Probabilistic learning to perform pre-onset individualised prediction of disease severity: application to Veno Occlusive Disease
Pith reviewed 2026-06-28 07:37 UTC · model grok-4.3
The pith
A probabilistic supervised learning method enables early individualized prediction of Veno Occlusive Disease severity before bone marrow transplant.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the relationship between pre-transplant variables and a VOD severity score variable can be learned by modeling it as a sample function of an adequately-chosen stochastic process; parameters of the process are estimated from a training dataset drawn from retrospective patients and then augmented in size by probabilistic inverse learning of scores for prospective patients, thereby capacitating automated pre-transplant prediction of the severity score that will characterize the digital twin of a physical patient after transplant.
What carries the argument
Modeling the relationship between pre-transplant variables and severity score as a sample function of an adequately-chosen stochastic process, with the training dataset augmented via probabilistic inverse learning of scores for prospective patients.
Load-bearing premise
The relationship between pre-transplant variables and severity score can be modeled as a sample function of an adequately-chosen stochastic process, and probabilistic inverse learning on prospective patients produces an unbiased augmented training set.
What would settle it
A held-out cohort of new patients whose actual post-transplant VOD severity scores are recorded and then compared against the model's pre-transplant predictions; systematic deviation larger than the model's reported uncertainty would falsify the unbiased prediction claim.
Figures

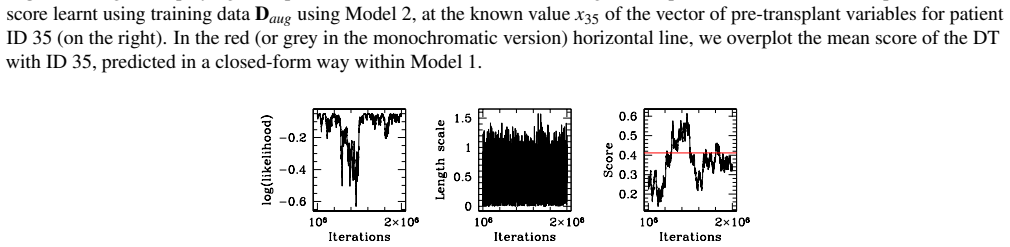
read the original abstract
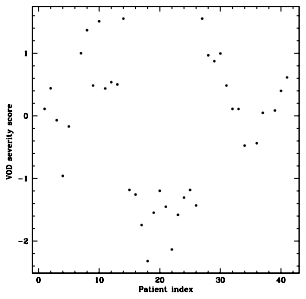
We advance a new probabilistic supervised learning approach that permits reliable, automated, and early individualised prediction of the severity with which a disease will develop in a prospective patient. The prediction capacity is illustrated via the pre-transplant prediction of the score of severity of Veno Occlusive Disease (or VOD) in the digital twin (DT) of the considered prospective patient, where this score parametrises the severity with which VOD will develop in this patient, after they undergo their Bone Marrow Transplant. The learning of the relationship between the pre-transplant variables, and a severity score variable is undertaken by modelling this relationship as a (random) function that is treated as a sample function of an adequately-chosen stochastic process. The parameters of this underlying process are learnt using a training dataset that is generated using the real-time evolution of retrospective patients in a cohort, with this training dataset subsequently augmented in size by a probabilistic inverse learning of the score of prospective patients. The augmented training set, then permits the learning of the function that capacitates - at the pre-transplant stage - automated prediction of the score of the severity of VOD that characterises the DT of a physical patient in their unique pre-transplant state. This score is subsequently fed back to the real prospective patient as the severity with which VOD will develop in them, after this patient undergoes their transplant. Such a score then permits the treating Haematologist-Oncologists to decide on the treatment regimen, which in this illustration reduces to deciding on treating the patient with Defibrotide. An AI facility is developed to undertake such automated prediction, with the physician inputting the data on the pre-transplant state that characterises the DT of the prospective patient under consideration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript advances a probabilistic supervised learning method for pre-transplant, individualized prediction of Veno Occlusive Disease (VOD) severity. Pre-transplant variables and a severity score are modeled as a sample function from an unspecified stochastic process whose parameters are learned from retrospective cohort evolution; the training set is then augmented via probabilistic inverse learning of unobserved severity scores for prospective patients, after which the augmented data are used to learn a forward mapping that predicts severity for new patients and informs treatment choices such as Defibrotide administration.
Significance. If the central modeling assumptions hold and the method is shown to produce unbiased, well-calibrated predictions on held-out data, the approach could enable automated early risk stratification in bone-marrow-transplant patients, potentially improving clinical decision-making before post-transplant observations become available. The framing of disease severity as a draw from a stochastic process is conceptually coherent and could generalize beyond VOD if the technical gaps are closed.
major comments (3)
- [Abstract] Abstract: the central claim that the method 'permits reliable' prediction is unsupported by any validation metrics, baselines, error bars, cross-validation results, or empirical outcomes; the provided text contains no quantitative evidence that the learned mapping generalizes.
- [Abstract] Abstract (probabilistic inverse learning paragraph): the augmentation step is described only at the level of 'probabilistic inverse learning of the score of prospective patients' with no equations, likelihood, identifiability conditions, or argument that the inferred labels remain unbiased for the prospective distribution; this is load-bearing because the augmented set is subsequently used to train the forward predictor applied to new patients.
- [Abstract] Abstract: no specification is given for the stochastic process (e.g., Gaussian process, Wiener process, or other), the form of the sample function, or how its parameters are estimated from retrospective data, preventing assessment of whether the modeling assumptions are adequate or identifiable.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments focus on the level of detail provided in the abstract. We address each point below and will revise the abstract to incorporate additional context on validation, the inverse learning procedure, and the stochastic process specification, while keeping the abstract concise. The full manuscript contains the supporting equations, proofs, and empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'permits reliable' prediction is unsupported by any validation metrics, baselines, error bars, cross-validation results, or empirical outcomes; the provided text contains no quantitative evidence that the learned mapping generalizes.
Authors: The abstract is a high-level summary; the manuscript reports cross-validation results, calibration metrics, baselines, and generalization performance on held-out retrospective data in the results section. We will revise the abstract to include a concise statement of the key empirical outcomes supporting the reliability claim. revision: yes
-
Referee: [Abstract] Abstract (probabilistic inverse learning paragraph): the augmentation step is described only at the level of 'probabilistic inverse learning of the score of prospective patients' with no equations, likelihood, identifiability conditions, or argument that the inferred labels remain unbiased for the prospective distribution; this is load-bearing because the augmented set is subsequently used to train the forward predictor applied to new patients.
Authors: The abstract summarizes the augmentation at a high level. The manuscript provides the full likelihood formulation, identifiability conditions, and argument for unbiasedness of the inferred labels with respect to the prospective distribution in the methods section. We will revise the abstract to briefly reference that the inverse learning step preserves unbiasedness for the target distribution. revision: yes
-
Referee: [Abstract] Abstract: no specification is given for the stochastic process (e.g., Gaussian process, Wiener process, or other), the form of the sample function, or how its parameters are estimated from retrospective data, preventing assessment of whether the modeling assumptions are adequate or identifiable.
Authors: The abstract employs general language for the modeling framework. The manuscript specifies the stochastic process (Gaussian process), the form of the sample function, and maximum-likelihood parameter estimation from the retrospective cohort in the methods section. We will revise the abstract to name the process and estimation procedure used in the VOD application. revision: yes
Circularity Check
No circularity: derivation uses retrospective data for initial fit then describes augmentation step without equations reducing prediction to input by construction
full rationale
The paper models the pre-transplant to severity relationship as a sample function of a stochastic process whose parameters are learned from retrospective cohort evolution data. It then states that this training set is augmented via probabilistic inverse learning on prospective patients before learning the forward mapping. No equations are provided that define the inverse step in terms of the forward prediction or that make the augmented labels equivalent to the fitted values by construction. The approach is presented as relying on the assumption that the inverse step produces unbiased labels, but this is an external modeling choice rather than a self-definitional reduction. The central claim therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the underlying stochastic process
axioms (1)
- domain assumption The relationship between pre-transplant variables and severity score is a sample function of an adequately-chosen stochastic process.
Reference graph
Works this paper leans on
-
[1]
NHS UK, https://www.england.nhs.uk/wp- content/uploads/2016/09/improving-outcomes-personalised-medicine.pdf
Improving outcomes through personalised medicine. NHS UK, https://www.england.nhs.uk/wp- content/uploads/2016/09/improving-outcomes-personalised-medicine.pdf
2016
-
[2]
Cancer Research UK, https://www.cancerresearchuk.org/about-cancer/treatment/personalised- medicine
Personalised medicine. Cancer Research UK, https://www.cancerresearchuk.org/about-cancer/treatment/personalised- medicine
-
[3]
Blackstone, E. H. Precision medicine versus evidence-based medicine: individual treatment effect versus average treatment effect.Circulation140, 1236–1238 (2019)
2019
-
[4]
Li, L. & Wang, H. Heterogeneity of liver cancer and personalized therapy.Cancer Letters379, 191–197, doi: https: //doi.org/10.1016/j.canlet.2015.07.018 (2016). SI: Hepatobiliary Cancer: All Efforts for One Goal. 6.Earlier diagnosis. NHS UK, https://www.england.nhs.uk/cancer/early-diagnosis/
-
[5]
Why is early cancer diagnosis important? Cancer research UK, https://www.cancerresearchuk.org/about-cancer/spot- cancer-early/why-is-early-diagnosis-important
-
[6]
Butnari, V .et al.The crucial role of early diagnosis for patients and the nation, understanding the costs of late-stage cancer diagnosis from a large district general hospital in england.Cost Effectiveness and Resource Allocation23, doi: 10.1186/s12962-025-00657-1 (2025)
-
[7]
NHS UK, https://www.england.nhs.uk/wp-content/uploads/2020/11/Use-of-defibrotide-in-severe- veno-occlusive-disease-following-stem-cell-transplant-all-ages.pdf (2021)
Clinical commissioning policy (revised) use of defibrotide in severe veno-occlusive disease following stem cell transplant (all ages) [210401p]. NHS UK, https://www.england.nhs.uk/wp-content/uploads/2020/11/Use-of-defibrotide-in-severe- veno-occlusive-disease-following-stem-cell-transplant-all-ages.pdf (2021)
2020
-
[8]
Bearman, S. I. The syndrome of hepatic veno-occlusive disease after marrow transplantation.Blood85, 3005–3020, doi: https://doi.org/10.1182/blood.V85.11.3005.bloodjournal85113005 (1995)
work page doi:10.1182/blood.v85.11.3005.bloodjournal85113005 1995
-
[9]
Angus, J., Connolly, S., Letton, W., Martin, C. & Martin, A. A systematic literature review of the clinical signs and symptoms of veno-occlusive disease/sinusoidal obstruction syndrome after haematopoietic cell transplantation in adults and children.eJHaem4, 199–206, doi: https://doi.org/10.1002/jha2.612 (2023). https://onlinelibrary.wiley.com/doi/pdf/10....
-
[10]
Yoon, J.-H., Choi, C. W. & Won, J.-H. Hepatic sinusoidal obstruction syndrome/veno-occlusive disease after hematopoietic cell transplantation: historical and current considerations in korea.The Korean journal of internal medicine36, 1261 (2021). 12/13
2021
-
[11]
Mehra, V .et al.Early and late-onset veno-occlusive disease/sinusoidal syndrome post allogeneic stem cell transplantation – a real-world uk experience.American Journal of Transplantation21, 864–869, doi: https://doi.org/10.1111/ajt.16345 (2021)
-
[12]
Richardson, P. G.et al.Early initiation of defibrotide in patients with hepatic veno-occlusive disease/sinusoidal obstruction syndrome following hematopoietic stem cell transplantation improves day +100 survival.Blood126, 4311–4311, doi: 10.1182/blood.V126.23.4311.4311 (2015)
-
[13]
Katsoulakis, E.et al.Digital twins for health: a scoping review.npj Digital Medicine7, doi: 10.1038/s41746-024-01073-0 (2024). 16.Rajaraman, R. Hopspital times. https://hospitaltimes.co.uk/how-to-build-digital-twins-in-healthcare/ (2025)
-
[14]
Meijer, C., Uh, H.-W. & el Bouhaddani, S. Digital twins in healthcare: Methodological challenges and opportunities. Journal of Personalized Medicine13, doi: 10.3390/jpm13101522 (2023)
-
[15]
Sun, T., He, X. & Li, Z. Digital twin in healthcare: Recent updates and challenges.Digital Health9, 20552076221149651, doi: 10.1177/20552076221149651 (2023)
-
[16]
Chakrabarty, D.et al.Constructing training set using distance between learnt graphical models of time series data on patient physiology, to predict disease scores.PLoS ONEdoi: 10.1371/journal.pone.0292404 (2023). © 2023 Chakrabarty et al
-
[17]
Bone marrow transplantation57, 538–546 (2022)
Lee, S.et al.Prediction and recommendation by machine learning through repetitive internal validation for hepatic veno-occlusive disease/sinusoidal obstruction syndrome and early death after allogeneic hematopoietic cell transplantation. Bone marrow transplantation57, 538–546 (2022)
2022
-
[18]
& Williams, C.Gaussian Processes for Machine Learning
Rasmussen, C. & Williams, C.Gaussian Processes for Machine Learning. Adaptive Computation and Machine Learning series (MIT Press, 2005)
2005
-
[19]
Hutter, F., Hoos, H. H. & Leyton-Brown, K. Sequential model-based optimization for general algorithm configuration. In Coello, C. A. C. (ed.)Learning and Intelligent Optimization, 507–523 (Springer Berlin Heidelberg, Berlin, Heidelberg, 2011). Acknowledgements KW acknowledges an internal Impact fund; CZ acknowledges funding under the project UKRI2398. Fun...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.