explicitly: 'Because performance is conditioned on successful trials, the benefit is conditional rather than a guaranteed end-to-end gain' and notes that 'Deopt-Reopt's effect on feasibility is also mixed.' The conclusion further emphasizes that gains 'depend on the kernel, the model, the search budget, and the success rate.' To respond to the request for more explicit discussion, we will expand the relevant paragraph in the Results section (and update the abstract if space permits) to include a short dedicated subsection on how success-rate differences qualify the recommendation of the workflow. We do not plan to introduce unconditional metrics such as success-weighted performance, because any such metric would require an arbitrary penalty for failures (e.g., infinite runtime or a fixed cost), which risks introducing more distortion than the current transparent conditional analysis accompanied by explicit caveats and BH-FDR correction. revision: partial
Circularity Check
No circularity: purely empirical comparison of translation strategies
full rationale
The paper reports runtime and success-rate measurements from LLM-based code translation experiments on 12 kernels under Direct vs. Deopt-Reopt workflows. No mathematical derivations, equations, fitted parameters, or uniqueness theorems appear anywhere in the text. All claims rest on observed outcomes of compilation/execution trials rather than any reduction of a 'prediction' to its own inputs or to a self-citation chain. The conditioning of performance statistics on successful trials is explicitly noted in the abstract and is a standard experimental reporting choice, not a circular definitional step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The twelve HPC kernels adequately represent the range of CPU-to-GPU porting challenges encountered in practice.
Reference graph
Works this paper leans on
-
[1]
Leveraging Large Language Models for Code Translation and Software Development in Scientific Computing,
A. Dhruv and A. Dubey, “Leveraging Large Language Models for Code Translation and Software Development in Scientific Computing,” inProceedings of the Platform for Advanced Scientific Computing Conference (PASC ’25), 2025, pp. 1–9
2025
-
[2]
CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming,
A. TehraniJamsaz, A. Bhattacharjee, L. Chen, N. K. Ahmed, A. Yaz- danbakhsh, and A. Jannesari, “CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 100 965– 100 999
2024
-
[3]
L. Chen, B. Lei, D. Zhou, P.-H. Lin, C. Liao, C. Ding, and A. Jannesari, “Fortran2CPP: Automating Fortran-to-C++ Translation using LLMs via Multi-Turn Dialogue and Dual-Agent Integration,”arXiv preprint arXiv:2412.19770, 2024
arXiv 2024
-
[4]
OpenMP to GPGPU: A Compiler Framework for Automatic Translation and Optimization,
S. Lee, S.-J. Min, and R. Eigenmann, “OpenMP to GPGPU: A Compiler Framework for Automatic Translation and Optimization,” inProceedings of the 14th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 2009), 2009, pp. 101–110
2009
-
[5]
Polyhedral Parallel Code Generation for CUDA,
S. Verdoolaege, J. C. Juega, A. Cohen, J. I. Gómez, C. Tenllado, and F. Catthoor, “Polyhedral Parallel Code Generation for CUDA,”ACM Transactions on Architecture and Code Optimization, vol. 9, no. 4, pp. 1–23, 2013, article 54
2013
-
[6]
Automated Transformation of OpenMP to CUDA Ker- nels Using AI Models,
M. Gruzewski, “Automated Transformation of OpenMP to CUDA Ker- nels Using AI Models,”Procedia Computer Science, vol. 270, pp. 3352– 3361, 2025
2025
-
[7]
KernelBench: Can LLMs Write Efficient GPU Kernels?
A. Ouyang, S. Guo, S. Arora, A. L. Zhang, W. Hu, C. Ré, and A. Mirho- seini, “KernelBench: Can LLMs Write Efficient GPU Kernels?” in Proceedings of the 42nd International Conference on Machine Learning (ICML 2025), ser. Proceedings of Machine Learning Research, vol. 267, 2025, pp. 47 356–47 415
2025
-
[8]
CUDA-LLM: LLMs Can Write Efficient CUDA Kernels,
W. Chen, J. Zhu, Q. Fan, Y . Ma, and A. Zou, “CUDA-LLM: LLMs Can Write Efficient CUDA Kernels,”arXiv preprint arXiv:2506.09092, 2025
arXiv 2025
-
[9]
CudaForge: An Agent Framework with Hardware Feedback for CUDA Kernel Optimization,
Z. Zhang, R. Wang, S. Li, Y . Luo, M. Hong, and C. Ding, “CudaForge: An Agent Framework with Hardware Feedback for CUDA Kernel Optimization,”arXiv preprint arXiv:2511.01884, 2025
arXiv 2025
-
[10]
LLM-Assisted Translation of Legacy FORTRAN Codes to C++: A Cross-Platform Study,
N. R. Ranasinghe, S. M. Jones, M. Kucer, A. Biswas, D. O’Malley, A. Most, S. L. Wanna, and A. Sreekumar, “LLM-Assisted Translation of Legacy FORTRAN Codes to C++: A Cross-Platform Study,” inPro- ceedings of the 1st Workshop on AI and Scientific Discovery: Directions and Opportunities. Association for Computational Linguistics, 2025, pp. 58–69
2025
-
[11]
BabelTower: Learning to Auto- parallelized Program Translation,
Y . Wen, Q. Guo, Q. Fu, X. Li, J. Xu, Y . Tang, Y . Zhao, X. Hu, Z. Du, L. Li, C. Wang, X. Zhou, and Y . Chen, “BabelTower: Learning to Auto- parallelized Program Translation,” inProceedings of the 39th Interna- tional Conference on Machine Learning (ICML 2022), ser. Proceedings of Machine Learning Research, vol. 162, 2022, pp. 23 685–23 700
2022
-
[12]
Beyond Code Pairs: Dialogue- Based Data Generation for LLM Code Translation,
L. Chen, N. Xu, W. Chen, B. Lei, P.-H. Lin, D. Zhou, R. Thakur, C. Ding, A. Jannesari, and C. Liao, “Beyond Code Pairs: Dialogue- Based Data Generation for LLM Code Translation,”arXiv preprint arXiv:2512.03086, 2025
Pith/arXiv arXiv 2025
-
[13]
Refactoring Programs Using Large Language Models with Few-Shot Examples,
A. Shirafuji, Y . Oda, J. Suzuki, M. Morishita, and Y . Watanobe, “Refactoring Programs Using Large Language Models with Few-Shot Examples,” inProceedings of the 30th Asia-Pacific Software Engineering Conference (APSEC 2023), 2023
2023
-
[14]
An Empirical Study on the Potential of LLMs in Automated Software Refactoring,
B. Liu, Y . Jiang, Y . Zhang, N. Niu, G. Li, and H. Liu, “An Empirical Study on the Potential of LLMs in Automated Software Refactoring,” arXiv preprint arXiv:2411.04444, 2024
arXiv 2024
-
[15]
LLM-Driven Code Refactoring: Opportunities and Limitations,
J. Cordeiro, S. Noei, and Y . Zou, “LLM-Driven Code Refactoring: Opportunities and Limitations,” inProceedings of the 2025 IEEE/ACM 2nd International Workshop on Integrated Development Environments (IDE), 2025, pp. 32–36
2025
-
[16]
Simplicity by Obfuscation: Evaluating LLM-Driven Code Transformation with Se- mantic Elasticity,
L. De Tomasi, C. Di Sipio, A. Di Marco, and P. T. Nguyen, “Simplicity by Obfuscation: Evaluating LLM-Driven Code Transformation with Se- mantic Elasticity,” inProceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering (EASE 2025), 2025
2025
-
[17]
Leveraging LLMs to Automate Energy-Aware Refactoring of Parallel Scientific Codes,
M. T. Dearing, Y . Tao, X. Wu, Z. Lan, and V . Taylor, “Leveraging LLMs to Automate Energy-Aware Refactoring of Parallel Scientific Codes,” arXiv preprint arXiv:2505.02184, 2025
Pith/arXiv arXiv 2025
-
[18]
Exploring the Potential of LLMs for Code Deobfuscation,
D. Beste, G. Menguy, H. Hajipour, M. Fritz, A. E. Cinà, S. Bardin, T. Holz, T. Eisenhofer, and L. Schönherr, “Exploring the Potential of LLMs for Code Deobfuscation,” inDetection of Intrusions and Malware, and Vulnerability Assessment – DIMVA 2025, Proceedings, Part I, ser. Lecture Notes in Computer Science, vol. 15747. Springer, 2025, pp. 267–286
2025
-
[19]
Natural Is The Best: Model-Agnostic Code Simplification for Pre-trained Large Language Models,
Y . Wang, X. Li, T. N. Nguyen, S. Wang, C. Ni, and L. Ding, “Natural Is The Best: Model-Agnostic Code Simplification for Pre-trained Large Language Models,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 586–608, 2024
2024
-
[20]
gpt-oss-120b & gpt-oss-20b Model Card,
OpenAI, “gpt-oss-120b & gpt-oss-20b Model Card,” https: //cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/ oai_gpt-oss_model_card.pdf, 2025
2025
-
[21]
Qwen3-235B-A22B-Instruct-2507 Model Card,
Qwen Team, “Qwen3-235B-A22B-Instruct-2507 Model Card,” https:// huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507, 2025
2025
-
[22]
Controlling the false discovery rate: a practical and powerful approach to multiple testing,
Y . Benjamini and Y . Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,”Journal of the Royal Statistical Society: Series B (Methodological), vol. 57, no. 1, pp. 289–300, 1995
1995
-
[23]
A floating-point technique for extending the available precision,
T. J. Dekker, “A floating-point technique for extending the available precision,”Numerische Mathematik, vol. 18, no. 3, pp. 224–242, 1971
1971
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.