Edge-Aware Curvature Modeling for Graph Understanding in Large Language Models
Pith reviewed 2026-06-27 23:34 UTC · model grok-4.3
The pith
Neglecting edge information in graph-LLM alignment leads to suboptimal solutions due to over-squashing from negative-curvature edges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
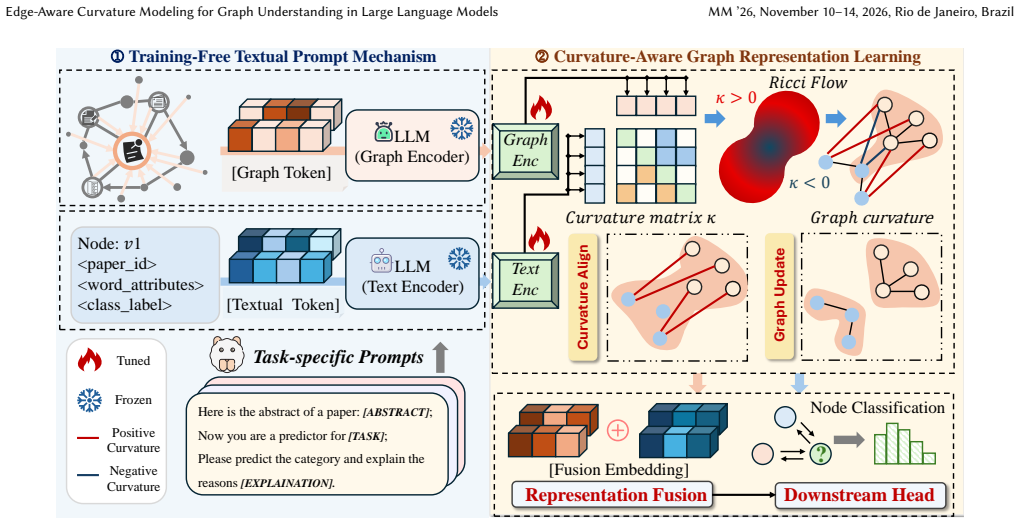
We prove theoretically for the first time that neglecting edge information leads to suboptimal solutions and negatively curved edges induce bottlenecked information flow, giving rise to the over-squashing phenomenon between graph and textual views. The CureLLM framework addresses this by using training-free textual prompts based on edges and curvature-aware message passing restricted to positive-curvature edges.
What carries the argument
Curvature-aware graph representation learning that restricts message passing to edges with positive curvature, combined with edge-aware textual prompts in the LLM.
If this is right
- Node-level alignment alone is insufficient for bridging graph and textual representations.
- Restricting information flow to positive-curvature edges mitigates over-squashing without additional parameter costs.
- The framework achieves superior performance compared to 20 other methods on 11 datasets.
- Edge information can be injected into LLMs through prompts without training new parameters.
Where Pith is reading between the lines
- Similar curvature-based restrictions could apply to other graph-to-text tasks where bottlenecks occur.
- Future work might explore whether selectively including some negative-curvature edges improves specific downstream tasks.
- This suggests that geometric properties of graphs play a key role in multimodal LLM performance beyond node features.
Load-bearing premise
The curvature properties of edges directly control information flow bottlenecks between graph encoders and LLM text representations in a manner that cannot be fixed by node-level alignment.
What would settle it
An experiment demonstrating that models using negative-curvature edges for message passing achieve better or equal performance on the tasks, or that the theoretical proof of suboptimal solutions does not hold empirically.
Figures



read the original abstract
Recently, graph-aware Large Language Models (LLMs) have shown promising capabilities in jointly modeling graph-structured data and textual information. Existing approaches typically employ a graph encoder and a frozen LLM to obtain node representations from graph and textual views, followed by node-level alignment to bridge the two modalities. However, such alignment mechanisms primarily focus on node information while overlooking edge-level structures, leading to suboptimal information propagation across views. In this work, we conduct a comprehensive theoretical analysis to uncover why node-level alignment is insufficient for aligning textual and graph representations. Specifically, we prove theoretically for the first time that neglecting edge information leads to suboptimal solutions and negatively curved edges induce bottlenecked information flow, giving rise to the over-squashing phenomenon between graph and textual views. To address the two challenges, we innovatively proposed a CureLLM framework of Curvature-enhanced Graph Representations for Large Language Model whose goal is to inject the signals of edge information into the existing LLMs. Specifically, CureLLM first introduces the training-free textual prompt mechanism to make the LLM model generate the output directly based on the edge-aware prompt without learnable parameter costs. Furthermore, a novel curvature-aware graph representation learning is designed to capture the edge structure information to enhance the downstream tasks, where the message passing between text and graph representations only depends on edges with positive curvature. Finally, we conduct evaluations with 20 different compared methods on 11 real world datasets from various domains and the experiment results demonstrate the superiority of our proposed CureLLM framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that node-level alignment between graph encoders and frozen LLMs is suboptimal because it neglects edge information, and provides a first-time theoretical proof that negative-curvature edges create unmitigable bottlenecks and over-squashing between graph and textual views. It introduces the CureLLM framework, which uses training-free edge-aware textual prompts and restricts message passing to positive-curvature edges only, reporting empirical superiority over 20 baselines on 11 datasets.
Significance. If the theoretical derivation rigorously establishes the curvature-to-cross-modal-flow mapping and the experiments include proper ablations and controls, the work would offer a concrete mechanism for incorporating edge structure into graph-LLM systems and a potential explanation for over-squashing phenomena across modalities. The training-free prompt component and curvature restriction are practically attractive if they generalize.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: the central claim that negative-curvature edges induce bottlenecked information flow between the graph encoder outputs and the independently encoded frozen-LLM text representations requires an explicit formal definition of cross-view information flow and a derivation showing why intra-graph discrete curvature governs LLM-side representations; the provided abstract and framework description do not supply these steps, leaving the mapping from graph curvature to cross-modal bottleneck unshown and load-bearing for the optimality proof.
- [Curvature-aware graph representation learning] Curvature-aware message passing description: the restriction of message passing to positive-curvature edges is presented as resolving over-squashing without loss of critical signals, yet no equation or analysis demonstrates that node-level alignment cannot route around negative-curvature edges or that the positive-curvature subset preserves task-relevant information; this assumption directly supports the framework's design choice.
minor comments (2)
- [Abstract] Abstract: the sentence introducing CureLLM contains a grammatical issue ('framework of Curvature-enhanced Graph Representations for Large Language Model whose goal...').
- [Experiments] The experimental claims of superiority would benefit from explicit reporting of metrics, error bars, and ablation results on the curvature threshold in the main text rather than relying solely on the abstract statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our theoretical claims and design choices. We address each major comment below and will revise the manuscript to improve clarity and completeness of the derivations.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the central claim that negative-curvature edges induce bottlenecked information flow between the graph encoder outputs and the independently encoded frozen-LLM text representations requires an explicit formal definition of cross-view information flow and a derivation showing why intra-graph discrete curvature governs LLM-side representations; the provided abstract and framework description do not supply these steps, leaving the mapping from graph curvature to cross-modal bottleneck unshown and load-bearing for the optimality proof.
Authors: The manuscript contains a dedicated Theoretical Analysis section that establishes the link between negative curvature and cross-modal over-squashing. We agree, however, that an explicit formal definition of cross-view information flow and a more detailed derivation of the curvature-to-LLM mapping would make the argument self-contained. In the revision we will insert a new subsection that supplies these definitions and step-by-step derivations. revision: yes
-
Referee: [Curvature-aware graph representation learning] Curvature-aware message passing description: the restriction of message passing to positive-curvature edges is presented as resolving over-squashing without loss of critical signals, yet no equation or analysis demonstrates that node-level alignment cannot route around negative-curvature edges or that the positive-curvature subset preserves task-relevant information; this assumption directly supports the framework's design choice.
Authors: The restriction follows directly from the theoretical result that negative-curvature edges create unmitigable bottlenecks. We acknowledge that the current text does not include an explicit supporting equation or analysis showing that node-level alignment cannot circumvent these edges or that the positive-curvature subset retains task-relevant information. We will add a short analytic argument together with a supporting lemma in the revised version. revision: yes
Circularity Check
No circularity: theoretical claim asserted as independent analysis without reduction to inputs or self-citations
full rationale
The paper's central claim is a first-time theoretical proof that node-level alignment is suboptimal because negative-curvature edges induce over-squashing between graph and textual views. The abstract states this conclusion and describes the CureLLM framework (training-free prompts plus curvature-aware message passing restricted to positive-curvature edges), but supplies no equations, fitted parameters, or self-citations that reduce the proof or the positive-curvature restriction to the inputs by construction. No self-definitional loop, fitted-input-called-prediction, or load-bearing self-citation chain appears in the provided text. The derivation is therefore treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- curvature sign threshold
axioms (2)
- domain assumption Neglecting edge information in node-level alignment necessarily produces suboptimal graph-text representations
- domain assumption Over-squashing between graph and textual views is induced specifically by negatively curved edges
Reference graph
Works this paper leans on
-
[1]
Hugo Attali, Davide Buscaldi, and Nathalie Pernelle. 2024. Delaunay Graph: Addressing Over-Squashing and Over-Smoothing Using Delaunay Triangulation. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
2024
-
[2]
Hugo Attali, Davide Buscaldi, and Nathalie Pernelle. 2024. Delaunay graph: Addressing over-squashing and over-smoothing using delaunay triangulation. In Forty-first International Conference on Machine Learning
2024
-
[3]
Jianyuan Bo, Hao Wu, and Yuan Fang. 2025. Quantizing text-attributed graphs for semantic-structural integration. InProceedings of the Thirty-First ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 107–118
2025
-
[4]
Jakub Bober, Anthea Monod, Emil Saucan, and Kevin N Webster. 2023. Rewiring networks for graph neural network training using discrete geometry. InIn- ternational Conference On Complex Networks And Their Applications. Springer, 225–236
2023
-
[5]
Bing Cao, Yinan Xia, Yi Ding, Changqing Zhang, and Qinghua Hu. 2024. Predic- tive Dynamic Fusion. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
2024
-
[6]
David Castillo-Bolado, Joseph Davidson, Finlay Gray, and Marek Rosa. 2024. Beyond Prompts: Dynamic Conversational Benchmarking of Large Language Models. InAdvances in Neural Information Processing Systems 38: Annual Confer- ence on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[7]
Zhaoliang Chen, Zhihao Wu, Zhenghong Lin, Shiping Wang, Claudia Plant, and Wenzhong Guo. 2023. AGNN: Alternating graph-regularized neural networks to alleviate over-smoothing.IEEE Transactions on Neural Networks and Learning Systems(2023)
2023
-
[8]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[9]
DeepSeek-AI. 2024. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism.arXiv preprint arXiv:2401.02954(2024). https://github.com/ deepseek-ai/DeepSeek-LLM
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[11]
Mingzhe Du, Anh Tuan Luu, Bin Ji, Qian Liu, and See-Kiong Ng. 2024. Mercury: A Code Efficiency Benchmark for Code Large Language Models. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Informa- tion Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[12]
Zihan Fang, Zhiling Cai, Yuxuan Zheng, Shide Du, Yanchao Tan, and Shiping Wang. 2025. HiTuner: Hierarchical Semantic Fusion Model Fine-Tuning on Text-Attributed Graphs. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence
2025
-
[13]
Tannenbaum, and Guillermo Sapiro
Amirhossein Farzam, Allen R. Tannenbaum, and Guillermo Sapiro. 2024. From Geometry to Causality- Ricci Curvature and the Reliability of Causal Inference on Networks. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 (Proceedings of Machine Learning Research). 13086–13108
2024
-
[14]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[15]
Buntine, and Ehsan Shareghi
Jiuzhou Han, Nigel Collier, Wray L. Buntine, and Ehsan Shareghi. 2024. PiVe: Prompting with Iterative Verification Improving Graph-based Generative Capa- bility of LLMs. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. 6702–6718
2024
-
[16]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. [n. d.]. DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION. InInter- national Conference on Learning Representations
-
[17]
Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. 2024. Harnessing Explanations: LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning. InThe Twelfth International Conference on Learning Representations
2024
-
[18]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. InProceedings of the 43rd International ACM SIGIR con- ference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang,...
-
[19]
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. 2024. G-retriever: Retrieval-augmented gen- eration for textual graph understanding and question answering.Advances in Neural Information Processing Systems37 (2024), 132876–132907
2024
-
[20]
Zhiyuan Hu, Chumin Liu, Xidong Feng, Yilun Zhao, See-Kiong Ng, Anh Tuan Luu, Junxian He, Pang Wei W Koh, and Bryan Hooi. 2024. Uncertainty of thoughts: Uncertainty-aware planning enhances information seeking in LLMs.Advances in Neural Information Processing Systems37 (2024), 24181–24215
2024
-
[21]
Sujia Huang, Yueyang Pi, Tong Zhang, Wenzhe Liu, and Zhen Cui. 2025. Boosting Graph Convolution with Disparity-induced Structural Refinement. InTHE WEB CONFERENCE. 1–10
2025
-
[22]
Xuanwen Huang, Kaiqiao Han, Yang Yang, Dezheng Bao, Quanjin Tao, Ziwei Chai, and Qi Zhu. 2024. Can GNN be Good Adapter for LLMs?. InProceedings of the ACM Web Conference 2024. 893–904. MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Trovato et al
2024
-
[23]
2008.Riemannian geometry and geometric analysis
Jürgen Jost and Jeurgen Jost. 2008.Riemannian geometry and geometric analysis. Vol. 42005. Springer
2008
-
[24]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InProceedings of the 5th International Conference on Learning Representations. 1–14
2017
- [25]
-
[26]
Andreas Köpf, Yannic Kilcher, Dimitri Von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, et al. 2023. Openassistant conversations-democratizing large language model alignment.Advances in Neural Information Processing Systems36 (2023), 47669–47681
2023
-
[27]
Jianxin Li, Xingcheng Fu, Qingyun Sun, Cheng Ji, Jiajun Tan, Jia Wu, and Hao Peng. 2022. Curvature graph generative adversarial networks. InProceedings of the ACM web conference 2022. 1528–1537
2022
-
[28]
Wanhua Li, Zibin Meng, Jiawei Zhou, Donglai Wei, Chuang Gan, and Hanspeter Pfister. 2024. SocialGPT: Prompting LLMs for Social Relation Reasoning via Greedy Segment Optimization. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[29]
Yuhan Li, Peisong Wang, Xiao Zhu, Aochuan Chen, Haiyun Jiang, Deng Cai, Wai Kin (Victor) Chan, and Jia Li. 2024. GLBench: A Comprehensive Benchmark for Graph with Large Language Models. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 -...
2024
-
[30]
Zhenghong Lin, Wei Huang, Hengyu Zhang, Jiayu Xu, Weiming Liu, Xinting Liao, Fan Wang, Shiping Wang, and Yanchao Tan. 2024. Enhancing dual-target cross-domain recommendation with federated privacy-preserving learning. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelli- gence, IJCAI-24. 2153–2161
2024
-
[31]
Zhenghong Lin, Yanchao Tan, Yunfei Zhan, Weiming Liu, Fan Wang, Chaochao Chen, Shiping Wang, and Carl Yang. 2023. Contrastive intra-and inter-modality generation for enhancing incomplete multimedia recommendation. InProceedings of the 31st ACM International Conference on Multimedia. 6234–6242
2023
-
[32]
Zhenghong Lin, Qishan Yan, Weiming Liu, Shiping Wang, Menghan Wang, Yan- chao Tan, and Carl Yang. 2023. Automatic hypergraph generation for enhancing recommendation with sparse optimization.IEEE Transactions on Multimedia26 (2023), 5680–5693
2023
-
[33]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys55, 9 (2023), 1–35
2023
-
[34]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Zheyuan Liu, Xiaoxin He, Yijun Tian, and Nitesh V Chawla. 2024. Can we soft prompt LLMs for graph learning tasks?. InCompanion Proceedings of the ACM Web Conference 2024. 481–484
2024
-
[36]
Haoran Luo, Haihong E, Zichen Tang, Shiyao Peng, Yikai Guo, Wentai Zhang, Chenghao Ma, Guanting Dong, Meina Song, Wei Lin, Yifan Zhu, and Anh Tuan Luu. 2024. ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models. InFindings of the Association for Computational Linguistics ACL 2024. Bangkok...
2024
-
[37]
Haoran Luo, Haihong E, Yuhao Yang, Tianyu Yao, Yikai Guo, Zichen Tang, Wentai Zhang, Shiyao Peng, Kaiyang Wan, Meina Song, Wei Lin, Yifan Zhu, and Anh Tuan Luu. 2024. Text2NKG: Fine-Grained N-ary Relation Extraction for N-ary relational Knowledge Graph Construction. InAdvances in Neural Information Processing Systems, Vol. 37. 27417–27439
2024
-
[38]
Zizhuo Meng, Ke Wan, Yadong Huang, Zhidong Li, Yang Wang, and Feng Zhou
-
[39]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29,
Interpretable Transformer Hawkes Processes: Unveiling Complex Interac- tions in Social Networks. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29,
2024
-
[40]
Mohri, A
M. Mohri, A. Rostamizadeh, and Talwalkar. 2018.Fundamentals of machine learning. MIT Press
2018
-
[41]
Chien-Chun Ni, Yu-Yao Lin, Jie Gao, Xianfeng David Gu, and Emil Saucan. 2015. Ricci curvature of the internet topology. In2015 IEEE conference on computer communications (INFOCOM). IEEE, 2758–2766
2015
-
[42]
Yann Ollivier. 2007. Ricci curvature of metric spaces.Comptes Rendus Mathema- tique345, 11 (2007), 643–646
2007
-
[43]
Yann Ollivier. 2009. Ricci curvature of Markov chains on metric spaces.Journal of Functional Analysis256, 3 (2009), 810–864
2009
-
[44]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
- [45]
-
[46]
Nils Reimers, I Sentence-BERT Gurevych, et al. 1908. Sentence embeddings using siamese BERT-networks. arXiv 2019.arXiv preprint arXiv:1908.1008410 (1908)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[47]
Xubin Ren, Jiabin Tang, Dawei Yin, Nitesh Chawla, and Chao Huang. 2024. A survey of large language models for graphs. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6616–6626
2024
-
[48]
Jayson Sia, Edmond Jonckheere, and Paul Bogdan. 2019. Ollivier-ricci curvature- based method to community detection in complex networks.Scientific reports9, 1 (2019), 9800
2019
-
[49]
Shichao Sun, Ruifeng Yuan, Ziqiang Cao, Wenjie Li, and Pengfei Liu. 2024. Prompt chaining or stepwise prompt? refinement in text summarization. InFindings of the Association for Computational Linguistics ACL 2024. 7551–7558
2024
-
[50]
Yanchao Tan, Hang Lv, Pengxiang Zhan, Shiping Wang, and Carl Yang. 2026. Graph-Oriented Instruction Tuning of Large Language Models for Generic Graph Mining.IEEE Transactions on Pattern Analysis and Machine Intelligence48, 1 (2026), 155–169
2026
-
[51]
Yanchao Tan, Zihao Zhou, Hang Lv, Weiming Liu, and Carl Yang. 2023. Walklm: A uniform language model fine-tuning framework for attributed graph embedding. Advances in neural information processing systems36 (2023), 13308–13325
2023
-
[52]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. GraphGPT: Graph Instruction Tuning for Large Language Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024. ACM, 491–500
2024
-
[53]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500
2024
-
[54]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Long Xia, Dawei Yin, and Chao Huang
-
[55]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Higpt: Heterogeneous graph language model. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2842–2853
-
[56]
Jake Topping, Francesco Di Giovanni, Benjamin Paul Chamberlain, Xiaowen Dong, and Michael M Bronstein. [n. d.]. Understanding over-squashing and bottlenecks on graphs via curvature. InInternational Conference on Learning Representations
-
[57]
Bronstein
Jake Topping, Francesco Di Giovanni, Benjamin Paul Chamberlain, Xiaowen Dong, and Michael M. Bronstein. 2022. Understanding over-squashing and bottlenecks on graphs via curvature. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022
2022
-
[58]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. InInternational Con- ference on Learning Representations
2018
-
[61]
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023. Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems36 (2023), 30840– 30861
2023
-
[62]
Yu Wang, Liang Hu, Xiaofeng Cao, Yi Chang, and Ivor W. Tsang. 2024. Enhancing Locally Adaptive Smoothing of Graph Neural Networks Via Laplacian Node Disagreement.IEEE Transactions on Knowledge and Data Engineering36 (2024), 1099–1112. doi:10.1109/TKDE.2023.3303212
-
[63]
Wei Wei, Chao Huang, Lianghao Xia, and Chuxu Zhang. 2023. Multi-modal self-supervised learning for recommendation. InProceedings of the ACM Web Conference 2023. 790–800
2023
-
[64]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Jun- feng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large language models with graph augmentation for recommendation. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 806–815
2024
-
[65]
Wei Wei, Jiabin Tang, Lianghao Xia, Yangqin Jiang, and Chao Huang. 2024. Multi- Modal Knowledge Distillation for Recommendation with Prompt-Tuning. InThe Web Conference 2024. https://openreview.net/forum?id=JG0Qa4LY3s
2024
-
[66]
Xiaobao Wu, Thong Nguyen, Delvin Zhang, William Yang Wang, and Anh Tuan Luu. 2024. FASTopic: Pretrained Transformer is a Fast, Adaptive, Stable, and Transferable Topic Model. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. ...
2024
-
[67]
Zhihao Wu, Xincan Lin, Zhenghong Lin, Zhaoliang Chen, Yang Bai, and Shiping Wang. 2023. Interpretable graph convolutional network for multi-view semi- supervised learning.IEEE Transactions on Multimedia25 (2023), 8593–8606
2023
-
[68]
Lianghao Xia, Ben Kao, and Chao Huang. 2024. OpenGraph: Towards Open Graph Foundation Models. InFindings of the Association for Computational Linguistics: EMNLP 2024. 2365–2379
2024
-
[69]
Chengming Xu, Chen Liu, Yikai Wang, Yuan Yao, and Yanwei Fu. 2024. Towards Global Optimal Visual In-Context Learning Prompt Selection. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Informa- tion Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[70]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How Powerful are Graph Neural Networks?. InInternational Conference on Learning Representa- tions
2019
-
[71]
Cheng Yang, Maosong Sun, Zhiyuan Liu, and Cunchao Tu. 2017. Fast Network Embedding Enhancement via High Order Proximity Approximation. InProceed- ings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017, Carles Sierra (Ed.). ijcai.org, 3894–3900. doi:10.24963/IJCAI.2017/544
-
[72]
Ze Ye, Kin Sum Liu, Tengfei Ma, Jie Gao, and Chao Chen. 2019. Curvature graph network. InInternational conference on learning representations
2019
-
[73]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations.Advances in neural information processing systems33 (2020), 5812–5823
2020
-
[74]
Xingyi Zhang, Kun Xie, Sibo Wang, and Zengfeng Huang. 2021. Learning Based Proximity Matrix Factorization for Node Embedding. InKDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, August 14-18, 2021, Feida Zhu, Beng Chin Ooi, and Chunyan Miao (Eds.). ACM, 2243–2253. doi:10.1145/3447548.3467296
-
[75]
Chuang Zhao, Hui Tang, Jiheng Zhang, and Xiaomeng Li. 2025. Unveiling Discrete Clues: Superior Healthcare Predictions for Rare Diseases. InProceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025- 2 May 2025. 1747–1758
2025
- [76]
-
[77]
Xin Zhou, Hongyu Zhou, Yong Liu, Zhiwei Zeng, Chunyan Miao, Pengwei Wang, Yuan You, and Feijun Jiang. 2023. Bootstrap latent representations for multi- modal recommendation. InProceedings of the ACM web conference 2023. 845–854
2023
-
[78]
Yun Zhu, Yaoke Wang, Haizhou Shi, and Siliang Tang. 2024. Efficient tuning and inference for large language models on textual graphs. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 5734–5742
2024
-
[79]
Shuman Zhuang, Sujia Huang, Wei Huang, Yuhong Chen, Zhihao Wu, and Ximeng Liu. 2024. Enhancing Multi-view Graph Neural Network with Cross- view Confluent Message Passing. InProceedings of the 32nd ACM International Conference on Multimedia. 10065–10074. MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Trovato et al. A Appendix A for Proofs of Theorems...
2024
-
[80]
He et al
proposed a framework to align graph domain-specific struc- tural knowledge with the reasoning ability of LLMs to improve the generalization of graph learning. He et al. [17] utlized LLMs to generate pseudo labels and explanations as augmented data, and concatenated the enhancements with text feature of PLMs for down- stream GNNs. Fang et al. [12] distille...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.