Detecting and Mitigating Bias by Treating Fairness as a Symmetry Operation
Pith reviewed 2026-06-28 10:25 UTC · model grok-4.3
The pith
A classifier is fair if its outputs stay invariant when a sensitive attribute is flipped while merit features remain fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
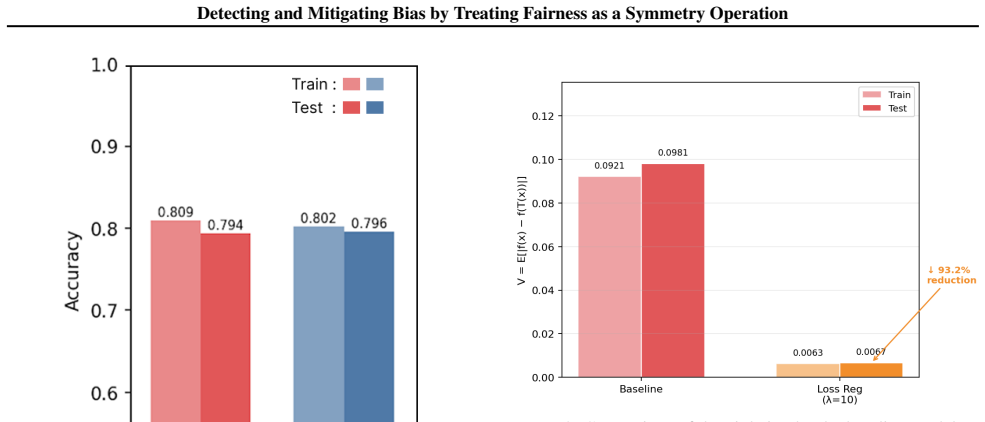
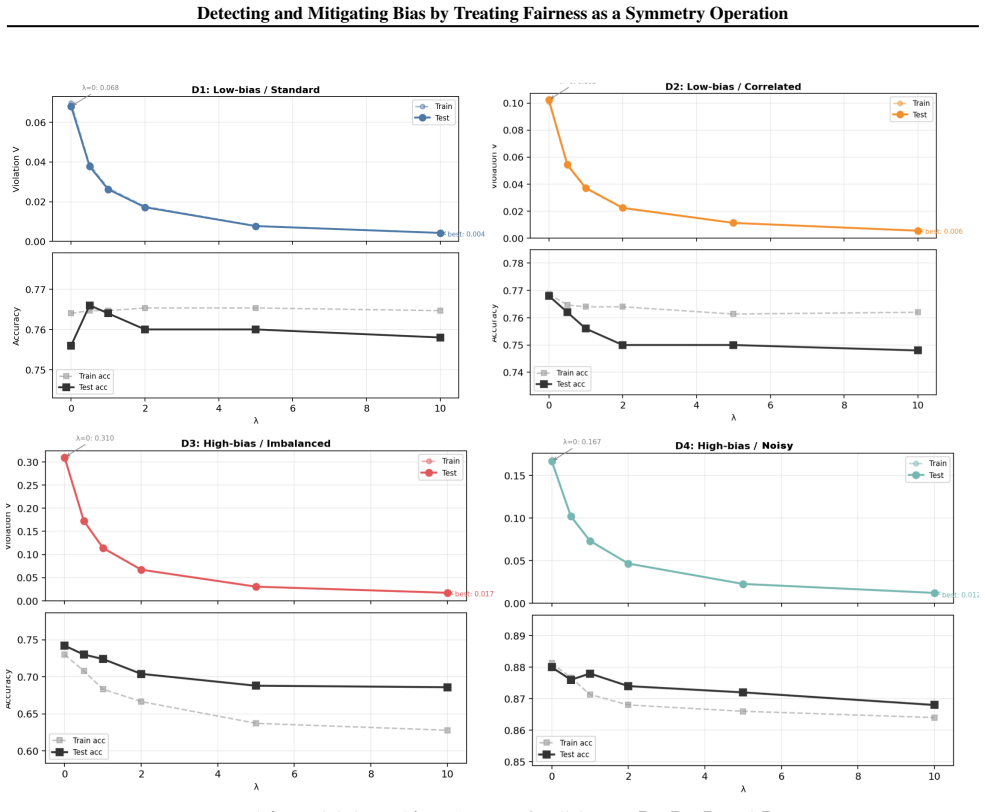
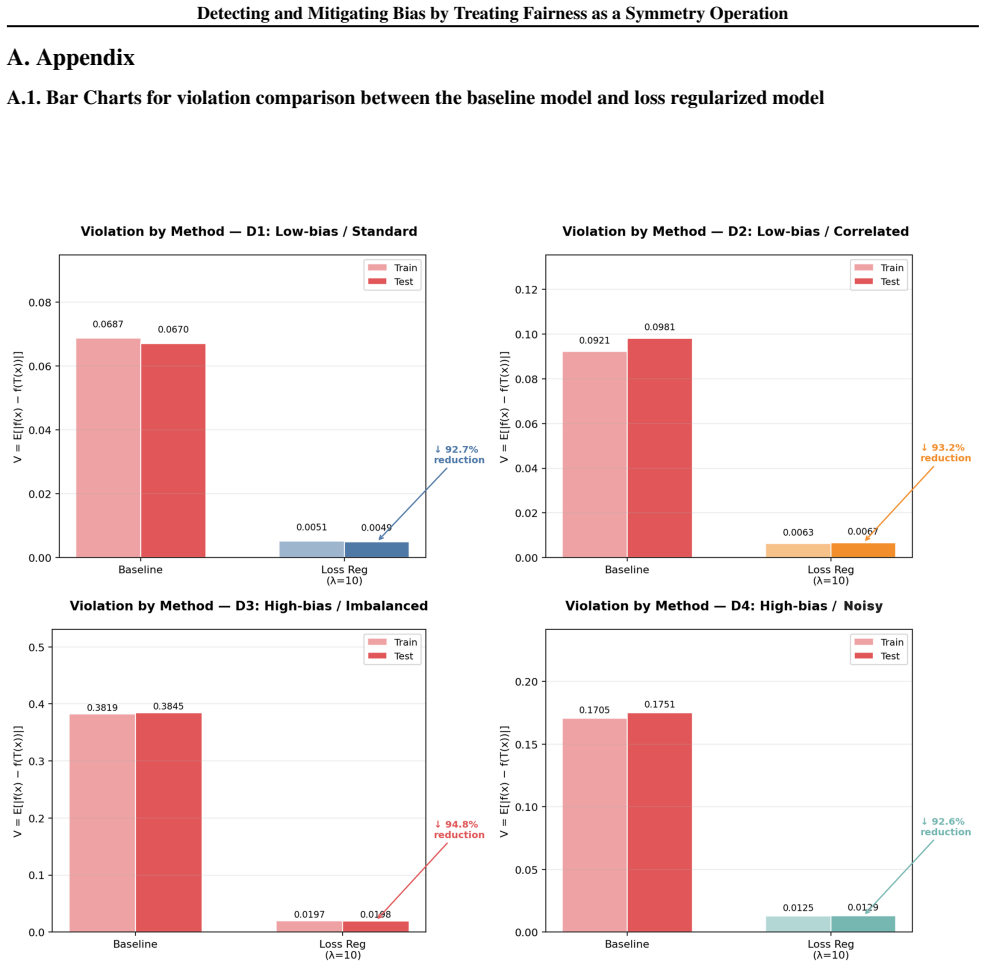
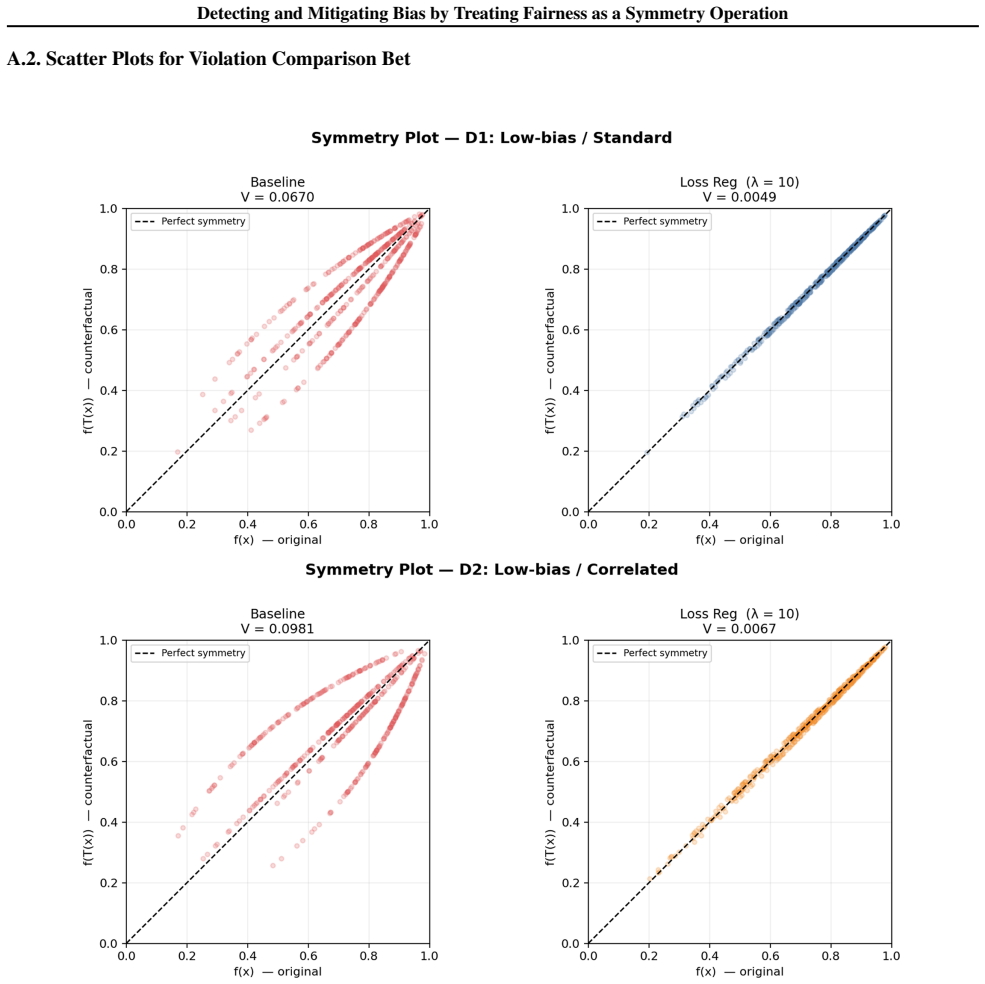
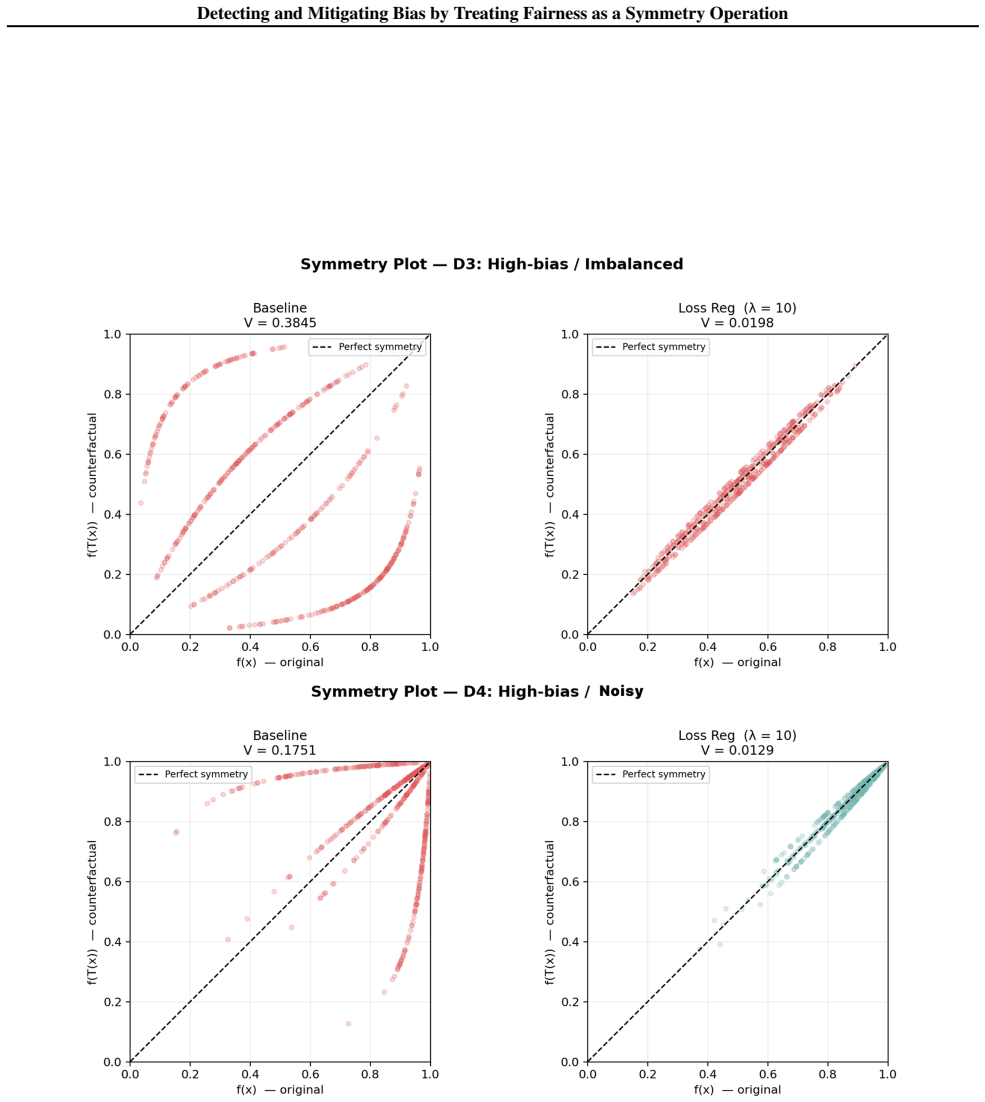
Bias is formalized as symmetry breaking where classifier outputs vary under the counterfactual operation of switching a sensitive attribute with merit features held fixed. Fairness is restored by loss-based regularization that enforces output invariance under this operation. On synthetic data the method reduces fairness violations by upwards of 90% with accuracy costs around 5%, without needing causal graph knowledge and generalizing to any bit-flip definable sensitive attribute.
What carries the argument
Loss regularization term that penalizes output differences under counterfactual sensitive-attribute bit-flips with merit features fixed.
If this is right
- Classifier outputs become identical for any instance and its counterfactual twin differing only in the sensitive attribute.
- Fairness violation reductions exceeding 90% are obtained on controlled synthetic data at an accuracy cost near 5%.
- The method applies to any binary sensitive attribute without requiring causal structure knowledge.
- It remains suitable for settings where sources of discrimination are absent from mainstream benchmarks.
Where Pith is reading between the lines
- The same regularization could be applied to regression or multi-class outputs by replacing the difference penalty with an appropriate distance measure.
- Checking invariance on held-out counterfactual pairs offers a simple post-training audit that does not need protected-group labels in the test set.
- If the invariance holds only approximately, combining the term with other regularizers might address multiple fairness definitions simultaneously.
Load-bearing premise
That enforcing output invariance under a simple bit-flip of the sensitive attribute with merit features fixed is a sufficient and complete definition of fairness that transfers from synthetic data to real settings.
What would settle it
A dataset where the regularized model shows low counterfactual violation yet still fails standard fairness metrics such as demographic parity or equalized odds.
Figures
read the original abstract
Machine learning systems deployed in high stakes socioeconomic settings routinely display bias. We formalize bias as a symmetry breaking operation: a classifier is fair if its outputs remain invariant under the counterfactual operation of switching a sensitive attribute, with merit features held fixed. We implement loss based regularization as a symmetry restoring mechanism and evaluate the framework on four synthetic datasets with varying levels of noise, correlation, and bias. The framework achieves upwards of 90\% violation reduction, with accuracy costs around 5\%. This framework does not require causal graph knowledge, is computationally lightweight, and generalizes to any sensitive attribute definable as a bit-flip, making it suitable for contexts where local sources of discrimination remain absent from mainstream benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes bias as symmetry breaking in classifiers, defining fairness as invariance of outputs under a counterfactual bit-flip of the sensitive attribute while holding merit features fixed. It proposes loss-based regularization to restore this symmetry and evaluates the approach on four synthetic datasets with controlled noise, correlation, and bias levels, reporting up to 90% violation reduction at roughly 5% accuracy cost. The method is presented as not requiring causal graph knowledge and applicable to any bit-flip definable sensitive attribute.
Significance. If the invariance-based regularization proves robust, the framework offers a computationally lightweight alternative to causal-graph-dependent fairness methods, potentially useful in domains lacking structural knowledge. The symmetry perspective is conceptually clean and could generalize across attribute types, but the exclusive reliance on synthetic data with author-controlled parameters limits demonstrated real-world applicability.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation sections: The central performance claims (≥90% violation reduction, ~5% accuracy cost) are supported exclusively by results on four synthetic datasets whose generation procedure, sample sizes, number of runs, and statistical tests are not described, preventing independent verification of the reported metrics.
- [Abstract] Abstract: The claim that the method 'does not require causal graph knowledge' is load-bearing for the contribution, yet the evaluation never tests transfer when the sensitive attribute has non-trivial dependencies on merit features that a simple bit-flip cannot isolate; this leaves open whether the learned invariance survives outside the controlled synthetic construction.
minor comments (1)
- [Abstract] The abstract states 'upwards of 90% violation reduction' without specifying the exact violation metric or how it is computed relative to the regularization term.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating where revisions to the manuscript will be incorporated.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation sections: The central performance claims (≥90% violation reduction, ~5% accuracy cost) are supported exclusively by results on four synthetic datasets whose generation procedure, sample sizes, number of runs, and statistical tests are not described, preventing independent verification of the reported metrics.
Authors: We agree that the current manuscript does not provide sufficient detail on the synthetic dataset construction and experimental protocol. In the revised manuscript, we will expand the evaluation section (and add an appendix if needed) with a complete description of the data generation process for the four datasets, including how noise, correlation, and bias levels were controlled; the sample sizes; the number of independent runs performed; and any statistical tests used to support the reported metrics. This will allow independent verification. revision: yes
-
Referee: [Abstract] Abstract: The claim that the method 'does not require causal graph knowledge' is load-bearing for the contribution, yet the evaluation never tests transfer when the sensitive attribute has non-trivial dependencies on merit features that a simple bit-flip cannot isolate; this leaves open whether the learned invariance survives outside the controlled synthetic construction.
Authors: The framework is formulated specifically for sensitive attributes that admit a well-defined bit-flip counterfactual while holding merit features fixed; the regularization directly penalizes violations of this invariance. The synthetic datasets were constructed to isolate this mechanism under controlled conditions. We acknowledge that the evaluation does not explore cases with complex, non-isolatable dependencies. In the revision we will add an explicit limitations paragraph clarifying the scope (i.e., applicability only when a clean bit-flip definition is feasible) and noting that performance under richer dependency structures remains an open question for future work. revision: partial
Circularity Check
No circularity identified from available text
full rationale
The provided abstract and context define fairness explicitly as output invariance under a sensitive-attribute bit-flip (merit features fixed) and describe loss regularization as the mechanism to enforce that invariance, with results reported on author-controlled synthetic data. No equations, self-citations, uniqueness theorems, or fitted parameters presented as independent predictions appear in the text. The central claim is therefore an empirical method proposal rather than a derivation that reduces to its own inputs by construction; the evaluation metrics are direct consequences of the regularization objective but are not shown to be tautological or load-bearing only via self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength
axioms (1)
- domain assumption A classifier is fair if its outputs remain invariant under the counterfactual operation of switching a sensitive attribute, with merit features held fixed.
Reference graph
Works this paper leans on
-
[1]
2017 , publisher=
Chouldechova, Alexandra , journal=. 2017 , publisher=
2017
-
[2]
2016 , eprint=
Equality of Opportunity in Supervised Learning , author=. 2016 , eprint=
2016
-
[3]
Information Technology Convergence and Services , year=
Inherent Trade-Offs in the Fair Determination of Risk Scores , author=. Information Technology Convergence and Services , year=
-
[4]
and Welling, Max , title =
Cohen, Taco S. and Welling, Max , title =. Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48 , pages =. 2016 , publisher =
2016
-
[5]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Kusner, Matt and Loftus, Joshua and Russell, Chris and Silva, Ricardo , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[6]
Dwork, Cynthia and Hardt, Moritz and Pitassi, Toniann and Reingold, Omer and Zemel, Richard , title =. Proceedings of the 3rd Innovations in Theoretical Computer Science Conference , pages =. 2012 , isbn =. doi:10.1145/2090236.2090255 , abstract =
-
[7]
Fairness-Aware Classifier with Prejudice Remover Regularizer
Kamishima, Toshihiro and Akaho, Shotaro and Asoh, Hideki and Sakuma, Jun. Fairness-Aware Classifier with Prejudice Remover Regularizer. Machine Learning and Knowledge Discovery in Databases. 2012
2012
-
[8]
Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society , pages =
Zhang, Brian Hu and Lemoine, Blake and Mitchell, Margaret , title =. Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society , pages =. 2018 , isbn =. doi:10.1145/3278721.3278779 , abstract =
-
[9]
Avoiding discrimination through causal reasoning , year =
Kilbertus, Niki and Rojas-Carulla, Mateo and Parascandolo, Giambattista and Hardt, Moritz and Janzing, Dominik and Sch\". Avoiding discrimination through causal reasoning , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[10]
Real World
AI in the "Real World": Examining the Impact of AI Deployment in Low-Resource Contexts , author=. 2020 , eprint=
2020
-
[11]
Joseph, J. , journal=. 2025 , publisher=. doi:10.3389/fpubh.2025.1643180 , pmid=
-
[12]
2021 , eprint=
Re-imagining Algorithmic Fairness in India and Beyond , author=. 2021 , eprint=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.